











 texto en
texto en  Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
En la administración de riesgo existe el problema de más de una fuente de incertidumbre; este es el caso de administrar simultáneamente el riesgo de precio y riesgo de rendimiento. El primero representa el riesgo de mercado y el segundo el riesgo sistemático. Una forma de administrar el riesgo de precio es emplear coberturas en un mercado de futuros, una cobertura cruzada como la ofrece ASERCA (Agencia de Servicios a la Comercialización y Desarrollo de Mercados Agropecuarios) (Martínez y García, 2010). Otra alternativa es implantar un programa de precios de garantía (Martínez, 1990), política que ya no es posible aplicar por los tratados comerciales. Esto es más complicado respecto al riesgo sistemático, pues hay numerosos factores, como climáticos o enfermedades, que son fuente de incertidumbre; así, generar un esquema multi-peligro es limitado porque los eventos a cubrir son muchos (Goodwin, 1993). Aun sin eventos catastróficos el rendimiento tiene variación natural que afecta el ingreso de los productores. La motivación para administrar riesgo de precio o rendimiento separadamente es baja, ya que cada uno ofrece solo protección parcial; la alternativa es administrar riesgo de ingreso (Hennessy, 1998). El problema principal radica en la dependencia entre precio y rendimiento, y entre precios y rendimientos cuando se considera más de un punto de planeación. Para asegurar un ingreso, un productor adverso al riesgo puede estar dispuesto a pagar una prima a cambio de tener un ingreso mínimo asegurado en el caso de variación de precio o rendimiento. Sin embargo, las condiciones de mercado limitan la posibilidad de ofrecer este tipo de seguro por tener que considerar simultáneamente fuentes de riesgo no independientes. Es decir, los oferentes de seguro pueden no presentar una alternativa de póliza de ingreso ante la incapacidad de modelar simultáneamente precio y rendimiento. Una póliza de precio es difícil de operar debido a que para productores, en un mismo lugar, los precios recibidos tienden a moverse en la misma dirección; una compañía debería tener suficientes productores asegurados de distintas procedencias para amortiguar este problema y lo mismo sucede para asegurar un rendimiento (Miranda, 1991). En este caso el rendimiento puede afectarse por heladas, inundación, granizo, plaga o enfermedad. Como cada una es un riesgo es más factible englobar la incertidumbre en riesgo de rendimiento. La presencia de correlación positiva para un mismo lugar es un problema.
Aun así, la intención de administrar riesgo en agricultura puede ser asegurar un ingreso mínimo, lo que implica incertidumbre de precio y rendimiento. El objetivo de este estudio fue modelar la dependencia entre precio y rendimientos para cuatro de los principales estados productores de maíz (Zea mays L.) en México. La dependencia considera la correlación entre precio y rendimiento dentro de un mismo estado, y la correlación de precios y rendimientos entre distintos estados. La hipótesis fue que al modelar la dependencia entre precio y rendimiento el riesgo de ingreso se puede administrar sin recurrir a dos instrumentos, uno de precio y otro de rendimiento, de manera separada.
Materiales y Métodos
Los datos de precios y rendimientos evaluados corresponden a los estados de Sinaloa, Jalisco, Estado de México y Chiapas, México, con frecuencia anual de 1980 a 2014; estos estados son los de mayor producción nacional de maíz (Sistema de Información Agroalimentaria de Consulta-Secretaría de Agricultura, Ganadería, Pesca y Alimentación; SIACON-SAGARPA[2]). Cada estado presenta variación en precio y en rendimiento, dependiente de la tecnología empleada y de la intensidad en el uso de insumos. Excepto la oportunidad de vender al exterior del estado, a mayor rendimiento hay menor precio; además, la decisión de producir maíz en un estado puede estar influenciada por el precio y rendimiento en otros estados. En la determinación de ingreso de un productor, interviene el resultado de precio por el rendimiento, aquí se modela que lo que interesa al productor es el ingreso. El ingreso por hectárea de maíz producido en un estado requiere considerar la dependencia de precio y rendimiento; así como la dependencia de precio y rendimiento con otros estados.
