











 texto en
texto en  Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
La infraestructura hidráulica de aprovechamiento o control, como embalses, diques de protección, encauzamientos y rectificaciones, puentes y drenaje pluvial, requieren en sus etapas de planeación, diseño, operación y revisión de la estimación lo más exacta posible de las crecientes de diseño. Con base en esas estimaciones hidrológicas todas las obras hidráulicas se dimensionan y su seguridad depende de ellas. Las crecientes de diseño son predicciones que se asocian a probabilidades de excedencia reducidas. El método más confiable para obtenerlas consiste en representar los datos disponibles de gastos máximos anuales o serie anual de máximos por una función de distribución de probabilidades (FDP) y, a partir de ella, realizar las predicciones buscadas (Deka y Borah, 2011; Ahmad et al., 2013). Este procedimiento se conoce como análisis de frecuencias de crecientes (AFC) y consta de las siguientes cinco etapas (Campos-Aranda, 2014): 1) recopilación de la información y verificación de su calidad estadística, 2) selección de una FDP, 3) elección de un método de estimación de sus parámetros de ajuste, 4) cuantificación objetiva del ajuste logrado con cada FDP y técnica de estimación, y 5) selección de resultados.
El AFC permite realizar predicciones cuyos intervalos promedio de recurrencia en años generalmente exceden varias veces la amplitud del registro disponible; por ello, son extrapolaciones que involucran errores. Para minimizar estos errores se sugieren dos enfoques diferentes. El primero fue utilizar FDP cada vez más flexibles y por ello se pasó de los modelos de dos parámetros de ajuste a los de tres, y se llegó al uso de la función Kappa de cuatro y la Wakeby o las funciones mixtas con cinco parámetros de ajuste. El segundo enfoque busca el uso mejorado de los datos disponibles, dando más importancia a sus valores grandes. Estadísticamente se trabaja con dos tipos nuevos de series de datos, conocidos como series de duración parcial y muestras censuradas o truncadas (Moisello, 2007).
La aplicación inicial de las series de duración parcial comenzó a mediados del siglo pasado y corresponde al uso de todos los datos superiores a un valor umbral; en cambio el uso de las series censuradas comenzó en la década de 1980. Desde la década de 1990 la técnica de ajuste de una FDP, mediante los momentos L, que son combinaciones lineales de los estadísticos de orden de los datos, se ha convertido en un procedimiento estándar debido a su sencillez y consistencia de resultados. Además se propusieron los momentos L depurados (1,1), los cuales dan peso nulo al valor menor y al mayor de la serie; por ello son más robustos, al ser menos sensibles a los valores dispersos o extremos (Shabri et al. 2011; Ahmad et al. 2013).
El objetivo de este estudio fue exponer la teoría de los momentos L, como base para la descripción detallada de los momentos L depurados (1,1). Las ecuaciones que estiman los tres parámetros de ajuste se citaron, con los métodos de momentos L y de momentos L depurados (1,1), en las tres FDP: la general de valores extremos (GVE), la logística generalizada (LOG) y la Pareto generalizada (PAG). En seguida se ajustaron, con ambos métodos, estas tres FDP a los 21 registros de crecientes anuales disponibles en la Región Hidrológica No. 10 (Sinaloa; México) y con base en el error estándar de ajuste se analizaron los resultados y se formularon las conclusiones.
Materiales y métodos
Momentos L poblacionales
Los momentos estadísticos se utilizan para caracterizar una serie de datos observados o una FDP. Los momentos L y los L depurados se han establecido como procedimientos alternativos de los momentos convencionales, ya que tienen menor varianza de muestreo y son más robustos cuando hay valores dispersos. Como los momentos convencionales, los de orden de uno a cuatro caracterizan a la localización, escala, asimetría y curtosis (Hosking, 1990; Elamir y Seheult, 2003).
De acuerdo con Karvanen (2006), el concepto de los momentos L se originó al final de la década de 1960, con variados resultados aislados sobre combinaciones lineales de los estadísticos de orden, los que culminaron con el trabajo de Greenwood et al. (1979). Hosking (1990) unificó la teoría de los momentos L y proporcionó guías para su uso práctico, que se han extendido a las áreas de la hidrología, meteorología y otras disciplinas de la ingeniería.
