











 text new page (beta)
text new page (beta) Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1. Introducción
En la práctica actual los métodos formales de estimación del esfuerzo de desarrollo apoyan sus estimaciones en métodos basados en modelos empíricos de estimación. De acuerdo con Abdel et al., un modelo empírico es aquel que usa los datos de proyectos previos para evaluar al proyecto nuevo y deriva fórmulas básicas a partir del análisis de las bases de proyectos históricos 1. En contra parte, un modelo teórico es aquel que usa fórmulas basadas en supuestos generales 1. Los autores de este artículo creamos un método de estimación del esfuerzo de desarrollo de software, al que denominamos como MUREM. MUREM, considerando el método científico en vigor, se basa en un modelo híbrido (teórico-empírico) de estimación. Esto es que, al principio, este método se formuló con supuestos generales, como se hace con un modelo teórico. Después, como se hace con un modelo empírico, en la elección de su fórmula básica se consideró el análisis de las bases de proyectos históricos que conforman este caso de estudio. Este caso de estudio está conformado por las bases de datos públicas de proyectos históricos de software: Albrecht, China, Desharnais, Finnish, Kemerer, Kitchenham, Maxwell, Mermaid, Miyasaki1 y NASA93. Obtenidas, en su mayoría, del Repositorio de Ingeniería de Software PROMISE (PRedictOr Models In Software Engineering). MUREM da buenos resultados (en términos de precisión) en este caso de estudio, cuando se compara con los métodos de regresión siguientes: 1) método de regresión lineal simple (OLS: Ordinary Least Squares), 2) método de regresión potencial (RP) de ajuste por mínimos cuadrados y 3) una red neuronal (RN), entrenada con retro propagación de alimentación hacia adelante (feedforward backpropagation network). Estos métodos de regresión han generado, a través del tiempo, importantes modelos empíricos de estimación del esfuerzo de desarrollo de software 2, 3, 6, 7, 8, 9, 10, 11.
El aspecto teórico de MUREM se fundamenta en los dos elementos siguientes: 1) elegir un modelo parsimonioso para realizar la estimación. Un modelo parsimonioso es aquel que usa el menor número de variables de entrada y de parámetros para realizar una representación adecuada de los datos 12 y, 2) una "ley a priori" que considera en su aplicación un conjunto de condiciones iniciales.
De acuerdo con los trabajos de 13, 14, la variable más significativa para predecir el esfuerzo de desarrollo es el tamaño del software. Por esta razón sólo se consideró esta variable para explicar la variabilidad del esfuerzo de desarrollo.
Nuestra ley a priori estipula las propiedades que, racionalmente, debe satisfacer la relación que se establece entre el tamaño del software y el esfuerzo de desarrollo. Esta ley considera en su aplicación un conjunto de condiciones iniciales, al que denominamos como "marco de condiciones iniciales". Este marco se define como el conjunto de circunstancias en las que se realiza el proceso de estimación del esfuerzo de desarrollo. Estas circunstancias dependen de las circunstancias en las que se está realizando el proceso de desarrollo del software nuevo.
Las circunstancias en las que se desarrolla un software dependen tanto de los factores humanos como de los tecnológicos 15. Los autores de este artículo proponemos que se tomen en consideración aquellas condiciones básicas relacionadas con los principales elementos a considerar durante la administración efectiva de un proyecto de software. Estos elementos, de acuerdo con Pressman, son: el personal, el producto, el proceso y el proyecto 16.
El resto del material de este artículo está organizado como sigue: La sección 2 explica el fundamento teórico de MUREM. La sección 3 describe, brevemente, los métodos de estimación del esfuerzo que se usaron para comparar a MUREM. En la sección 4, se presentan la experimentación y los resultados obtenidos de esta comparación. Finalmente, en la sección 5 se dan las conclusiones y se sugieren los trabajos futuros.
2. Los fundamentos de MUREM
A continuación se describe, brevemente, lo que se entiende por marco de condiciones iniciales del proceso de estimación del esfuerzo y por ley a priori para la estimación del esfuerzo.
2.1. Marco de condiciones iniciales para la estimación del esfuerzo de desarrollo
Llamamos "marco de condiciones iniciales del proceso de estimación del esfuerzo de desarrollo de software", al conjunto de circunstancias en el que ha de ocurrir el proceso de estimación del esfuerzo de desarrollo para un proyecto nuevo. Las condiciones en las que se desarrolla un software nuevo son diversas y dependen en mucho del giro de la empresa de software que lo está desarrollando. Si el modelo utiliza datos históricos para realizar la estimación, entonces estos datos necesariamente deberán considerar las condiciones en las que se realizó el proceso de desarrollo que los generó. Los autores de este artículo sugerimos que las condiciones que limitan el proceso de desarrollo de software tomen en cuenta los principales elementos a considerar durante la administración eficiente de un proyecto de software. Estos elementos, de acuerdo con Pressman, son: el personal, el producto, el proceso y el proyecto 16. A continuación ejemplificamos cuáles condiciones iniciales se podrían considerar en cada uno de estos rubros.
a. Condiciones iniciales con respecto al personal.
- Nivel de educación del equipo de desarrollo.
- Experiencia del equipo en el desarrollo de software.
- Experiencia del equipo en el lenguaje de programación.
- Experiencia del equipo en la metodología de desarrollo.
- Experiencia del equipo en el dominio del proyecto.
- Experiencia del equipo en el uso de las herramientas de soporte.
b. Condiciones iniciales con respecto al producto de software.
- Tamaño del producto. Esta condición es muy importante ya que la estimación del esfuerzo está en función de la estimación del tamaño del producto nuevo. La estimación del tamaño se debe realizar tomando en cuenta el mismo estándar que se usó para medir el tamaño del software de los proyectos históricos.
- Tipo de producto. Por ejemplo: software de sistema, software de programación, software de aplicación, etc.
- Lenguaje e IDE de desarrollo.
c. Condiciones iniciales con respecto al proceso de desarrollo de software.
- Metodología de desarrollo (tradicional o ágil).
- Modelo de SDLC (cascada, espiral, por prototipos, una combinación de ellos, etc.).
- Complejidad de la programación.
- Complejidad en los datos.
- Uso de herramientas CASE.
d. Condiciones iniciales con respecto al proyecto de desarrollo de software.
- Tipo de proyecto. Por ejemplo: Administrativo, Bancario, Contabilidad, Educación, Electrónica, Finanzas, Medicina, Telecomunicaciones, Ventas, etc.
- Dominio de la práctica de software. Por ejemplo: proyectos muy grandes, proyectos aeroespaciales, aplicaciones de negocios, etc.
Éstas son sólo algunas de las condiciones básicas que se podrían considerar al momento de iniciar el proceso de desarrollo del software. Sin embargo, es imprescindible que, antes de realizar las estimaciones, cada empresa determine su propio marco de condiciones iniciales. Este marco deberá ser considerado en el criterio que se use para elegir el segmento de la base de proyectos históricos que se utilizará para estimar, tanto el tamaño como el esfuerzo de desarrollo del software nuevo.