Una forma de modelar las fuentes de incertidumbre es emplear una función cópula. Estas funciones se emplean para modelar riesgo bajo dependencia entre precio y rendimiento en el comercio entre productores de cebada canadienses y malteros estadounidenses (Bekkerman et al., 2014), en la evaluación del programa de seguro agrícola bajo distintas alternativas de función cópula (Goodwin y Hungerford, 2015) y en el cálculo del valor en riesgo de un portafolio cambiario (Plascencia, 2012). En cada uno de estos casos lo fundamental es modelar la dependencia entre variables aleatorias y enriquecer al análisis multivariado. La atención en nuestro estudio es la dependencia entre precio y rendimiento, al modelar el ingreso por hectárea y así administrar el riesgo de dicho ingreso.
Una función cópula es una función de distribución conjunta p-variada cuyas marginales son uniformes (Nelsen, 2006):
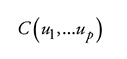
donde C( ) tiene soporte definido en Rp sobre el hiper-plano [0,1]p e imagen definida en R1 [0,1], y ui denota la distribución uniforme sobre el intervalo [0,1]. Si se tienen Y 1, Y2,... Yp variables aleatorias con funciones de distribución F1, F2,... Fp y función de distribución conjunta F(Y1, Y2,... Yp), entonces una función cópula si existe es tal que:
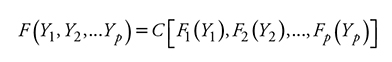
La función cópula, si existe, es única y puede obtenerse como:

Una propiedad importante es que la densidad conjunta puede representarse como el producto de la densidad de la cópula por el productorio de las marginales individuales:

Del Teorema de Skalar (Nelsen, 2006) la densidad de la cópula es definida como:

Esto destaca que solo con variables aleatorias independientes, la conjunta puede factorizarse como el producto de las marginales respectivas. Sin embargo, aquí radica la importancia práctica de las funciones cópula, ya que se puede modelar la dependencia separadamente de las distribuciones marginales.
Resultados y Discusión
En nuestro estudio se ajustaron distribuciones para los precios respectivos y rendimientos de maíz para los estados de: Sinaloa, Jalisco, Estado de México y Chiapas, lo que mostró ocho variables aleatorias en total. Un primer problema en este ajuste es que datos de precio y rendimiento presentan tendencia; esta última mueve la media en el tiempo y debe ser considerado al momento de ajustar una distribución. Respecto a precio la tendencia está compuesta de los efectos de la inflación (incrementando la media), de productos relacionados y efecto de importaciones que reducen la media. Por tanto, se sustrajo la tendencia con un algoritmo no-paramétrico consistente en ajustar rectas de regresión a un subconjunto de puntos en una vecindad de los valores observados en forma iterativa, una descripción detallada se encuentra en Cleveland et al. (1988). La ventaja de este proceder es que no obliga a asumir un modelo particular de predicción, lo que elimina el error de especificación, a la vez que se modelan las propias oscilaciones de los datos. Los datos empleados en el ajuste de las distribuciones de precio fueron obtenidos como:

donde yt es el dato empleado para ajustar las
distribuciones marginales, ŷp2014 es el valor
predicho para el año 2014 y
Con estos datos libres de tendencia se ajustó una distribución a los rendimientos y precios de cada estado. Aun después de eliminar la tendencia el precio es una variable aleatoria, cuyas variaciones obedecen a cambios inesperados en precios de insumos, de productos relacionados y del maíz importado, lo que se modela a través de una función de distribución. Dado que tanto precios como rendimientos son valores positivos se usaron distribuciones con soportes positivos, obteniendo buenos ajustes bajo las distribuciones Wald, Gama y Beta (Bekkerman et al., 2014; Goodwin y Kerr, 1988). Dichas distribuciones se emplearon como marginales en el ajuste de funciones cópula. Las cópulas gaussiana y t se probaron; estas funciones son apropiadas cuando la naturaleza de la dependencia proviene mayormente de los datos alrededor de la media, como se esperaría en datos de precio y rendimiento.
Sean uj ~U(0,1) para j=1,2,...,m donde m es el total de variables aleatorias empleadas, y U denota la distribución uniforme sobre el intervalo [0,1]; sea Σ una matriz de correlaciones positiva semi-definida, entonces la función cópula normal se puede escribir como:
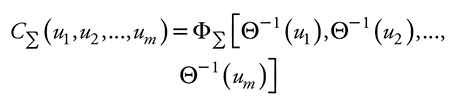
donde ΦΣ: denota la función de distribución normal m-variada con media un vector de ceros y matriz de covarianzas Σ y Θ-1: denota la función normal inversa. En este caso se desconoce Σ, el ajuste consiste en estimar esa matriz paramétrica.
