











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
The rapid growth of Internet over the last two decades instigated the proliferation of user generated content (UGC), added many new challenges for automatic text processing due to the informal and noisy nature of UGC, typically social media texts, chats conversations, and instant messages. Recent trends show that such informal texts contain a mixture of two or more languages depending on the geographical locations of the users and based on their proficiencies in the neighboring languages. Such mixing of languages is known as Code-Mixing . Code-Mixing24 is found in abundance in the Indian subcontinent and is prevalent in Indian Social Media. People feel ease to type their own language using Roman script or Transliteration due to the unavailability of proper input methods for their languages.
India is a home to several hundred languages. Indeed Indians know and use English but they do mix Indian languages frequently in their social media posts. Hindi is the official language spoken almost by the half of the nation, and it is the 4th most popular language world-wide based on first language speaker1. Here in this paper we concentrate on IR problem for English-Hindi Code-Mixed text. Code-Mixed Information Retrieval (CMIR) is challenging because queries written either in native or Roman scripts need to be matched to the documents written in either or both the scripts. However in this paper, we will focus only on Roman transliterated Hindi mixed with English Code-Mixed twitter data. CMIR has to address a non-trivial term matching solution for searching to match each Roman transliterated query terms with the desired word(s), but Roman transliterated form of a Hindi word has no standardization, could have several spelling variations. For example, the Hindi word “मै” (“I” in English) can be written as me, mei, mey, main, mai and so on. When such a Code-Mixed transliterated query search is made, the problem of matching the exact query terms with the terms present in the documents increases due to the spelling variations. Thus, there is a significant effect on the query relevance.
There have been several studies17,18,9,25 on Cross Lingual Information Retrieval (CLIR) and on Multi Lingual Information Retrieval (MLIR) including Indian languages. In a CLIR setup users are allowed to make queries in one language and retrieve documents in one or more other languages. MLIR deals with asking questions in one or more languages and retrieving documents in one or more different languages. In either case, the documents and the query are written in their native scripts. For example, a CLIR with English query for a Hindi document might be written in Roman and Devanagari scripts respectively for the query and the document.
Another case is when the query is in one language but written in different scripts. This is called Mixed Script Information Retrieval (MSIR)8. However, the scenario is different when the query is in Roman transliterated form but contains query terms of different languages. The retrieval task becomes more difficult when the search domain is the social media text such as twitter. This is due to the informal and terse nature of tweets that makes the retrieval task difficult. Moreover, tweets are less likely to be coherent with each other due to the 140 characters limitation. Recently, text mining from Social Media sites such as Facebook and Twitter has taken momentum due to the nature and volume of data being generated (UGC) on the web. The UGC generated on Facebook and Twitter provide information for several business analytics purposes such as mining user’s opinion about some products, organizations, sporting events, political campaigns and so on. Organizations can collect such information and perform data analytics for business development. But all the information being generated may not be useful for a particular purpose. Therefore, technology should be able to retrieve only the relevant information being desired. However, Twitter texts being more restrictive in terms of character length, carry information in a very concise manner. The users try to convey the maximum information within the 140 characters limitation of tweets by using phonetic typing, abbreviations, emoticons etc. thus making the retrieval tasks much more difficult. The difficulty further increases when the tweets are written using two or more languages. This is because in the CMIR scenario, the query terms are written in mixed languages and when documents (tweets) are searched, the retrieval task will only search across the documents (tweets) containing the query search terms and rank them accordingly. Existing state-of-the-art technologies have not been designed to handle such type of Code-Mixed texts and thus fail to address the issue of CMIR. Therefore, all these issues have motivated us to conduct our studies on IR for such type of informal texts.
In this paper, for the first time, we formally introduce the problem of transliterated Code-Mixed query search from twitter for Hindi-English mixed query terms. Present state of the art systems are unable to process Code-Mixed transliterated queries due to the lack of resources such as transliterated dictionaries, machine translation systems. Semantic search for transliterated query is still an unsolved problem and it increases many fold when applied on twitter search. Adequate tools are not available to process queries having Code-Mixed query terms and existing state of the art systems do not perform well for ranking the documents based on the queries.
The major contributions of this paper are:
-. To present the concept, formal definition of Code-Mixed Information Retrieval (CMIR) from twitter for Indian languages particularly Hindi-English bilingual texts.
