











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
English has been a dominating language of the Web for long but with the rising popularity of the Web, native languages have also found their places - now the Web has substantial content in multiple languages. This prompted the task of Cross Language Information Retrieval (CLIR), where the language of the documents being queried is different from the query language. One of the main motivations behind CLIR is to gather a lot of knowledge from a variety of knowledge bases which are in the form of documents in various languages, helping a diverse set of users, who can provide the queries in the language of their choice. Intuitively, Cross Language Information Retrieval is harder than Monolingual Information Retrieval because it needs to cross the language boundaries either by translating the query or by translating the document or by translating both the query and the document to a third language. There are many techniques to implement CLIR. One way to translate the query is a token-to-token translation based approach that uses a machine readable dictionary1,10,18. Another is to employ Statistical Machine Translation (SMT) systems21,23,24 to translate the query. SMT is a machine translation technique that leverages statistical models whose parameters are derived using parallel bilingual corpora. Other methods for query translation include online translation services like Google Translate8 or by using large scale multilingual resources like Wikipedia 7.
Most of these approaches require either a full fledged dictionary, an aligned corpora or a machine translation system, which may not be guaranteed for resource scarce languages. In this paper, we attempt to solve the problem in a scenario when the monolingual corpus is available in both the languages, but may not be aligned. Additionally, a few word pair translations between the two languages are required, but these need not be exhaustive. We study the effectiveness of word embeddings based methods in this scenario.
In word embeddings, words from the vocabulary are mapped to vectors of real numbers in a low dimensional space; and these vectors are called as embeddings. It has been seen that in the distributed space defined by the vector dimensions, Word embedding is the collective name for a set of language modeling and feature learning techniques in natural language processing where words from the vocabulary (and possibly phrases thereof) are relative to the vocabulary size(“continuous space") syntactically and semantically similar words fall closer to each other. Given a training corpus, word embeddings are able to generalize well over words that occur less frequently as well. In this paper we try to explore how the usage of word embeddings can affect the retrieval performance in a CLIR based system. To the best of our knowledge, no such approach using comparable corpora has been tried out for the CLIR tasks.
Handling Out-Of-Vocabulary (OOV) terms that are not named entities is a major technical difficulty in CLIR task. For Hindi words that are actually part of the English vocabulary, for example, ‘kaiMsara’1 (meaning, cancer), ‘aspataala’ (meaning, hospital), dictionary and corpus based methods had to resort to “transliteration", but the embedding based method captured their contextual cues and was able to find related words in English. Words brought out as translations for ‘kaiMsara’ were ‘cancer’,‘disease’,‘leukemia’, for ‘aspataala’ the words that came out as translations were ‘hospital’,‘doctor’,‘ambulance’. We perform transliterations only to handle the named entities.
We also propose and compare various techniques for aggregating the target translations using multiple query terms. We find that instead of aggregating the query vector at the source side, if we compute the similarity scores for each query term separately and then aggregate the resulting vectors, it provides better performance. Our proposed word embedding based approach and the hybrid approach (combined with dictionary) could achieve 88% and 92% of the Mean Average Precision (MAP) as reported by the English monolingual baseline, respectively. When combined with translations obtained from Google Translate, it was able to beat the English monolingual MAP by 15%. The methods also showed improvements of 29%, 34% and 68% over2 , a state-of-the-art corpus based approach.
2 Related Work
2.1 Cross-Language Information Retrieval
People have tried viewing Cross-Language Information Retrieval (CLIR) from various aspects. To start with,18 uses dictionary based translation techniques for Information Retrieval. They use two dictionaries, one, in which general translation of a query term is present and the other, in which, domain-specific translation of the query term is present.12 discusses the key issues in dictionary-based CLIR. They have shown that query expansion effects are sensitive to the presence of orthographic cognates and develop a unified framework for term selection and term translation.13 perform CLIR by computing Latent Semantic Indexing on the term-document matrix obtained from a parallel corpora. After reducing the rank, the queries and the documents are projected to a lower dimensional space.