Los momentos L están relacionados con los valores esperados de los estadísticos de orden. Sea X una variable aleatoria y sea Xj:n su estadístico de orden, otra variable aleatoria distribuida como su j-ésimo elemento más pequeño de una muestra aleatoria de tamaño n, tomada de la FDP de X. Además, sea Q(u) la llamada función de cuantiles, es decir la solución inversa de la ecuación de la FDP, es entonces una función que aumenta en el intervalo de u Î [0,1]. Los primeros cuatro momentos L poblacionales son (Hosking, 1990; Hosking y Wallis, 1997; Karvanen, 2006):
su expresión general es:
donde el segundo paréntesis es un cociente de factoriales que define el número de combinaciones posibles de los m términos tomando q en cada arreglo; su expresión general es (Asquith, 2011):
Por convención 0!=1 y la función factorial Gamma es Г(m+1)=m! Los valores esperados de los estadísticos de orden de la Ecuación 5 se estiman con la expresión siguiente (Hosking y Wallis, 1997; Kottegoda y Rosso, 2008; Asquith, 2011):
La ecuación anterior establece la relación entre los momentos de probabilidad ponderada de Greenwood et al. (1979) y los momentos L. Los cocientes de momentos L de asimetría para r=3 y curtosis para r=4 son:
The above equation establishes the relation between the probability weighted moments by Greenwood et al. (1979) and the L moments. The quotients of L moments of asymmetry for r=3 and kurtosis for r=4 are:
Momentos L depurados (1,1) poblacionales
Estos momentos, designados como “TL” de “Trimmed” que significa depurado, cortado o truncado, asignan peso nulo a las observaciones extremas y por ello son generalizaciones robustas de los momentos L. Sus expresiones poblacionales son (Elamir y Seheult, 2003; Hosking, 2007):
su expresión general es:
Los cocientes de momentos L depurados (1,1) se calculan con la Ecuación 8.
Momentos L depurados (1,1) de la muestra
En una muestra o serie de datos de tamaño n ordenada en forma progresiva de manera que X1:n≤X2:n≤...≤Xn:n la estimación no sesgada de
donde lr(t) es una combinación lineal simétricamente ponderada de una muestra depurada o truncada de tamaño (n-2t) de valores ordenados X t+1:n , ..., X n-t:n . Los cocientes de momentos L depurados (1,1) de la muestra serán: t 3 (1,1) y t 4 (1,1), evaluados con la Ecuación 8.
Ajuste con momentos L de las distribuciones GVE, LOG y PAG
Hosking y Wallis (1997) destacan en su Tabla 5.1, que estas tres FDP, cuando su parámetro de forma es negativo (k<0), tienen sus colas derechas más gruesas o densas que todas las otras FDP comúnmente utilizadas en los AFC. Debido a ello han ganado aceptación en los análisis de frecuencias de datos hidrológicos extremos (El Adlouni et al. 2008). Esas FDP, cuando k=0, definen las funciones de dos parámetros de ajuste conocidas como Gumbel, logística y exponencial. Estas FDP también coinciden en tener un límite superior cuando k>0.
A continuación se citan para las distribuciones GVE, LOG y PAG su fórmula F(x), solución inversa x(F), con la cual se estiman las predicciones que se asocian a una cierta probabilidad de no excedencia (F) y las ecuaciones que permiten estimar sus tres parámetros de ajuste (k, a, u) correspondientes a la forma, escala y ubicación, con el método de momentos L.
Distribución GVE (Stedinger et al., 1993): intervalo de x: u+a/k≤x<¥ si k<0; -¥<x<¥ si k=0; -¥<x≤u+a/k si k>0.
donde y es la variable reducida:
donde:
Para la evaluación de la función Gamma se utilizó la fórmula de Stirling (Davis, 1965):
Distribución LOG (Rao y Hamed, 2000): intervalo de x, idéntico al de la GVE.
donde y igual a las Ecuaciones 16 y 17.
Distribución PAG (Hosking y Wallis, 1997): intervalo de x:u≤x<∞ si k≤0;u≤x≤u+a/k si k>0
donde y igual a las Ecuaciones 16 y 17.