Establecer el marco de condiciones iniciales para el proceso de estimación del esfuerzo de desarrollo no es suficiente. Además es necesario que se determinen las propiedades que, racionalmente, debe satisfacer la relación que se establece entre el esfuerzo de desarrollo y el tamaño del software. Estas propiedades se consideran en lo que nosotros denominamos como "ley a priori para la estimación del esfuerzo de desarrollo de software", la cual se describe a continuación.
2.2. Ley a priori para la estimación del esfuerzo de desarrollo de software
El proceso de estimación del esfuerzo de desarrollo de software es uno de los procesos del "Ciclo de Vida del Desarrollo de Software" (SDLC: Software Development Life Cycle). Un SDLC es un marco de referencia que contiene los procesos, las actividades y las tareas involucradas en el desarrollo, la explotación y el mantenimiento de un producto de software, abarcando la vida del sistema desde la definición de sus requerimientos hasta la finalización de su uso 17. El "Principio de Incertidumbre en la Ingeniería de Software" (UPSE: Uncertainty Principle in Software Engineering), formulado en 18, estipula que la incertidumbre es inherente e inevitable en el SDLC y sus productos.
Para considerar la incertidumbre aleatoria inherente al proceso de estimación del esfuerzo de desarrollo de software, representamos a este proceso como un experimento aleatorio que se realiza bajo un mismo marco de condiciones iniciales. Es evidente que aunque este proceso se realice bajo el mismo marco de condiciones los valores de las medidas (o estimaciones) de los atributos involucrados en dicho proceso podrán cambiar. Así que definiremos el conjunto de todos los posibles resultados de dicho experimento (espacio muestral), Ω, como:
donde Ω⊆Rm.
Cada vector numérico, s de Ω es una realización de un vector aleatorio (X1.., Xm), definido como una función:
donde a cada s ∈ Ω se le asocia un vector de m números reales (X1(s),…,Xm (s)) y
Estas m variables aleatorias representan los atributos del proceso de estimación del esfuerzo de desarrollo a los que se les puede asociar un número (medición o estimación).
De acuerdo con Jiang et al. 13 y Kemerer et al. 14 la variable más significativa para predecir el esfuerzo de desarrollo es el tamaño del software. Por consiguiente, una vez establecido el marco de condiciones iniciales, para estimar el esfuerzo de desarrollo únicamente se considerará el valor estimado del tamaño del software. Entonces el espacio muestral, Ω, quedará definido de la manera siguiente:
donde y > 0, x > 0 y sus variables aleatorias correspondientes están definidas como: Y: Ω → R+, X: Ω → R+, con Y((x, y)) = y y X((x, y)) = x, ∀(x, y) Є Ω, respectivamente.
Debido a que la variabilidad del esfuerzo no es completamente explicada por el tamaño del software, el resto de las variables significativas para la estimación del esfuerzo se podrán considerar a través de la elección de las condiciones iniciales del proceso de estimación.
En nuestra ley asumimos que la variabilidad del esfuerzo de desarrollo (Yt) es proporcional a su estimación
donde c es una constante.
Es decir la varianza del esfuerzo debe aumentar conforme aumenta el tamaño y el esfuerzo de desarrollo del software. En situaciones como esta, la gráfica de los datos de esfuerzo frente a los estimados se ensanchará como un abanico hacia la derecha. Este supuesto se justifica en el hecho de que pedir que la varianza sea fija para cualquier valor del tamaño del software implicará que los intervalos de confianza y de predicción para el esfuerzo también sean fijos. Esto es absurdo si consideramos que el tamaño del error de una estimación deberá aumentar conforme el software se vuelve más complejo.
En estas circunstancias de acuerdo con 19, 20 estamos esencialmente asumiendo una estructura multiplicativa de los errores de estimación del esfuerzo. En otras palabras, el error es un múltiplo del promedio del esfuerzo de desarrollo. Modelamos estadísticamente esta relación con la ecuación (2):
En el modelo (2) se supone que:
1. La variable Yt se distribuye log-normalmente porque este tipo de distribuciones son comunes cuando los valores de sus medias son bajos, sus varianzas son grandes y los valores de la variable aleatoria dependiente no deben ser negativos.
2. {Yt}tЄT es una sucesión de variables aleatorias independientes e idénticamente distribuidas (iid). Esto es, porque suponemos independencia estadística entre los experimentos aleatorios que se ejecutan cada vez que se ejecuta el proceso de estimación del esfuerzo de desarrollo.
3.
si f(∙) es conocido excepto por un vector desconocido de parámetros, 8, a ser estimados tenemos que f(Xt)= f(Xt, θ) y el modelo es llamado paramétrico; en caso contrario es llamado no-paramétrico.
4. La desviación estándar de Yt es proporcional a f(Xt) (SD(Yt) = cf(Xt)), es decir la varianza del esfuerzo debe aumentar conforme aumenta el esfuerzo mismo.
5. Se tienen almacenadas las mediciones de tamaño, Xt, y de esfuerzo de desarrollo, Yt, de n proyectos históricos. Estos proyectos se realizaron bajo el mismo marco de condiciones iniciales que el del proyecto nuevo. Denotamos por {(X1 ,Y1), (X2 ,Y2).....(Xn ,Yn)], a una muestra de tamaño n y, por
6. El término de error ut , es una variable aleatoria lognormal que mide el error de la estimación de Yt , su función de densidad de probabilidad está definida sobre un soporte (0,+ ∞), con media unitaria (E(ut ) = 1) y varianza constante pero desconocida,
7. ut , se supone independiente del tamaño del software, Xt.
8. {ut}tЄT se supone independiente e idénticamente distribuida (iid) sobre todo el intervalo de datos.
Existe una variedad de métodos que corrigen la heterocedasticidad, sin embargo para la heterocedasticidad representada en la ecuación (1), de acuerdo con 19, la primera solución es transformar los datos originales tomando su logaritmo natural.
Si aplicamos la transformación logarítmica: Zt: = ln(Yt)., g(Xt) := ln(f(Xt )) y εt := ln(ut), obtenemos que los errores multiplicativos, ut, se convierten en aditivos, εt, y la varianza de Zt es constante:
donde Zt, g(Xt) y et son variables aleatorias normales y, Xt y εt son independientes 21. Dado que suponemos que ambas sucesiones {Yt}tЄT y {ut}tЄT, son lognormales, entonces {Zt}tЄT y {εt}tЄT , son iid normales 22.
En todos los modelos de regresión y en particular para el modelo (4) el caso ideal es que el error εt sea aleatorio, es decir que sea creado por un proceso de ruido blanco gaussiano de media cero (zero mean additive white gaussian noise, o zero mean AWGN), 23, 24, 25. De acuerdo con Ruppert 26 y Fan 27, la secuencia {εt}tЄT es un AWGN de media cero si:
Por otro lado, dado que f: R+ → R+ , entonces g:f(R+ ) → R. Además, como las funciones f(∙) y In(∙) son continuas y monótonas estrictamente crecientes, entonces g(∙) = f°ln(∙), también lo será. Además de que dado que f(0) ≈ 0 entonces g(0) = ln(f(0)) ≈ 1.
