










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkAgrociencia
versión On-line ISSN 2521-9766versión impresa ISSN 1405-3195
Agrociencia vol.44 no.3 Texcoco abr./may. 2010
Fitociencia
Muestreo combinado para la regeneración de recursos fitogenéticos de especies monoicas con polinización natural
Combined sampling for regeneration of plant genetic resources of monoecious species with natural pollination
Jaime Sahagún–Castellanos* , J. Enrique Rodríguez–Pérez, Aureliano Peña–Lomelí
Proyecto: Genética Estadística del Instituto de Horticultura, Departamento de Fitotecnia, Universidad Autónoma Chapingo. 56230. Km 38.5, Carretera México–Texcoco. Estado de México. *Autor responsable: (jsahagun@correo.chapingo.mx).
Recibido: Agosto, 2008.
Aprobado: Febrero, 2010.
RESUMEN
En la regeneración de recursos fitogenéticos de especies monoicas y de las que se reproducen por apareamiento aleatorio debe utilizarse procedimientos de muestreo que minimicen el costo y la endogamia, que a su vez se relaciona con la disminución del tamaño efectivo de población, el aumento de la probabilidad de extinción de genes, etc. Dos formas para tomar una muestra aleatoria de individuos de un ciclo para generar el siguiente que no requieren polinización artificial son: 1) completamente al azar (MACA), como en la población ideal (PI); 2) como en la PI pero en dos etapas (MADE), primero se selecciona al azar n familias de medios hermanos y después de cada una de ellas se selecciona aleatoriamente m individuos. En este último caso el apareamiento aleatorio subsecuente permitirá cruzas entre medios hermanos. El objetivo de este estudio fue determinar el tamaño efectivo de población en términos de endogamia (Ne(f)) de MADE y su relación con el de MACA (Ne(f)CA). Como para MADE, se consideró que la muestra completamente al azar fuera de tamaño mn. Con base en la varianza del número de gametos de un individuo que llegan a formar progenie, para MADE se encontró que Ne(f)= [4mn–2]/[m–(mn)–1+2] , que implica que para una muestra de tamaño constante mn MADE aumenta su Ne(f) a medida que m es más pequeño (y que, consecuentemente, n es más grande) y para cualquier valor de n alcanza su máximo cuando m = 1; y sólo en este caso es mayor que el tamaño efectivo de MACA que siempre es igual a nm. Cuando mn es grande, el cociente Ne(f) / Ne(f)CA. se reduce, aproximadamente, a 4/(m+2); esto implica que cuando m=1, el tamaño efectivo de MADE supera al de MACA (aproximadamente, 33.33 %); y con m=2 ocurre que Ne(f)=Ne(f)CA. Se encontró que en MADE la composición de la muestra es muy importante en la recolección o regeneración de recursos fitogenéticos. Por ejemplo, con un tamaño de muestra mn = 1000, el C puede tomar valores desde 4 (con m=1000 y n=1) hasta 1333.33 (con n= 1000 y m=1).
Palabras clave: apareamiento aleatorio, familias de medios hermanos, población ideal, tamaño efectivo de población.
