











 text new page (beta)
text new page (beta) English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1 Introduction
Sign Language is at the same time a very promising and challenging field of study given the big number of hearing impaired people who cannot express their needs and communicate with others. To avoid this problem and its associated societal and economic impact, intelligent systems have been proposed.
Hand gesture recognition is one of the most important tasks in the sign language research area. Since it is a difficult field suffering from complex problems related to the study context, it needs the use of robust descriptors.
Many approaches have been developed in literature to achieve this challenging objective and perform a gesture recognition using a simple camera 27, 4, 22.
Although these approaches are intuitive, easy and cheap, the results are still not sufficient especially for real-time applications. This may be due to the limitation of the optical sensor in the given quality of the captured image which is sensitive to lighting conditions and complex backgrounds.
Using a depth sensor leads to better results 23, 28, 18. Approaches using this sensor can be classified into two categories: static and dynamic. Static methods treat static gestures that are represented by individual movements and then by a single image; however, the dynamic approaches deal with dynamic gestures represented by image sequences.
This paper focuses only on the static hand gestures. It also proposes and evaluates a new approach for the recognition of hand gestures of the 23 static letters of the French alphabet.
In vision-based hand gesture recognition, the key factor is the accurate and fast hand tracking and segmentation. This challenge is very difficult to achieve due to the complex backgrounds and illumination variations especially when a standard camera is used.
Our system aims at achieving fast and accurate hand gesture recognition based on the depth Map captured by a Kinect camera.
Many steps are performed to achieve our proposed system as illustrated in Figure 1.

The remaining part of this paper is organized as follows: Section two presentes the related studies about hand gesture recognition before describing the hand localization process in section three. Section four, however, introduces a new technique of image segmentation to remove the complex background and noise from the hand image. In section five different new descriptors for hand gesture recognition are proposed. These are classified in two categories : 2D descriptors and 3D descriptors extracted from depth information. Section six, describes the performed tests on two datasets, by evaluating the relevance of the proposed system and comparing it to the previous studies in terms of classification rate. The paper conclusion as well as some potential future studies are presented in the last section.
2 Related Works
Several methods have been developed for hand gesture recognition. These can be classified into many categories. The first one is based on glove-analysis 13, used to control a virtual actor, describe and manipulate objects on computer screens 1, 2 or even recognize the sign language 5.
Although these approaches are not complex and intuitive, they still remain expensive.
The second category is the vision-based analysis, which relies on hand gesture acquisition with camera for Human computer interaction (HCI) application or sign language recognition. These methods need to localize the hand in an image captured by a simple webcam or a Microsoft Kinect camera.
In 4, the authors developed a drawing application that provides a real-time position of a finger, by correlation to the fingertip.
In 11, they proposed deformable models by using a point-distribution model, which represents any form of the skeleton by a set of feature points and variation patterns that describe the movements of these points. This model is made from a set of training sequences by a singular value decomposition of the differences between the forms of a set of training sequence and the averaged form. Recognition is based on the model of distribution points, proposed by Martin and Crowley 22.
The system developed in 23 employs a combined RGB and depth descriptor in order to classify the hand gestures. Two interconnected modules are employed: the first detects a hand in the region of interaction and performs a user classification, and the second performs the gesture recognition.
A robust hand gesture recognition system using the Kinect sensor is built in 28. The authors also proposed a novel distance metric for a hand dissimilarity measure, called Finger-Earth Mover's Distance (FEMD).
In 18, the authors proposed a highly precise method to recognize static gestures from depth data. A multi-layer random forest (MLRF) is then trained to classify the feature vectors, which leads to the recognition of the hand signs.
In 14, the authors have proposed a new method for the American Sign Language alphabet (ASL) recognition using a low-cost depth camera. This new method uses a depth contrast feature based on per-pixel classification algorithm to segment the hand configuration. The authors used specific gloves to ensure the hand segmentation step. Then, a hierarchical mode-seeking method is developed and implemented to localize the hand joint positions under kinematic constraints. Finally, a Random Forest (RF) classifier is built to recognize the ASL signs using the joint angles.