Statistical Machine Translation (SMT) techniques and its improvements have also been tried out 20,21,24. 11uses SMT for CLIR between Indian languages. They use a word alignment table that was learnt using an SMT on parallel sentences to translate source language query to target language query. In 21, the SMT technique was trained to produce a weighted list of alternatives for query translation.
Transliteration based models have also been looked into. 25 uses transliteration of the Out-Of-Vocabulary (OOV) terms. They treat a query and a document as comparable and for each word in the query and each word in the document, they find out a transliteration similarity value. If this value is above a particular threshold, then the word is treated as a translation of the source query word. They iterate through this process, working on relevant documents retrieved in each iteration. 2 uses a simple rule based transliteration approach for converting OOV Hindi terms to English and then uses a pageRank based algorithm to resolve between multiple dictionary-translations and transliterations.
7uses Wikipedia concepts along with Google translate to translate queries. The Wikipedia concepts are mined using cross-language links and redirects and a translation table is built. Translations from Google are then expanded using these concept mappings. Explicit Semantic Analysis (ESA) is a method to represent documents in the Wikipedia article space as vectors whose components represent its association with the Wikipedia articles. 22 uses it in CLIR along with a mapping function that uses cross-lingual links to link documents in the two languages that talk about the same topic. Both the queries and the documents are mapped to this ESA space, where the retrieval is performed.
5 leverages BabelNet, a multilingual semantic network. They build a basic vector represenation of each term in a document and a knowledge graph for every document using BabelNet and interpolate them in order to find the knowledge-based document similarity measure.
Similarity Learning via Siamese Neural Network 27 trains two identical networks concurrently in which the input layer corresponds to the original term vector and the output layer is the projected concept vector. The model is trained by minimizing the loss of the similarity scores of the output vectors, given pairs of raw term-vectors and their labels (similar or not).
8 uses online translation services, Google and Bing, to translate queries from source language to target language. They conclude that no single perfect SMT or online translation service exists, but for each query one performs better than the others.
2.2 Word Embedding
14 proposed a neural architecture that learns word representations by predicting neighbouring words. There are two main methods by which the distributed word representations can be learnt. One is the Continuous Bag-of-Words (CBOW) model that combines the representations of the surrounding words to predict the word in the middle. The second is the Skip-gram model that predicts the context of the target word in the same sentence. GloVe or Global Vectors 17 is also an unsupervised algorithm for learning word representations. The training objective of GloVe is to learn word vectors such that for any pair, the dot product equals the log of the words’ probability of co-occurrence. They use global matrix factorization and local context window methods to build global vectors.
Word embedding based methods have been utilized in many different tasks, such as word similarity4,9,19, cross lingual dependency parsing9, finding semantic and syntactic relations4, finding morphological tags3 , identifying POS and translation equivalence classes6 and in analogical reasoning19 .15 uses the word vectors to translate between languages. Once the word vectors of the two languages have been obtained, it builds a translation matrix using stochastic gradient descent version of linear regression that transforms the source language word vectors to the target language space.
2.3 Word Embedding based CLIR
26 leverages document aligned bilingual corpora for learning embeddings of words from both the languages. Given a document d in a source language and its comparable document aligned equivalent t in the target language, they merge and randomly shuffle the documents d and t. They train this “pseudo-bilingual" document using word2vec. To get the document and query representations, they treat them as bag-of-words and combine the vectors of each word to obtain the representations of query and document. Between a query vector and a document vector, they compute the cosine similarity score and rank the documents according to this metric.
In this paper, we attempt to perform CLIR from Hindi to English using translations obtained from word embedding based methods. The main advantage of word embeddings is that it does not suffer from data sparsity problems. Given a training corpus, they are able to generalize well over words that occur less frequently. Additionally, they are also computationally efficient 14.