Sea C(ν,Σ)la función t cópula con ν ϵ(1,...,∞) y Σ una matriz de correlaciones, sea tν una distribución t univariada con media cero y ν grados de libertad, y la función t cópula se puede escribir como:
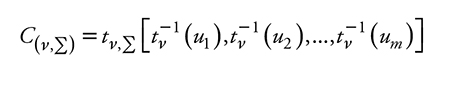
donde tν,Σ es una distribución t, m-variada con ν grados de libertad y matriz de correlaciones Σ y t-1v(uj) denota la inversa de la distribución t con ν grados de libertad. En este caso lo que se desconoce y debe resolverse por estimación son la matriz de correlaciones y los grados de libertad.
La estimación en cada caso se puede realizar con máxima verosimilitud (Kjersti, 2004; McNell et al., 2015) y en el caso de la cópula normal solo se estima la matriz de correlaciones, mientras que en el caso de la cópula t se debe estimar además los grados de libertad (Kjersti, 2004; McNell et al., 2015). La estimación de las correspondientes matrices de correlaciones para la cópula normal y t permite constatar la correlación negativa entre precio y rendimiento principalmente dentro del mismo estado como se aprecia para los estados de: Sinaloa, Estado de México y Chiapas (Cuadro 1 y 2). Para Jalisco la correlación precio y rendimiento resultó positiva, lo que haría al ingreso por hectárea riesgoso en ese estado; sin embargo, el rendimiento en Jalisco tuvo correlación negativa con el precio en Sinaloa, Estado de México y Chiapas bajo la cópula normal y solo con Sinaloa bajo la cópula t. Esto da la base para la distribución de riesgo de ingreso en un esquema de cobertura que contenga productores fuera del propio estado de Jalisco. Además, la correlación de precios entre estados es positiva lo que hace necesario buscar correlaciones negativas con rendimientos dentro o fuera del estado para cubrir el riesgo de precio.
Cuadro 1 Matriz de correlaciones estimada bajo la copula normal.
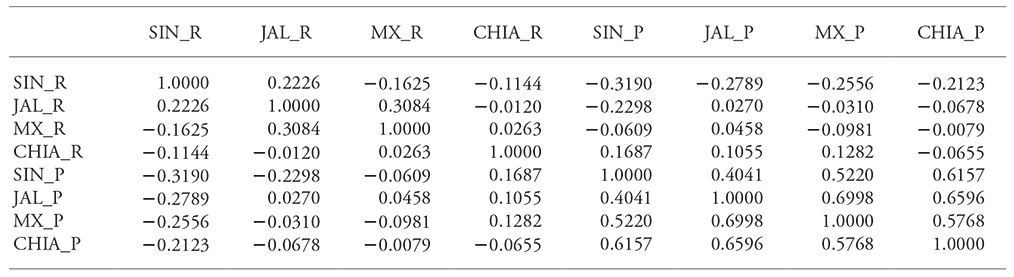
SIN_R: rendimiento Sinaloa; JAL_R: rendimiento Jalisco; MX_R: rendimiento Estado de México; CHIA_R: rendimiento Chiapas; SIN_P: precio Sinaloa; JAL_P: precio Jalisco; MX_P: precio Estado de México; CHIA_P: precio Chiapas.
Cuadro 2 Matriz de correlaciones estimada bajo la copula t.
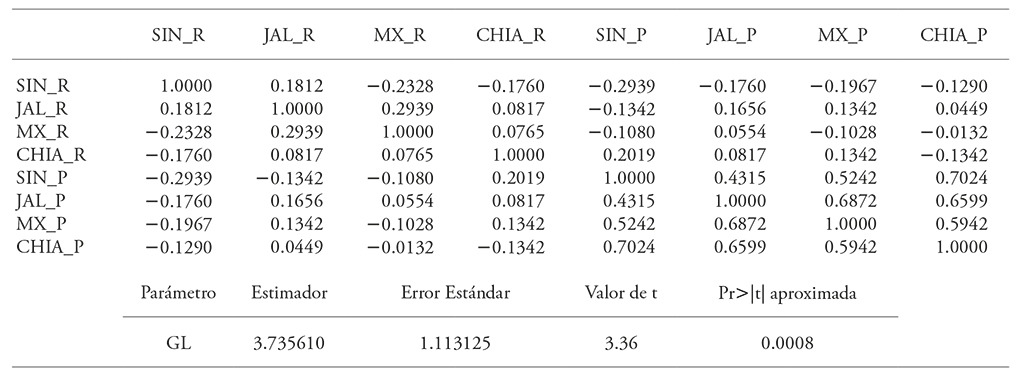
SIN_R: rendimiento Sinaloa; JAL_R: rendimiento Jalisco; MX_R: rendimiento Estado de México; CHIA_R: rendimiento Chiapas; SIN_P: precio Sinaloa; JAL_P: precio Jalisco; MX_P: precio Estado de México; CHIA_P: precio Chiapas.
