











 text new page (beta)
text new page (beta) English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1 Introduction
Chinese characters are logograms used in the writing of Chinese and some other Asian languages. In Standard Chinese, they are called Hanzi (simplified Chinese: 汉字)1. They have been adapted to write a number of other languages including Japanese, Vietnamese, and et.al. Modern Chinese has many homophones; thus the same spoken syllable may be represented by many characters, depending on meaning. Cognates in the several varieties of Chinese are generally written with the same character. They typically have similar meaning, but often quite different pronunciations 1.
For beginners, the very first step to learn a Chinese character is to learn its pronunciation and Bishun (order of strokes). When he wants to learn the pronunciation of Chinese characters which are very complex (“饕”, “霹”, “犇”) or sharing the same spoken syllable with others (“阿(a)姨”, “东阿(e)”, “西藏(zang)”, “储藏(cang)”), he may feel very puzzled.
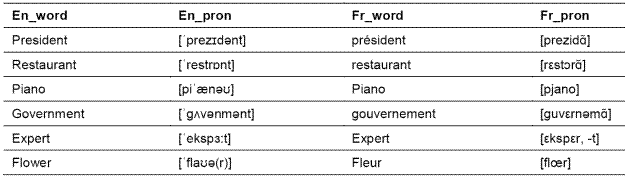
If you are a native English speaker, and you know nothing about languages (which written in Latin alphabet) like French, you can also read some French words 2. Why? That’s because English and French share most characters, even some words, and the same Latin character usually has the same/similar pronunciation. For example, given some French words “président”, “restaurant”, “piano”, “gouvernement”, “expert”, “fleur”, we can transfer these words into phonetic symbols by English and French transformation rules (Table 1), respectively.
In this paper, we try to predict the pronunciation of Chinese characters based on a machine translation model 3,4,5. Here, we follow one principle: for characters, same characters may have same/similar pronunciation; for character sequence, same/similar character sequence may have same/similar pronunciation. In Chinese learning, we first convert one single Chinese character into a Bihua sequence, and consider the pronunciation prediction as a machine translation problem. We introduced two important features for the pronunciation prediction model: (1) according to local Bishun language modeling, we obtain the local language model score (LLM score); (2) for polyphones in Chinese, we consider global language model score (GLM score) between Chinese characters, also based on Bishun. Moreover, some error tolerant strategies also proposed to make the model more practically.
Section 2 presents some previous work related to our topic. The details of Chinese pronunciation prediction model are described in section 3. We evaluate our model in several experiment sets in section 4. In section 5, we give our conclusions and future directions.
2 Related Work
In the field of Chinese pronunciation prediction, 6 proposed a system to foreigners to speak a language they don’t know it, this system use a phonetic spelling in the foreigner’s own orthography to represent the input text, 7 presented a generative model based on existing dialect pronunciation data plus medieval rime books to discover phonological patterns that exist in multiple dialects. Our work mainly inspired by the framework of statistical machine translation 3,4; parameters of the pronunciation prediction model are derived from the analysis of “bilingual” (which means Bishun, Pinyin in our paper) corpus8,9.
To the best of our knowledge, this work is the first time that exploiting the orthography of Chinese to predict its pronunciation.
3 Methodology
In this section, we first describe the representation of Chinese characters in our model; then, we present two language model features used in our model and details of the translation model based Chinese pronunciation prediction approach; finally, we introduce some error tolerant methods to optimize the pronunciation prediction model.
3.1 Representation of Chinese Characters by Bishun
For convenience, we always wrote Chinese words as Pinyin sequence in English research papers. In our method, we introduce another form to represent Chinese characters: Bishun. Bishun, also known as the strokes order (how to write a Chinese character). There are five basic strokes (Bihua, CJKV character) in Chinese, as present in Table 2.

Here, we first convert each Chinese character into Bishun. For convenience, we assign each stroke (Table 2) a number (1-5). Accordingly, Chinese characters can be represented as shown in Table 3.