3 Proposed Framework
We use the query translation approach towards Hindi to English CLIR, that is, we translate Hindi queries to English and perform monolingual information retrieval on English documents. Towards query translation, we first obtain word embeddings for both the source and target languages using corpus for individual languages. Then, we learn a projection function from source to target word embeddings using aligned word pairs, as obtained from the dictionary. Finally, we employ various methods for query translations: one in which every query term in the source language has k best translations in the target language. The second, in which we aggregate the query word vectors into a single vector that represents the query as a whole and then obtain k best translations for the query itself.
3.1 Dataset
We have used the FIRE (Forum for Information Retrieval Evaluation, developed as a South-Asian counterpart of CLEF, TREC, NTCIR) 2012 and 2008 datasets obtained from 2. The FIRE 2012 corpus contains 392,577 English documents (from the newspapers - ‘The Telegraph’ and ‘BDNews 24’) and 367,429 Hindi documents (from the newspapers - ‘Amar Ujala’ and ‘Navbharat Times’). For FIRE 2008, we used the same number of English documents3 and 95,215 Hindi documents (from the Hindi newspaper ‘Dainik Jagran’). The corpora are comparable but not aligned.
The queries for the CLIR task of FIRE were ranging from topics 176-225 and 26-75 for 2012 and 2008, respectively. We use the title field for the experiments. The English-Hindi dictionary is obtained from http://ltrc.iiit.ac.in/onlineServices/Dictionaries/Dict_Frame.html. It also contains translations that were multi-word. We exclude these translation pairs for our experiments. We obtain the stopword list from http://www.ranks.nl/stopwords/hindi and English Named-Entity Recognizer from http://nlp.stanford.edu/software/CRF-NER.shtml.
Next, we discuss in detail various steps in our framework.
3.2 Obtaining Word Embeddings for the Source and Target Languages
We use word2vec introduced by 14. We train the word2vec package4 for both the monolingual datasets of English and Hindi. We use the CBOW model with a window size of 5 and output vector of 200 dimensions with other default parameters set.
3.3 Learning the Projection of Word Embeddings from the Source to the Target Language Space
We use linear regression to learn a projection from the source to the target language space, similar to an approach used by 15. The idea is as follows: Given a translation dictionary, we extract the word embeddings of the translation pair
After obtaining the translation matrix W using linear regression, embeddings for each word in Hindi (
3.4 Query Translation Process
Given a query Q and its terms
-. Word embedding (WE) to translate each query term independently: In this approach, once we get the word vector of each query term projected in the target language (v), we compute the cosine similarity between the vector embedding of each English word and 𝑣 and pick the k best translations for this query term. An example of a query and its 3 best translations is as follows:
-. Query in Hindi: 2008 guvaahaaTii bama visphoTa se xati
-. Meaning in English: Loss due to 2008 Guwahati explosions
-. The translations of the query terms are given in Table. 1. 2008 and guvaahaaTii are treated as Named Entities (details in Section 3.5) and hence have one translation each. We see that the WE method gives related words for each query term. We add the translations obtained independently from each query term to obtain the final translation but each term is weighted uniformly.
-.

-. WE weighted: Assigning weights to query words is necessary to distinguish between words that are important in a query from words that are not. In this approach, we proportionally distribute the weights according to the similarity score for each translated word with the query word(s). We then normalize the translated query so that the weights for all translations terms add up to 1.
-.
Combining Similarity Vectors for Translations (SIM Vec): In this approach, instead of treating each query term independently, we aggregate the results by combining results from each query term. One possible way is to combine the vector components at the source5. Instead, we first map each query term to the target space, then compute similarity values for each query term with the target words, and combine these similarity values. Thus, for a query word
-.