In 20, the writers proposed a novel method for contact-less HGR using Microsoft Kinect for Xbox. Their system is can detect the presence of gestures, identify fingers, and recognize the meanings of nine gestures in a pre-defined Popular Gesture scenario.
In 30, a new superpixel-based hand gesture recognition system is proposed. This system is based on a novel superpixel earth mover's distance metric, together with Kinect depth camera, to measure the dissimilarity between the hand gestures. This measurement is not only robust to distortion and articulation, but also invariant to scaling, translation and rotation with a proper preprocessing.
In 3, the authors proposed a new approach for digit recognition based on a hand gesture analysis from RGB images. They extracted and combined a set of features modeling the hand shape with an induction graph. Their approach is invariant to scale, rotation and translation of the hand.
3 Hand Localization
Hand detection is a very important step to start the hand gesture recognition process. In fact, to identify a gesture, it is necessary to localize the hands and their characteristics in the image. We used a Kinect sensor presented in Figure 2 as an input device which captures the color image and the depth map.

The RGB image can be displayed as in all the cameras. The Kinect sensor produces 640x480 images when using 30 fps and 1280x1024 at 15 frames per second.
The Kinect can capture depth information by projecting an infrared dot pattern and its subsequent capture by an infrared camera 7. The depth information can be extremely interesting to detect shapes on the Kinect's video stream. This feature, would be used in our context to localize and get the hand shape while discarding other information.
3.1 Depth Map
The depth information is the determinant factor in our application. It indeed gives each pixel depth for the sensor. Thus, in addition to the 2D position of each pixel and its color, we also have its depth. This makes it far to search for the hands.
First of all, the depth information is converted into a gray scale image.
The key point here is therefore the Kinect's ability to give us three-dimensional information.
When the Kinect follows a person precisely, it can provide a skeleton from all the key points already detected.
To achieve better results, it is necessary that the person stand at a distance of 1.2 to 3.5 meters from the camera 7. Above these limits, the accuracy of the sensor decreases rapidly and is therefore not possible to follow the person.
As shown in Figure 3, there are 20 key points (which will be called joints) that are detected and tracked.

The depth data are stored in the form of integer arrays of 16 bits. The depth information can be recovered in 320x240 or in 80x60.
The 16 bits of each pixel are as follows:
3.2 Hand Detection from Depth Map
In our application that aims to analyze and recognize the French alphabet, we are interested only in the right hand.
Consequently, from the matrix containing the 20 key point coordinates, we get only point number 12 since it corresponds to the center of the right hand palm. The coordinate of this point is used to localize the hand position in the image.
4 Hand Segmentation
The hand segmentation step follows the hand localization to remove all the useless and annoying information like noise and background.
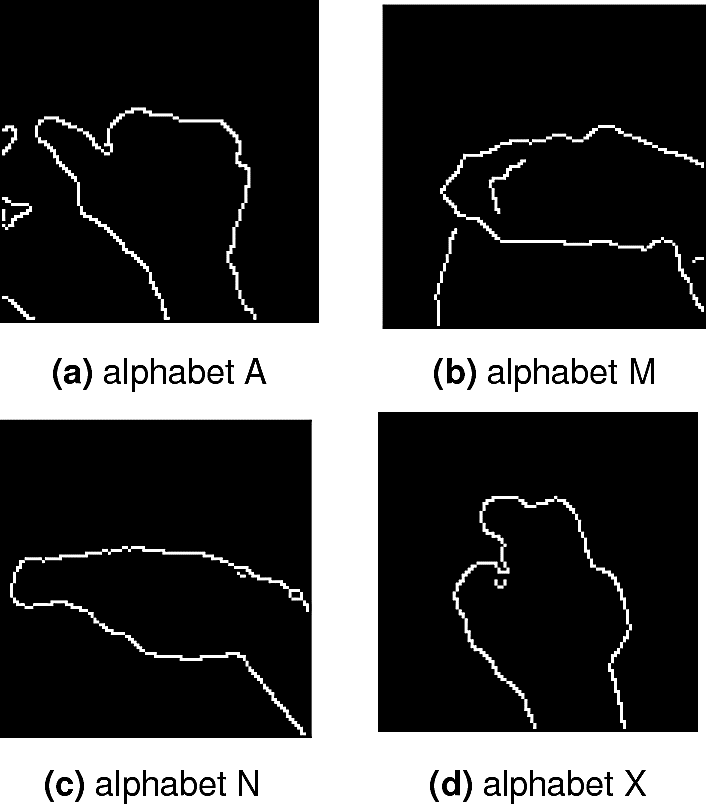
In Figure 4, we present the output images after the detection step from the depth map. It should be noted that these images can contain beside the hand, noise, background and other parts of the body.