Los estimadores de las matrices de correlaciones difieren debido a la forma funcional ajustada en cada caso. Al estar interesado en un evento particular, como:

A pesar de tener la función cópula y las marginales, obtener esta probabilidad por integración directa no es posible porque dicha integral no tiene forma analítica cerrada. Una solución es simular una muestra desde la función cópula y usar las marginales empíricas. Aquí se simularon valores obtenidos de la función cópula ajustada respectiva; en particular, una muestra aleatoria de tamaño 1000 se obtuvo de las ocho variables empleadas (cuatro precios y cuatro rendimientos). Esto produce las ocho variables sintéticas con la estructura de dependencia estimada; sin embargo, esas variables son de distribución uniforme. Para regresar los datos a su forma original se usó la transformación inversa:

donde y es la variable aleatoria precio o rendimiento generada, F-1( ) es la función inversa de las distribuciones marginales empleada y u es una variable aleatoria uniforme obtenida de la simulación de la función cópula.
La ventaja de esto es que cada variable aleatoria simulada contiene el efecto intra-estado y entre-estado simultáneamente; por tanto, estos datos se pueden emplear como provenientes de una distribución conjunta. En la presente aplicación estos datos se usan para modelar el ingreso por hectárea de los cuatro estados, obtenidos como precio por rendimiento.
El ingreso por hectárea se puede construir calculando los cuantiles de los precios y rendimientos. Esto permite distinguir umbrales de pérdida de ingreso por estado, que toma en cuenta la dependencia conjunta de precios e ingresos dentro y entre estados (Cuadro 3 para la función cópula normal; Cuadro 4 para la función cópula t).
Cuadro 3 Cuantiles de precio, rendimiento y siniestros de ingreso bajo copula normal.
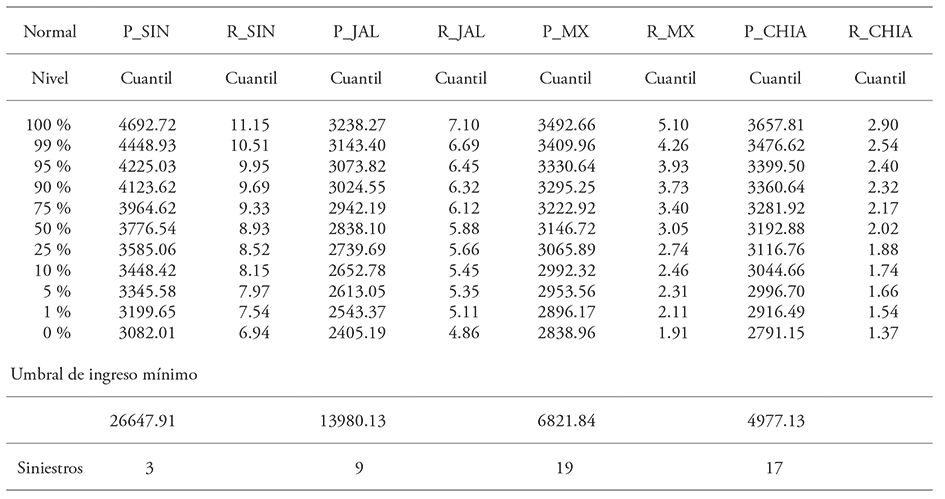
SIN_R: rendimiento Sinaloa; JAL_R: rendimiento Jalisco; MX_R: rendimiento Estado de México; CHIA_R: rendimiento Chiapas; SIN_P: precio Sinaloa; JAL_P: precio Jalisco; MX_P: precio Estado de México; CHIA_P: precio Chiapas.