Table 2 Example to illustrate SIM Vec. The table shows Cosine Similarity Values between the Hindi word khela (which means ‘game’) with other English words
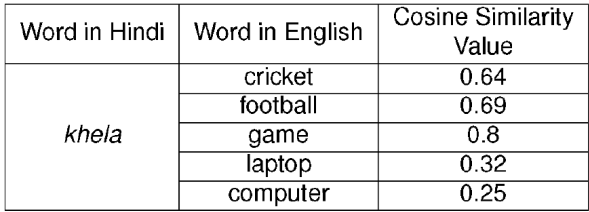
-.
Now, once we obtain such vectors for each query term, these vector components are merged using the summation or the maximum function. The idea behind using the ‘summation’ function is to find which words in the target language (English) vocabulary is the most similar when there is a contribution by all the source language query terms. The ‘maximum’ function provides knowledge as to which word in the target language vocabulary is maximally correlated to any of the source language query terms. The formula for finding the resultant query vector (
-.
-.
-. From the resultant vector, we extract the top k target language vocabulary words with the highest scores.
3.5 Transliteration of Named Entities
The source language query also contains named entities, which may not be present in the vocabulary. Since no Named-Entity Recognition (NER) tool is available for Hindi, we resort to the transliteration based process. For each Hindi character, we construct a table of its possible transliterations. For example, the first consonant in Hindi ka has 3 possible transliterations in English - ka, qa, ca. We apply several language specific rules - a consonant, for instance ka in Hindi can have two forms, one that is succeeded by a silent a, i.e., ka and another that is not, i.e., k. The second case applies when it is succeeded by a vowel or another consonant in conjunction (also known as yuktakshar). For each transliteration of an OOV Hindi query word h and for each word 𝑒 in the list of words returned as named entities in English language, we apply the Minimum Edit Distance algorithm between h and e. We then take the word with the least edit distance. Our transliteration concept is based on 2 and gives quite a satisfactory result, with an accuracy of 90%.
4 Experiments
We used Apache Solr version 4.1 as the monolingual retrieval engine. The similarity score for the query and the documents was the default TF-IDF Similarity6. The human relevance judgments were available from FIRE. Each query had about 500 documents that were manually judged as relevant (1) or non-relevant (0). We then used the trec-eval tool 7 for finding the Precision at 5 and 10 (P5 and P10) and the Mean Average Precision (MAP).
4.1 Baselines
We use the following baselines for comparison. English Monolingual corresponds to the retrieval performance of the target language (English) queries supplied by FIRE. Dictionary is the dictionary based method where the query translations have been obtained from the dictionary. For words that contain multiple translations, we include all of them. Translations with multi-words are not considered. Named entities are handled as described in Section 3.5. We also use the method proposed by Chinnakotla et al. 2 as a baseline since they participated in the FIRE task16 8. Finally, Google Translate is also used as a baseline, where the Hindi query is translated using Google Translate to English.
Results for these baselines are reported in Table 3. 2 shows improvements over the dictionary since the OOV terms are transliterated and multiple dictionary translations are disambiguated using the contextual cues from the corpus, however it is not able to perform better than the monolingual baseline. Google Translate9 outperforms the monolingual baselines.