ABSTRACT
In the regeneration of plant genetic resources of monoecious species and those that are reproduced by random mating sampling procedures should be used to minimize cost and inbreeding, which in turn is related to the decrease of the effective population size, the increase of probability of extinction of genes, and so on. Two ways to take a random sample of individuals from one cycle to generate the next that does not require artificial pollination are: 1) completely random (MACA), as in the ideal population (IP), 2) as in the IP but in two stages (MADE), first n families of half–sibs are randomly selected and then from each one of them m individuals are randomly selected. In the latter case, the subsequent random mating will allow crosses between half–sibs. The objective of this study was to determine the effective population size in terms of inbreeding (Ne(f)) of MADE and its relation to that of MACA (Ne(f)CA). As for MADE, it was considered that the size of the completely random sample was mn. Based on the variance of the number of gametes of an individual forming progeny, for MADE it was found that Ne(f)= [4mn–2]/[m–(mn)–1+2], which implies that for a sample of constant size mn MADE increases its Ne(f) as m is smaller (and, consequently, n is larger) and for any value of n reaches its maximum when m=1; and only in this case is larger than the effective size of MACA that is always equal to nm. When mn is large, the Ne(f) / Ne(f)CA. ratio is reduced to approximately 4/(m+2); this means that when m=1, the effective size of MADE exceeds that of MACA (approximately 33.33 %); and with m = 2 Ne(f)=Ne(f)CA. It was found that in MADE the composition of the sample is very important in the collection or regeneration of plant genetic resources. For example, with a sample size mn = 1000, Ne(f) can take values from 4 (with m = 1000 and n = 1) up to 1333.33 (with n= 1000 and m = 1).
Key words: random mating, half–sib families, ideal population, effective population size.
INTRODUCCIÓN
En el manejo, la recolección y regeneración de los recursos fitogenéticos es muy importante el diseño de la muestra tomada de un ciclo para generar el siguiente. En este diseño se debe evitar un alto costo y la pérdida de variabilidad genética, que a su vez se relaciona con el aumento de la endogamia que tiene que ver con la depresión endogámica, el aumento de la probabilidad de ocurrencia de deriva genética y la probabilidad de la extinción de genes (Crow y Kimura, 1970; Falconer y Mackay, 2007). Las generalidades de estos temas ya han sido tema de estudio de la Genética de Poblaciones.
El estudio teórico formal del comportamiento de las poblaciones en el tiempo se inició con la ley de Hardy–Weinberg desde principios del siglo 20. Una versión sencilla de esta ley establece que: en una población grande con apareamiento aleatorio en ausencia de selección, mutación y selección, las frecuencias génicas y genotípicas, permanecen constantes de generación en generación (Molina, 1992; Falconer y Mackay, 2007). Por ejemplo, de una población monoica, diploide de tamaño TV donde el genotipo del i–ésimo individuo es Ai1 Ai2 (i=1,2,...,N) que se reproduce por apareamiento aleatorio está en equilibrio Hardy–Wenberg si el arreglo genotípico esperado de la progenie es:
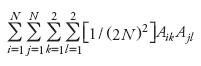
Sin embargo, en la naturaleza pueden actuar factores que hacen que tal arreglo en ocasiones sea diferente. Por ejemplo, si los individuos fueran autoestériles, como en el tomate de cascara (Physalis ixocarpa Brot.), el arreglo genotípico esperado sería:

Para estudiar la dinámica generacional de las poblaciones que no satisfacen plenamente el requisito del apareamiento aleatorio, u otros requisitos, se debe hacer las adecuaciones correspondientes a la ley de Hardy–Weinberg (Crow y Kimura, 1970; Hendrick, 2005; Falconer y Mackay, 2007).
En este escenario es importante el concepto de población ideal (Wright, 1931, 1938; Crow y Kimura, 1970; Falconer y Mackay, 2007), definida a partir de un conjunto de un número infinito de individuos diploides no endogámicos ni emparentados, monoicos, que se reproducen por apareamiento aleatorio en ausencia de migración, mutación y selección. De ella se extrae una muestra completamente al azar, y del apareamiento aleatorio de sus integrantes se genera la población del ciclo uno; éste se muestrea de la misma manera para que el apareamiento aleatorio de la muestra produzca la población del ciclo dos, y así sucesivamente. En especies como el tomate de cascara y el maíz (Zea mays L.), además del muestreo completamente al azar, puede ser atractivo seleccionar la muestra en dos etapas. En la primera se selecciona al azar un conjunto de familias de medios hermanos y de cada una de ellas se toman al azar varios individuos (por ejemplo, en maíz se seleccionan varias mazorcas al azar y de cada una se toman aleatoriamente varias semillas). Este es un proceso similar al de selección recurrente combinada direccional (se hace selección primero entre y después dentro de familias) (Hallauer y Miranda, 1981), pero diferente del método que describen Crossa y Vencovsky (1999) al referirse a la variación que ocurre primero en el muestreo de individuos y después en el de sus gametos.