Partiendo del supuesto de que g(∙) existe y es calculable, ¿cómo arribamos a un valor de g(∙)?, ¿y cómo decidimos si este valor es óptimo o no?, y si es óptimo, ¿en qué sentido?. Para responder a estas preguntas, primero precisamos elegir una función de costo que penalice el error de estimación. La estimación resultante g(∙) será óptima sólo en el sentido de que conduzca al valor mínimo de costo. La elección de una función de costo diferente, generalmente, conducirá a una elección diferente para g(∙). Cada una de ellas siendo óptima a su manera. El criterio de diseño que nosotros adoptamos es el criterio de error cuadrático medio. Hay varias buenas razones para elegir este criterio. La más sencilla es que este criterio, más que ningún otro, es susceptible de manipulaciones matemáticas. Adicionalmente, este criterio esencialmente intenta forzar a que el error de estimación tome valores cercanos a su media, es decir cero 28. El error de estimación, εt, se define en (9) de la manera siguiente:
para determinar
la solución está dada por el teorema siguiente, enunciado por Sayed 28.
Teorema. (Estimador óptimo de error cuadrático medio). El mínimo error cuadrático medio de Zt dado Xt es la esperanza condicional de Zt dado Xt , es decir,
la esperanza condicional puede verse como el concepto generalizado de regresión. En nuestro caso sólo hay un regresando (Zt) y un regresor numérico (Xt).
De una gran variedad de modelos de regresión que se pueden elegir para realizar la estimación del esfuerzo de desarrollo, el más simple que podemos considerar para establecer la relación entre Zt y Xt, es el lineal. Sin embargo, para tomar una decisión fundamentada en la información disponible en las muestras que conforman este caso de estudio, se realizó el diagrama de dispersión del tamaño vs el esfuerzo de desarrollo, para cada muestra. Ignorando el ruido y la heterocedasticidad, se determinó que se puede trazar una línea recta que divide la nube de puntos a la mitad. Por lo que se supuso que los datos tienen un comportamiento aproximadamente lineal. Esto significa que f(∙) de la ecuación (3) se puede sustituir por (aXt + b), obteniendo la ecuación (12):
donde a y b son parámetros.
Como, por hipótesis, f(∙) debe ser positiva, continua, monótona estrictamente creciente y f(0) ≈ 0, entonces a > 0 y b ≈ 0. Esto significa que f(Xt) ≈ aXt, aplicando logaritmo natural a ambos lados de la ecuación (11) tenemos que:
es decir, g(Xt) = ln(f(Xt)) * ln(aXt) = ln(Xt) + ln(a), dado que a es un parámetro parece razonable estimar a g(∙) con el modelo de regresión logarítmica (13):
donde c1 y c2 son parámetros que se calculan por el método de mínimos cuadrados. Se pide que c1 > 0, para que g(∙) satisfaga la propiedad de monotonía estrictamente creciente. Por ende:
de tal manera que, conforme c1 se acerque a uno, f(∙) tenderá a ser lineal.
Para estimar los intervalos de confianza y de predicción de f(∙) primero se tienen que calcular los intervalos de confianza y de predicción de la función g(∙).
Supongamos que los errores tienen una distribución normal y su media
para < 30,
para n ≥ 30.
Con las mismas condiciones para εt, de acuerdo con Helsel en 29, para estimar el intervalo de predicción de una observación nueva Zn+1 cuando Xn+1 = xn+1 ., se usa la ecuación (17) o (18), según sea el caso:
para < 30.
para ≥ 30.
Una vez estimado el intervalo de confianza de g(∙), para estimar el intervalo de confianza de f(∙), de acuerdo con 29, se usa (19 o 20), según sea el caso:
para < 30,
para ≥ 30.
Una vez estimado el intervalo de predicción de una observación nueva Zn+1 cuando Xn+1 = xn+1. Para estimar el intervalo de predicción para una observación nueva Yn+1 cuando Xn+1 = xn+1, de acuerdo con 29, se usa la ecuación (21 o 22), según sea el caso:
para < 30,
para ≥ 30.
En las ecuaciones (15-22) n es el tamaño muestral y
3. Comparación de MUREM con otros métodos
El desempeño de MUREM fue comparado con el de los métodos de regresión siguientes: 1) regresión lineal simple (OLS: Ordinary Least Squares), 2) regresión potencial (RP) ajustada por mínimos cuadrados y 3) una red neuronal (RN) entrenada con retropropagación de alimentación hacia adelante (feed-forward backpropagation network). A continuación se describe, brevemente, cada uno de ellos.
3.1. Método de regresión lineal simple (OLS)
La regresión lineal simple se usa para modelar la relación lineal entre dos variables 30. Esta regresión se representa con la ecuación (23):
donde c3 y c4 son parámetros que se calculan por el método de mínimos cuadrados. Para que f(∙) satisfaga la propiedad de monotonía estrictamente creciente se pide que c3 > 0.
De acuerdo con 31, 31y 33, el método de regresión lineal (simple o múltiple) es un método clásico en la estimación del esfuerzo de desarrollo. Como muestra de esto se tienen los modelos empíricos de dicho método que se presentan en la Tabla 1.

3.2. Método de regresión potencial (RP)
El modelo de regresión RP es un método de regresión no lineal. Esto significa que el esfuerzo requerido para la implementación no necesariamente es directamente proporcional al tamaño del software. De acuerdo con 36, esta regresión se representa con la ecuación (24):
donde c5 y c6 son dos parámetros de la misma que se calculan por el método de mínimos cuadrados. Se pide que c5> 0 y c6> 0 para que f(∙) satisfaga la propiedad de monotonía estrictamente creciente.
La ecuación (24) es la forma más común de los modelos no lineales y ha sido utilizada, a través del tiempo, por una gran variedad de modelos empíricos para la estimación del esfuerzo de desarrollo. En la Tabla 2 se muestran algunos de estos modelos.

Uno de los algoritmos de aprendizaje supervisado de red neuronal más usado es el denominado como retropropagación de alimentación hacia adelante (feed-forward backpropagation network). Este algoritmo considera tres fases: 1) la alimentación hacia adelante del patrón de entrenamiento de entrada, 2) el cálculo y la retropropagación del error asociado y 3) el ajuste de los pesos. En este estudio comparativo se usó un modelo de red neuronal con este tipo de algoritmo de entrenamiento y fue implementado con la función, "newff', de la librería de redes neuronales de MATLAB R2012a.
La arquitectura de esta red está compuesta por una capa oculta con una neurona tangente sigmoidal hiperbólica (tansig), seguida por una capa de salida con una neurona puramente lineal (purelin). Se consideró solamente una neurona en la capa oculta para lograr que esta red generara funciones monótonas estrictamente crecientes. El algoritmo de entrenamiento de retropropagación que se eligió para esta red fue el de, "trainbr", denominado como regularización bayesiana. La regularización bayesiana tiene buenas cualidades de generalización. En la experimentación trainbr fue el que tuvo mejor desempeño.
4. Evaluación de MUREM y análisis de resultados experimentales
Para evaluar a MUREM, se comparó su desempeño con el obtenido por los tres métodos de estimación descritos en la sección anterior. Estos métodos se aplicaron a un mismo caso de estudio. Este caso de estudio está conformado por las bases de datos públicas de proyectos de software: Albrecht, China, Desharnais, Finnish, Kemerer, Kitchenham, Maxwell, Mermaid, Miyasaki1 y NASA93.
