











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introducción
In essence, a topic model decomposes the sparse word-document matrix into a product of word-topic and topic-document matrices; this idea was first fieshed out in probabilistic latent semantic analysis (PLSA) 15, and now the topic model of choice is latent Dirichlet allocation (LDA), which is a Bayesian version of PLSA with Dirichlet priors assigned to word-topic and topic-document distributions 9,14.
Over the years, LDA has received tremendous attention, with many extensions developed for many different purposes, but each of them has been a separate research project, with a new version of one of the two basic inference algorithms for LDA: either a variational approximation for the new posterior distribution or a new Gibbs sampling scheme. Hence, it is hardly practical to expect a researcher, especially in social sciences, to develop new LDA extensions for each new problem; even slight modifications of an existing extension may be hard both to develop and to implement in software
Hence, we use a recently developed approach called additive regularization for topic modeling (ARTM)31 and the corresponding open-source implementation BigARTM32. ARTM extends the basic PLSA model with a general regularization mechanism that can directly express desired properties in the objective function, and the inference algorithm results automatically.
As a special case, ARTM with smoothing regularizers can mimic the LDA model34, although such regularization results in the same model stability as already noted for LDA itself24,34. Note that recent studies uncover deep problems with the basic LDA model, specifically its instability stemming from numerous local maxima of the objective function1,18,19.
Flexibility is a big advantage of ARTM in practice, especially for digital humanities where one often has but a feeling of what one is looking for. Having trained a trial model in the form of regular LDA or ARTM without regularizers, a researcher can formulate what is lacking and what is desired of the resulting topic model. In most cases, BigARTM lets a researcher combine regularizers from a built-in library in order to meet a set of requirements to the model quickly and efficiently. To achieve all these results, a social scientist has only to learn how to create regularizes and set their parameters; this can be done easily by editing a few lines of code; with no mathematical inference and no coding. Having trained a trial model in the form of regular LDA or ARTM without regularizers, a researcher can formulate what is lacking and what is desired of the resulting topic model. The BigARTM framework also lets one quickly develop and test new regularizers tailored specifically for one's problem. In most cases, BigARTM lets a researcher combine regularizers from a built-in library in order to meet a set of requirements to the model quickly and efficiently.
In this work, we show one such application of the ARTM approach for the problem of mining a large corpus/stream of user-generated texts (in our case, blog posts) for specific topics of discourse (in our case, ethnic-related topics) defined with a fixed dictionary of subject terms (ethnonyms). To achieve a good topic model, we split the entire set of topics into subject-related and background topics, develop a new regularizer that deals with this predefined dictionary of subject terms, and build a combination of regularizers to make topics more interpretable, sparse, and diversified. The ARTM framework lets us do all of these things seamlessly, without complicated inference and developing new algorithms.
We present an extensive evaluation of our results, concentrating on interpretability evaluation produced by a team of human assessors; this is both needed in our case study (where it is important for topics to be interpretable for non-specialists) and generally represents a gold standard for the quality of a topic model. Experimental results suggest that while the basic (unregularized or weakly regularized) ARTM model is no better than regular LDA, new regularizers significantly improve both number and quality of relevant topics.
The paper is organized as follows. In Section 2, we introduce the basic PLSA model, its Bayesian counterpart LDA, and the general setting of the ARTM approach. In Section 3, we review regularizers used in this work and comment on their effect on the resulting topic model. Section 4 lists the specific models we have trained and covers the results of our case study in finding ethnic-related texts in a large dataset of blog posts. Section 5 concludes the paper.
A preliminary version of this work has appeared in the Proceedings of the 15th Mexican International Conference on Artificial Intelligence (MICAI 2016)4; compared to the conference version, we have conducted a novel study of topic modeling on a reduced collection filtered with respect to the top words of relevant topics (see Section 4.5) and extended the survey part of the paper (Section 2).
2 Topic Modeling and Related Work
Let D denote a finite set (collection) of documents (texts) and let W denote a finite set (vocabulary) of all terms from these documents Each term can represent a single word or a key phrase. Following the “bag of words” model, we represent each document d from D as a subset of terms from the vocabulary W. Assume that each term occurrence in each document refers to some latent topic from a finite set of topics T. A text collection is considered as a sequence of triples (d j, w j, t j), i = 1,..., n, drawn independently from a discrete distribution p(d, w, t) over the finite probability space D x W X T. Terms wj and documents dj are observable variables, while topics tj are latent variables.
A probabilistic topic model represents the probabilities p(w | d) of terms occurring in docu ments as mixtures of term distributions in topics φwt = p(w | t) and topic distributions in documents θtd = p(t | d):
This mixture also directly corresponds to the generative process for a document d: for each term position i, sample topic index t i from distribution p(t|d) and then sample the word w i from distribution p(w|t i).
Parameters of a probabilistic topic model are usually represented as matrices
with non-negative and normalized columns
2.1 PLSA
In Probabilistic Latent Semantic Analysis PLSA) 15,16 the topic model (1) is trained by log-likelihood maximization with linear constraints of nonnegativity and normalization:
Under constraints
Where n dw is the number of occurrences of the term w in the document d. The solution of this optimization problem satisfies the following Karush-Kuhn-Tucker conditions with auxiliary variables p tdw, n wt, n td.