-. To create a corpus for Hindi-English Code-Mixed tweets.
-. To demonstrate how difficult the problem is and where existing IR techniques fail when applied on such data.
The rest of the paper is organized as follows. In Section 2, we discuss about the related works. Section 3 introduces the notion of CMIR formally and outlines the possible applications scenarios and research challenges. Section 4 discusses corpus acquisition process and statistics. In Section 5 the experimental setup and results are presented along with extensive empirical analysis. Finally, in Section 6 we make the concluding remarks.
2. Related Work
Although several studies have been done on CLIR or MLIR, very little attention has been drawn on Code-Mixed Information Retrieval (CMIR) from the Social Media domain. The work presented in this paper is mainly motivated from8 that do discuss the issue of MSIR from Roman transliterated query search for Hindi song lyrics. However, the MSIR setup in did not focus on Code-Mixed Social Media texts. Song lyrics whether written in native script or Roman transliterated form, are mostly monolingual in nature whereas Code-Mixed tweets are multilingual (bilingual in our case).
The MSIR setup in 8 may not address the true complexity of CMIR scenario presented here since there are inherent difficulties in Code-Mixed texts such as identifying the sentence boundaries of text within a tweet. In Code-Mixed tweets, one part may be written in one language and another part in another language or there could be Code-Mixing at the word level also. Sentence boundary detection (SBD) is itself a difficult problem for such informal texts. Thus, matching the query terms to the languages in the documents is much more difficult. Such characteristics are not found in the cases of either CLIR or MLIR where the languages of query and the documents are implicitly known to the search engine. It is also likely that the problem of spelling variations or out of vocabulary words (OOV) may not be present in a significant manner in CLIR or MLIR. The reason for this argument is that in CLIR, the query and the documents are assumed to be written in their native scripts with spelling variations to be almost negligible.
In contrast, Code-Mixed transliterated twitter data is full of noise such as spelling variations, OOV words etc. Identification of Named Entities (NE) plays a crucial role in IR. This is again a difficult task when applied on transliterated tweets because of the spelling variations of the query terms and their presence in the documents.1 show that due to the lack of standardization in the way a local language is mapped to the Roman script, there is a large variation in spellings which further compounds the problem of transliteration. In 5 they have proposed a query-suggestion system for a Bollywood Song Search system where they have stressed on the presence of valid variations in spelling Hindi words in Roman script.6 have shown that 90 % of the queries are formulated using the Roman alphabet while only 8% use the Greek alphabet, and the reason for this is that out of every 3 Greek navigational queries, 1 fails due to the low level of indexing by the search engines of the Greek Web.
7describe a method to mine Hindi-English transliteration pairs from online Hindi song lyrics crawled from the web. 10 and 12 have used Edit-distance based approaches for the generation of language pairs for Tamil-English and for English-Telugu respectively. 12developed a stemmer based method that deletes commonly used suffixes. 14 propose a method for normalization of transliterated text that combines two techniques: a stemmer based method that deletes commonly used suffixes with rules for mapping variants to a single canonical form. 20 have proposed a method that uses both stemming and grapheme-to-phoneme conversion for a multilingual search engine for 10 Indian languages. 22 have worked on transliterated search of Hindi song lyrics where they have converted the Roman transliterated words into Devanagari form. 23 use an English taxonomy system to classify non-English based queries which is heavily dependent on the availability of translation systems for the language pairs in question.
It is therefore, observed that though previous studies have attempted to develop transliterated IR systems for Indian Languages (IL) but none of them have addressed the problem with respect to Code-Mixed transliterated IR for twitter data. Therefore, the problem of IR with respect to transliterated Code-Mixed query search on social media still remains unexplored.
3 CMIR: Formalization
In this section, we formalize the concept of Code Mixed Information Retrieval with respect to MSIR introduced by 8.
