











 nova página do texto(beta)
nova página do texto(beta) Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink1 Introduction
Recognizing Textual Entailment (RTE) is a task that consists in the following: given a pair of text fragments, decide whether the meaning of one fragment (referred to as the hypothesis H) can be derived from that of the other (referred to as the text T), i.e., whether there is a directional relationship called entailment between the two input fragments. Note that if the meaning of Η can be deduced from the meaning of T, the opposite may not be true. The RTE task has very important applications in many natural language processing (NLP) areas, such as information retrieval, text summarization, question answering, information extraction, reading comprehension, paraphrase acquisition, e-learning 15, opinion mining, and machine translation, to name just a few.
The task of accurately labelling a pair of text fragments as textually entailed or not is attracting increasing attention of the NLP community. Due to its importance, the PASCAL (Pattern Analysis, Statistical Modelling and Computational Learning) network has organized the corresponding competitions, also called RTE.
Consider an example from the PETE development set:
T: He would wake up in the middle of the night and fret about it.
H: He would wake up.
Here, the truth value of Η can be inferred from T. However, Τ contains some extra information not contained in H, therefore Τ cannot be inferred from H, while part of the information contained in Τ is sufficient to verify the truth value of H. Thus, textual entailment (TE) is a unidirectional relation which holds from Τ to H, but not vice versa.
In this paper, we present a rule-based textual entailment method based entirely on dependency parsing. Two separate parse trees are generated for the text and for the hypothesis using a dependency parser. Each dependency triple of the hypothesis Η is compared against all triples of the text Τ to find a possible matching pair. If a match is found according to any of the six matching rules we developed, then the child node of the dependency triple is assigned a matching score 1. This process is repeated for all dependency triples of the hypothesis, and the corresponding child nodes are assigned scores basing on successful match. Finally, the dependency tree is traversed in post-order way to propagate the final entailment score to the root node. The entailment score for a T-H pair is in the range from 0 to 1; the maximum score of 1 indicates that the hypothesis Η is completely contained within the text T. This score is checked against a threshold value learnt from the PETE development set to make the final entailment decision: a score above the threshold indicates entailment and that below the threshold indicates absence of entailment.
Evaluation on the PETE dataset shows 87.69% accuracy on the development set and 73.75% accuracy on the test set. This is higher than state-of-the-art results reported on this dataset so far.
The rest of the paper is organized as follows. Section 2 describes related work, which is mainly focused on recognizing textual entailment basing on the syntactic structure of a sentence using dependency relations. Section 3 describes our method. Experimental results are presented in Section 4. Section 5 gives error analysis. Finally, Section 6 concludes the paper and outlines future research directions.
2 Related Work
A number of methods have been proposed for RTE in recent years. Many of them simply use some form of lexical matching such as simple word overlap, η-gram matching, skip-gram matching, etc. Some systems represent the pair of text fragments as syntactic dependency parse trees before the actual processing. Many systems also use semantic relations such as semantic role labelling or logical inference.
The work by Rios and Gelbukh 25 is based on the assumption that a given text-hypothesis pair holds an entailment relation if there exists a sequence of edit operations that can be performed on Τ to produce Η with an overall cost below a certain threshold. This approach needs to represent the input pair of text fragments in the predicate-argument structure format.
The approach described by Blake 1 has demonstrated that the sentence structure alone plays an important role in recognizing textual entailment.
The textual entailment recognition system by Vanderwende et al. 30, 31 represents the T-H pair as graphs of syntactic dependencies generated by the NLPwin parser. The system tries to align each node in Η with a node in Τ using a set of syntactic heuristics. The main motivation behind this task was to recognize false entailment.
In the dependency parser-based textual entailment system by Pakray et al. 18, two separate parse trees were generated by using CCG and Stanford parser separately. Then the hypothesis relations were compared with the text relations on the basis of various features, and different weights were assigned to exact and partial matches. Finally, all these weights were summed up and checked against a threshold value to make the final entailment decision.
Rus et al. 26 and Herrera et al. 11 used the degree of graph subsumption, or graph inclusion. The dependency tree structure of Η was examined to find whether it can be completely or partially mapped to the tree of T.