El procedimiento de muestreo en dos etapas debe tener efectos diferentes a los del muestreo completamente al azar de individuos. Por ejemplo, puede haber diferencias en los coeficientes de endogamia que se genere con ambas formas de muestreo puesto que, aunque en los dos casos el apareamiento aleatorio de la muestra permite las autofecundaciones con igual frecuencia, los apareamientos entre medios hermanos pueden ocurrir con frecuencias muy diferentes. Otra forma de medir el efecto de la diferencia entre los efectos de las dos formas de obtener las muestras se basa en la determinación del número o tamaño efectivo de población expresado en términos de endogamia. Por ejemplo, el tamaño efectivo en términos de endogamia de una población X, también conocido como tamaño efectivo de esa población, es el tamaño de muestra que necesita la población ideal para tener una tasa de endogamia igual a la de la población X en cuestión (Falconer y Mackay, 2007). El tamaño efectivo de una población sirve para, independientemente de su estructura de apareamiento, ser analizada en términos de una población estándar denominada población ideal. La utilidad del tamaño efectivo de población en el contexto de los recursos genéticos se debe a que su magnitud tiene una relación inversa con la probabilidad de extinción de los genes y con la tasa de endogamia (Crow y Kimura, 1970). De hecho, hay dos versiones del tamaño efectivo de población; la relacionada con la endogamia y la relacionada con la varianza de la frecuencia alélica (Kimura y Crow, 1963).
En el contexto del mejoramiento genético por selección y en el de los recursos fitogenéticos, por lo general es deseable que el coeficiente de endogamia sea bajo o que el tamaño efectivo sea alto. Además, se requiere que el costo del muestreo y del manejo de la muestra sea acorde con los recursos disponibles, usualmente escasos.
En la recolección y regeneración de recursos fitogenéticos en particular, además de la tecnología para mantener el material genético que se desea salvaguardar, el éxito depende del diseño de la muestra y del sistema de apareamiento de los individuos que la componen para regenerar el ciclo siguiente. De la muestra, además de ser aleatoria, de tamaño finito y comúnmente sujeta a restricciones económicas, se debe determinar la forma de constituirla y una estrategia de apareamiento que permita, por ejemplo, minimizar la endogamia. Además, el apareamiento de los individuos de la muestra puede ser al azar, en forma natural, o puede hacerse manualmente, de acuerdo con un diseño predeterminado. Dado que la muestra es aleatoria y de tamaño finito, las frecuencias alélicas se convierten en variables aleatorias que fluctúan a través de las generaciones en forma cada vez más intensa pero con dirección impredecible, con la posibilidad de que se fijen algunos alelos (Hendrick, 2005; Falconer y Mackay, 2007). Sin embargo, fijar un alelo de un locus implica la pérdida de los alelos restantes de ese locus (Crow y Kimura, 1970; Falconer y Mackay, 2007), algo muy lamentable en la recolección y conservación de recursos fitogenéticos.
El efecto del carácter finito y aleatorio de la muestra también se puede visualizar en términos de un aumento en la frecuencia de genotipos homocigóticos que pueden traer un efecto de depresión endogámica, particularmente severo en poblaciones que no han sufrido un proceso intenso de selección artificial en una dirección, como puede ser el rendimiento de grano de maíz (Hallauer y Miranda, 1981). Sin embargo, además de la variación aleatoria, otros factores pueden influir en las frecuencias génicas y genotípicas; en maíz, por ejemplo, la diferencia entre las frecuencias esperadas y las observadas también puede depender de: 1) el ángulo de inserción y el tamaño de las hojas, 2) el grado de asincronía entre la floración masculina y femenina, 3) la cantidad de polen producido, etc. Sin embargo, en los estudios relacionados con la recolección y regeneración de recursos genéticos, y con el mejoramiento genético de los cultivos, comúnmente todos estos factores se consideran implícitamente como parte del azar y no reciben consideración particular (Wricke y Weber, 1986; Lynch y Walsh, 1998; Dudley, 2009).