Con los momentos y cocientes L expuestos por Campos Aranda (2014) se estimaron los tres parámetros de ajuste de las distribuciones GVE, LOG y PAG con las Ecuaciones 20 a 24, 28 a 30 y 34 a 36, respectivamente.
Ajuste con momentos L depurados (1,1) de las distribuciones GVE, LOG y PAG
Para la distribución GVE, Deka y Borah (2011) desarrollaron una ecuación de T 3 (1,1) en función del parámetro de forma (k), cuya expresión empírica inversa es:
La cual es válida cuando 0.70≤k≤0.50 y tiene un coeficiente de determinación cercano a uno y error estándar de la estimación de 0.00261. Las Ecuaciones 38 a 45 proceden de Deka y Borah (2011), Shabri et al. (2011) y Ahmad et al. (2013).
Para la distribución LOG se tienen:
y para la distribución PAG:
Diagrama de cocientes de momentos L depurados (1,1)
Hosking y Wallis (1997) expusieron la relación gráfica y numérica (Ecuación 46) que tiene el cociente de momentos L de asimetría (T3) con el de curtosis (T4) en cinco FDP, lo cual constituye el diagrama de cocientes de momentos L. Esta gráfica se puede utilizar para seleccionar la mejor FDP, de acuerdo con los valores de los cocientes de momentos L de asimetría y curtosis (t 3 y t 4) de la muestra local o a su estimación regional ponderada. Para obtener el diagrama de cocientes de momentos L depurados (1,1), se debe encontrar la relación entre T3 (1,1) y T4 (1,1) para cada FDP. Shabri et al. (2011) y Deka y Borah (2011) obtuvieron esas relaciones teóricas y las representaron con polinomios de cuarto grado para las distribuciones GVE y PAG, y de segundo para la LOG; los coeficientes de la Ecuación 46 de cada polinomio están en el Cuadro 1.
Cuadro 1 Coeficientes de los polinomios de aproximación de t4 (1,1) en función de t3 (1,1) en las distribuciones GVE, LOG y PAG según Shabri et al. (2011).
| Coeficiente | GVE | LOG | PAG |
|---|---|---|---|
| a0 | 0.0576 | 0.0833 | - |
| a1 | 0.0943 | - | 0.1610 |
| a2 | 0.9183 | 0.9450 | 0.9904 |
| a3 | -0.0745 | - | -0.1295 |
| a4 | 0.0373 | - | 0.0184 |
Con base en la Ecuación 46 y sus coeficientes (Cuadro 1) se construyó el diagrama de cocientes de momentos L depurados (1,1), para las distribuciones GVE, LOG y PAG (Figura 1).
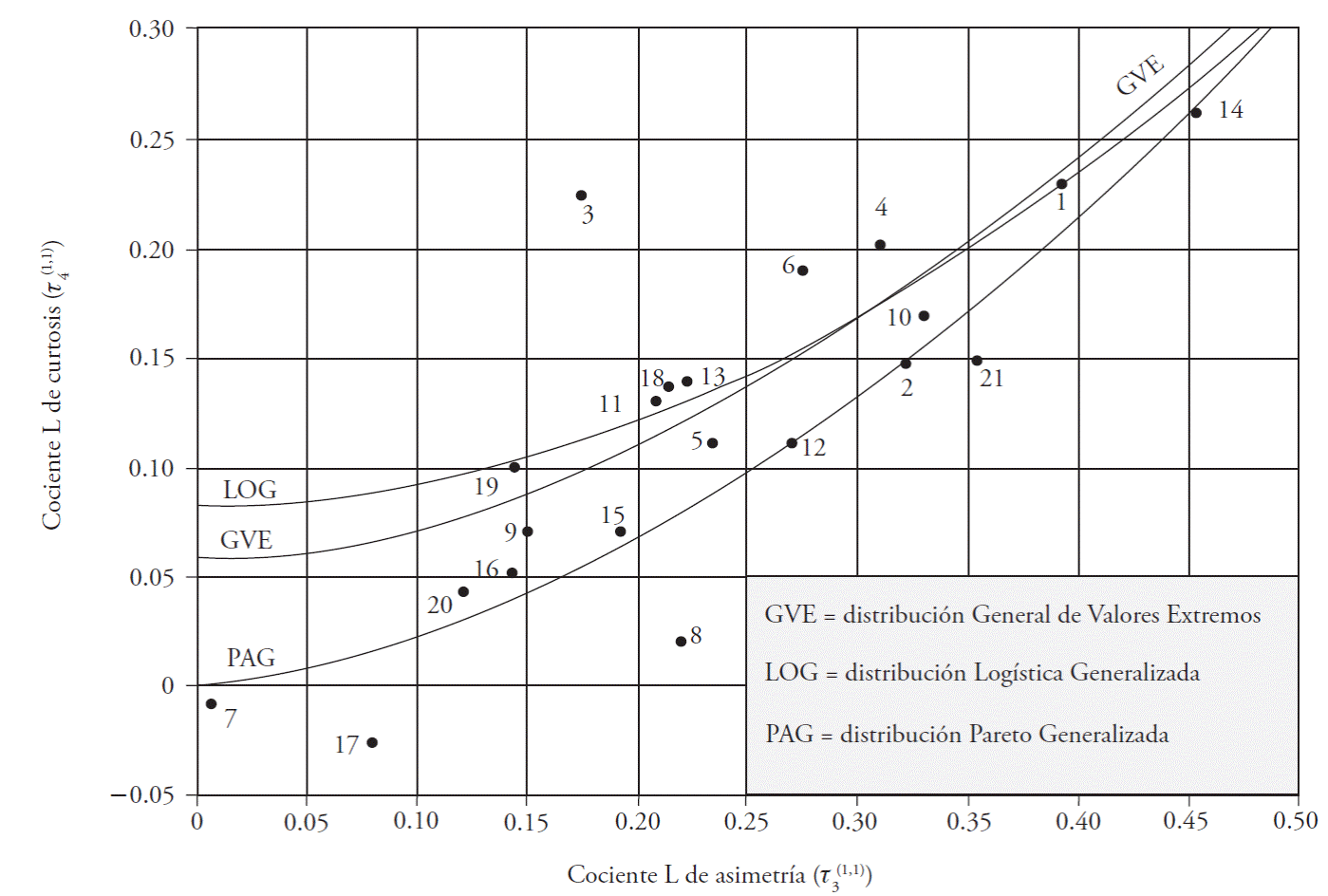
Figura 1 Diagrama de cocientes de momentos L depurados (1,1) de las distribuciones GVE, LOG y PAG según Shabri et al. (2013), y localización de 21 registros de crecientes de la Región Hidrológica No. 10, Sinaloa, México.