Marsi et al. 16 used the concept of normalized alignment of dependency trees for the RTE task.
The architecture of the system by Kouylekov et al. 14 uses a tree edit-distance algorithm on the T-H dependency tree pair in order to map the tree of Η to the tree of T. If the distance, i.e., the cost of editing operations, between the two trees is below a certain threshold, then the text Τ is said to entail H.
Haghighi et al. 10 adopted a graph-based representation of sentences and used a graph-matching approach to measure the semantic overlap of the two texts. They developed a learned graph-matching approach to approximate entailment using the amount of the sentence's semantic content that is contained in the text.
Pakray et al. 20 used the Universal Networking Language (UNL), which is a formalism similar to dependency parsing representation, in order to find relations between words in a sentence, which were then used in an unsupervised framework for RTE.
Wang and Neumann 32 proposed a structure-oriented entailment method that constructed a sentence similarity function operating on the T-H pair. Erwin et al. 8 presented a syntax-based paraphrasing method for recognizing textual entailment that used the DIRT dataset. Paraphrase and textual entailment has been considered for languages other than English 17.
Sidorov 27 introduced various types of syntactic triples and, more generally, syntactic n-grams, which can be used in the way similar to our use of syntactic triples. Unsupervised learning methods have been applied for disambiguation of syntactic dependencies 9.
Apart from RTE, dependency tree-based patterns have been also proved to be a powerful tool for sentiment analysis 21, aspect extraction in opinion mining 3, 22, and text-based personality recognition 23.
On the other hand, a large body of literature has been devoted to measuring text similarity using various techniques. Syntactic η-grams have been used by Calvo et al. 2 to measure text similarity in a way similar to our proposal. Other recent proposals include such measures as soft cardinality 13, soft cosine measure 28, graph distance metrics 7, semantic and discourse-based measures 6, as well as relational features and latent topic detection 12.
3 The Method
A flowchart of the proposed method is presented in Fig. 1. The individual modules are presented in the following sections.

3.1 Pre-Processing
This module takes a text-hypothesis pair and checks for the presence of contracted tokens. In case of the presence of such tokens, they are replaced by their corresponding expanded forms listed in Table 1, because the dependency parser produces erroneous output for such contracted tokens; therefore, it is necessary to replace them before further processing.
Table 1 Token replacement
| Contracted tokens | Expanded forms |
|---|---|
| didn't | did not |
| aren't | are not |
| that'll | that will |
| hadn't | had not |
| it's | it is |
| I've | I have |
| they're | they are |
The next step of pre-processing is to find the root form of each word. We used the Porter stemming algorithm 24. This is a very important step because the text and the hypothesis may contain different word-forms of the same base form; which will not match according to any of the matching criteria, resulting in an incorrect score assignment, which leads to wrong entailment decision.
3.2 Dependency Parsing
The modified text-hypothesis pairs are passed on to the dependency parsing module. In the present work, we used the Stanford dependency parser1 for this purpose. The output of this module is a set of dependency triples. A dependency triple produced by the parser consists of three parts in the form R(N1, N2), where N1 and N2 are two words in the sentence connected by the relation R.
An example of a text-hypothesis pair from the PETE development set is:
T: Thus committed, action might follow.
H: Action might follow.
For this T-H pair, the dependency parser generates the set of triples shown in Table 2.
3.3 Dependency Tree Representation
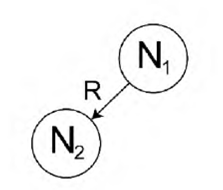
A complete dependency parse tree is built by combining all the dependency triples generated in the previous stage. For each word in a sentence, a separate node is created. Each dependency triple is represented as an arc in the parse tree. The first word of the triple N1 is the parent node of the arc and the second word N2 is the child node linked to that parent by the relationship R. Thus, for a dependency triple in the form R(N1,N2), an arc is created as shown in Fig. 2.