Where
This system follows from (2)-(3) and can be solved numerically. The simple-iteration method for this system of equations is equivalent to the EM algorithm and is typically used in practice. It repeats two steps in a loop according to the equations above.
The E-step (4) can be understood as the Bayes rule for the probability distribution of topics ptdw = p(t | d, w) for each term w in each document d. Auxiliary variable n
wt estimates how many times the term w is associated with the topic t over all documents; n
td estimates how many terms from document d are associated with the topic t. The M-step (5) can be interpreted as frequency estimation for conditional probabilities
2.2 LDA
The latent Dirichlet allocation (LDA) model 9,14
introduces prior Dirichlet distributions for the vectors of term probabilities
in topics
Inference in LDA is usually done via either variational approximations or Gibbs sampling, In the basic LDA model, with the latter reducing to the so-called collapsed Gibbs sampling, where θ and φ variables are integrated out, and topic t i for each word position (d i, w i) is iteratively resampled from p(t | d, w) distribution estimated according to the same formula (4), similar to PLSA, but with smoothed Bayesian estimates of conditional probabilities:
where n wt is the number of times term w has been generated from topic t and n td is the number of terms in document d generated from topic t except the current triple (d i, w i, t i).
Over the recent years, the basic LDA model has been subject to many extensions, each presenting either a variational of a Gibbs sampling algorithm for a model that extends LDA to incorporate some additional information or presumed dependencies.
Extensions that add new dependencies include correlated topic models (CTM) that exploit the fact that some topics are more or less similar to each other and may share words with each other, using logistic normal distribution instead of Dirichlet to model correlations between topics 6, Markov topic models use Markov random fields to model the interactions between topics in different parts of the dataset (different text corpora), connecting a number of different hyperparameters β i in a Markov random field expressing prior constraints 20, relational topic models construct a hierarchical model refiecting the structure of a document network as a graph 11, and so on.
Extensions that use additional external information include various time-related extensions such as Topics over Time36 or dynamic topic models7,35, that apply when documents have timestamps (e.g., news articles or blog posts) and represent topic evolution in time; supervised LDA that assigns each document with an additional observed response variable 8, an approach that can be extended further to, e.g., recommender systems 23; sentiment-related extensions add sentiment variables to the basic topic model and train both topics and sentiment variables in various contexts 21,30,38, and so on. In particular, a lot of work has been done on nonparametric LDA variants based on Dirichlet processes that can determine the optimal number of topics automatically 13,28,37.
For our present purpose of mining and analyzing documents related to a specific user-defined topic, the LDA extensions that appear to be most relevant are the Topic-in-Set knowledge model and its extension with Dirichlet forest priors 2,3, where words are assigned with “z-labels”; a z-label represents the topic this specific word should fall into, and the Interval Semi-Supervised LDA (ISLDA) model 10,24 where specific words are assigned to specific topics, and sampling distributions are projected onto that subset.
2.3 ARTM
Topic modeling can be viewed as a special case of matrix factorization, where the problem is to find a low-rank approximation ΦΘ of a given sparse matrix of term-document occurrences. Note, however, that the product ΦΘ is defined only up to a linear transformation since
ΦΘ = (ΦS)(S -1Θ)
for any nondegenerate matrix S. Therefore, our problem is ill-posed and generally has an infinite set of solutions. Previous experiments on simulated data 34 and real social media data 10 show that neither PLSA nor LDA can ensure a stable solution. To make the solution more appropriate one must introduce additional optimization criteria, usually called regularizers29.
The Dirichlet prior can be considered as a weak smoothing regularizer. Therefore, our starting point will be the PLSA model, completely free of regularizers, rather than the LDA model, although the latter is more popular in recent research works.
In Additive Regularization of Topic Models (ARTM) 31 a topic model (1) is trained by maximizing a linear combination of the log-likelihood L(Φ, Θ) and r regularizers R i(Φ, Θ), i = 1,..., r with regularization coefficients τ i :
Karush-Kuhn-Tucker conditions for this nonlinear problem yield (under some technical restrictions) necessary conditions for the local maximum 34:
where
The strength of ARTM is that each additive regularization term Ri yields a simple
additive modification of the M-step. Many models previ ously developed within
the Bayesian framework can be easier reinterpreted, trained, and combined in the
ARTM framework 33,34; e.g., PLSA does not use
regularization at all, R = 0, and LDA with Dirichlet priors
3 Additive Regularization
3.1 General Appoach
In this section, we consider an exploratory search problem of discovering all ethnic-related topics in a large corpus of blog posts. Given a set of ethnonyms as a query 𝑄⊂𝑊, ,we would like to get a list of ethnically relevant topics. We use a semi-supervised topic model with lexical prior to solve this problem; similar models have appeared for news clustering tasks 17, discovering health topics in social media 25 and ethnic-related topics in blog posts 10,24. In all these studies, researchers specify for each predefined topic a certain set of seed words, usually very small, e.g., a news category or ethnicity. This means that we must know in advance how many topics we would like to find and what each topic should be generally about. The interval semi-supervised LDA model (ISLDA) allows to specify more than one topic per ethnicity 10, but it is difficult to guess how many topics are associated with each ethnicity, and if an expert does not anticipate a certain subset of seed words, it will be impossible to learn in the model. Moreover, and in 10,24, where the case study was similar to our present work, ISLDA was used to look for ethnic-related topics, but since seed words related to different ethnicities were separated into different topics, so no multi-ethnic topics could appear. In our present approach, the topic model has more freedom to decide the composition of subject topics in S. Moreover, all cases above include a large amount of preliminary work involved in associating seed words with predefined topics.
