










Servicios Personalizados
Revista

Articulo
 Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por emailIndicadores
 Citado por SciELO
Citado por SciELO Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkAgrociencia
versión On-line ISSN 2521-9766versión impresa ISSN 1405-3195
Agrociencia vol.43 no.2 Texcoco feb./mar. 2009
Fitociencia
El coeficiente de endogamia de una población bajo selección masal
The inbreeding coefficient of a population under mass selection
Jaime Sahagún–Castellanos*, Francisco García–Mezano
Instituto de Horticultura, Departamento de Fitotecnia, Universidad Autónoma Chapingo. Chapingo, Estado de México. 56230. km 38.5. Carretera México–Texcoco. *Autor responsable: (jsahagun@correo.chapingo.mx)
Recibido: Marzo, 2007.
Aprobado: Octubre, 2008.
Resumen
La endogamia generada en el mejoramiento genético de poblaciones finitas de especies alógamas se relaciona con los conceptos de población ideal, número efectivo de la población, y magnitud de la respuesta a la selección. Dado que para la selección masal existen dos ecuaciones diferentes para determinar el coeficiente de endogamia, se desarrolló un estudio teórico tendiente a verificar la veracidad de ambas. Dicho estudio se hizo en términos probabilísticos basándose en el modelo de población ideal, donde el avance de generaciones se inicia a partir del ciclo 0 (C0) que fue una muestra aleatoria de mn individuos no endogámicos y no emparentados. En cada uno de los ciclos siguientes la muestra fue de n familias de m medios hermanos cada una. Se encontró que, para la generación t, el coeficiente de endogamia (Ft), aquí derivado, es Ft = (1 + Ft–1) / (2mn) + (m – 1)(1 + Ft–2 + 6 Ft–1) / (8mn)+ (n – 1) Ft–1 / n donde, t = 2, 3, ...; F0 = 0 y F1 = (2mn)–1. Además, para el caso en que C0 es una muestra de n familias de m medios hermanos cuyo coeficiente de endogamia es igual a cero, se encontró que para los ciclos 0 y 1 los coeficientes de endogamia son F0, F = 0 y F1,F = 1/(2mn) + (m – 1)/(8mn), y para t = 2, 3,..., el coeficiente de endogamia (Ft,F ), tiene la misma expresión que la de Ft, excepto que los coeficientes de endogamia son Ft–1F y Ft–2,F en lugar de Ft–1 y Ft–2 . Para incluir el efecto de la presión de selección en estos coeficientes se substituyen mn, n y m por Ne(v) (número efectivo en términos de varianza), (nNe(v)m)0.5 y (mNe(v)n)0.5.
Palabras clave: Coeficiente de endogamia, coeficiente de parentesco o coancestría, número efectivo, respuesta a la selección, selección masal.
Abstract
The inbreeding generated in the genetic improvement of finite populations of alogamous species is related to the concepts of ideal population, effective number of the population, and magnitude of the response to selection. Given that for mass selection there are two different equations to determine the inbreeding coefficient, a theoretical study was developed tending to verify the veracity of both. This study was made in probabilistic terms based on the ideal population model, where the advance of generations starts from the cycle 0 (C0) which was a random sample of mn individuals that were not inbred and not related. In each one of the following cycles the sample was of n families of m half sibs each. It was found that for generation t, the inbreedng coefficient (Ft), derived here, is Ft = (1 + Ft–1) / (2mn) + (m – 1)(1 + Ft–2 + 6 Ft–1) / (8mn)+ (n – 1) Ft–1 / n where t = 2, 3, ...; F0 = 0 and F1 = (2mn)-1. Furthermore, for the case in which C0 is a sample of n families of m half sibs whose inbreeding coefficient is equal to zero, it was found that for the cycles 0 and 1 the inbreeding coefficients are F0,F = 0 and F1,F = 1/(2mn) + (m – 1)/(8mn), and for t = 2, 3,..., the inbreeding coefficient (Ft,F) has the same expression as that of Ft , except that the inbreeding coefficients are Ft–1F and Ft–2t instead of Ft–1 and Ft–2 . To include the effect of the selection pressure in these coefficients, mn, n and m are substituted by Ne(v) (effective number in terms of variance), (nNe(v)m)0.5 and (mNe(v)n)0.5.
Key words: Inbreeding coefficient, coefficient of relationship or coancestry, effective number, selection response, mass selection.
INTRODUCCIÓN
En el estudio teórico de una población se requiere el concepto de población ideal introducido por Wright (1922), a fin de referirla a una población estándar, al pasar de una generación a la siguiente. El nexo más característico entre cualquier población y la ideal es el tamaño efectivo o número efectivo de la población (Falconer y Mackay, 2001). El número efectivo tiene dos definiciones (Crow y Kimura, 1970): a) en términos de endogamia, y b) en términos de varianza. En el primer caso, el número efectivo de una población es el tamaño de la población ideal cuya tasa de endogamia es igual a la de la población. En términos de varianza, el número efectivo de una población es el tamaño de la población ideal cuya varianza de la frecuencia génica es igual a la de la población.
En el mejoramiento genético la endogamia de una población es importante porque reduce la variabilidad genética y genera depresión endogámica y, con ello, reduce la ganancia genética esperada por efecto de selección (Robertson, 1960). En la selección masal, en cultivos como maíz (Zea mays L.), tomate de cáscara (Physalis ixocarpa Brot.), etc., cada generación puede considerarse como el resultado del apareamiento aleatorio de los mn individuos provenientes de n familias de m medios hermanos cada una (cada familia proviene de las semillas de cada uno de los n individuos seleccionados en la generación anterior). El tamaño finito de estas poblaciones es la fuente de endogamia que, como se mencionó, puede producir depresión endogámica y pérdida de variabilidad, causantes ambas de una reducción en la ganancia genética que se esperaría en un programa de mejoramiento genético por selección.
Las poblaciones de plantas alógamas objeto de mejoramiento genético por selección masal tienen una estructura muy parecida a la de la población ideal en las generaciones 1, 2, 3,... . En éstas, debido a los tamaños finitos de las poblaciones, se producen apareamientos entre parientes, aunque la reproducción sea por apareamiento aleatorio. Márquez–Sánchez (1998, 2005) desarrolló fórmulas del coeficiente de endogamia asociadas a la selección masal en dos formas: en una, el coeficiente de endogamia de una generación lo expresó en función del coeficiente de endogamia de las tres generaciones inmediatamente anteriores (Márquez–Sánchez, 1998), y en la otra lo hizo en términos sólo de la generación anterior (Márquez, 2005). En ambos casos el ciclo cero fue considerado como un conjunto de individuos no emparentados, con un coeficiente de endogamia igual a cero. En razón de que ambas fórmulas producen resultados diferentes, el presente desarrollo teórico tuvo por objeto determinar la validez de cada una de las fórmulas y derivar una nueva para expresar sin error el nivel de endogamia verdadero. Otro objetivo fue derivar el coeficiente de endogamia para el caso particular en que el ciclo cero es una muestra de familias de medios hermanos cuyo coeficiente de endogamia es igual a cero.
MÉTODOS Y MARCO TEÓRICO
La población ideal, más que un conjunto de individuos, es un proceso cuyo punto de partida es un conjunto formado por un número infinito de individuos no emparentados y con un coeficiente de endogamia igual a cero (Falconer y Mackay, 2001). De esta población se toma una muestra aleatoria de N individuos (ciclo cero) cuya progenie, producida por apareamiento al azar, constituye el ciclo 1. El ciclo 2 es la progenie que produce el apareamiento aleatorio de los N individuos de una muestra tomada aleatoriamente de la generación 1. Las generaciones siguientes se producen de igual manera. Según Falconer y Mackay (2001), el coeficiente de endogamia de la generación 1(F1) es igual a 1/ (2N), y sólo contribuyen a él las autofecundaciones. Éstas ocurren con una frecuencia de 1/N, y cada una produce una progenie cuyo coeficiente de endogamia es ½. Al coeficiente de endogamia de la generación 2(F2), además de las autofecundaciones, también contribuyen las cruzas entre individuos emparentados (Sahagún, 2006), y debe expresarse como F2 = 1 (1/N) + [1–1 / (2N)] F1 . Desde la generación 2 las fuentes endogámicas son las dos mencionadas, y el coeficiente de endogamia de la generación t (t = 2, 3,...) es (Falconer y Mackay, 2001):