3.4 Comparing Dependency Trees
Each dependency triple of the hypothesis Η is compared against all triples of the text Τ in search of a matching pair. If a match is found according to any one of the six matching criteria listed below, then the child (dependent) node N2 H of that arc in the hypothesis parse tree is assigned a matching score of 1; if none of the following matching criteria is satisfied for any triple of the hypothesis, a 0 score is assigned to the node N2 H of that triple. The matching criteria are stated below in detail and are illustrated by corresponding diagrams.
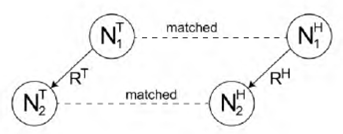
Rule 1. This rule corresponds to the complete triple match. If a dependency triple RH(N1 H, N2 H) of the hypothesis Η entirely matches a dependency triple RT(N1 T, N2 T) of the text T, then the child node N2 H of the dependency triple of Η is assigned a parent matching score of 1. The entailment score calculation component of a node is described in Section 3.5. A few examples are listed in Table 3 to illustrate complete triple match. Fig. 3 illustrates this matching rule.
Table 3 Examples satisfying matching rule 1
| RT and RH | T-H pairs | Dependency triples |
|---|---|---|
| T: For the fifth consecutive month, purchasing | ||
| nsubj | managers said prices for the goods they purchased fell. | nsubj(fell-15, prices-9) |
| H: The prices fell. | nsubj(fell-3, prices-2) | |
| T: My host went over and stared out the window at his | ||
| dobj | peacocks; then he turned to me | dobj(stared-6, window-9 |
| H: Somebody stared out the window | dobJ(stared-2, window-5 |

Rule 2. If the nodes N2 H and N1 H of a dependency triple of Η match N1 T and N2 T, respectively, of a dependency triple of T, but the relations RH and RT do not match, while the dependency relation RT belongs to the set
{vmod, amod, rcmod, ccomp, advcl},
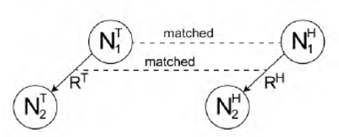
then the cases listed in Table 4 are checked for matching. Upon finding a successful match, the child node N2 H of the triple of Η is assigned a parent matching score of 1. Examples of text-hypothesis pairs satisfying this rule are given in Table 4. Rule 2 is illustrated in Fig. 4.
Table 4 Examples satisfying matching rule 2
| RT | RH | T-H pairs | Dependency triples |
|---|---|---|---|
| vmod | nsubj | T: Producers have seen this market opening up and they are now creating wines that appeal to these people. | vmod(market-5, opening-6) |
| H: The market is opening up. | nsubj(opening-4, market-2) | ||
| amod | nsubjpass | T: Occasionally, the children find steamed, wholewheat grains for cereal which they call 'buckshot'. | amod(grains-7,steamed-5) |
| H: Grains are steamed. | nsubjpass(steamed-3, Grains-1) | ||
| ccomp | advcl | T: If he was sober, which was doubtful, he would have him get in touch with Mr. Crombie. | ccomp(sober-4, doubtful-7) |
| H: It is doubtful, if he was sober. | advcl(doubtful-3, sober-7) | ||
| rcmod | dobj | T: It required an energy he no longer possessed to be satirical about his father. | rcmod(energy-4, possessed-8) |
| H: Somebody no longer possessed the energy. | dobj(possessed-4, energy-6) | ||
| rcmod | nsubj | T: l reached into that funny little pocket that is high up on my dress. | rcmod(pocket-7, is-9) |
| H: The pocket is high up on something. | nsubj(is-3, pocket-2) |

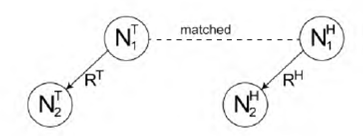
Rule 3. If the nodes N1 H and N2 H of a dependency triple in Η match N1 T and N2 T, respectively, of a dependency triple of T, but the relations RH and RT do not match, then for the cases listed in Table 5, the child node N2 H of the hypothesis dependency triple is assigned a parent matching score of 1. Table 5 presents examples of T-H pairs satisfying this rule. Fig. 5 illustrates this matching rule.