Error estándar de ajuste
A mediados de la década de 1970 se estableció al error estándar de ajuste (EEA) como un indicador estadístico cuantitativo, ya que evalúa la desviación estándar de las diferencias entre los valores observados y los estimados con la FDP que se prueba. Su expresión es la siguiente (Kite, 1977):
donde n y np son el número de datos de la muestra y de parámetros de ajuste, en este caso tres; xi son los datos ordenados de menor a mayor y
En la cual m es el número de orden del dato, con 1 para el menor y n para el mayor.
Indicadores cualitativos del ajuste
Los diagramas de diagnóstico de probabilidades y el de cantidades se han popularizado (Coles, 2001; Wilks, 2011); el primero emplea en el eje de las abscisas la probabilidad empírica estimada con la Ecuación 48 y en las ordenadas la probabilidad que define la FDP ajustada para cada dato disponible, ordenados en forma progresiva de magnitud (x 1≤x 2≤...≤x n ), la que se estima con las Ecuaciones 15, 25 y 31 para las distribuciones GVE, LOG y PAG. En el gráfico de cantidades se indica en las abscisas el valor del dato observado x 1≤x 2≤...≤x n y en las ordenadas el valor estimado con la solución inversa de la FDP, con las Ecuaciones 18, 26 y 32 para las funciones GVE, LOG y PAG, y la probabilidad empírica estimada con la Ecuación 48. En resumen las coordenadas x y y de cada diagrama son (Coles, 2001):
Registros procesados de crecientes anuales
Entre los registros de gastos máximos anuales (m3·s-1) de las estaciones hidrométricas de la Región Hidrológica No. 10 (Sinaloa; México) existen 21 que no tienen régimen de escurrimiento afectado por embalses, cambios físicos drásticos o ambos en sus cuencas y muestran más de veinte años de datos en el sistema BANDAS (IMTA, 2002). Los registros de las estaciones de aforos Huites y Guamuchil llegan hasta el año en que la construcción del embalse respectivo afectó su escurrimiento. Los datos de la estación San Francisco proceden del Boletín Hidrológico No. 36 (SRH, 1975). Campos-Aranda (2014) verificó la calidad estadística de los registros citados y presenta sus momentos y cocientes L; además expone un mapa con la localización de las 21 estaciones hidrométricas y sus cuencas respectivas.