We address the above problems by providing a lexical prior determined by a set of ethnonyms Q common for all ethnically relevant topics. The model itself determines which ethnicity or combination of ethnicities make up each relevant topic.
We use an additive combination of regularizers for smoothing, sparsing, and decorrelation in order to make topics more interpretable, sparse, and diversified 34. The ARTM framework lets us do all of these things seamlessly, without complicated inference and developing new algorithms. All these regularizers have been implemented as part of the BigARTM open-source topic modeling toolbox. We show that the combination of regularizers significantly increases the number of retrieved well-interpretable ethnical topics.
First of all, we split the entire set of topics T into two subsets: domain-specific subject topics S and background topics B. Regularizers will treat S and B differently. The relative size of S and B depends on the domain and has to be set in advance by the user. The idea of background topics that gather uninteresting words goes back to the special words with background (SWB) topic model 12, but unlike SWB, we define not one but many background topics in order to model irrelevant non-ethnic-related topics better, thereby improving the overall quality of the model
3.2 Smoothing and Sparsing
A straightforward way to integrate lexical priors is to use smoothing and sparsing regularizers with uniform β distribution restricted to a set of ethnonyms Q:
We introduce a smoothing regularizer that encourages ethnonyms
In the exploratory search task, relevant content usually constitutes a very small part of the collection. In our case, the entire ethnicity discourse in a large dataset of blog posts is unlikely to add up to more than one percent of the total volume. Our goal is to mine fine-grained thematic structure of relevant content with many small but diverse and interpretable subject topics S, but also to describe a much larger volume of content with a smaller number of background topics B. Formally, we introduce a smoothing regularizer for background topics B in Θ and a sparsing regularizer that uniformly supresses ethnic-related topics S:
The idea is to make background topics B smooth, so that they will contain irrelevant words, and subject topics S sparse, so that they will be as distinct as possible, with each topic concentrating on a different and meaningful subject.
3.3 Decorrelation
Diversifying the term distributions of topics is known to make the resulting topics more interpretable 27. In order to make the topics as different as possible, we introduce a regularizer that minimizes the sum of covariances between φ، vectors over all specific topics t:
The decorrelation regularizer also stimulates sparsity and tends to group stop-words and common words into separate topics 27. To move these topics from S to B, we add a second regularizer that uniformly smoothes background topics.
3.4 Modality of Seed Words (Ethnonyms)
Another possible way to use lexical priors is to distinguish ethnonyms into a separate modality. Generally, modality is a kind of tokens in a document. Examples of modalities include a separate class of tokens (sample modalities include named entities, tags, foreign words, n-grams, authors, categories, time stamps, references, user names etc.). Each modality has its own vocabulary and its own Φ matrix normalized independently. A multimodal extension of ARTM has been proposed in 32 and implemented in BigARTM. We introduce two modalities: words and ethnonyms. The latter is defined by a seed vocabulary Q and matrix Φ of size |Q| x |T|. In ARTM, the log-likelihood of a modality is treated as a regularizer:
where regularization coefficient
In order to make ethnic-related topics more diverse in their ethnonyms, we introduce an addi tional decorrelation regularizer for the modality of ethnonyms:
Note that we introduce decorrelation for subject topics S separately for words modality with Φ matrix and for ethnonyms modality with Φ matrix.
3.5 Putting it All Together
The BigARTM library1 lets users build topic models for various applications simply by choosing a suitable combination of predefined regularizers. All of the regularizers listed above can be used in any combination; by using different mixtures one can achieve different properties for the resulting topic model. In one of the models (model 5 in Section 4.2), we combined all regularizers described above. Note that while the resulting models have relatively many hyperparameters, and optimal tuning of them may incur prohibitive computational costs, in practice it suffices to set the hyperparameters to some reasonable values found in previous experiments. In all results shown below, hyperparameters were tuned with a greedy procedure, one by one.
4 Evaluation
4.1 Datasets and Settings
From the sociological point of view, the goal of our project is to mine and monitor ethnic-related discourse in social networks, e.g., find how popular topics are related to various ethnic groups, perhaps in specific regions, and identify worrying rising trends that might lead to ethnic-related outbursts or violence. While multimodal analysis that would account for topic evolution in time and their geospatial distribution remains a subject for further work, we evaluate our models on a real life dataset mined from the most popular Russian blog platform LiveJournal.
The dataset contains 1.58 million lemmatized posts from the top 2000 LiveJournal bloggers embracing an entire year from mid-2013 to mid-2014. Data were mined weekly according to the LiveJournal's rating that was quite volatile, which is why the number of bloggers in the collection comprized several dozens of thousands. The complete vocabulary amounted to 860K words, but after preprocessing (leaving only words that contain only Cyrillic symbols and perhaps a hyphen, are at least 3 letters long, and occur > 20 times in the corpus) it was reduced to 90K words in 38·1 million nonempty documents.