Table 5 Examples satisfying matching rule 3
| RT | RH | T-H pairs | Dependency triples |
|---|---|---|---|
| T:The Big Board also added computer capacity to | |||
| dobj | nsubjpass | handle surges in trading volume | dobj(added- 5, capacity-7) |
| H: Computer capacity was added | nsubjpass(added-4,capacity-2) | ||
| nsubj | nsubjpass | T:Totals include only vehicle sales reported in period | nsubj(reported-6, sales-5) |
| H: The sales were reported | nsubjpass(reported-3, sales-2) |
Rule 4. If the node N1 H and relation RH of a triple of Η match N1 T and RT, respectively, of a triple in T, but the node N2 H does not match N2 T, and the relation belongs to the set
{nsubj, dobj, pobj}
the matching criteria listed in Table 6 are checked. If any of these criteria is satisfied, the child node N2 H of that triple is assigned a parent matching score of 1. Some examples are presented in Table 6, and Fig. 6 illustrates this matching rule.
Table 6 Examples satisfying the matching rule 4
| N2 H | T-H pairs | Dependency triples | |
|---|---|---|---|
| nsubj | somebody someone something it | T: It required an energy he no longer possessed to be satirical about his father. H: Somebody no longer possessed the energy. | nsubj(possessed-8, he-5) nsubj(possessed-4, Somebody-1) |
| dobj | something somebody | T: That was where the pegboard would go on which he would hang his hand tools. H: He would hang something. | dobj(hang-12, tools-15) dobj(hang-3, something-4) |
| pobj | something somebody | T: / reached into that funny little pocket that is high up on my dress. H: The pocket is high up on something. | pobj(on-12, dress-14) pobj(on-6, something-7) |
| nsubjpass | somebody | T: It said the man, whom it did not name, had been found to have the disease after hospital tests. H: Somebody had been found to have the disease. | nsubjpass(found-12, man-4) nsubjpass(found-4, somebody-1) |
| advmod | somewhere somehow | T: That was where the pegboard would go on which he would hang his hand tools. H: The pegboard would go somewhere. | advmod(go-7, where-3) advmod(go-4, somewhere-5) |
Rule 5. If node N1 H of a hypothesis triple matches that of N1 T of a triple of T, but neither N2 H nor RH matches that of N2 T and RT, then only for the cases presented in Table 7, the child node N2 H is assigned a parent matching score of 1. An example is given in Table 7, and Fig. 7 illustrates this rule.
Table 7 Example satisfying matching rule 5
| RT | RH | T-H pairs | Dependency triples |
|---|---|---|---|
| T: "Last year we probably bought one out of every | |||
| prep | dobj | three new deals," he says. | prep(bought-5, of-8) |
| H: Someone bought deals | dobj(bought-2, deals-3) |
Rule 6. There are some insignificant relations that we have identified after a thorough study of the PETE dataset. These insignificant relations are as follows:
{aux, auxpass, cop, det, expl, mark, nn, pit, predet}.
Wherever two nodes N1 H and N2 H in a triple are connected by any of these relations, the child node N2 H of that triple is assigned a parent matching score of 1. When ignoring these insignificant relations, the overall entailment score at the root node often is decreased and falls below the threshold value, which results in an incorrect entailment decision. So these relations, although seem to be less important, should also be considered.
3.4 Entailment Score Calculation
The score of each node NH in the hypothesis dependency parse tree is divided into three components: the parent score (p_score), the child score (c_score), and the total score (t_score).
The previous comparison module assigns a matching score of 1 to the p_score component of a node N2 H if any of the six matching criteria is satisfied for the dependency triple RH(N1 H,N2 H). Otherwise, a score value of 0 is assigned to the p_score component of the node N2 H of the dependency triple.
After assigning matching score to the p_score components of all the nodes in the hypothesis parse tree, the parse tree is traversed in bottom-up fashion from the leaf nodes to the root node, the scores for non-leaf nodes being calculated by traversing the tree in the post-order way. Since the leaf nodes have no children, their c_score component is set to 0 and the t_score component is set to the value of their p_score. For a non-root non-leaf node, the c_score is calculated by taking the average of all the t_scores of its child nodes. Then its own t_score is set to the average of its p_score and c_score. Finally, the p_score component of the topmost node of the dependency tree immediately below the dummy ROOT node of the parse tree is assigned a value of 0 since it has no parent. The t_score of this node is set to the value of its c_score, which has already been calculated by the average of its immediate children.