Respecto a la recolección de recursos fitogenéticos, puede ser que la muestra deba obtenerse de la semilla producida por el apareamiento aleatorio natural de las plantas en un lote de producción comercial del cultivo de interés. También se puede tener grupos de semilla que originarán familias (un conjunto de mazorcas de maíz, por ejemplo). Estas dos situaciones de muestreo corresponden al muestreo completamente al azar y al muestreo combinado en dos etapas, respectivamente.
El objetivo de la presente investigación fue determinar el tamaño efectivo en términos de endogamia de una población monoica asociada a dos maneras con bajo costo de formar y manejar una muestra para recolectar y regenerar tal población. Los métodos son el muestreo combinado en dos etapas y el muestreo completamente al azar; en ambos, el paso de una generación a la siguiente es mediante apareamiento aleatorio de los individuos que constituyen la muestra.
MÉTODOS Y MARCO TEÓRICO
La población
Como la presentan Falconer y Mackay (2007) al describir el modelo de población ideal, una población objeto de recolección, o población base, en este estudio se entendió como un conjunto de un número grande de individuos monoicos no endogámicos y no emparentados que se reproducen por apareamiento aleatorio sin fuerza alguna que cambie las frecuencias génicas. El ciclo cero (Co) se consideró como a una muestra aleatoria de mn individuos tomados aleatoriamente de la población base. El coeficiente de endogamia de este ciclo (Fo,e), por su origen, es cero, es decir, Fo,e=0; además, el apareamiento aleatorio de los individuos de la muestra produce nm familias de medios hermanos. En el muestreo en dos etapas primero se hace la selección al azar de n de estas familias (n mazorcas, por ejemplo) y de cada una de ellas se toman m semillas aleatoriamente. Con las nm semillas seleccionadas se formará el ciclo 1 (C1). Si en este ciclo el genotipo del individuo p(p = 1,2,...,m) de la familia i(i=1,2,...,n) se representa por Api1 Api2, el arreglo genotípico del C1[AGC1] se expresa así:
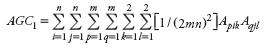
Para regenerar la población, del C1 se toma una muestra como en el ciclo anterior. Los mn individuos se someten a apareamiento aleatorio y se produce el C2, y así se continúa avanzando generacionalmente.
En el muestreo completamente al azar, de la población que resulte del apareamiento aleatorio del C0(C1) se toma una muestra al azar, sin ninguna restricción, de mn individuos. Para regenerar la población, se somete a apareamiento aleatorio a los mn individuos. La población resultante es muestreada de la misma forma y la muestra se someterá a apareamiento aleatorio, y así sucesivamente. En el arreglo genotípico de la progenie habrá individuos cuyos genotipos estarán formados por dos genes idénticos por descendencia (ApikApik) producidos por autofecundaciones y por cruzas entre individuos emparentados.
En el muestreo aleatorio en dos etapas (MADE), el apareamiento aleatorio de la muestra que se toma del Ct–1 para formar el Cp también produce genotipos formados por dos genes idénticos por descendencia (producidos por autofecundaciones, cruzas entre medios hermanos y cruzas entre individuos emparentados de diferentes familias). En términos generales, se espera que la frecuencia de éstos sea mayor que la del muestreo completamente al azar (MACA).