To choose the number of topics, we have trained PLSA models with 100, 300, and 400 topics, evaluated (by a consensus of a team of human assessors) that the best result was at 400 topics, and hence chose to use 400 topics in all experiments. This corresponds to our earlier experiments with the number of topics in relation to mining ethnic discourse 10,24.
The collection was divided into batches of 10000 documents each. All ARTM-based models were trained by an online algorithm with a single pass over the collection and 25 passes over each document; updates are made after processing every batch. For the semi-supervised regularizer, we have composed a set of several hundreds ethnonyms - nouns denoting various ethnic groups, based on literature review, Russian census and UN data, expert advice and other sources; 249 of those words occurred in the collection Ethnonyms were considered the best candidates for improving mining topics that correspond to the sociological notion of ethnicity and inter-ethnic re lations. The latter are understood as interpersonal or intergroup interactions and attitudes caused or justified by the ethnic status of participants; they should be differentiated from international relations where the main actors are countries, including nation-states, and their governments or individual official representatives, and the subject is not always related to the ethnic status of individuals or groups. International and inter-ethnic relations are closely connected and in some situations inseparable, however, intuitively it is clear that for preventing internal ethnic confiict monitoring attitudes to migrants expressed by bloggers is more relevant than mining news on world summits or international trade treaties. We, therefore, assumed that topics on ethnicity per se should be dominated by ethnonyms (Turks), while ethnic adjectives (Turkish) and country names (Turkey) would more probably refer to international relations. In the Russian language, these three categories are almost always different words, which in our mind could contribute to easier differentiation between topics on ethnicity and on international relations.
4.2 Models
In our BigARTM experiments, we have trained a series of topic models. In all models with hyperparameters, we have tuned these hyperparameters to obtain the best models available for a specific model with a greedy procedure: start from reasonable default values, optimize the first parameter, fix it and optimize the second parameter and so on.
In total we have evaluated eight models with |T| = 400 topics each. For all models, we have chosen regularization coefficients manually based on the results of several test experiments. In all additively regularized models with lexical priors, we divided topics into |S| = 250 subject topics and |B| = 150 background topics. Next we list the different models compared in the experiments below and provide the motivation behind introducing and comparing these specific topics:
plsa: reference PLSA model with no regularizers;
lda: LDA model implemented in BigARTM with smoothness regularizers on Φ and Θ with uniform a and β and hyperparameters a0 = β0 = 10-4;
smooth: ARTM-based model with smoothing and sparsing by the lexical prior, with regularization coefficients τ1 = 10-5 and τ2= 100 (tuned by hand); besides, in this and all subsequent regularized models we used the smoothing regularizer for the Θ matrix with coefficients τ3 = 0.05 and τ4 = 1;
decorrelated: ARTM-based model that ex tends (3) with decorrelation with coefficients τ5 = 5 x 104 and τ6 = 10-8; the smoothing coefficient for ethnically relevant subject topics was τ1 = 10-6;
restricted dictionary: ARTM-based model that extends (4) by adding a modality of thnonyms with coefficients τ7 = 100 and τ8 = 2 x 104 ; the decorrelation coefficients was τ5 = 1.5 x 106 and τ6 = 10-7 ; subject words were smoothed with coefficient τ1 = 1.1 x 10-4 ; for this model we used a dictionary with |Q |=249ethnonyms;
extended dictionary: same as (5) but with dictionary extended by adjectives and country names if respective ethnonyms did not occur; the positive outcome here would be that more relevant topics can be found with an extended dictionary, while the negative outcome is that ethnic topics could instead get lost within topics on international relations;
recursive: the basic PLSA model trained on a special subset of documents, namely documents retrieved from topics that were considered ethnic-relevant by assessors in model 5 with a threshold of 10-6 in the Θ matrix for all subject topics; here, the hypothesis was that a collection with a higher concentration of relevant documents could yield better topics;
keyword documents: PLSA model identical to (7) but trained on a subset of only those documents that contained at least one word from the dictionary.
Models 7 and 8 were introduced to test two different ways of enriching the initial collection. Model 8 was used as reference for model 7: it was to check if enriching the collection through a preliminary cycle of topic modeling would yield better results than retrieving texts via a simple keyword search.
Figure 1 shows several sample topics from some of the models (translated to English; superscript adj denotes an adjectival form of the word, usually a different word in Russian). It appears that later models, 6 and 7, yield topics that are better suited for the ethnic purpose of our study; in what follows, we will expand and quantify this observation.

4.3 Assessment
In the rest of this section, we discuss the qualitative and quantitative results of our study, starting from the assessment methodology and then discussing the results of our human coding experiments. However, results coming from the assessors were supplemented with values of the tf-idf coherence quality metric introduced earlier in 10,24. It has been shown that tf-idf coherence better matches the human judgment of topic quality than the traditional coherence metric 22.