The final t_score of the root node of the tree is considered as the entailment score of the T-H pair. It lies in the interval between 0 and 1. This entailment score is then used for making the entailment decision at the final stage of the algorithm. The rules used for assigning the scores to the various components of a node are summarized in Table 8. The diagram in Fig. 8 presents the different score components of the nodes in a parse tree, which are calculated following the rules listed in Table 8.
Table 8 Score assignment to the nodes in the parse tree
| Types of nodes | p_score | c_score | t_score |
|---|---|---|---|
| Leaf node | 1 on successful match 0 otherwise. | 0 | p_score |
| Non-leaf non-root node | 1 on successful match 0 otherwise. | Average of the t scores of all its childTen. | 1 4 (p_score + c_score) |
| Topmost node next to ROOT | 0 | Average of the t scores of all its children. | c_score |
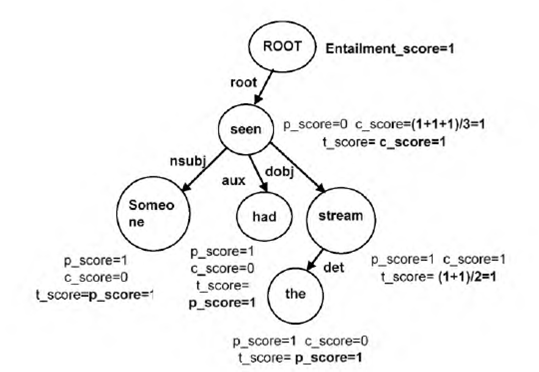
Consider the following T-H pair from the PETE development set:
T: He could also hear the stream which he had seen from his position.
H: Someone had seen the stream.
The output of the Stanford dependency parser for this T-H pair is shown in Table 9. Table 10 lists the hypothesis triples, their corresponding matching text triples, the matching rules satisfied by each of them, and the actions taken on successful matching. Fig. 8 shows the score components of the nodes in this parse tree.
Table 9 Example of dependency triples of a T-H pair
| Text triples | Hypothesis triples | ||
|---|---|---|---|
| T1. | nsubj(hear-4,He-1) | ||
| T2. | aux(hear-4,could-2) | ||
| T3. | advmod(hear-4,also-3) | ||
| T4. | root(ROOT-0,hear-4) | ||
| T5. | det(stream-6,the-5) | H1. | nsubj(seen-3,someone-1) |
| T6. | dobj(hear-4,stream-6) | H2. | aux(seen-3,had-2) |
| T7. | dobj(seen-10,which-7) | H3. | root(ROOT-0,seen-3) |
| T8. | nsubj(seen-10,he-8) | H4. | det(stream-5,the-4) |
| T9. | aux(seen-10,had-9) | H5. | dobj(seen-3,stream-5) |
| T10. | rcmod(stream-6,seen-10) | ||
| T11. | prep(seen-10,from-11) | ||
| T12. | poss(position-13,his-12) | ||
| T13. | pobj(from-11,position-13) |
3.5 Entailment Decision
The final entailment score calculated at the previous step is then compared with a predefined threshold value. If it exceeds the threshold value, the T-H pair is marked as entailment; otherwise it is marked as having no entailment. The threshold was learned from the PETE development set. We used the same threshold to make the entailment decisions for all 301 T-H pairs of the PETE test set.
Evaluation results on the PETE dataset show 87.69% accuracy on the development set and 73.75% accuracy on the test set.
4 Experimental Results
We tested our system on the PETE development dataset, which consists of 66 T-H pairs. We experimented with different values of the threshold that controls the entailment decision as described in Section 3.5. We observed that the best performance, with accuracy of 87.69%, was achieved on the PETE development set for the threshold values in the range between 0.84 and 0.9.
Fig. 9 shows the accuracy of our system for different threshold values on the PETE development set. The accuracy reaches its peak when the threshold is 0.84, stays nearly constant in the interval between 0.84 and 0.9, and falls at 0.95.