4.2 Proposed Word Embeddings based Approaches
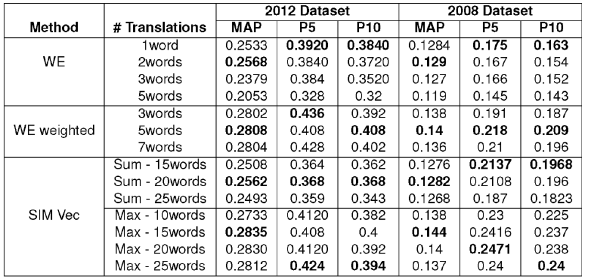
Table 4 shows the performance of the proposed word embedding based approaches for query translation. Among the proposed approaches, SIM Vec (max) seems to perform the best on both the datasets. An issue that comes up while using the embedding based methods is whether to include the embeddings of the named entities in the process. For a particular word in the source language w, similar words that showed up are relevant to w but are not translations. For example, the word BJP in Hindi (which is an Indian political party) the words that were most similar also included the names of other political parties like Congress and also words like Parliament and government in the target language English. Inclusion of such terms can harm the retrieval process as named entities play a critical role in Information Retrieval and so we decide to exclude them from the embeddings and use a transliteration scheme as described in Section 3.5
Table 4 Peformance Results when Queries are translated using proposed Word Embedding based methods: for WE and WE weighted, # Translations per query term are shown, while for SIM Vec, # Translations for the complete query are show
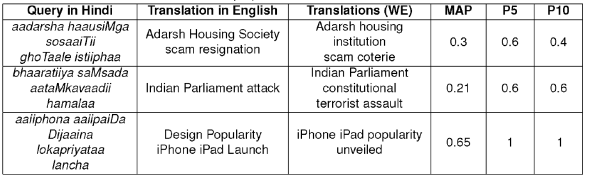
On further investigation, we find that there are 8 such queries for which no translation was available from the Dictionary. Table 5 shows some of these queries. For OOV words that are actually in English and have been written in Hindi orthographic format (e.g, ‘housing’, ‘speaker’ and ‘cancer’ in English have been written as ‘haausiMga’, ‘spiikara’ and ‘kaiMsara’ in Hindi), word embeddings (WE) can easily retrieve translations like ‘housing’,‘society’ and ‘speaker’,‘parliament’ and ‘cancer’,‘disease’ respectively using contextual cues. It is thus evident that the word embedding based method is robust, the translations being very close in meaning to the source language words.
Table 5 Example queries which could not find Translations in the Dictionary but could find Translations using the proposed WE method
When weights are assigned to the translated words, the performance is even better. The insight gained after observing the individual query results for the weighted version is, that it works better for long queries, distributing the weights as per the similarity values.
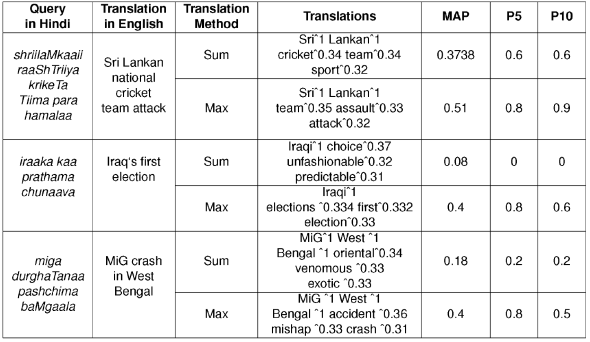
For SIM Vec, we experimented with both the ‘Sum’ and ‘Max’ functions. After doing an analysis on the queries returned by the sum function, we found that those words that are related to the meaning of the entire query come up, while in max, words that have high similarity with one of the query terms, come up in the translation. Table 6 illustrates some example queries from this method. For the first example, ‘sum’ could not retrieve words like ‘assault’ and ‘attack’, because these were similar only to one query term, ‘hamalaa’, but not the others.
While the SIM Vec with the ‘Max’ function performs the best among the proposed approaches, these results are still inferior to the monolingual baseline as well as Google Translate. Next, we use our proposed method with dictionary based approach as well as Google Translate in a hybrid model.
4.3 Experiments with Hybrid Models
For these experiments, we combine the dictionary based translations or those obtained from Google Translate with translations derived from the embedding based method. The following variations have been tried.
-. Hybrid Translations using Dictionary (WE+DT): In this technique of query translation, for each query term qi, we take translations from the dictionary, if a translation exists. If not, we take its translation from the embedding based methods.