El registro más corto tiene 19 años y los más largos 56, con valor mediano de 33 años (Cuadro 2). Los momentos L depurados (1,1) estimados a través de la Ecuación 14 y los cocientes de momentos calculados con la Ecuación 8 se presentan en el Cuadro 2.
Cuadro 2 Características generales, momentos y cocientes L depurados (1,1), en 21 registros procesados de crecientes anuales de la Región Hidrológica No. 10, Sinaloa, México.
| No. | Estación hidrométrica | Área de cuenca (km 2 ) | Años de Registro (n) | L 1 (1,1) | L 2 (1,1) | L 3 (1,1) | L 4 (1,1) | T 3 (1,1) | T 4 (1,1) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Huites | 26 057 | 1942-1992 (51) | 2578.9710 | 643.4111 | 252.0877 | 148.1874 | 0.39180 | 0.23032 |
| 2 | San Francisco | 17 531 | 1941-1973 (33) | 1417.6250 | 334.2696 | 107.8858 | 49.8560 | 0.32275 | 0.14915 |
| 3 | Santa Cruz | 8919 | 1944-2002 (52) | 825.6472 | 191.9839 | 33.6176 | 43.3249 | 0.17511 | 0.22567 |
| 4 | Jaina | 8179 | 1942-1998 (56) | 789.5898 | 188.1527 | 58.7587 | 38.1695 | 0.31229 | 0.20286 |
| 5 | Palo Dulce | 6439 | 1958-1986 (21) | 818.7865 | 145.9885 | 34.1639 | 16.8504 | 0.23402 | 0.11542 |
| 6 | Ixpalino | 6166 | 1953-1999 (45) | 986.9792 | 186.6518 | 51.6721 | 35.2875 | 0.27684 | 0.18906 |
| 7 | La Huerta | 6149 | 1970-1999 (28) | 927.6062 | 197.2018 | 1.4513 | -1.7109 | 0.00736 | -0.00868 |
| 8 | Chinipas | 5098 | 1965-2002 (24) | 790.5296 | 159.9196 | 35.3124 | 3.2871 | 0.22081 | 0.02055 |
| 9 | Tamazula | 2241 | 1963-1999 (32) | 531.4827 | 76.7720 | 11.5965 | 5.4135 | 0.15105 | 0.07051 |
| 10 | Naranjo | 2064 | 1939-1984 (45) | 497.4072 | 157.6427 | 51.9003 | 26.6872 | 0.32923 | 0.16929 |
| 11 | Acatitán | 1884 | 1955-2002 (43) | 664.8182 | 195.9668 | 40.7487 | 25.5050 | 0.20794 | 0.13015 |
| 12 | Guamuchil | 1645 | 1940-1971 (32) | 577.3327 | 128.4394 | 34.5535 | 14.3540 | 0.26903 | 0.11176 |
| 13 | Choix | 1403 | 1956-2002 (38) | 290.3594 | 55.7844 | 12.2758 | 7.7038 | 0.22006 | 0.13810 |
| 14 | Badiraguat | 1018 | 1974-1999 (26) | 746.8054 | 239.1029 | 108.2557 | 62.7376 | 0.45276 | 0.26239 |
| 15 | El Quelite | 835 | 1961-2001 (33) | 408.9254 | 109.0321 | 20.8927 | 7.7677 | 0.19162 | 0.07124 |
| 16 | Zopilote | 666 | 1939-2001 (56) | 319.5128 | 89.7444 | 12.7530 | 4.5793 | 0.14210 | 0.05103 |
| 17 | Chico Ruiz | 391 | 1977-2002 (19) | 196.6518 | 52.4802 | 4.1569 | -1.4225 | 0.07921 | -0.02711 |
| 18 | El Bledal | 371 | 1938-1994 (56) | 241.8649 | 54.0593 | 11.5716 | 7.4244 | 0.21405 | 0.13734 |
| 19 | Pericos | 270 | 1961-1992 (30) | 229.4434 | 44.2758 | 6.3602 | 4.4083 | 0.14365 | 0.09956 |
| 20 | La Tina | 254 | 1960-1983 (24) | 75.5672 | 21.1883 | 2.5428 | 0.9513 | 0.12001 | 0.04490 |
| 21 | Bamícori | 223 | 1951-1983 (33) | 153.8719 | 45.9496 | 16.1642 | 6.8401 | 0.35178 | 0.14886 |
†Momentos L depurados (1,1) de la muestra
¶Cocientes de momentos L depurados (1,1) de la muestra
Resultados y discusión
Selección de la FDP más conveniente
Cada registro de crecientes se llevó al diagrama de cocientes de momentos L depurados (1,1) para obtener la FDP más conveniente de acuerdo a sus valores de cocientes L de asimetría y curtosis (Cuadro 2). Once registros se aproximaron a la función PAG, siete a la LOG y tres pudieran ser representados por la distribución GVE (Figura 1) (Cuadro 3).