Estas bases, a pesar de tener la gran ventaja de ser ampliamente conocidas y accesibles, cumplen, de manera muy relajada, con el criterio de condiciones iniciales homogéneas. Sin embargo, aun así, MUREM fue capaz de obtener buenos resultados sin sacrificar la validez externa. En la Tabla 3 se muestran la cantidad de proyectos y las unidades que tiene cada una de estas bases para medir el tamaño del software y el esfuerzo de desarrollo. Considerando las unidades del tamaño del software, se obtuvieron 12 muestras etiquetadas como: KemererAFP, KemererKSLOC, AlbrechtAFP, AlbrechtKSLOC, Mermaid, Finnish, Miyasaki1, Maxwell, Desharnais, Nasa93, Kitchenham y China.
Tabla 3 Cantidad de proyectos en las bases que conforman este caso de estudio
| BD | No. Proyectos | Unidades de tamaño del software | Unidades de esfuerzo |
|---|---|---|---|
| Kemerer | 15 | AFP KSLOC | Hombre-mes Hombre-mes |
| Albrecht | 24 | AFP SLOC | Hombre-mes Hombre-mes |
| Mermaid | 30 | AFP | Hombre-hora |
| Finnish | 38 | FP | Hombre-hora |
| Miyasakil | 48 | KSLOC | Hombre-mes |
| Maxwell | 62 | FP | Hombre-hora |
| Desharnais | 81 | AFP | Hombre-hora |
| Nasa93 | 93 | KSLOC | Hombre-mes |
| Kitchenham | 145 | AFP | Hombre-hora |
| China | 499 | AFP | Hombre-hora |
Esta comparación se realizó considerando los criterios siguientes:
Proporción de muestras que cumplen con la condición de positividad de f(∙).
Precisión de la estimación puntual de f(∙).
Proporción de muestras cuyos residuales pasaron la prueba de ruido blanco gaussiano de media cero.
Calidad de los intervalos de confianza y de predicción de f(∙).
A continuación se describen, brevemente, los resultados obtenidos para cada uno de estos criterios.
4.1. Positividad de f(∙)
Para estimar los parámetros c1, c2, c3, c4, c5 y c6, de los modelos de regresión (13. 23, 24), respectivamente, se usó la librería ezyfit de MATLAB R2012a. En la Tabla 4 se muestran los valores estimados para estos parámetros.
Tabla 4 Valores estimados para los parámetros c1, c2, c3 ,c4, c5 y c6
| MUREM | OLS | RP | ||||
|---|---|---|---|---|---|---|
| Muestra | c1 | c2 | c3 | c4 | c5 | c6 |
| KemererAFP | 0.90 | -1.06 | 0.34 | -121.57 | 2.06E-05 | 2.28 |
| KemererKSLOC | 0.81 | 0.97 | 1.39 | -39.91 | 0.02 | 1.74 |
| AlbrechtAFP | 1.49 | 0.09 | 54.45 | -13387.9 | 0.12 | 1.81 |
| AlbrechtKSLOC | 1.17 | 4.99 | 386.0 | -1703.04 | 413.25 | 0.98 |
| Mermaid | 0.82 | 4.05 | 14.74 | 3354.4 | 468.42 | 0.53 |
| Finnish | 1.06 | 1.67 | 8.99 | 813.80 | 40.39 | 0.80 |
| Miyasaki1 | 0.99 | -0.07 | 1.92 | -48.46 | 6.5E-05 | 2.75 |
| Maxwell | 0.87 | 3.24 | 11.27 | 633.12 | 8.66 | 1.04 |
| Desharnais | 0.94 | 3.04 | 17.56 | -33.09 | 14.94 | 1.03 |
| Nasa93 | 0.93 | 1.94 | 5.06 | 148.8 | 20.57 | 0.78 |
| Kitchenham | 0.67 | 3.61 | 6.18 | -148.77 | 3.63 | 1.06 |
| China | 0.77 | 3.30 | 4.19 | 1881.5 | 64.31 | 0.70 |
En la Tabla 4 se ve que, dado que c5 > 0 y c6 > 0 para todas las muestras, se tiene que RP satisfizo la propiedad de positividad para el 100% de las muestras. Con OLS, el 58% de las muestras no cumplieron con la condición de positividad. Los valores de tamaño de estas muestras que caigan dentro del intervalo
El método RN pasó la prueba de positividad para cada una de las muestras.
En la Tabla 4 también se ve que casi todos los valores de c1 están muy cercanos a uno, corroborándose el supuesto de que la relación que se establece entre el esfuerzo de desarrollo y el tamaño del software es aproximadamente lineal.
4.2. Precisión de la estimación puntual de f(∙)
A sugerencia de 31, 39 y 40 se usaron los estadísticos (15) y (16) para medir la precisión de la estimación puntual del esfuerzo de desarrollo.
si el MMRE es cercano a cero y el Pred(0.25) (para k=0.25) cercano a uno, entonces se considera que el método de estimación tiene una buena precisión puntual 31.
En la Tabla 5 se muestra el promedio obtenido del índice MMRE para cada uno de los métodos.
Tabla 5 Medias del índice MMRE
| Muestra | MUREM | OLS | RP | RN |
|---|---|---|---|---|
| KemererAFP | 0.43 | 1.06 | 0.65 | 0.60 |
| KemererKSLOC | 0.49 | 0.67 | 0.66 | 0.60 |
| AlbrechtAFP | 0.53 | 0.90 | 0.47 | 0.71 |
| AlbrechtKSLOC | 0.44 | 0.63 | 0.71 | 1.25 |
| Mermaid | 0.93 | 2.48 | 2.06 | 2.73 |
| Finnish | 0.80 | 1.20 | 1.29 | 1.24 |
| Miyasakil | 0.40 | 1.42 | 0.92 | 1.27 |
| Maxwell | 0.54 | 0.64 | 0.51 | 0.76 |
| Desharnais | 0.58 | 0.65 | 0.65 | 0.65 |
| Nasa93 | 0.65 | 2.33 | 1.45 | 2.33 |
| Kitchenham | 0.68 | 0.81 | 0.72 | 2.36 |
| China | 1.04 | 2.36 | 1.79 | 1.75 |
| Media= | 0.63 | 1.26 | 0.99 | 1.35 |
En la Tabla 6 se muestra el promedio obtenido del índice Pred(0.25) para cada uno de los métodos.