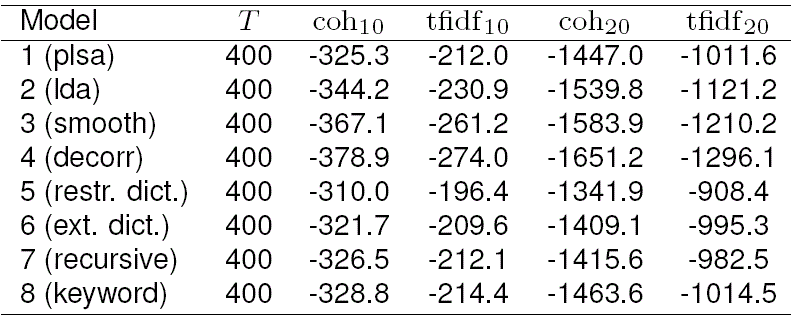
Results on average coherence and tf-idf coher ence for all topics in every model are shown in Table 2; we show two versions of coherence-based metrics, computed with top 10 words in a topic and computed with top 20 words. The distributions of all four metrics are also shown in more detail on Fig. 1, which shows the sorted metrics (coh10, tfidf 10, coh20, and tfidf20) for each model, so a graph that goes above the other represents the better model. Table 2 and Fig. 1 show that while models 5 (restricted dictionary) and 6 (extended dictionary) win in all four cases, all models have comparable values with respect to the topic quality metrics except for models 3 (smooth) and 4 (decorrelated). This was supported by preliminary human evaluation, so we decided to drop these two sets of results from further consideration, choosing to use limited human assessment resources on the better models.

For all other models, assessors were asked to interpret the topics based on 20 most probable words in every topic of each model, except models and 4 that demonstrated much lower quality as measured with coherence and tf-idf coherence 24 and thus were excluded from assessment. For each topic, two assessors answered the following questions, related both to the overall quality and to the ethnic nature of our study:
Do you understand why these words are collected together in this topic? (1) absolutely not; (2) partially; (3) yes.
If you answered “partially” or “yes” to question 1:do you understand which event or phenomenon can be discussed in texts related to this topic? (1) absolutely not; (2) partially; (3) yes.
Is there an ethnonym among the top-words of this topic? Specify the total number of ethnonyms.
If you answered “partially” or “yes” to question 2: is this event or phenomenon related to ethnic issues? (1) not at all; (2) partially or unclear; (3) yes.
If you answered “partially” or “yes” to question 2: is this event or phenomenon related to international relations? (1) not at all; partially or unclear; (3) yes
If you answered “partially” or “yes” to question 2: is this event or phenomenon related to some other category of topics, not related to ethnicity? (1) not at all; (2) partially or unclear; yes.
Assessors were clearly instructed on all matters, including the differences between ethnicity and international relations. We have asked assessors about both of these issues because from our previ ous experience with semi-supervised approaches 10,24 we know that the international relations topics are often retrieved instead of ethnic-related topics or tend to blend with them. This, ultimately, produces high probabilities for documents devoted to global political conflicts/relations or just travel abroad and fails to bring up texts related to internal ethnic conflict, everyday interethnic communication, including hate speech, or national policies on ethnicity issues - everything that was considered important in this case study. We, therefore, wanted to discriminate between the algorithms good at retrieving international relations topics and those able to retrieve exactly what we want - ethnic discourse
We have collected the answers of seven assessors; Table 3 summarizes total intercoder agreement values, showing the share of differing answers for every question. In general, these results show good convergence between the assessors, on the level of our previous experiments with similar evaluation 26. When the assessors disagreed in assigning a topic to a category, rather than averaging their results we produced two sets of scores: in the first set, we assigned each topic a maximum from the assessors’ scores; in the second set, we did the opposite -that is, assigned a topic the minimal score. We thus obtained the upper and the lower bounds of the human judgment and compared the models.

For every model, Table 4 also shows the average tf-idf coherence metric. Note that although our results match previous experiments regarding the comparison between coherence and tf-idf coherence well (correlation with tf-idf coherence is in our experiments approximately 10-12% better than correlation with standard coherence), still in this study human judgments correlate with tf-idf coherence only at the level of approximately 0.5, so there is still a long way ahead to develop better quality measures.
Table 4 Experimental results: general interpretability and coherence for partially, highly, and generally interpretable models

Since the models we test here all attempt to extract a certain number of high-quality topics while filtering out “trash” topics into a specially created “ghetto”, it makes little sense to compare the models by the overall quality of all topics. It is much more important to look at the coherence of those topics that were found either good or relevant by the assessors.
4.4 Relevance and Coherence Scores
Table 4 summarizes the most important results on quality understood as interpretability (question 2) and its relation to tf-idf coherence. In this table, “partially interpretable” topics are those that were scored “1” by at least one of the assessors answering question 2; “highly interpretable” are those that were scored “2” respectively (but it is enough for only one assessor to give the high mark, i.e. this is the optimistic evaluation). The two leaders are models 5 and 6 (restricted dictionary and extended dictionary, respectively). We can see in Table 4 that model 6 (extended dictionary) outperforms all the rest by the overall quality, that is, by coherence and tf-idf coherence calculated over all topics. Model 5 (restricted dictionary) does produce higher values of coherences and tf-idf coherences in the groups of interpretable topics, but note that the number of interpretable topics is lower. This means that model 5 finds fewer topics, but the topics it finds are on average better.