Fig. 4 Hand detection: (A) Hand with noise, (M) Hand with body and background, (N) Hand with body and (X) Only the hand
Many approaches have been proposed in the literature to segment a hand and remove all the other regions in images. Methods based on thresholding, like that of Otsu 21 are not robust. We, then, suggest a new approach based on the edge detection considered as the most common method for detecting significant discontinuities in an image 15.
In what follows, we introduce our new approach for hand segmentation based on edge detection. Our segmentation approach steps can be stated as follows:
4.1 Edge Detection
Many edge detection methods, such as Sobel filtering, Perwit filtering and Canny operator have been proposed in the literature. The most powerful one is the Canny method 8, because it uses two different thresholds to detect both strong and weak edges. The weak edges are included only if they are connected to strong ones.
In Figure 5, we show the edge detection results using the Canny operator applied on already localized hands. It should be noted that the obtained results are not very satisfactory and many erroneous edges are detected. This might be due to the presence of noise.

In order to improve the edge detection results, we propose to eliminate the noise before the canny detection step by applying a bilateral filter which would preserve the edge and reduce the noise 9, 10, 16.
Figure 6 shows the effectiveness of the bilateral filter in reducing the noise in the image and going better results after the edge detection with the Canny method.
4.2 Edge Closing
After the edge detection step, many imprecise results, like incomplete or open contours are found. A step of contour closing is therefore necessary.
Several researchers have only used morphological operations, such as dilation and erosion to close the edges. In this paper, we introduce a new approach for closing the edges relying on both the morphology operator and many other forms of control in order to improve the results and make sure that the hand's edge is closed.
The new approach of the edge closing is presented in Algorithm 1. Figure 7 represents the hand's regions after an edge closing step using Algorithm 1.

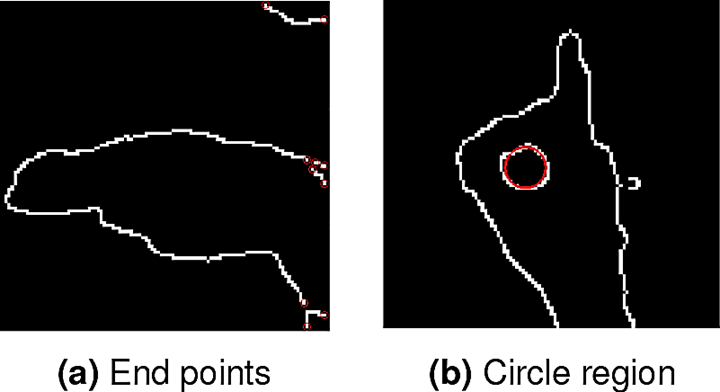

4.3 Filling the Hand Region
After closing the contours of the image, two cases can be faced:
Since the hand is the closest object to the camera, the pixels having the minimum depth value belong or are very close to the hand region. Consequently, even if there are several regions, the desired one namely the hand region is defined as the area that includes the minimum depth pixel.