Tabla 6 Medias del índice Pred(0.25)
| Muestra | MUREM | OLS | RP | RN |
|---|---|---|---|---|
| KemererAFP | 0.40 | 0.13 | 0.40 | 0.33 |
| KemererKSLOC | 0.40 | 0.33 | 0.13 | 0.27 |
| AlbrechtAFP | 0.54 | 0.33 | 0.29 | 0.50 |
| AlbrechtKSLOC | 0.38 | 0.38 | 0.33 | 0.46 |
| Mermaid | 0.13 | 0.17 | 0.23 | 0.17 |
| Finnish | 0.24 | 0.29 | 0.26 | 0.29 |
| Miyasakil | 0.42 | 0.17 | 0.02 | 0.29 |
| Maxwell | 0.23 | 0.23 | 0.29 | 0.21 |
| Desharnais | 0.37 | 0.43 | 0.43 | 0.43 |
| Nasa93 | 0.34 | 0.16 | 0.15 | 0.16 |
| Kitchenham | 0.28 | 0.40 | 0.37 | 0.16 |
| China | 0.21 | 0.20 | 0.19 | 0.18 |
| Media= | 0.33 | 0.27 | 0.26 | 0.29 |
Para evaluar si existe una diferencia significativa entre las medias obtenidas para cada uno de los métodos, tanto para el MMRE (de la Tabla 5) como para el Pred(0.25) (de la Tabla 6), se plantearon las hipótesis siguientes:
Las hipótesis (27, 28, 29) se contrastaron para ambos índices (MMRE y Pred(0.25). En estas pruebas se utilizó la prueba de hipótesis de igualdad de medias de dos muestras pequeñas para cola inferior (the two-sample test of small samples for lower tail) que viene definida en 40, 42. Se obtuvieron los resultados siguientes:
Se aplicó la prueba de dos muestras pequeñas para cola inferior, en la modalidad de varianzas desconocidas y diferentes, para probar si la diferencia entre las medias del MMRE, era estadísticamente significativa. Con un nivel de significación de 0.05, se rechazó la hipótesis nula de cada una de las hipótesis (27, 28, 29). Esto implica que, para este caso de estudio, existe una relación significativa entre el uso de MUREM y la disminución del MMRE.
Se aplicó la prueba de dos muestras pequeñas para cola inferior, en la modalidad de varianzas desconocidas pero iguales, para probar si la diferencia entre las medias del Pred(0.25), era estadísticamente significativa.
Con un nivel de significación de 0.05, se rechazó la hipótesis alterna de cada una de las hipótesis (27, 28, 29). Esto significa que las medias del índice Pred(0.25), se consideran estadísticamente iguales.
4.3. Proporción de muestras cuyo error es creado por un AWGN de media cero
Las hipótesis (30, 31, 32), se plantearon para contrastar el supuesto de AWGN de media cero en los errores:
para contrastar estas hipótesis en todos los supuestos (5, 6, 7 ,8) de AWGN de media cero se usó la prueba Chi-cuadrado de Pearson para la independencia de variables. Esta prueba está definida en 43.
a. Contraste de normalidad en los errores.
Se probó el supuesto (5) de AWGN de media cero, el cual asume que los errores tienen distribución normal. Para ello se contrastaron, dos veces, las hipótesis (30, 31, 32). Primero se contrastaron utilizando el estadístico de Kolmogorov-Smirnov (KS), definido en 44, y después utilizando el estadístico de Jerque-Bera (JB), definido en 45.
En las Tablas 7 y 8 se presenta la proporción de muestras que pasaron la prueba de normalidad del error. En la Tabla 7 es con respecto al estadístico de Kolmogorov-Smirnov (KS) y en la Tabla 8 es con respecto al estadístico de Jerque-Bera (JB). En ambas tablas, la entrada 1, significa que no se rechaza la hipótesis de normalidad de los residuales y la entrada 0 significa que se rechaza.
Tabla 7 Proporción de muestras que cumplen con la propiedad de normalidad (KS) en los residuales
| Muestra | KS | KS | KS | KS |
|---|---|---|---|---|
| MUREM | OLS | RP | RN | |
| KemererAFP | 1 | 1 | 1 | 1 |
| KemererKSLOC | 1 | 1 | 1 | 1 |
| AlbrechtAFP | 1 | 1 | 1 | 1 |
| AlbrechtKSLOC | 1 | 1 | 1 | 1 |
| Mermaid | 1 | 1 | 1 | 1 |
| Finnish | 1 | 1 | 1 | 1 |
| Miyasaki1 | 1 | 0 | 0 | 0 |
| Maxwell | 1 | 1 | 1 | 1 |
| Desharnais | 1 | 1 | 1 | 1 |
| Nasa93 | 1 | 0 | 0 | 0 |
| Kitchenham | 1 | 0 | 0 | 0 |
| China | 1 | 0 | 0 | 0 |
| Proporción= | 1.00 | 0.67 | 0.67 | 0.67 |
Tabla 8 Proporción de muestras que cumplen con la propiedad de normalidad (JB) en los residuales
| Muestra | JB | JB | JB | JB |
|---|---|---|---|---|
| MUREM | OLS | RP | RN | |
| KemererAFP | 1 | 1 | 1 | 1 |
| KemererKSLOC | 1 | 0 | 1 | 0 |
| AlbrechtAFP | 0 | 1 | 1 | 0 |
| AlbrechtKSLOC | 1 | 0 | 0 | 1 |
| Mermaid | 1 | 0 | 0 | 0 |
| Finnish | 1 | 1 | 1 | 1 |
| Miyasaki1 | 1 | 0 | 0 | 0 |
| Maxwell | 1 | 0 | 0 | 0 |
| Desharnais | 0 | 0 | 0 | 0 |
| Nasa93 | 0 | 0 | 0 | 0 |
| Kitchenham | 0 | 0 | 0 | 0 |
| China | 1 | 0 | 0 | 0 |
| Proporción= | 0.67 | 0.25 | 0.33 | 0.25 |
En las tres pruebas de las hipótesis (30, 31) y (32) el valor-p (de la prueba Chi-cuadrado de Pearson), obtenido fue de p = 0.028. Este valor es lo suficientemente pequeño (menor que 0.05), para rechazar la hipótesis nula de las tres hipótesis. Esto significa que las diferencias encontradas entre las proporciones difícilmente pueden ser explicadas por el azar, siendo mayor la proporción de muestras cuyos residuales presentan normalidad cuando se aplica MUREM.
En las pruebas de las hipótesis (30, 32) el valor-p obtenido fue de p = 0.04. Este valor es lo suficientemente pequeño para rechazar la hipótesis nula en ambas hipótesis. Esto significa que la proporción obtenida por MUREM es estadíscamente mayor que las proporciones obtenidas con los métodos OLS y RN.
En la prueba de la hipótesis (31), el valor-p obtenido fue de p = 0.102. Este valor es lo suficientemente grande (mayor ó igual que 0.05) para rechazar la hipótesis alterna. Esto significa que la diferencia entre las proporciones obtenidas por los métodos MUREM y RP puede ser ocasionada por el azar.
b. Contraste de homocedasticidad en los errores.
Las hipótesis (30, 31, 32), se contrastaron para probar el supuesto (6) de AWGN de media cero. Este supuesto asume homocedasticidad en los errores.
Para probar la homocedasticidad de los residuales se aplicó una prueba de hipótesis basada en el estadístico de White. Esta prueba se describe en 46.
En la Tabla 9 se presenta la proporción de muestras que pasaron la prueba de White para la homocedasticidad. La entrada 1, significa que no se rechaza la hipótesis de homocedasticidad en los residuales y la entrada 0 significa que se rechaza.
En las pruebas de las hipótesis (30, 31, 32) los valores-p obtenidos fueron de: p = 0.0093, p = 0.014 y p = 0.04, respectivamente. Estos valores son lo suficientemente pequeños para rechazar la hipótesis nula de las tres hipótesis.
Esto significa que las diferencias encontradas entre las proporciones difícilmente pueden ser explicadas por el azar, siendo mayor la proporción de muestras cuyos residuales presentan homocedasticidad cuando se aplica MUREM.