3.1 Code Mixed IR
We assume L to represent the set of natural languages and S to be the set of scripts such that
Let q be a query given over a set of documents D where the IR task is to rank the documents in D so that the documents most relevant to q appear at the top. For a monolingual query q, we can assume that
where
The document pool thus becomes
where
3.2. Difficulties and Challenges in CMIR for Social Media Texts
The IR task under the CMIR setup is to search for documents written in multiple languages and rank them according to the query given. CMIR on social media texts introduces several challenges for the IR task. First, it is a difficult task to identify the language of each query terms for a given Code-Mixed query across Code-Mixed tweets where the document length is short. The second challenge is the presence of spelling variations in transliterated query terms. For example, “मै” in Hindi which stands for “I” or “me” in English, can be written in any one of the following Roman transliterated forms such as mein,me,mei,main,mai and so on. Therefore, for a query 𝑞 which has one of the given Roman transliterated search terms, only those documents (tweets in our case) in the document collection 𝐷 will be retrieved which matches with the exact terms. However, there may be documents in 𝐷 with same query terms with different spellings. A retrieval system in such a scenario will ignore all documents that do not contain the query search term with the exact spellings. Third challenge is to identify words which are represented using mixing of non-alphabetic characters. Tweets are known to be terse in nature and sometimes words could be expressed with non-alphabetic characters. For instance, “before” is often written as “b4”. Therefore, existing state-of-the-art systems are not appropriate for handling documents of such nature as discussed above.
4 Corpus Creation
4.1 Data Collection
For this study, we have collected Hindi-English tweets where the Hindi terms are in Roman transliterated form. Fetching Code-Mixed Hindi-English tweets is itself a difficult task. Tweets were collected on topics related to the events trending at that time. However, it is difficult to decide what is trending. Therefore, we started searching for tweets for events that were happening and making news at the time of collection. For example, for a topic like Delhi election which was held in February 2015, we started collecting tweets from November 2014 to April 2015 that is the period from political campaigning to declaration of the election results. For such collection of tweets, the probable query search terms are the entities such as names of the political parties and the candidates contesting the election. Initially we attempted to collect tweets based on the Entities related to the topic. However, it was difficult to retrieve Code-Mixed Hindi-English tweets, therefore, we simply issued bag of words as the query containing Hindi terms in Roman transliterated form mixed with the topic under consideration. The Hindi search terms are mostly stop words. For example, for tweets related to the Delhi election, queries such as “BJP aur Kejriwal” (BJP and Kejriwal) were issued. In the example query, “BJP” is the name of a political party, “Kejriwal” is the name of a candidate and “aur" is a Hindi stop word meaning “and” in English. In another example query, “aam aadmi party Delhi mein” where “aam aadmi party” is the name of a political party and “mein” (“in”) is the Roman transliterated Hindi word. In similar fashion, tweets related to other trending topics were collected such as Cricket World Cup 2015 which was held between February and March 2015, the Bollywood2 controversy related to an Indian film actor. We also tried to collect tweets from other topics during the period from December 2015 to January 2016.Though several other topics were searched but we did not include them in the corpus because of their smaller presence (limited to 3 to 4 tweets only). We have used Twitter4j API 3 for collecting the tweets. Due to the API restriction, we could not fetch tweets beyond seven days thus resulting in limited number of tweets for some topics.
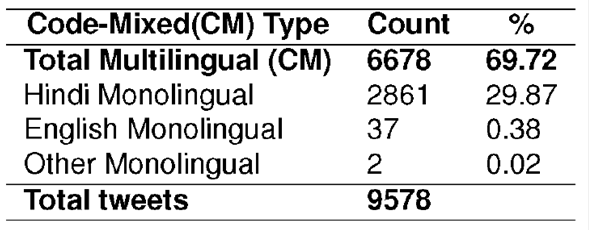
Tweets were collected based on different query search terms using AND and OR Boolean operators. For example, a search query like “AAP OR aadmi AND hai” which has three terms viz; “AAP”, “aadmi” and “hai” was used to fetch tweets containing either “AAP” only or “aadmi” and “hai” both. A total of 9,715 tweets were collected based on different query search terms. It has been observed that there were initially redundant tweets due to the presence of re-tweets, retrieval of the same tweets from two different queries and same tweets with trailing different hash tags, URLs and emoticons. By redundant, we mean in cases where the maximum text of two or more tweets match. Therefore, we have considered them as duplicate tweets and have removed them by a measure known as Jaccard similarity coefficient 4.It is interesting to observe that certain tweets were retrieved which are written in Devanagari script for the Hindi words. In some cases an entire tweet has been found to be written in Devanagari script. We have not considered such tweets for our work and therefore we have manually removed them from our corpus. As our initial step, we have used CMU tokenizer 5, 13for tokenizing the tweets. Finally, the corpus size was reduced to 9578 tweets out of which 6678 are Code-Mixed and the distribution is shown in Table 1.