Tamaño efectivo de población
El tamaño efectivo de la población en términos de endogamia para MADE (Ne(f))se determinó con base en la derivación de la varianza de cada una de dos variables relacionadas con la cantidad de gametos de un individuo que llegan a formar progenie para la generación siguiente: los de origen femenino y los de origen masculino. Se hizo así porque si bien en la fórmula del tamaño efectivo de población en términos de endogamia (Crow y Kimura, 1970) se requiere la varianza del número de gametos exitosos de un individuo, se quiso determinar la contribución a ésta la de la varianza de los gametos de origen femenino y la de los de origen masculino ya que en este caso, por el tipo de muestreo, deben ser diferentes. Para MACA de mn individuos, el tamaño efectivo de población en términos de endogamia (Ne(f)CA) determinó con la fórmula y procedimiento descritos para MADE. De esta manera se calcularon los valores Ne(f) y Ne(f)CA Para las combinaciones de 13 valores de m y 13 de n. Y la eficiencia relativa de estos dos métodos de muestreo se calculó como [Ne(f) / Ne(f)CA] 100.
RESULTADOS Y DISCUSIÓN
El tamaño efectivo en términos de endogamia (Ne(f)) de una población que es como la población ideal (PI) definida por Falconer y Mackay (2007), pero que tiene la posibilidad de que los progenitores tengan diferencias en sus capacidades reproductivas; se expresa como (Wright, 1938; Crow y Kimura, 1970):

En la Ecuación 1, Var(G) es la varianza (Var) de G, la variable aleatoria para el número de gametos de un individuo que llegan a formar progenie. En la PI este número de gametos es una variable aleatoria binomial con parámetros 2mn y 1/(mn); su varianza es igual a 2mn[1 / (mn)] [1 – 1 / (mn)] =2[1 – 1 / (mn)]. Con esta varianza en la Ecuación 1 resulta que Ne(f) = mn, como era de esperarse (Crow y Kimura, 1970). En la población ideal con MADE, para formar la muestra se toman m individuos al azar de cada una de n familias de medios hermanos, también tomadas al azar. Así, cada uno de los n progenitores comunes de las familias de medios hermanos seleccionadas aleatoriamente aportará m gametos (femeninos) que formarán progenie; y los n(m–1) individuos restantes aportarán cero gametos de este tipo. Así, hay una variable aleatoria (F) para estos números de gametos maternos. Además, el número de gametos de origen paterno que formarán progenie es una variable aleatoria (M) que sigue una distribución binomial con parámetros mn y 1 /(mn); es decir, los valores que puede tomar M son 0, 1, 2,...,mn y la probabilidad de que cada gameto tenga éxito es 1 /(mn). Respecto a la relación entre las variables My F se considerará que su covarianza es igual a cero. Y con relación a los términos de la fórmula para el tamaño efectivo de población con muestreo combinado en dos etapas (Ecuación 1), G=M+F y Var(G) = Var(M) + Var(F). Además:
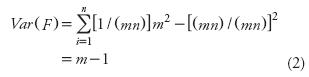
Obviamente, Var(F) es mayor a medida que m crece (Ecuación 2). Cuando m = 1, Var(F) = 0, que refleja la falta de variabilidad debida a que cada uno de los n individuos que forman la muestra contribuye con un gameto femenino efectivo (con m=1 el tamaño de muestra es mn = n). Respecto a M:

De acuerdo con las Ecuaciones 2 y 3, en el caso extremo en que m=1 y n=1, Var(M) = Var(F) = 0 refleja que por tratarse de sólo un individuo tiene que haber sólo un gameto masculino y uno femenino exitosos y ambos tamaños efectivos de población en términos de endogamia (los de los dos tipos de muestreo) son iguales a 1 (Ecuación 1). Además, siempre que m=1 y n>1, Var(F) < Var (M) (Ecuaciones 2 y 3). Sin embargo, es suficiente que m>1 para que Var(F) > Var(M), y esta superioridad de Var(F) se acentúa a medida que m es mayor; es decir, al tener cada familia más miembros, la diferencia Var(F) – Var(M) será más grande. Este efecto se relaciona directamente con la mayor contribución que tiene en la endogamia la aportación de más gametos femeninos que formarán progenie de un mismo progenitor. En el caso general, de acuerdo con las Ecuaciones 2 y 3, respecto a Var(G):