Es importante hacer notar que si el supuesto de homocedasticidad en los errores no se cumple, entonces el estimador de mínimos cuadrados ordinarios pierde su eficiencia.
c. Contraste de ausencia de autocorrelación en los errores.
Las hipótesis (30, 32), se contrastaron para probar el supuesto (7) de AWGN de media cero, Este supuesto asume la ausencia de autocorrelación en los errores. La contrastación de la hipótesis (31) no se realizó porque en la experimentación resultó que πMUREM - πRP.
Para contrastar la existencia de autocorrelación (lineal) de primer orden en los residuales, se aplicó una prueba de hipótesis basada en el estadístico de Durbin-Watson (DW). Esta prueba se describe en 47.
En la Tabla 10 se presenta la proporción de muestras que pasaron la prueba de Durbin-Watson (DW) para cada uno de los métodos. La entrada 1, significa que no existe autocorrelación, el 0 significa que existe autocorrelación y el 2 significa que no se puede concluir nada.
En las pruebas de las hipótesis (30, 32), los valores-p obtenidos fueron de: p = 0.3359 y p = 0.13, respectivamente. Estos valores son lo suficientemente grandes para rechazar la hipótesis alterna de ambas hipótesis. Esto significa que la diferencia entre las proporciones puede ser explicada por el azar.
d. Contraste de supuesto de media cero de los errores.
La hipótesis (32) se contrastó para probar el supuesto (8) de AWGN de media cero. Este supuesto asume que los errores tienen media cero. Para determinar si la muestra de residuales cumple con este supuesto, se usó la prueba de hipótesis de media cero de los errores, con varianza desconocida. Esta prueba está definida en 48. En la Tabla 11, se presenta la proporción de muestras que pasaron dicha prueba. La entrada 1, significa que no se rechaza la hipótesis de media cero de sus residuales y la entrada 0 significa que se rechaza. La contrastación de las hipótesis (30, 31), no se realizó porque en la experimentación resultó que:
Tabla 11 Proporción de muestras que cumplen con la propiedad de media cero de los residuales
| Muestra | MUREM | OLS | RP | RN |
|---|---|---|---|---|
| KemererAFP | 1 | 1 | 1 | 1 |
| KemererKSLOC | 1 | 1 | 1 | 1 |
| AlbrechtAFP | 1 | 1 | 1 | 1 |
| AlbrechtKSLOC | 1 | 1 | 1 | 1 |
| Mermaid | 1 | 1 | 1 | 1 |
| Finnish | 1 | 1 | 1 | 1 |
| Miyasaki1 | 1 | 1 | 1 | 1 |
| Maxwell | 1 | 1 | 1 | 1 |
| Desharnais | 1 | 1 | 1 | 1 |
| Nasa93 | 1 | 1 | 1 | 1 |
| Kitchenham | 1 | 1 | 1 | 0 |
| China | 1 | 1 | 1 | 1 |
| Proporción= | 1 | 1 | 1 | 0.92 |
En la prueba de la hipótesis (32), el valor-p obtenido fue de p = 0.3. Este valor es lo suficientemente grande para rechazar la hipótesis alterna. Esto significa que la diferencia entre las proporciones puede ser explicada por el azar.