3.2 Translation Model-based Chinese Pronunciation Prediction Model
With method presented above, we can transfer Chinese characters into Bishuns, and consider the Chinese character pronunciation prediction as a machine translation problem.
Statistical machine translation (SMT for short) is a machine translation paradigm where translation results are generated on the basis of statistical translation models whose parameters are derived from the statistical analysis of parallel data. We use the phrase-based translation model as the baseline in our pronunciation prediction model.
In this part, we define the phrase-based translation model formally. The phrase-based translation model is based on the noisy channel model. To train the prediction model, we reformulate the translation probability for translating a Bihua sequence f 𝐵 into pinyin sequence 𝑒 𝑃 according to Bayes rule 3,4 as:
Word Alignment
The alignment models used in the pronunciation prediction model are trained based on the IBM models 8. The IBM alignment models are instances of the EM (Expectation-Maximization) algorithm 14,15,16. The parameters of alignment models are guessed then to apply EM algorithm iteratively so as to approach a local maximum of the likelihood of a particular set of sequence pairs (Bihua sequence and Pinyin sequence).
E-step: the translation probabilities within each sequence are computed;
M-step: they are accumulated to global translation probabilities
Model Training
Training of the machine translation is starting from extract phrase table and reordering rule table according to word alignment matrix which obtained from the word alignment stage. In our pronunciation prediction task, the alignment points in a sequence pairs are in order. In detail, we collect each phrase pair from the sequence pair using the word alignment because its characters match up consistently.
We define the consistent with a word alignment as follow: for a phrase pair (𝑒, 𝑓)
consistent with an alignment matrix WAM 17,18, if all characters
3.3 Language Model Features
Statistical language models 10,11 have been designed to assign probabilities to strings of words (or tokens), which are widely used in speech recognition, machine translation, part-of-speech (POS) tagging, intelligent input method and text to speech system. In this paper, we obtain two important language model features to constraint the output of the pronunciation prediction model’s decoding stage. We use n-gram language models 12,13 in our model, which are trained on unlabeled text.
Let
Local Language Model Feature
A Chinese character usually consists of several Bihua. So, when training the pronunciation prediction model, we first consider the very basic feature - the pinyin language model of Chinese character itself, called local language model feature (LLM feature for short). According to the definition of language model, we formulate the LLM feature as follows:
Let
Here, we use 2-gram language model to denote the language model of a Chinese character’s pinyin sequence (LLM).
Global Language Model Feature
There are many polyphone characters in Chinese. If we only use LLM features described above, it is difficult to distinguish them. To alleviate this problem, we introduce a global language model feature, which means that when predict the pronunciation of a Chinese character, we not only evaluate the score of it, but also consider its context information (global language model feature, GLM feature for short). In this paper, we define the context information of a Chinese character as the pronunciation of its previous and next n characters. The GLM feature can be formulated as (3):
Let
LLM + GLM
The optimized language model can be formulated as follows:
To integrate the LLM and GLM into the machine translation model, we optimize the basic formula of the phrase-based model as follows:
The translation probability
3.3 Error Tolerant Strategies
Another most important contribution of this paper is the error tolerant strategies in pronunciation prediction. For a beginner, it is difficult to remember the Bishun of Chinese characters correctly. Some mistakes may make when converts a Chinese character into Bishun. Or, the Chinese learner may not know the correct pronunciation of a character, but he known the pronunciations of some parts. We will introduce the details of the strategy in this section.
Conversion Error
When errors occurred during convert, a correction model in our pronunciation prediction framework will be triggered. The conversion error means when a Chinese learner wants to predict the pronunciation of a Chinese character according our model, Bihua lost, Bihua substitution, Bihua insertion may occur. These may reduce the performance of our prediction model. In this paper, we consider the correction of these errors as calculate the similarity of strings.
In the correction system, we use edit distance algorithm to obtain the most similar Chinese character according to the given Bihua sequence. Edit distance2 is an algorithm of quantifying how dissimilar two strings (in our paper, mean the input Bihua sequence and a standard Chinese character Bihua sequence) are to one another by counting the minimum number of operations required to transform one string into the other. These operations include: insertion, deletion and substitution.
LM (Language Model) Based Stroke Order Decision
For Chinese learners, they can remember some basic strokes at first, but it is difficult for them to write all Chinese characters in order (the traditional way). Given an input Bihua sequence, we obtain the stroke order probability based on language model. We follow some general rules3:
Horizontal before vertical;
Diagonals right-to-left before diagonals left-to-right;
Dots and minor strokes last.
In fact, there are more stroke order rules. In this paper, we just consider these three basics. Here, we reformulate these rules as
The
Local Pronunciation to Global
In Chinese, there exist many characters that include other Chinese characters, such as “清”(“青”), “歌”(“哥”), “都”(“者”), “信”(“言”). For characters like “清” if the Chinese learner already know the pronunciation of “青”, he could pronounce “清” correctly. But it is not always work when he know the pronunciation of “言” and wants to pronounce “信”. Although not all Chinese characters like “清”(“青”), we can derive some features from these characters to predict the pronunciation of a given Chinese character (“清”) from its component (“青”).
In this paper, we define the local pronunciation to global feature (LPG) as in (8):
Here,
We use the LPG as an important feature in decoding part of the Chinese pronunciation prediction model. With the LPG feature, characters like “清” can be assigned high probability similar as its component.
4 Experiments
4.1 Data and Setup
Corpus used in this paper can be divided into two kinds, one is a Chinese dictionary4 crawled online, which include much information about a Chinese character, such as its pronunciation (Pinyin), strokes (Bihua), strokes order (Bishun) and et.al, we convert a Chinese character into Bishun according to rules defined in this dictionary. Another kind of corpus is used to train and test the pronunciation prediction model, these sentences are sampled from People’s Daily corpus; we divided the corpus into two data sets: training set and test set. Size of these corpora is listed is presented in Tables 4 and 5.