Table 5 summarizes our most important findings regarding how relevant the topics are to our goal. “Partially relevant” topics are those that were scored “1” by at least one of the assessors answering questions 5 and 6; “highly relevant” are, respectively, those that were scored “2” by at least one assessor. “All relevant” topics in Table 5 include topics that are either partially or highly relevant to either ethnicity or international relations. Average interpretability was calculated as the mean evaluation scores given to the respective topics by assessors answering question 2. Here we again see the same two leaders, models 5 and 6, and the former outperforms the latter in terms of tf-idf coherence of relevant topics, while the latter outperforms the former in terms of the number of topics considered relevant by the assessors. This is true both for ethnic and international relations topics, and for both levels of relevance. This means that our extension of the seed dictionary brings more topics found by assessors both generally interpretable and relevant to both international relations and ethnicity, although average coherence of these topics becomes somewhat lower. Ethnic topics, thus, do not get substituted by or lost among topics on international relations.
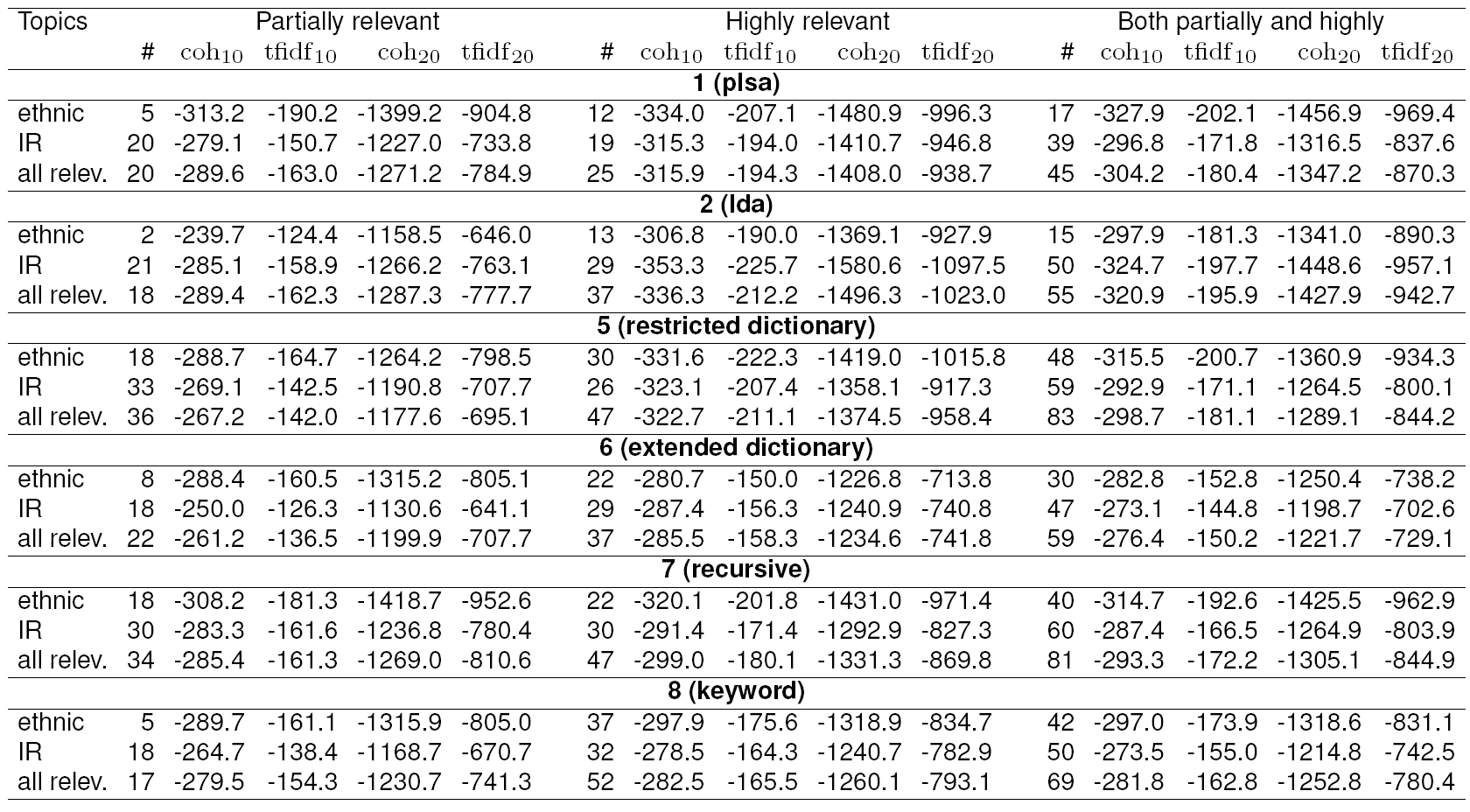
Table 6 shows human-evaluated interpretability of the topics: it shows the average score given by the assessors to topics from each subset and for the two general questions, e.g., the top left corner shows that on average, assessors scored 1.80 on question 1 (general interpretability) for topics that are highly relevant to ethnic issues. Note that, interestingly, now model 6 outperforms model 5 in terms of interpretability: according to this measure, in model 6 relevant topics are not only more numerous, but also slightly more interpretable than in model 5; however, fewer of them are clearly related to specific events (question 2). For sociologists, a larger number of relevant topics is an advantage since they are not very numerous anyway and can be double-checked for relevance and interpretability manually, while, had they been filtered out automatically, they may never be brought to the expert’s attention, so model 6 looks preferable.