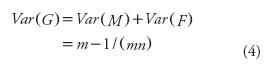
Según las Ecuaciones 1 y 4, el número efectivo en términos de endogamia [Ne(f)] para la población ideal con muestreo en dos etapas (MADE) se expresa como:
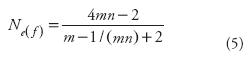
De acuerdo con la Ecuación 5, y con los Ne(f) calculados que se muestran en el Cuadro 1, el tamaño efectivo de la población con MADE (Ne(f))para un tamaño de muestra constante, crece en la medida en que m disminuye (y n aumenta); y para cualquier valor de n, respecto a m, alcanza su máximo cuando m=1. Además, cuando m=1 Ne(f) se expresa como Ne(f) = n (4n — 2) / (3n—1). Según esta ecuación, Ne(f) se aproxima a (4/3) n cuando n crece. Esto se evidencia en los Ne(f) que se muestran en el Cuadro 1 para m=1. Lo referido acerca del tamaño de muestra de los dos tipos de muestreo implica que con MADE para la recolección y regeneración de recursos genéticos una vez determinado el tamaño de la muestra, la mejor estrategia es tomar al azar un número de individuos igual al tamaño de muestra y de cada uno de ellos tomar al azar una semilla. Con los individuos resultantes se establece el ciclo siguiente. Con cualquier otra forma de componer una muestra del mismo tamaño (por ejemplo la mitad de familias y 2 individuos por familia) o con la muestra completamente aleatoria (MACA) del mismo tamaño se tendrá un tamaño efectivo de población menor, lo que implica una mayor endogamia o un menor tamaño efectivo, o una mayor probabilidad de perder genes.
Respecto a los efectos que tienen las magnitudes de m y n en el Ne(f), la Ecuación 5 y los N calculados (Cuadro 1) permiten apreciar que: 1) para un valor dado de m, Ne(f) crece prácticamente en la misma proporción en que se incremente n; 2) para un valor cualquiera de n fijo, en cambio, a los aumentos de m corresponden aumentos menores de Ne(f) que muy pronto deja de crecer; y nunca supera a 4n.
Cuando la muestra es de tamaño mn y se hace completamente al azar, Fy M tienen la misma varianza que debe ser 1 — 1 / (mn) (Ecuación 3), y de acuerdo con la Ecuación 1, el tamaño efectivo (Ne(f)CA) se debe expresar como en la forma:

Respecto al caso de muestreo en dos etapas (MADE) con m = 2, de la Ecuación 5 resulta que:
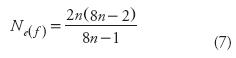
Esta expresión (Ecuación 7) implica que MADE con m = 2 genera un valor de Ne(f) que siempre será menor que el tamaño efectivo de MACA (Ne(f)CA) que tiene el mismo tamaño de muestra (2n). Sin embargo, la diferencia es marginal y para efectos prácticos ambos tamaños efectivos son iguales (Cuadro 1).
Respecto a la fórmula general del tamaño efectivo para MADE (Ne(f), Ecuación 5), ésta puede ser expresada, de manera muy aproximada y simple, como:
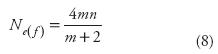
Esta expresión aproximada para Ne(f) (Ecuación 8) produce, para efectos prácticos, los mismos valores que genera la Ecuación 5 para prácticamente todas las combinaciones de valores de m y n. La Ecuación 8, sin embargo, es más manejable. Por ejemplo, esta expresión, (4mn) / (m + 2), permite apreciar rápidamente que: 1) para m = 2, Ne(f) = 2n, que es igual a Ne(f)CA =2n; 2) con m>3, Ne(f) < Ne(f)CA ( Ne(f)CA = mn), y 3) conforme m crece, Ne(f) se acerca más a 4n.