Cuadro 3 Errores estándar de ajuste (m3·s-1) obtenidos con los métodos de momentos L y momentos L depurados (1,1), en 21 registros de crecientes anuales de la Región Hidrológica No. 10, Sinaloa, México.
| No. | Estación Hidrométrica | FDP según DCM ¶ | Error Estándar de Ajuste (EEA) † | |||||
|---|---|---|---|---|---|---|---|---|
| GVE | LOG | PAG | ||||||
| moL § | moLD § | moL | moLD | moL | moLD | |||
| 1 | Huites | LOG | 979 | 1101 | 1061 | 1099 | (834) | 875 |
| 2 | San Francisco | PAG | 377 | 232 | 419 | 249 | 302 | (200) |
| 3 | Santa Cruz | LOG | (406) | 599 | 421 | 564 | 409 | 691 |
| 4 | Jaina | GVE | 360 | 285 | 382 | (270) | 346 | 382 |
| 5 | Palo Dulce | GVE | 895 | 1063 | 922 | 1056 | (866) | 1095 |
| 6 | Ixpalino | LOG | 346 | 349 | 367 | (332) | 334 | 432 |
| 7 | La Huerta | PAG | 96 | 111 | 124 | 148 | (53) | 63 |
| 8 | Chinipas | PAG | 139 | 98 | 154 | [98] | 126 | 117 |
| 9 | Tamazula | GVE | (145) | 189 | 150 | 179 | 147 | 216 |
| 10 | Naranjo | PAG | 156 | 185 | 173 | 193 | (127) | 132 |
| 11 | Acatitán | LOG | 227 | 219 | 239 | (196) | 231 | 293 |
| 12 | Guamuchil | PAG | 235 | 210 | 247 | (202) | 225 | 245 |
| 13 | Choix | LOG | 105 | 126 | 110 | 120 | (101) | 149 |
| 14 | Badiraguato | PAG | 1077 | (791) | 1130 | 860 | 1037 | 872 |
| 15 | El Quelite | PAG | 87 | 71 | 98 | (69) | 74 | 93 |
| 16 | Zopilote | PAG | 48 | 62 | 61 | 81 | 25 | [25] |
| 17 | Chico Ruiz | PAG | 28 | 30 | 34 | 36 | (16) | 17 |
| 18 | El Bledal | LOG | 64 | 72 | 67 | (63) | 68 | 100 |
| 19 | Pericos | LOG | 29 | 26 | 33 | 26 | (24) | 33 |
| 20 | La Tina | PAG | 90 | 116 | 92 | 114 | (87) | 122 |
| 21 | Bamícori | PAG | 52 | 77 | 57 | 77 | (43) | 64 |
| Número de mínimos | 2 | 1 | 0 | 7 | 9 | 2 | ||
†En paréntesis circular o rectangular su valor mínimo de cada estación.
¶Diagrama de cocientes de momentos.
§moL: ajuste por momentos L y moLD: ajuste por momentos L depurados (1,1).