4.2. Language Identification
For any Code-Mixed corpus, it is of utmost importance to identify the languages at the word level. Automatic language identification from large multilingual corpora has great significance and therefore, we have used such a system2 for our purpose. 2 gave an F1 score of 91.1% for automatic language identification on our corpus. The tokens were tagged as hi,en,ne,acro,univ,undef. Here hi and en signifies that a token is either a Hindi or an English word respectively. Likewise, ne signifies that a token is a Named Entity, acro is an Acronym, univ is either an emoticon or a punctuation symbol and undef for tokens which are neither univ nor hi or en. An example annotation is shown below:
Tweet:
jaldi delhi .... thoda time aur ... aapni sarkar ko chuno ..... this time 75% voting .... :)
Annotation:
jaldi/ hi delhi/ ne ..../ univ thoda/ hi time/ en aur/ hi .../ univ aapni/ hi sarkar/ hi ko/ hi chuno/ hi ...../ univ this/ en time/ en 75%/ univ voting/ en ..../ univ : )/ univ
Meaning:
hurry delhi .... little more time ... choose your government ..... this time 75% voting .... :)
Tag wise distribution of the tokens from 6,678 Code-Mixed tweets is shown in Table 2. From Table 2 it is observed that Hindi word count is more than the English words in the corpus.

4.3 Code Mixing Types
After automatic language identification of the words using2, we have measured the level of Code-Mixing by calculating the Code Mixing Index (CMI) introduced in 3 and 4.CMI has been calculated to measure the level of mixing between Hindi and English in our corpus. In our corpus both intra and inter-sentence level Code-Mixing are present. We have not measured their percentage distribution because categorizing them requires Sentence Boundary Detection (SBD) which is itself a very difficult task. We therefore only report the distribution of Code-Mixed data in our corpus. However, there is another type of Code-Mixing occurring at word level which we have not found in our corpus. Table 3 lists the distribution of monolingual vs. multilingual tweets. We observed that 69.72% of our corpus is Code-Mixed and the remaining 30.28% is monolingual.2% of the corpus has been found to be of other monolingual type. A tweet is considered as “other monolingual” if there are no hi or en words.
5 Experiments and Results
5.1 Creation of Gold Standard Data
From the 6678 Code-Mixed tweets, we have taken 1959 tweets and conducted two annotation experiments. The reason for choosing the 1959 tweets for creating gold standard is that for our experiments, the chosen set of queries from few topics constitute only 1959 tweets. For the annotation purpose we could not deploy annotators from Amazon Mechanical Turk (AMT) due to financial constraints. Therefore, two in-house students studying Masters in Computer Science and Engineering, were selected for the annotation work who are well conversant with both Hindi and English languages. In our first experiment, each annotator was given a topic with query related to the topic and the list of tweets. Annotators were then requested to rank the tweets according to its relevance for the given query without consulting each other. The agreement score in the first experiment was very low with a Kappa6 value of 0.1312 only. After carefully investigating the queries and the corresponding tweets, we have found that for some queries it was comparatively easier to rank them whereas for some other queries, the ranking based on relevance judgement was difficult. It was difficult because the collection of tweets for certain queries were semantically diverse from each other with respect to the query. Therefore, in our second experiment, both the annotators were instructed to understand the expected outcome of a given query and to discuss the relevance of a tweet accordingly. After conducting the second experiment, we achieved inter-annotator agreement with a Kappa value of 0.6762. This suggests that relevance judgement for tweets is itself a very difficult task due to their terse nature.
5.2 Searching and Ranking
For evaluation of existing IR systems on our corpus of 1959 gold data, we have used Lucene7 for indexing, searching and retrieval. Lucene combines Boolean model (BM) with Vector Space Model (VSM) of Information Retrieval where each distinct index term is a dimension, and weights are 𝑡𝑓-𝑖𝑑𝑓 values and uses the practical scoring function8. We tested with 20 queries with an average query length of 2.67 terms and compared them against the gold data. For our experimental purposes, Boolean queries with AND and OR operators and queries as phrases were issued for searching and retrieving the tweets.