Los Ne(f) que se muestran en el Cuadro 1 para numerosas combinaciones de valores de m y n permiten ilustrar la importancia considerable que tiene la forma de integrar la muestra. Por ejemplo, para un tamaño de muestra constante mn, Ne(f) responde con incrementos mayores a los incrementos de n que a los de m. Estos resultados son consistentes con los que encontraron Sahagún y García (2009) en términos de endogamia, y se puede explicar arguyendo que los incrementos de m redundan en mayores aportaciones de genes de un mismo origen, en tanto que los de n significan una mayor diversidad genética para la población. El efecto que tiene la forma de constituir una muestra de tamaño mn fue impactante; por ejemplo, para un tamaño de muestra (mn) igual a 1000, el Ne(f)CA sólo puede de ser igual a 1000; el Ne(f), en cambio, fluctúa entre 4 y 1333; el 4 ocurre cuando n=1 y m = 1000, y el 1333 cuando n=1000 y m= 1.
Para relacionar Ne(f) con Ne(f)CA considérese que cuando mn es grande, del orden de 100 al menos, el cociente Ne(f) / Ne(f)CA se reduce aproximadamente a 4 / (m + 2). Claramente, este cociente es independiente de n y tiene un valor inversamente proporcional a m, y (de nuevo) sólo si m =1 resulta más conveniente el uso del muestreo en dos etapas (MADE) que el muestreo completamente aleatorio (MACA); en este caso MACA requiere un tamaño de muestra 33–33 % mayor que el de MADE para producir la misma tasa de endogamia, o el mismo tamaño efectivo de población en términos de endogamia. Del cociente 4 / (m + 2) se puede concluir más fácilmente que de la Ecuación 5 que da lo mismo hacer MADE tomando dos individuos de cada familia que tomar la muestra completamente al azar. Sin embargo, con m>2 el muestreo en dos etapas siempre será inferior.
De acuerdo con la fórmula de Crow y Kimura (1970) para Ne(f) (Ecuación 1), es posible aumentar el tamaño efectivo de población en términos de endogamia en relación a los obtenidos con muestreo en dos etapas y con muestreo completamente al azar con una muestra del mismo tamaño. Para que esto suceda se debe aplicar una estrategia que reduzca Var(G). Sin embargo, las estrategias tendientes a reducir la variabilidad del grado de participación de los individuos en la formación de la progenie requieren polinización artificial y ésta incrementa los costos.
Por ejemplo, para que ocurra que Var(G) = 0 es necesario que Var(F) = Var(Af)=0; esto es posible si de las mn plantas de la muestra se hacen mn/2 parejas y de la cruza (artificial) entre los dos miembros de cada pareja se obtienen dos individuos (hermanos completos). De acuerdo con la Ecuación 1, en este caso Ne(f) es igual a 2mn— 1.
En el presente estudio se ha discutido la obtención de sólo una muestra de mn individuos para la regeneración de la población. Por supuesto, en la práctica es conveniente tener varias copias de la muestra para evaluar la germinación de la muestra y asegurarse contra una pérdida por desastre en el campo, etc. En el presente estudio se ha considerado sólo al ciclo cero formado por mn individuos no endogámicos y no emparentados. Si la población original se encuentra en forma de familias de medios hermanos (por ejemplo en forma de mazorcas en el caso de maíz) el ciclo cero puede ser un conjunto de n familias de m medios hermanos cada una. El uso de esta forma de muestra no produciría cambios a los resultados aquí obtenidos en relación a Ne(f) dado que no se afectaría la fórmula para Ne(f) (Ecuación 1).