Error estándar de ajuste
Por medio de sus soluciones inversas de FDP (Ecuaciones 18, 26 y 32) se obtuvieron las estimaciones
Con los momentos y cocientes L depurados (1,1) (Cuadro 2) y las Ecuaciones 37 a 45 se obtuvieron los tres parámetros de ajuste de las funciones GVE, LOG y PAG. En seguida, por medio de sus soluciones inversas (Ecuaciones 18, 26 y 32) se estimaron los valores de
El EEA menor de los seis calculados se identificó (Cuadro 3, en paréntesis circular) y valores iguales ocurrieron en los registros de Chinipas y Zopilote, seleccionando el ajuste que aportó las predicciones más grandes (Cuadro 3, en paréntesis rectangular). Los EEA mínimos definidos por las distribuciones GVE, LOG y PAG coincidieron con las FDP en once registros (Figura 1): San Francisco, Ixpalino, La Huerta, Tamazula, Naranjo, Acatitán, Zopilote, Chico Ruiz, El Bledal, La Tina y Bamícori.
El ajuste de las distribuciones GVE, LOG y PAG con base en los momentos L depurados (1,1) (Cuadro 3, último renglón) es una opción que puede abatir el EEA del método de momentos L de una manera sistemática, pues esto ocurrió en diez registros. Destaca el ajuste con tal método de la función LOG, el cual mostró los EEA menores en siete registros. También sobresalió la distribución PAG que condujo a los ajustes mayores en 11 de los 21 registros procesados, nueve de ellos con el método de momentos L.
El resultado último no debe guiar hacia la aplicación exclusiva de tal FDP, ya que en los registros de Santa Cruz, Palo Dulce, Tamazula, Choix, Badiraguato y La Tina, con las otras funciones se obtuvieron EEA mínimos, casi iguales, y en varios registros como: Ixpalino, Chinipas, Guamuchil, El Quelite y Pericos, se lograron EEA semejantes. Debido a lo anterior, se recomienda seguir aplicando bajo precepto a las distribuciones GVE y LOG.
Predicciones obtenidas con el mejor ajuste
Las predicciones con cada uno de los mejores ajustes en los registros procesados (Cuadro 4, tercera columna) se obtuvieron según los resultados moLD (Cuadro 3). Para el registro de la estación hidrométrica Jaina, el método de momentos L produjo EEA del orden de 360 m3 s-1 con las distribuciones GVE, LOG y PAG; en cambio, con el procedimiento de los momentos L depurados (1,1) se logró la reducción a 270 m3 s-1 con la función LOG. Para este ajuste en los diagramas de diagnóstico respectivos se verificó el ajuste alcanzado (Figura 2 y 3).
Cuadro 4 Predicciones (m3.s-1) obtenidas con los ajustes mejores en 21 registros de crecientes anuales de la Región Hidrológica No. 10, Sinaloa, México.
| No. | Estación hidrométrica | FDP y MA † | Periodos de retorno en años | |||||
|---|---|---|---|---|---|---|---|---|
| 10 | 25 | 50 | 100 | 500 | 1000 | |||
| 1 | Huites | PAG-moL | 6710 | 10 581 | 14 355 | 19 056 | 34 919 | 44 673 |