-. Hybrid Translations using Dictionary, weighted (WE+DT weighted, SIM Vec+DT Weighted): We assign weights to the dictionary and word embedding based translation words such that the weights for the translations for each of the query terms add up to 1. If a query term has its translation from both dictionary as well as embedding based method, then the dictionary terms are assigned a total weight of w and the rest 1 - w is divided proportionately according to similarity values from the embedding based methods. We give 80% importance to the word embedding based terms and 20% importance to the dictionary based terms (w = 0.2)10
-. Hybrid Translations using Google Translate (Google Translate+Sim Vec, Google Translate+Sim Vec+DT): We include query translations from Google, with the same weighting approach as described above.
Table 7 shows the results of the hybrid approaches with dictionary and Table 9 shows these results while using Google Translate with our embedding methods. In both the cases, the hybrid model improves upon the Dictionary / Google Traslate results, obtained when the word embeddings are not used. Specifically, Sim Vec with the Max function performs the best.
Table 7 Peformance Results when Queries are Translated using a Hybrid of Word Embeddings and Dictionary
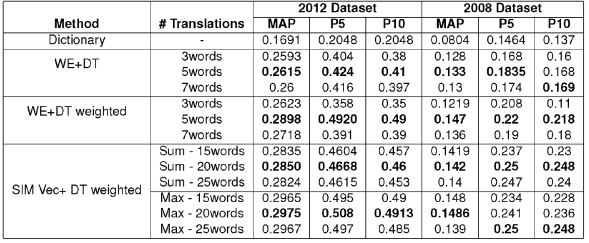

Table 9 Performance Results when Queries are Translated using a Hybrid of Word Embeddings, Google Translate and Dictionary
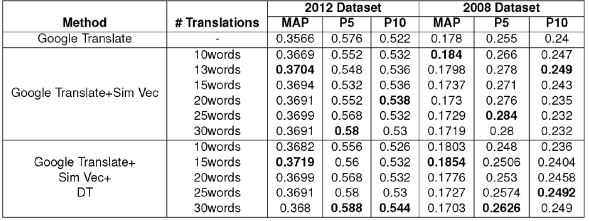
Results for some of the individual queries are shown in Table 8. We see that WE, when combined with DT, retrieves many relevant terms, which improve the performance.
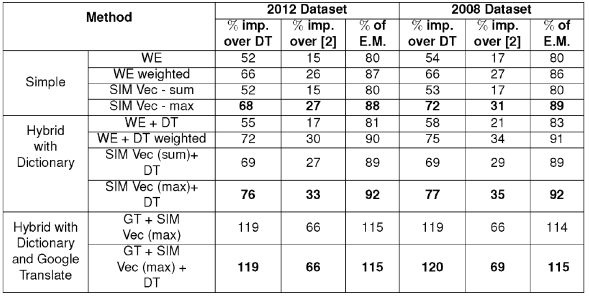
From Table 9 we see that our proposed method not only improves upon the dictionary but also improves over Google Translate and English Monolingual. Table 10 summarizes the improvements of our approach over the baselines, to nearest integers. For DT and 2, improvements obtained by our method are shown, while for English Monolingual, we show the % of the E.M. results obtained by our method. We see that all the proposed approaches improve over DT and 2 consistently. Hybrid model with Google Translate improves even on the English monolingual.
Table 10 Comparison of Word Embedding based methods with Baselines. (DT stands for ‘Dictionary’; 2 refers to Chinnakotla et al.’s method; E.M. stands for ‘English Monolingual’; imp. is ‘improvement’
5 Conclusion and Future Work
In this paper, we proposed a method based on word embeddings for query translation in the CLIR task. Extensive evaluations performed under various settings confirm that word embedding based method is a potential tool with which the language barrier in the CLIR task can be resolved. It alone performs well over the dictionary method and when combined with the dictionary and Google Translate in a hybrid model, it gives the best performance, improving even the target monolingual baseline by 15%. In future, we will like to repeat these experiments over other source-target language pairs to confirm that this is generalizable across many different language pairs and achieves similar performance gains. We will also study the effect of corpus size (on source and target) as well as the dictionary size on the performance of the system. Finally, we will also experiment using this method for tasks such as bilingual lexical induction.