We have configured Lucene to retrieve the top 20 tweets for each query. Each tweet has been considered as a document for indexing. Therefore, for 1,959 tweets there are 1,959 documents that were indexed. The Lucene Standard Analyzer is capable of preprocessing (tokenization, stop word removal) only English texts. A total of 11,565 terms were indexed with three fields (contents, file name, file path). The top ten terms that Lucene identified are shown in Table 4. It is interesting to observe that most of these terms are actually Hindi stop words such as hai,ki,ko,ka.The Standard Analyzer could not detect the presence of Hindi stop words in their Roman transliterated form thus affecting the ranking. Also noted in Table 4 is that the frequency of relevant indexed terms such as kejriwal,sonia,khan etc. are comparatively low. An indexed term is considered relevant if it is close to the topic. For example, terms like kejriwal,bjp,modi etc. are considered relevant for the tweets related to Delhi election.

5.3 Results
For evaluating the performance of Lucene on our gold corpus of 1,959 tweets, we initially noted the Mean Average Precision (MAP) of all the tweets ranked by Lucene for the queries against the gold standard. The MAP value we obtained is 4.254359863552588 x 10-5 which is very low in terms of performance. This suggests that relevance judgement for ranking informal texts such as tweets, is a difficult task because relevance judgement is idiosyncratic in nature and therefore, creating gold standard data for IR is biased. Therefore, MAP is more likely to be low if there is a huge disparity between the system rankings and the gold rankings. Moreover, due to the terse nature of tweets, it is difficult to judge whether a particular tweet is more relevant than the other for a query. Therefore, we instead took a different approach for evaluating Lucene on our corpus. In our alternate approach, we first issued exactly the same queries to Lucene that were used to collect the tweets. Again we conducted two rounds of annotations. In the first round, tweets that were ranked by Lucene were given to the annotators for manual re-ranking. The inter-annotator agreement was then observed to be 0.7458, which is higher in comparison to the earlier annotation agreement score of 0.6762. In the second round, both the annotators were requested to come to a consensus and create the gold standard. Finally, gold data was created after manually re-ranking the system (Lucene) retrieved tweets. Queries have differing number of relevant documents. Therefore, we cannot use one single cut-off level for all queries. This would not allow systems to achieve the theoretically possible maximal values in all conditions. We have therefore, measured the 11-point average precision 11 and Mean Average Precision (MAP) for the Vector Space Model based ranking mechanism. A total of 20 queries were issued and finally a MAP value of 0.186 was obtained which is reported in Table 5.

6. Discussion and Conclusion
Previous works on multilingual IR such as 8 have addressed the issue with respect to retrieval of Hindi song lyrics written either in Devanagari script or Roman transliterated form of Hindi words or a mixture of both. But the work in 8 did not consider the case of documents where the text is Code-Mixed. In this paper we have addressed the problem of retrieving Code-Mixed Hindi-English documents from informal texts such as tweets where the nature of the text is unpredictable. It is unpredictable due to the informal nature of tweets where spelling variations, out of vocabulary words are often present. We have also stated the difficulties in creating gold standard data for CMIR corpus and established that relevance judgement for ranking tweets is a difficult task as inter-annotator agreement is very low. Without any modification to the original tweets in our corpus, we have indexed the Code-Mixed tweets in Lucene with the standard configurations, which Lucene ranked them using its Practical Scoring Function. We have adopted relevance feedback mechanism for our evaluations due to the fact that it assumes that the user issuing the queries has sufficient knowledge about the documents desired. This is due to the fact that tweets are very short in length with only 140 characters. Therefore, two tweets may carry the same information but written in different contexts thus making it difficult for human judges to score the relevance. For relevance judgement, sufficient knowledge about the documents is desired. Our experiments suggests that relevance judgement for CMIR does not improve the performance of the ranking mechanism. This is because relevance judgement is biased and it is not appropriate in certain cases where the data has “misspellings", “spelling variations" and “Mismatch of searcher‘s vocabulary versus collection vocabulary". Tweets are terse and noisy in nature. Therefore, misspellings and spelling variations are found in abundance in such informal texts and thus make the IR tasks more difficult. In future, we can extend our work with other evaluation measures such as Query Expansion, semantic search. Global relevance evaluation mechanisms such as Query Expansion could be applied on our corpus to measure the performance of searching and ranking. It is clear that state-of-the-art techniques do not perform well on CMIR and therefore, our stated problem opens new research challenges in the Code-Mixed Social Media IR domain.