We refer to the work proposed in 29 in order to fill the hand region. Since this work uses only one pixel belonging to the desired area to fill the whole region, we have to find only one pixel from the hand region.
Therefore, we start by looking for the list of pixels with the minimum depth value. For each pixel three cases are possible:
- Pixel on the hand contours: In this case pixel value=1; so, we can not fill the region 29.
- Pixel outside the hand region: Since this pixel is characterized by a minimum depth value, it is necessarily located near the contour of the hand.
- Pixel in the hand region: This pixel can be far from the contour or very close to the hand edge.

Since the pixel that has to be chosen to the fill the region step must be in the hand region and far from the contours 29, it must not have a neighborhood belonging to the contour image. We propose to apply 5*5 windows for all the pixels (having the minimum depth) to verify all the neighborhood values. The chosen pixel must have all neighborhood values equal to zero.

When a filling pixel inside the hand region is not found (all pixels are on or close to the contour region), we increment the used minimum depth value over a millimeter to have another list of pixels, and then we repeat the same search process described above.
The obtained binary image is considered as a mask to be applied on the depth image and remove all the other pixels as illustrated in Figure 8.

5 Feature Extraction
5.1 Proposed Descriptors
The proposed recognition system is based on two types of features: the first consists of 2D features representing the hand deformation in the 2D plan and describing the geometry information and the hand structure to differentiate between the hand shapes. The second, however, represents the depth information (3D features) mainly selected to represent the finger positions and palm closure.
The 2D features (hand orientation and euler number) are used by 24 but the hand dimension is modified in our approach compared to the literature to make it invariant to scale. The hand occupancy is invented in our approach.
The 3D features (the variance depth values, depth average related to the minimum value and depth average related to the centroid of the hand) are invented in our approach and have never been used in any other research.
5.2 2D Features
5.2.1 Hand Orientation
The hand orientation changes with the change of the gestures. Therefore, it can be used as a characteristic feature of the hand gesture. Since the human hand has an elliptic shape, we propose here to find the best ellipse that includes the hand. The input parameters are a set of (x, y) points (the x, y coordinates of all the hand regions), and the output is the minor and major axis, while the θ is the orientation for the best ellipse (the one that contains the majority of (x, y) input points). The former parameter is assumed as the hand orientation 3. Figure 9 gives an illustration of the ellipse including the hand region and the effectiveness of the feature in differentiating between two similar hand gestures from different classes. The θ orientation is given by the angle between the ellipse major axis and the x coordinate axis.
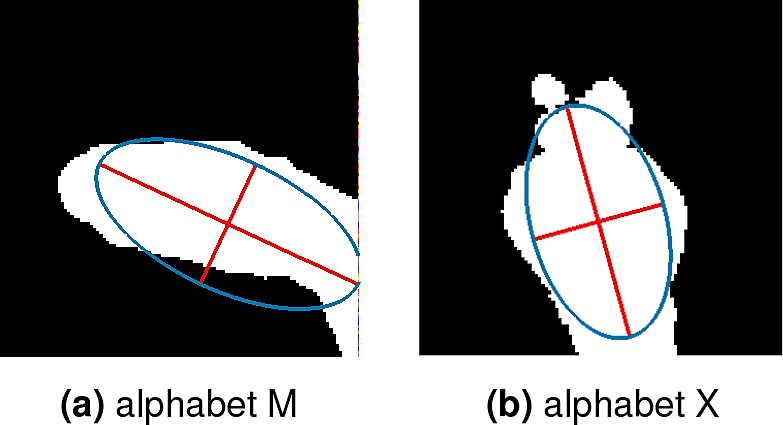
The hand orientation is considered as a gesture hand descriptor also used for hand adjustment step into the vertical direction (normalized direction). This is very important to get all the extracted features invariant to rotation.
5.2.2 Hand Dimension and Occupancy
To estimate the hand dimensions, we try to bind all the hand pixels in the rectangular area having the smallest perimeter, as presented in Figure 10.