4.3. Calidad de los intervalos de confianza y de predicción de f(∙)
De acuerdo con 49, la precisión de un estimador por intervalo de confianza, se determina por el ancho de su intervalo de la manera siguiente: entre más angosto sea su intervalo, más preciso será su estimador.
En nuestro caso, comparar las longitudes de los intervalos de confianza, como se propone en 49, para determinar cuál método nos genera los resultados más precisos, es una empresa, relativamente difícil. Esto es porque a diferencia del resto de los métodos, la longitud del intervalo de confianza de MUREM no es fijo para todos los valores del tamaño. Esto se puede constatar en las Figuras 1 a 12 (2, 3, 4, 5, 6, 7, 8, 9, 10, 11).



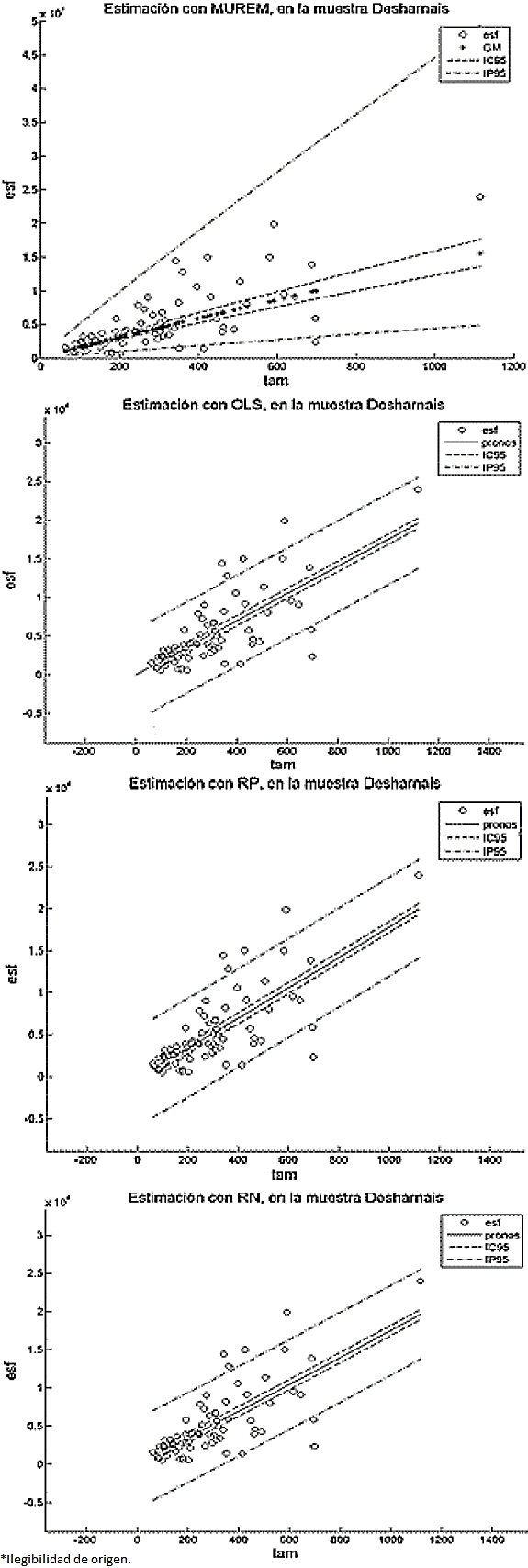
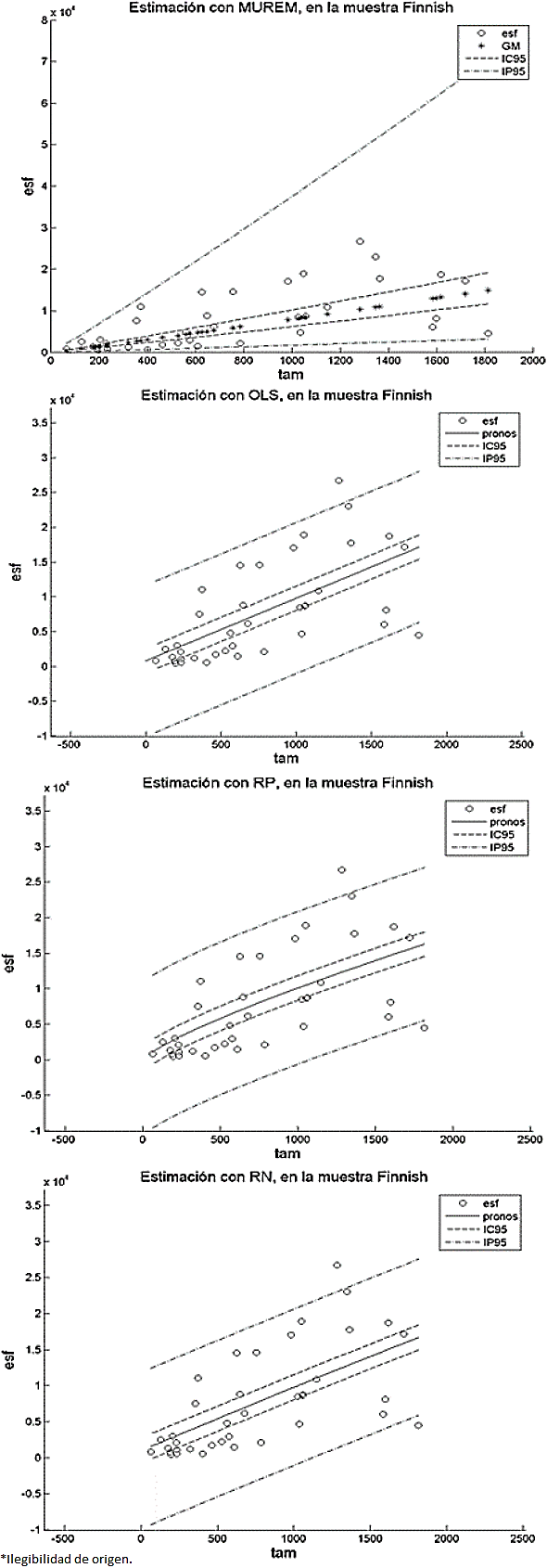


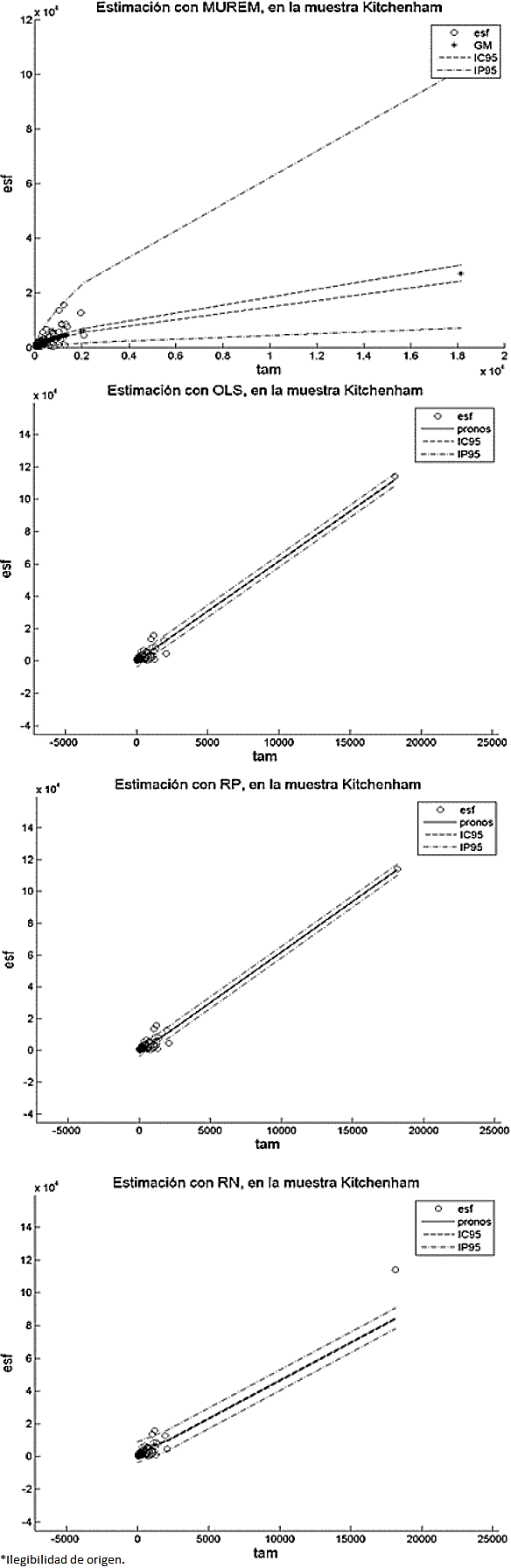
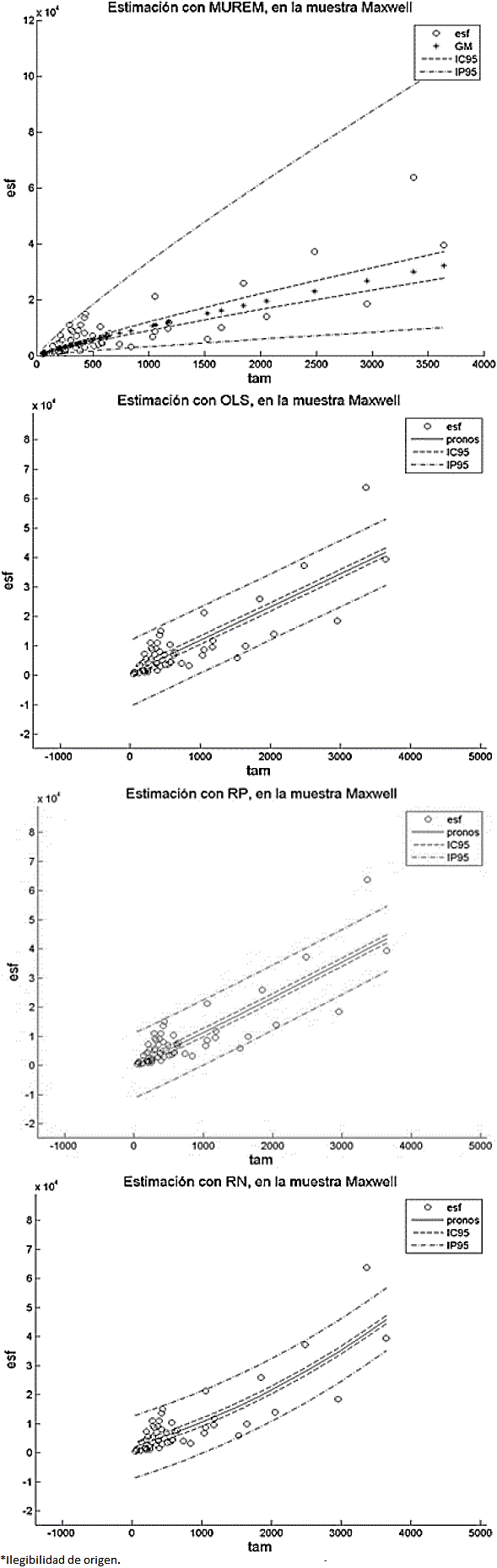


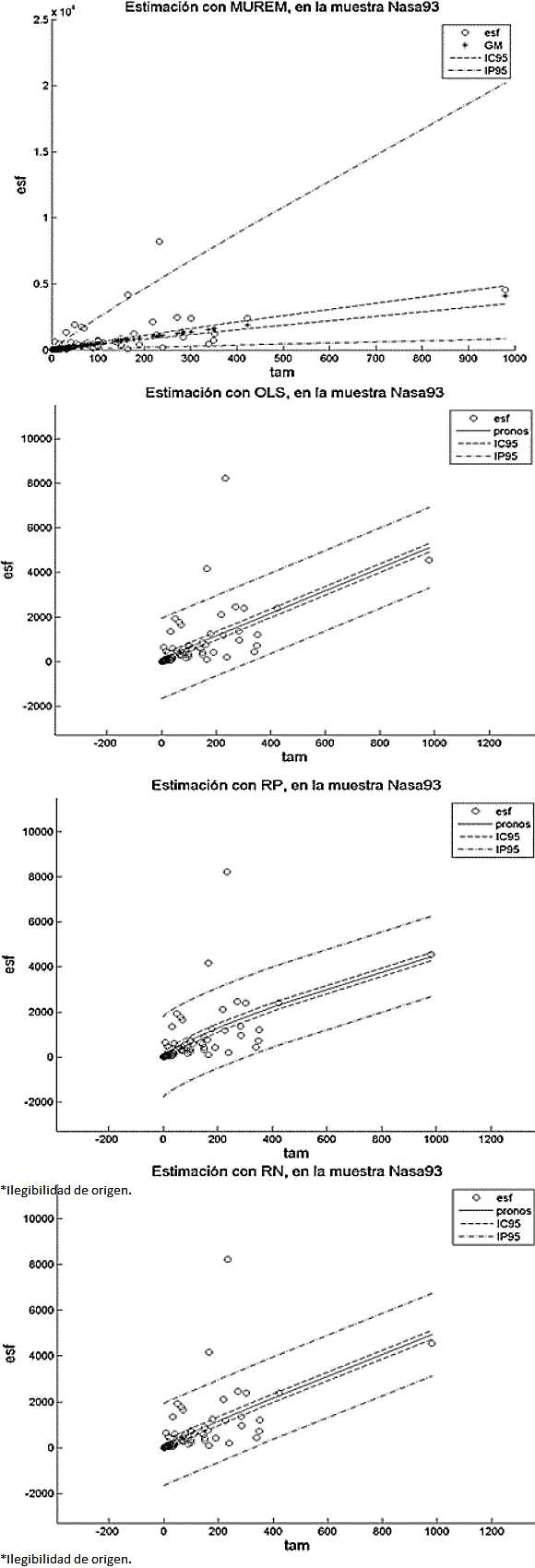
En el método MUREM las longitudes mínimas del intervalo de predicción se presentan en los proyectos de menor tamaño y las longitudes máximas se presentan en los proyectos de mayor tamaño. Esto ocasiona que la mayoría de las observaciones que se salen de este intervalo correspondan con sistemas de software de tamaño pequeño.
En cambio, en el resto de los métodos, la longitud del intervalo de predicción es fijo para todos los valores del tamaño.
Esto ocasiona que la mayoría de las observaciones que se salen del intervalo de predicción sean aquellas que se correspondan con sistemas de software de tamaño grande. Esto aumenta, considerablemente, la pérdida económica asociada al tamaño del error de estimación. En las Figuras 1 a 12 se presentan los intervalos de confianza y de predicción, superpuestos a los datos de la muestra.
Las leyendas: esf, IC95 y IP95, en las gráficas de las Figuras 1 a 12, representan, respectivamente, los valores del esfuerzo, del intervalo de confianza y del intervalo de predicción (ambos intervalos calculados con un 95% de confianza). La leyenda GM, en las gráficas del método MUREM, representa el valor de la estimación usando la ecuación (14): La leyenda pronos, en las gráficas.
5. Conclusiones
Nuestro método de estimación del esfuerzo de desarrollo, denominado como MUREM, se sintetizó a partir de la teoría y se contrasta con la experiencia. Se basa en el establecimiento de un conjunto de condiciones iniciales que enmarca el proceso de estimación del esfuerzo de desarrollo, conjuntamente, con una ley a priori que estipula las propiedades que, racionalmente, debe satisfacer la relación que se establece entre