The threshold value of 0.84, which optimizes the system performance on the PETE development set, was used to make the entailment decisions for all 301 T-H pairs of the PETE test set. The evaluation results obtained on the PETE test set are presented in Tables 11 and 12. The performance of our system in terms of accuracy is better than the highest-scoring system among all the teams participated in the SemEval 2010 task 12 33.
Table 10 Simulated matching rules on dependency triples
Table 11 PETE test set results
| Actual positive Entailment | Actual Negative Entailment | |
|---|---|---|
| System Positive Entailment | True Positive: 96 | False Positive: 19 |
| System Negative Entailment | False Negative: 6G | True Negative: 126 |
5 Error Analysis
Since in the development of the system we focused on the dependency triples, any two nodes connected in a triple of the hypothesis parse tree but not connected in the text's tree failed to be properly detected by any of our matching rules. There are several such examples for which our system gives erroneous results.
Example 1. Consider the following T-H pair from the PETE test set:
T: Moreland sat brooding for a full minute, during which I made each of us a new drink.
H: Someone made a drink.
The corresponding dependency triples generated by the Stanford parser are shown in Tables 13, 15 and 16.
Table 13 Dependency triples for the T-H pair in Example 1
| Text triples | Hypothesis triples | |
|---|---|---|
| T1. | nsubj(sat-2, Moreland-1) | |
| T2. | root(ROOT-0, sat-2) | |
| T3. | xcomp(sat-2, brooding-3) | |
| T4. | prep(brooding-3, for-4) | |
| T5. | det(minute-7, a-5) | |
| T6. | amod(minute-7, full-6) | |
| T7. | pobj(for-4, minute-7) | H1. nsubj(made-2, Someone-1) |
| T8. | prep(made-12, during-9) | |
| H2. root(ROOT-0, made-2) | ||
| T9. | pobj(during-9, which-10) | |
| H3. det(drink-4, a-3) | ||
| T10. | nsubj(made-12,1-11) | |
| H4. dobj(made-2, drink-4) | ||
| T11. | rcmod(minute-7, made-12) | |
| T12. | dobj(made-12, each-13) | |
| T13. | prep(each-13, of-14) | |
| T14. | pobj(of-14, us-15) | |
| T15. | det(drink-18, a-16) | |
| T16. | amod(drink-18, new-17) | |
| T17. | dep(us-15, drink-18) |
Our system failed to detect the entailment relation in this T-H pair, because for the nodes made and drink, which are connected in the hypothesis's parse tree, the parser failed to correctly identify a dependency relation in the text's tree. Thus these nodes failed to satisfy any of our matching rules. As a result, the p_score component of drink is set to 0 and the entailment relation was not detected.
Partial dependency parse trees of Τ and Η are shown in Fig. 10. All the score components of the nodes in the hypothesis are indicated in this figure. The overall entailment score is 0.75, which is below our chosen threshold value of 0.84. Therefore, the system marked this T-H pair as having no entailment. There have been several such cases where two nodes in one of the dependency trees were not connected in the other dependency tree. Such T-H pairs resulted in false negatives.

Example 2. Consider another T-H pair:
T: It wasn't clear how NL and Mr. Simmons would respond if Georgia Gulf spurns them again.
H: Simmons would respond.
In this case, the hypothesis sentence Η is completely contained in the text sentence T, and the words in the sentence Τ appear in the hypothesis in the same order. However, in this case the additional information in Τ appearing before the underlined part of the text contradicts the truthfulness of the hypothesis. Some of the dependency triples of this pair are shown in
Table 15. Here, the hypothesis triples Hi and H2 completely match the text triples T5 and T6, respectively, satisfying our matching rule 1.
Table 15 Dependency triples for the T-H pair in Example 2
| Text triples | Hypothesis triples |
|---|---|
| T2. cop(clear-4, was-2) | |
| T2. cop(clear-4, was-2) | |
| T3. neg(clear-4, not-3) | H1. nsubj(respond-3, Simmons-1) |
| T4. root(ROOT-0, clear-4) | H2. aux(respond-3, would-2) |
| T5. nsubj(respond-11, Simmons-9) | H3. root(ROOT-0, respond-3) |
| T6. aux(respond-11, would-10) |
Therefore, the system incorrectly reports such T-H pairs as entailment, being not sophisticated enough to infer the absence of entailment in this case. This T-H pair is an example of a false positive.