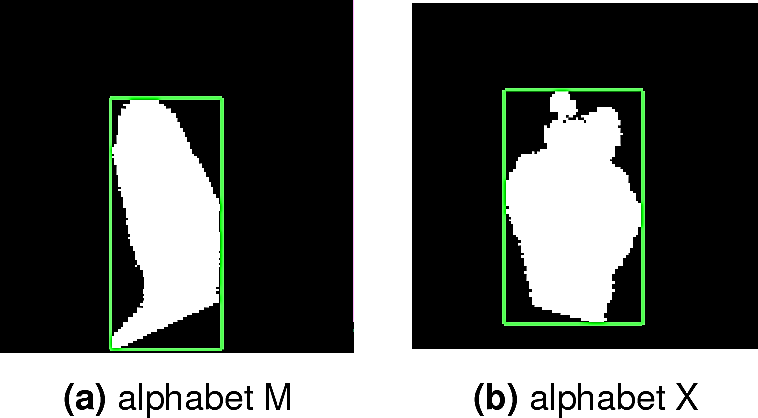
If (l, w) are respectively the length and width of the rectangle, two hand descriptors can be proposed. The first one noted Ddim is given by equation 1:
The second one noted Doccupancy is defined by equation 2 as follows:
where N is the number of all the hand pixels (white pixels).
These two features are invariant to scale and orientation.
5.2.3 Euler Number
The Euler number can describe the structure of the hand and give its characteristic topological. The Euler number E represents the total number of objects in the image (in our case there is only the hand object) minus the total number of holes in those objects H 17, 25:
5.3 Features Based on Depth Information: 3D Features
5.3.1 The Variance Depth Value
The variance depth value Vdepth is obtained by the difference between the maximum value of depth depthmax and the minimum depthmin:
The utility of the global feature is to know the palm closure and hand orientation from Z axis.
5.3.2 Depth Average
We compute two features based on depth average, the first one Aυgc is related to centroid depth information and the second one Aυgmin is related to the minimum depth information. They are defined in equations 5 and 6:
where Hdepth (X, Y) represents the depth of the hand pixel with coordinates (X, Y), (Xc , Yc) are the coordinates of the centroid and N the total number of pixels (Xi , Yj) in the hand region:
where Hdepth(X, Y) represents the depth of the hand pixel with coordinates (X, Y), (Xmin, Ymin) are the coordinate of the pixel having the minimum depth value and N the total number of pixels (Xi, Yj) in the hand region.
6 Experimental Results
6.1 Evaluation on our Dataset
In this section, we evaluate our approach and all the proposed descriptors by creating a new dataset based on the French sign language alphabet which contains 2300 gesture images from the 23 static letters of the French alphabet. Figure 11 shows the French sign language alphabet.
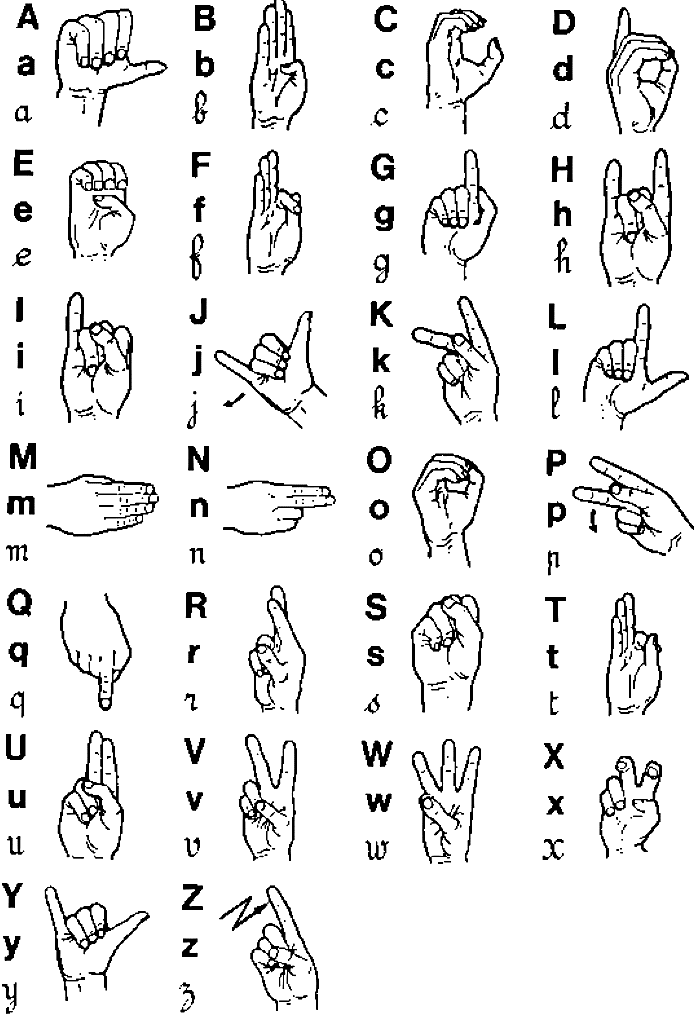
These images, which contain only the depth information of hand gesture, are captured in different backgrounds and angle views.