el esfuerzo de desarrollo y el tamaño del software. Para elegir la fórmula básica de MUREM se buscó que, además de satisfacer nuestra ley a priori, se ajustara bien a las muestras extraidas de las bases de proyectos históricos de este caso de estudio. Este caso está conformado por las bases de datos públicas de proyectos históricos de software: Albrecht, China, Desharnais, Finnish, Kemerer, Kitchenham, Maxwell, Mermaid, Miyasaki1 y NASA93.
El desempeño de MUREM fue comparado con el de los métodos siguientes: regresión lineal simple (OLS), regresión potencial (RP) ajustada por mínimos cuadrados y una red neuronal (RN) entrenada con retropropagación de alimentación hacia adelante. De acuerdo con los resultados obtenidos en la experimentación se tiene que:
A diferencia de los métodos OLS, RP y RN, MUREM nos asegura que la estimación del esfuerzo de desarrollo será positiva para cualquier muestra. En esta experimentación, OLS logró que solamente el 42% de las muestras cumplieran con esta condición.
MUREM genera estimaciones puntuales más precisas que el resto de los métodos. Las medias del índice MMRE son de: 0.63, 1.26, 0.99 y 1.35, para MUREM, OLS, RP y RN, respectivamente. Con esto, MUREM redujo, casi a la mitad, los valores obtenidos por los otros métodos.
Los residuales obtenidos por MUREM satisfacen la prueba de ruido blanco gaussiano de media cero. Con esto se prueba que el error de estimación de dicho método es aleatorio. El resto de los métodos presentan problemas con la satisfacción de las propiedades de homocedasticidad y normalidad en sus errores.
Las proporciones de las muestras cuyos residuales presentan homocedasticidad son de: 0.75, 0.08, 0.25 y 0.33 para MUREM, OLS, RP y RN respectivamente. Con esto se muestra que MUREM funciona bien para corregir la heterocedasticidad de los datos.
Las proporciones de las muestras cuyos residuales presentan normalidad, cuando se aplica el estadístico de Kolmogorov-Smirnov (KS), son de: 1.00, 0.67, 0.67 y 0.67; para MUREM, OLS, RP y RN, respectivamente. Con esto se muestra que MUREM aumenta, aproximadamente, el 33% de las muestras que cumplen con esta propiedad. La normalidad del error es un supuesto teórico en la deducción de las fórmulas que se usan para estimar los intervalos de confianza y de predicción. Si el error no cumple con este supuesto no se garantiza que la estimación de los intervalos sea precisa.
A diferencia de los métodos OLS, RP y RN, MUREM genera intervalos de predicción pequeños, para tamaños pequeños del software, y grandes, para tamaños grandes. Con esto se disminuye considerablemente la pérdida económica asociada al tamaño del error de estimación.