Finalmente, se usó sólo el tamaño efectivo en términos de endogamia, aunque también se ha usado el tamaño efectivo en términos de varianza (Vencovsky y Crossa, 1999). Se hizo así porque ambos coinciden cuando el tamaño de muestra es constante a través de generaciones (Caballero, 1994).
CONCLUSIONES
En una población que se recolecta y se regenera cíclicamente, y cada ciclo se forma por el apareamiento al azar de los individuos de una muestra del ciclo anterior, la muestra puede ser completamente aleatoria (MACA) o tomarse en dos etapas (MADE), m individuos aleatorios tomados de cada una de n familias también seleccionadas al azar. Con MADE, el tamaño efectivo de población en términos de endogamia ( Ne(f))crece a medida que m es más pequeño y alcanza su valor más alto cuando m=1, y sólo en este caso (con n>1) supera al de MACA ( Ne(f)CA) ; las fórmulas son: Ne(f) =[4mn–2] / [m–(mn)–1+2] y Ne(f)CA = mn. En el caso que puede ser de un valor aplicado importante) donde el valor de mn es de al menos 100, Ne(f) / Ne(f)CA es aproximadamente igual a 4 / (m + 2), que implica que: 1) MADE es superior que MACA sólo cuando m=1; 2) cuando m = 2 no hay diferencia en tamaño efectivo entre MADE y MACA; y 3) cuando m>2 siempre sucederá que Ne(f)CA > Ne(f). Además la composición de la muestra en términos de la selección de m y n es de importancia considerable.
LITERATURA CITADA
Caballero, A. 1994. Developments in the prediction of effective population size. Heredity 73: 657–679. [ Links ]
Crossa, J., and R. Vencovsky. 1997. Variance effective population size for two–stage sampling in monoecious species. Crop Sci. 37: 14–26. [ Links ]
Crow, J. R, and M. Kimura. 1970. An Introduction to Population Genetics Theory. Harper and Row Publishers. New York. 591 p. [ Links ]
Dudley, J. W., and G. R. Johnson. 2009. Epistatic models improve prediction of performance in corn. Crop Sci. 49: 763–770. [ Links ]
Falconer, D. S., y T. F. C. Mackay. 2007. Introducción a la Genética Cuantitativa. 4a Edición. Editorial Acribia S. A. Zaragoza, España. 469 p. [ Links ]
Hallauer, A. R., and J. B. Miranda Fo. 1981. Quantitative Genetics in Maize Breeding. Iowa State University. Ames, IA. USA. 468 p. [ Links ]
Hendrick, P. 2005. Genetics of Populations, 3rd ed. Jones and Bartlett Publishers. Massachusetts, USA. 737 p. [ Links ]
Kimura, M., and J. F. Crow. 1963. The measurement of effective population. Evolution 17: 279–288. [ Links ]
Lynch, M., and B. Walsh. 1998. Genetics and Analysis of Quantitative Traits. Sinauer Associates. Sunderland, Massachusetts. 920 p. [ Links ]
Molina G., J. D. 1992. Introducción a la Genética de Poblaciones y Cuantitativa: Algunas Implicaciones en Genotecnia. AGT Editor S. A. México. 349 p. [ Links ]
Sahagún C., J.,y F. García M. 2009. El coeficiente de endogamia de una población bajo selección masal. Agrociencia 43: 119–132. [ Links ]
Vencovsky R., and J. Crossa. 1999. Variance effective population size under mixed self and random mating with applications to genetic conservation of species. Crop Sci. 39: 1282–1294. [ Links ]
Wricke, G., and W. E. Weber. 1986. Quantitative Genetics and Selection in Plant Breeding. Walter de Gruyter, Berlin, New York. 406 p. [ Links ]
Wright, S. 1931. Evolution in mendelian populations. Genetics 16:97–159. [ Links ]
Wright, S. 1938. Size and population and breeding structure in relation to evolution. Science 87: 430–431. [ Links ]