Table 6 Interpretability results for the topics relevant for ethnic and international relations subjects
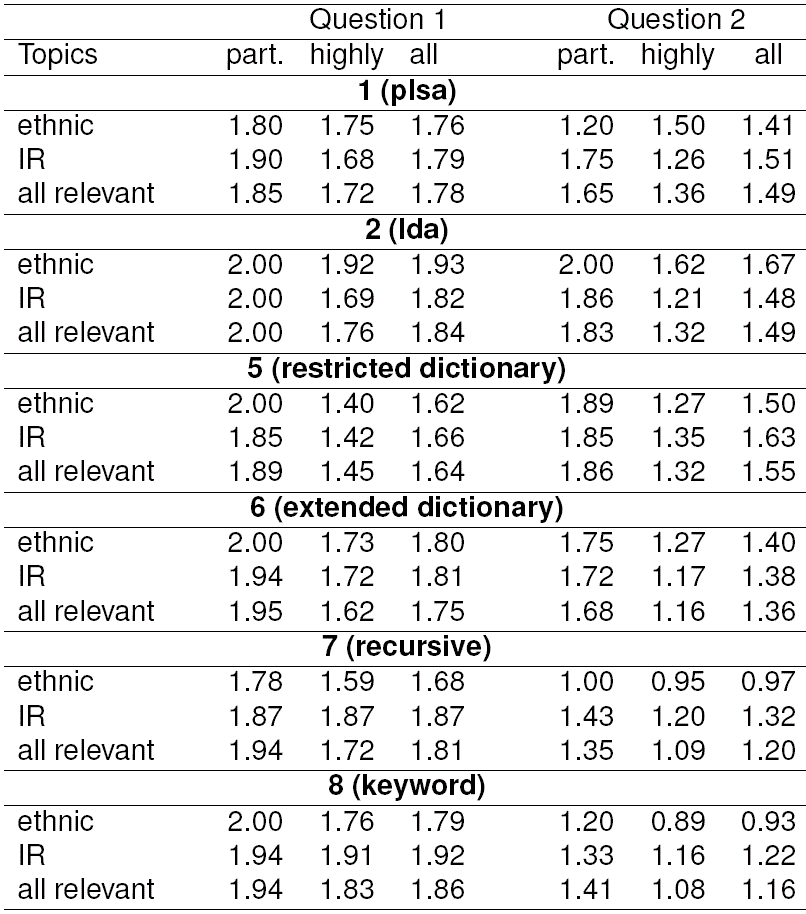
At the same time, the dictionary of model 6 has been situational: it substituted the missing ethnonyms with adjectives and country names, while the ethnic groups whose ethnonyms were present in the collection were not supplemented by adjectives or country names. This principle of dictionary construction means that different adjectives and country names should be excluded each time even if some of them are present in the collection. It also may have lead to some overfitting in our best model. To make this model more practical and the quality assessment more reliable, in the future we suggest to rerun it with the full dictionary of ethnonyms, adjectives and country names that will be made universal.
Interesting results are produced by models 7 (recursive) and 8 (keyword texts). By evaluating both the number of relevant topics and coherence, the recursive model looks similar to model 5 with restricted dictionary (fewer, but more coherent topics of interest); keyword-based model is similar to model 6 (more numerous and a little less coherent topics of interest) (see Table 3).
It, thus, means that re-iteration of topic modeling on a subset of texts extracted during the first iteration does not bring improvement, or even brings deterioration, and therefore is excessive and useless. In terms of numerical results, single-iteration modeling on a collection selected by keyword produces the results similar to or not dramatically worse than the best model (model 6), but the sets of ethnicity-related topics found by these two approaches are significantly different, so to get the best possible coverage one should probably use a combination of these techniques, one possible direction for further work.
4.5 Prefiltering and Two-Stage Topic Modeling
In the final series of computational experiments, we tested a natural extension of the ideas expressed in previous models: to filter the original collection with respect to the resulting subject topics and try topic modeling again. To test this idea, we have chosen documents from the original collection that contained top words from subject topics discovered on the previous step. Then, the much reduced collection was again subject to topic modeling; in this experiment, we have compared several variations of ARTM models. The reduced collection contained approximately 320K documents with the same set of ethnonyms as the large models.
The reduced collection has allowed us to perform a large-scale comparison of ARTM models with different parameters. In the paper, we show a sample of nine models with characteristic parameters that may result in different behaviour. Table 7 shows their parameters; note that model 9 has the same parameters as model 8 but has been trained for three epochs over the entire dataset compared to a single pass in model 8.
Table 7 Second stage topic models. Model 9 is the same as model 8 but with three passes instead of one

To make the results comparable with full models, we have trained all models with the same number of topics, 250 subject (ethnic) topics and 150 general (background) topics and computed coherence scores on the entire dataset rather than the reduced one (those scores would, naturally, be much better). Table 8 shows coherence results for new models. The top nine rows show average coherence scores for all topics and can be directly compared with Table 2; we see that the best second-stage models. models 4 and 5, have better coherence scores than the best first-stage models from Table 2. Comparing models 8 and 9, we also see that additional passes over the corpus do indeed improve the topics but only very slightly, so in case of a large corpus, when it is costly to double or triple the training time, one pass should be sufficient.