This dataset is divided randomly ten times into a set of training images (50%) and a set of test images (the remaining 50%). In the literature, there are several techniques of supervised learning. We evaluate our system with the random forest techniques6.
The classification accuracy is used in order to evaluate the performance of our system and the proposed descriptors.
6.1.1 Comparative Study between Descriptors
To compare the representative power of the proposed descriptors, we test the performance of each one in terms of classification accuracy as represented in Figure 12.
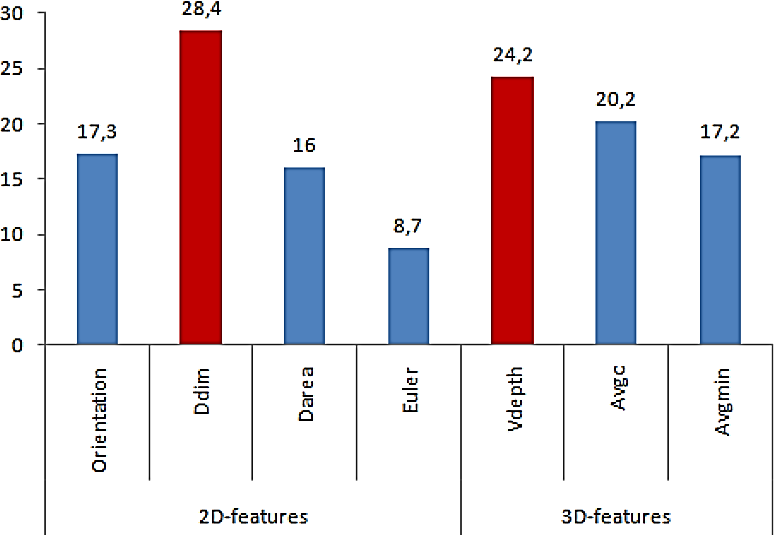
The results show that the dimension descriptor, which is a 2D-type feature, and the variance depth descriptor which is a 3D-type feature present the highest classification accuracy.
We note that the 3D descriptor based on depth information ranks second, which proves that it represents a very suitable feature in terms of gesture classification. This shows the importance of using the Kinect camera and depth information in our study.
6.1.2 Performance of the Proposed System
In order to achieve better accuracy, we take advantage of two types of features to design a new one. The proposed descriptor combines all the proposed descriptors by means of superposition.
Classification accuracy values presented in Table 1 confirm this result. In fact, when using 2D descriptors only, the classification accuracy reaches 77.8%. However, it climbs to (93.7%) when combining 3D and 2D descriptors.
Table 1 Importance of depth features for classification
| Descriptor | Accuracy rate |
| Geometry, 2D | 77.8 |
| All (2D-3D) | 93.7 |
In Table 2, we present the precision rate and the recall rate for the 23 different gestures in the French sign language alphabet.