Cuadro 4 Cuantiles de precio, rendimiento y siniestros de ingreso bajo copula t.
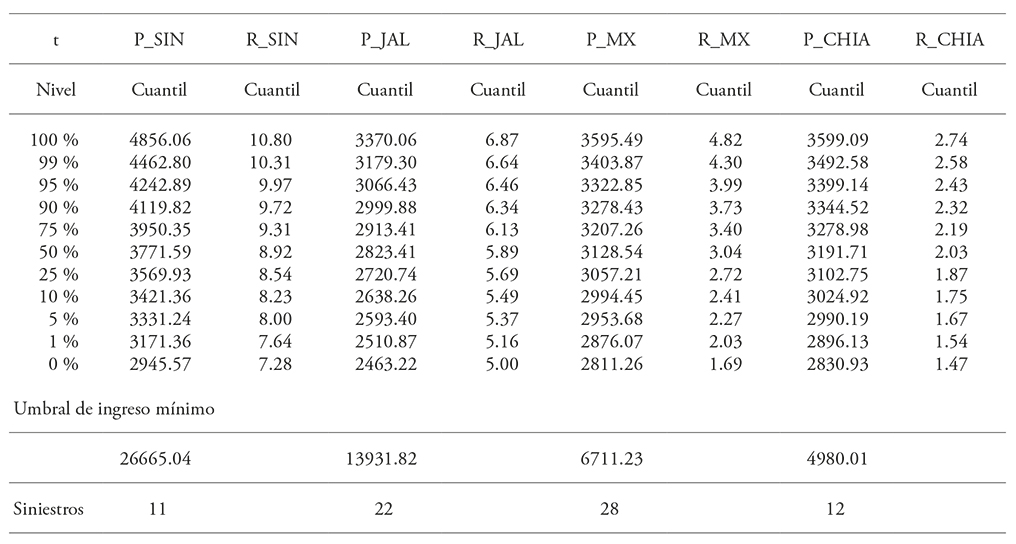
SIN_R: rendimiento Sinaloa; JAL_R: rendimiento Jalisco; MX_R: rendimiento Estado de México; CHIA_R: rendimiento Chiapas; SIN_P: precio Sinaloa; JAL_P: precio Jalisco; MX_P: precio Estado de México; CHIA_P: precio Chiapas.
Una compañía de seguros que ofrece indemnizar cuando el ingreso es inferior a un umbral podría utilizar los resultados de los cuantiles estimados. Por ejemplo, cuando el ingreso es inferior a 26 647 en Sinaloa indemnizar es un evento que ocurre con 5 % de probabilidad, en precio y rendimiento. Sin embargo, mientras que debido al percentil 5 % se esperarían 50 precios y 50 rendimientos inferiores al umbral respectivo; tomados en conjunto, el total de observaciones de ingreso por hectárea por debajo del umbral es menor. El total de observaciones por debajo de un umbral de ingreso por hectárea de 26 647 es de tres bajo la cópula normal (Cuadro 3) y de 11 bajo la cópula t (Cuadro 4). El número de siniestros con cada función cópula difiere por el propio ajuste a las funciones lo que implica que la función cópula empleada tiene relevancia (Goodwin y Hungerford, 2015). Aquí no se presentó un estudio comparativo; pero si no se toma en cuenta las dependencias entre los respectivos precios y rendimientos, el número de siniestros esperados es mayor. Esta forma de administrar riesgo, una póliza de ingreso, es más eficiente, si existiera. El oferente no requiere dos pólizas, la de precio y la de rendimiento, ya que se duplica el requerimiento administrativo. El tomador de decisiones adverso al riesgo de precio y de rendimiento, puede hacerlo erogando una sola prima de seguro en una operación. Además, el número de siniestros esperados es menor aprovechando las dependencias.
Conclusiones
Cuando se tiene más de una fuente de incertidumbre la administración de riesgo puede ser costosa. Es el caso de riesgo de precio y de rendimiento; su administración separada implicaría doble prima de riesgo y esto se compone si existen distintas localidades. Sin embargo, si se modela la dependencia es posible construir un instrumento de administración de riesgo de ingreso, que considera simultáneamente riesgo de precio y rendimiento. Este es potencialmente más económico tanto para ofrecerse como de comprarse, con número menor de siniestros, comparado con pólizas separadas de precio y rendimiento.