| 2 | San Francisco | PAG-moLD | 3619 | 5771 | 7926 | 10 673 | 20 327 | 26 486 |
| 3 | Santa Cruz | GVE-moL | 2104 | 3258 | 4410 | 5883 | 11 118 | 14 497 |
| 4 | Jaina | LOG-moLD | 1990 | 3365 | 4967 | 7317 | 17 985 | 26 512 |
| 5 | Palo Dulce | PAG-moL | 1984 | 3386 | 4988 | 7282 | 17 183 | 24 745 |
| 6 | Ixpalino | LOG-moLD | 2141 | 3340 | 4665 | 6523 | 14 340 | 20 125 |
| 7 | La Huerta | PAG-moL | 1764 | 1935 | 2002 | 2041 | 2079 | 2085 |
| 8 | Chinipas | LOG-moLD | 1725 | 2553 | 3396 | 4495 | 8563 | 11 288 |
| 9 | Tamazula | GVE-moL | 1009 | 1390 | 1745 | 2173 | 3543 | 4349 |
| 10 | Naranjo | PAG-moL | 1449 | 2183 | 2815 | 3522 | 5506 | 6534 |
| 11 | Acatitán | LOG-moLD | 1793 | 2758 | 3720 | 4955 | 9396 | 12 297 |
| 12 | Guamuchil | LOG-moLD | 1365 | 2167 | 3042 | 4258 | 9262 | 12 944 |
| 13 | Choix | PAG-moL | 683 | 998 | 1275 | 1592 | 2514 | 3009 |
| 14 | Badiraguato | GVE-moLD | 2691 | 5510 | 9584 | 16776 | 62319 | 109 957 |
| 15 | El Quelite | LOG-moLD | 1025 | 1528 | 2017 | 2632 | 4765 | 6114 |
| 16 | Zopilote | PAG-moLD | 787 | 976 | 1087 | 1175 | 1319 | 1361 |
| 17 | Chico Ruiz | PAG-moL | 429 | 490 | 518 | 537 | 558 | 562 |
| 18 | El Bledal | LOG-moLD | 555 | 828 | 1102 | 1458 | 2752 | 3608 |
| 19 | Pericos | PAG-moL | 480 | 599 | 676 | 742 | 865 | 906 |
| 20 | La Tina | PAG-moL | 239 | 392 | 539 | 722 | 1335 | 1709 |
| 21 | Bamícori | PAG-moL | 418 | 610 | 769 | 942 | 1403 | 1630 |
†Método de ajuste: moL, por momentos L y moLD, por momentos L depurados (1,1).
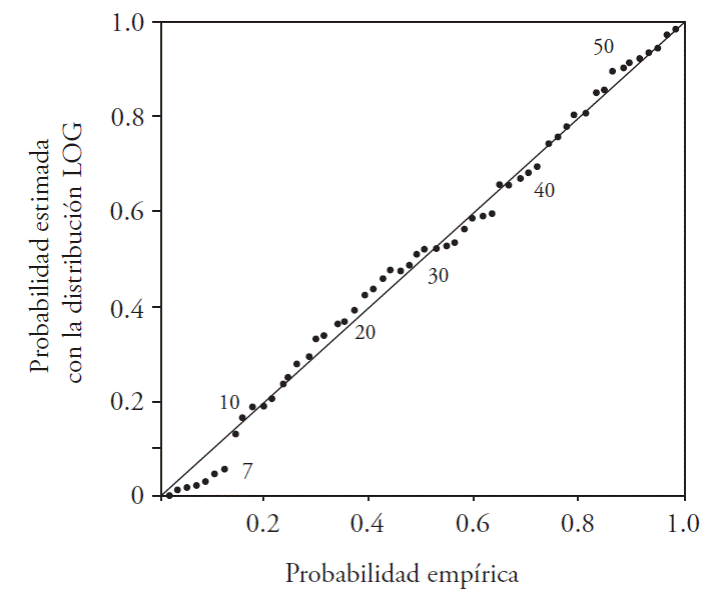
Figura 2 Diagrama de probabilidad para el registro de crecientes anuales de la estación hidrométrica Jaina, con ajuste de la distribución LOG (EEA=270 m3. s-1).

Conclusiones
La motivación para representar a los datos de gastos máximos anuales con una FDP consiste en permitir realizar predicciones confiables o estimaciones de las crecientes de diseño, lo cual depende de la exactitud del ajuste logrado. Por lo anterior, el EEA es el elemento básico de selección.
Los resultados del contraste de las distribuciones GVE, LOG y PAG, en 21 registros de crecientes anuales de la Región Hidrológica No. 10 (Sinaloa, México), con los métodos de ajuste de momentos L y de momentos L depurados (1,1), destacan la conveniencia de aplicar sistemáticamente a la distribución PAG, ya que condujo a los EEA menores en once de las series procesadas. Con la función LOG se logran los EEA menores en siete registros y con la distribución GVE en tres.
El uso del método de momentos L depurados (1,1), para lograr mejores ajustes de las tres distribuciones aplicadas, permite sugerir su aplicación sistemática en los análisis de frecuencia de crecientes, ya que reduce el EEA en la mitad de los registros procesados. El ajuste de la distribución LOG con este procedimiento destacó, ya que también alcanza EEA menores, en siete registros.