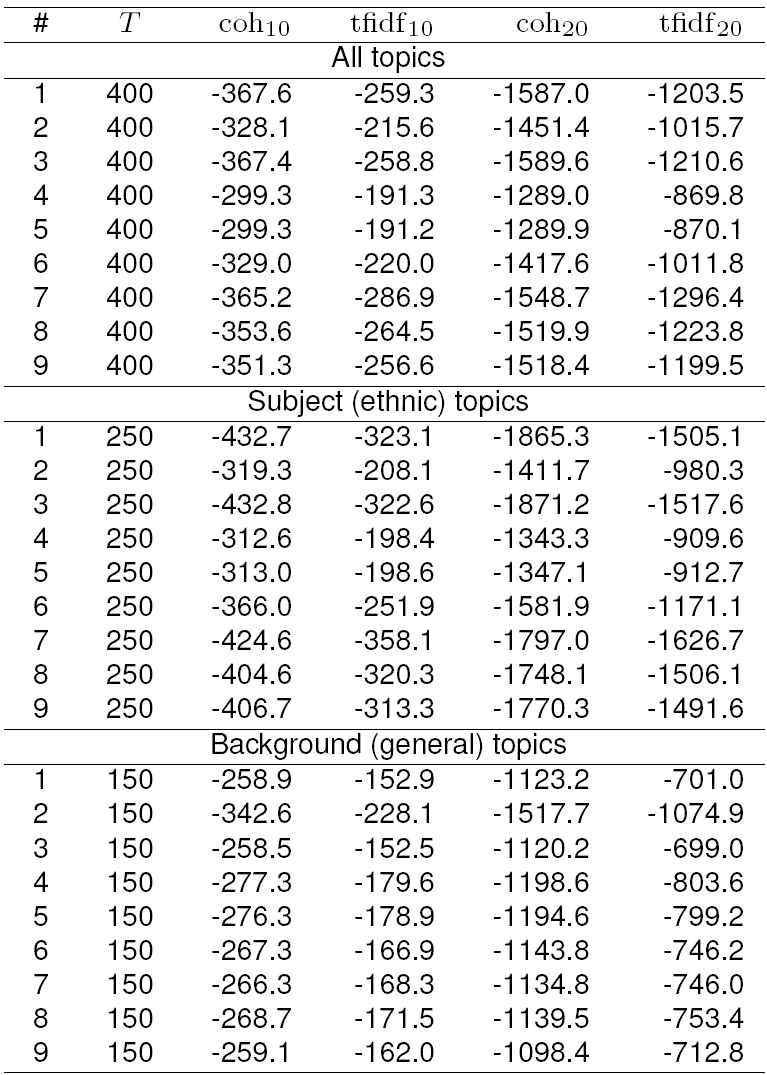
Table 8 also provides separate average esti mates for coherences and tf-idf coherences of subject (ethnic) and background (general) topics. Note an interesting effect: backgroundtopics have consistently better scores than subject topics across all models. This is due mainly to the fact that we have chosen a far larger number of ethnic topics (250) than necessary since we need to make sure all ethnic topics are captured by the model, and a false positive (a junk ethnic topic) is not a problem. We show some sample topics from one of the best second stage models in Table 9. While ethnic topics do indeed have plenty of good ethnic- or nationality-related topics, they also have a lot of uninterpretable junk topics (e.g., topics 92 and 232 in Table 9); at the same time, background topics are not ethnic-related but are indeed more coherent on average.

5 Conclusion
In this work, we have shown that additive regularization of topic models (ARTM) can provide social scientists with an effective tool for mining specific topics in large collections of user-generated content. Our best model has outperformed basic LDA both in terms of the number of relevant topics found and in terms of their quality, as it was found in experiments with topics related to ethnicity.
What is especially important for digital humanities, additive regularization allows one to easily construct nontrivial extensions of topic models without mathematical research or software development. By combining built-in regularizers Background (general) topics Subject (ethnic) topics from the BigARTM library, one can get topic models with desired properties. In this work, we have combined eight regularizers and constructed a topic model for exploratory search that can take a long list of keywords (in our case, ethnonyms) as a query and output a set of topics that encompass the entire relevant content. This model can be used to explore narrow subject domains in large text collections. In general, this study shows that ARTM provides unprecedented flexibility in constructing topic models with given properties, outperforms existing LDA implementations in terms of training speed, and provides more control overthe resulting topics. Both specific regularizers introduced here and the general ARTM approach can be used in further topical studies of text corpora concentrating on different subjects and/or desired properties of the topics.
However, further experiments are needed to make our comparisons more precise. First, it would be interesting to compare our best model with semi-supervised non-interval LDA, where, instead of ascribing small bunches of words to multiple small ranges of topics, the entire dictionary would be ascribed to a large range of topics (akin to ARTM-produced models). Second, as has been mentioned above, it would be interesting to experiment with the universal dictionary of ethnonyms, adjectives, and country names. Finally, the results should be tested for stability via multiple runs of each model; stability of topic models is an interesting problem in its own right 18. In general, semi-supervised learning approaches exhibit a good potential for mining not only ethnicity-related topics but also other types of specific topics of which the end-users may have incomplete prior knowledge.