Table 2 Performance of the proposed system
| Class | Precision | Recall | Class | Precision | Recall |
| A | 99.3 | 97.0 | N | 97.7 | 97.3 |
| B | 90.9 | 96.0 | O | 99.0 | 98.3 |
| C | 96.8 | 99.7 | Q | 97.6 | 96.0 |
| D | 99.0 | 97.0 | R | 92.8 | 90.7 |
| E | 94.6 | 92.7 | S | 90.0 | 93.3 |
| F | 93.8 | 90.7 | T | 89.9 | 91.7 |
| G | 97.4 | 98.0 | U | 94.2 | 87.0 |
| H | 93.3 | 92.3 | V | 88.8 | 84.7 |
| I | 77.7 | 87.0 | W | 85.9 | 81.0 |
| K | 98.6 | 96.7 | X | 88.5 | 94.7 |
| L | 99.3 | 98.3 | Y | 98.3 | 96.0 |
| M | 93.7 | 98.3 | - | - | - |
6.2 Evaluation on a Public Dataset and Comparison with Existing Work
In order to validate our approach, a comparative study with previous methods on a public dataset is performed.
Our approach is compared to 26 who developed an application to recognize different hand gestures representing the alphabet of the American sign language. This work uses the Kinect camera for hand detection and tracking. To recognize the different gestures, 26 used descriptors based on the Gabor filter 12.
We use the database provided by 26 which contains 500 samples for each of the 24 signs (American alphabet without "J" and "Z") recorded by 5 different people. The dataset has two types of images, "RGB" and "Depth", captured in different backgrounds and view angles.
Since our approach is based on depth image, we use only depth images (60.000 images) from the dataset to evaluate our system and compare it to the work proposed in 26which uses the same database (Surrey University dataset), the same protocol test (the 50% of data are used for training and the rest for testing) and the same classifier (the random forest 6). Proposed descriptors in this work are based on Gabor filters.
Our system can reach 76% of accuracy rate, while 26 attained only 69%. These results shown in Table 3 highlight the robustness of our proposed approach, specially, the hand segmentation and the feature extraction steps.
Table 4 shows the precision rate for each sign and for the two approaches.
Table 4 Precision rate of our approach and that of 26 for each American alphabet sign language
| Class | Our | 26 | Class | Our | 26 |
| A | 81.8 | 76.0 | N | 64.2 | 66.0 |
| B | 88.7 | 91.0 | O | 73.4 | 42.0 |
| C | 89.9 | 67.0 | P | 75.5 | 66.0 |
| D | 81.1 | 80.0 | Q | 83.6 | 65.0 |
| E | 71.2 | 88.0 | R | 71.3 | 48.0 |
| F | 78.6 | 62.5 | S | 64.1 | 59.0 |
| G | 85.2 | 65.5 | T | 60.2 | 35.0 |
| H | 88.1 | 65.0 | U | 66.5 | 86.0 |
| I | 76.2 | 60.0 | V | 67.0 | 66.0 |
| K | 73.6 | 64.0 | W | 62.8 | 81.0 |
| L | 91.2 | 98.0 | X | 76.5 | 68.0 |
| M | 61.4 | 58.0 | Y | 89.9 | 90.5 |
7 Conclusion and Future Works
In this paper, we presented a new approach of hand gesture recognition based on a depth map captured by a Kinect camera. Our approach requires many adjustments and removal steps to segment the hand and avoid noisy information. On the other hand, we proposed new descriptors based on the depth information and showed their relevance to our proposed system. This reflects the importance of using a Microsoft camera Kinect which provides depth information.
Our experimental results show that the approach is effective as its performance reached over 93% when applied on the alphabet French sign dataset. A comparative study enabled us to show that our approach outperforms the existing ones in the state of the art.
Our future focus will be on the use of "RGB Image" captured by the Kinect camera in the segmentation step to improve the result of hand gesture recognition. We also think about making a 3D-model that will be used in the hand tracking in order to recognize dynamic gestures.