We use the open source machine translation toolkits Moses5, 19 as the baseline to train the pronunciation prediction model. GIZA++6 with the heuristic grow-diag-final-and was used to obtain the word alignments. We use the standard language models provided by the toolkits SRILM7, 20. For validate our method, we also compare the traditional model with several optimized pronunciation prediction models.
In error tolerant experiments, we rebuild the test set according to different task. For example, when validate our method use to overcome the conversion error, when first define a random function to select an index and change, or delete a stroke in the input text.
Although the most commonly used metric to evaluate the performance of machine translation is BLEU (Bilingual Evaluation Understudy), to estimate the pronunciation prediction models effectively, the experimental results are evaluated with P (Precision), R (Recall) and F1. We introduce details of these three metrics as follows:
R is the number of correct positive results (A) divided by the number of positive results (A + C) that should have been returned, and P is the number of correct positive results (A) divided by the number of all positive results (A + B). The F score can be interpreted as a weighted average of the R and P.
4.2 Results
*Experiments with the symbol “#” are results of standard inputs.
*Experiments with the symbol “☆” are results of initial inputs (often with errors), experiments with the symbol “★” are results of corrected inputs with optimized methods.
4.3 Analysis and Discussion
Our first evaluation (Table 6) is on the baseline model (Translation model based Chinese Pronunciation Prediction, TMCPP), which include two results TMCPP_WO (without context information) and TMCPP_W (with context information). Results shown that the model with context information is outperformed the non-context model significantly. Train the pronunciation prediction model based on context information has a powerful ability to distinguish the pronunciation from several complex situations.

Table 7 shown results in conversion error correction experiment. In this experiment, we first generate some errors occurred in Chinese character - Bishun conversion according a random function. We use the baseline model to predict the pronunciation of the input text (with errors); the performances of TMCPP_WO_I and TMCPP_W_I are really low compared with the baselines (TMCPP_WO and TMCPP_W). When the input texts were optimized by the edit distance algorithm, the performances are much better, but still lower than the baseline. However, it is shown the effectiveness of our correction method.
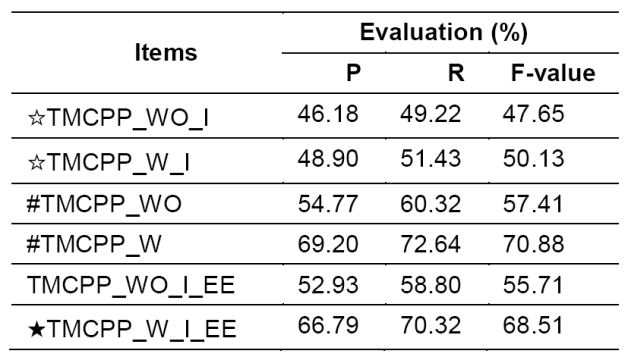
Another part of the error tolerant mechanism is disorder of strokes. Like the conversion error correction experiment, we also generate some stroke disorder errors in the input text (Table 8). Compared with the baseline, the results of the disorder input (TMCPP_WO_I’ and TMCPP_W_I’) are much lower, which is because our model trained, based on “bilingual” corpus, and the output of our model is strictly constraint by the language model. With the LM (Language Model) Based Stroke Order Decision operation described in section 3.4, some disorder errors occurred in input text can be corrected before decoding. Therefore, experimental results on the corrected input text (TMCPP_WO_I’_SO and TMCPP_W_I’_SO) are outperformed the initial disorder experimental results. In Table 7 and Table 8, we validate the error tolerant ability in our pronunciation prediction framework. Although we just generate some errors automatically, this is a very important step that makes our framework practically.

In Table 9, we have shown the powerful of our model that predict the pronunciation of Chinese character according to its local pronunciation. We extract many richness features to make our pronunciation prediction model better. Experimental results shown that with the LPG features the optimized model is outperformed the baseline, and achieved the best performance.

5 Conclusions and Future Directions
In this paper, we proposed a novel approach to predict pronunciation of Chinese characters. Our method based on statistical machine translation framework, and we convert each Chinese character into Bishun firstly. To adapt our task, we introduced two important language model features to improve the performance of our prediction model: (I) predict the pronunciation of a Chinese character according to its local Bishun (LLM); (II) if a Chinese character has more than one pronunciation (polyphones in Chinese), we also extract disambiguation information according its context (previous n characters / next n characters) (GLM). We presented three error tolerant strategies to improve the flexibility of our model. Experimental results shown that, the pronunciation of Chinese characters can be predicted effectively with our approach.
In our future work, we will try to find an optimized knowledge representation model to further improve the accuracy of Chinese character pronunciation prediction model.