Example 3. Consider the following T-H pair:
T: And many in the young cast bear striking resemblances to American TV and movie personalities known for light roles.
H: Many bear resemblances to movie personalities.
In this case, the dependency parser again produces erroneous triples. Some of them are shown in Table 16. The parser fails to properly POS-tag the words in the hypothesis, which resulted in incorrect triples Hi and H2. So Hi and H2 do not match the text triples T2 and T9, respectively, and the system fails to properly identify entailment in this T-H pair. Such types of errors occur due to wrong parsing and not due to limitations of the method itself.
Table 16 Dependency triples for the T-H pair in Example 3
| Text triples | Hypothesis triples |
|---|---|
| T1. cc(bear-7, And-1) | |
| T2. nsubj(bear-7, many-2) | |
| T3. prep(many-2, in-3) | |
| T4. det(cast-6, the-4) | |
| T5. amod(cast-6, young-5) | |
| T6. pobj(in-3, cast-6) | |
| T7. root(ROOT-0, bear-7) | |
| T8. amod(resemblances-9, striking-8) | H1. amod(bear-2, Many-1) |
| T9. dobj(bear-7, resemblances-9) | H2. nsubj(resemblances-3, bear-2) |
| T10. prep(bear-7, to-10) | H3. root(ROOT-0, resemblances-3) |
| T11. amod(TV-12, American-11) | H4. prep(resemblances-3, to-4) |
| T12. pobj(to-10, TV-12) | H5. nn(personalities-6, movie-5) |
| T13. cc(TV-12, and-13) | H6. pobj(to-4, personalities-6) |
| T14. nn(personalities-15, movie-14) | |
| T15. conj(TV-12, personalities-15) | |
| T16. vmod(TV-12, known-16) | |
| T17. prep(known-16, for-17) | |
| T18. amod(roles-19, light-18) | |
| T19. pobj(for-17, roles-19) |
6 Conclusion and Future Work
We have presented a method for recognizing textual entailment that relies solely on the dependency tree matching. Since our aim was to emphasize the role of dependency structure in the task of recognizing textual entailment, we avoided the use of any enhancements or any resources other than a dependency parser. Even with this restriction, our method outperforms all systems that participated in the SemEval 2010 task 12.
Besides simply matching dependency triples, the system makes use of six rules that account for slight differences in the syntactic structures in the text and the hypothesis, to improve the accuracy of the textual entailment recognition. Since we tested our system only on the PETE dataset, which exhibits mainly syntactic differences in the text and the hypothesis, we concentrated primarily on soft matching of syntactic structures and did not feel a need in the use of any additional lexical resources or involving semantic similarity calculations in our system.
Only identifying the base forms of the words using the Porter stemming algorithm followed by applying the matching criteria was sufficient to assign a binary matching score of 1 or 0 to each node in the hypothesis dependency parse tree. We used equal weighting in assigning the matching scores to the nodes in the parse tree: when any of the six matching rules was satisfied, a matching score of 1 was assigned to a node, thus giving equal importance to all the matching rules. These matching scores were then propagated in a bottom-up fashion by post-order tree traversal to the root node, with which the final entailment score was obtained.
Thus the presented algorithm is deliberately simplistic and can be improved and generalized in many ways. Still this simple method has proved to be quite effective in correctly labelling a significant percentage of T-H pairs as representing or not representing entailment. The method is completely rule-based and the matching rules have been developed after a thorough and minute analysis of the development set. Only string comparison was used for matching.
In future work, we expect to augment the system with semantic similarity measures so that it can capture both syntactic divergence as well as semantic similarity. We also expect to explore the UNL parser for the system to be able to efficiently capture the entailment relations. Anaphora resolution as a pre-processing step for the textual entailment 5, 19 and application of advanced text similarity measures (4, 29) are also parts of our future works.