Llevar el avance generacional de la población ideal requiere considerar el concepto de sistema recurrente de endogamia. Los sistemas recurrentes de endogamia relevantes en este desarrollo teórico son la autofecundación y el apareamiento entre medios hermanos cuyas ecuaciones recurrentes para el coeficiente de endogamia en la generación t (t = 1, 2, 3,...) son (Falconer y Mackay, 2001):

y

En este trabajo el coeficiente de endogamia de una población es la probabilidad de que los dos genes de un locus cualquiera de un individuo tomado al azar sean idénticos por descendencia. El coeficiente de parentesco o coancestría de una población, como la que es objeto de este estudio, es la probabilidad de que dos genes tomados al azar del mismo locus de dos individuos, también tomados al azar de la población, sean idénticos por descendencia. Además, con apareamiento aleatorio, el coeficiente de endogamia de una población en la generación t es igual a la coancestría de la población de la generación t–1.
La fórmula del coeficiente de endogamia de una población es una combinación lineal de coeficientes de endogamia y de coancestrías. Según Márquez–Sánchez (1998), el coeficiente de endogamia de una población como la ideal en la generación t en la que la muestra aleatoria de la generación t–1 (t = 2, 3,...) está formada por n familias de m medios hermanos maternos cada una (FMt) es:

Los componentes de la Ecuación (4) tienen el siguiente significado: 1) la fracción de la generación t que se formó por las cruzas entre individuos de diferentes familias es (n—1)/ n cuyo coeficiente de endogamia es Ft–1, el cual es igual a la coancestría de individuos de familias diferentes de medios hermanos; 2) la fracción de la generación t que se formó por apareamiento entre individuos de una misma familia es (m–1)l(mn) y su coeficiente de endogamia es Ft–2; 3) la fracción de la generación t que se produjo por autofecundación es 1/(mn), y tiene un coeficiente de endogamia (1 + Ft–3)/2.
La segunda forma como Márquez Sánchez (2005) expresó el coeficiente de endogamia Ft para la poblacional ideal constituida por n familias de m medios hermanos cada una es:

En este estudio las derivaciones del coeficiente de endogamia se hicieron con base en el arreglo genotípico descrito por Kempthorne (1969) y Sahagún (1994) y en el concepto de probabilidad de identidad por descendencia de dos genes. Similarmente, el avance de una generación a la siguiente se basó en el concepto de arreglo gamético de Kempthorne (1969) de la generación precedente. La población de referencia en este estudio está formada por n familias de medios hermanos maternos con m individuos en cada familia.
RESULTADOS Y DISCUSIÓN
Ciclo 0: Individuos no endogámicos y no emparentados
Para efectos de notación, supóngase que de una muestra aleatoria de mn individuos de la población ideal básica, con un número infinito de individuos no endogámicos y no emparentados, se forman n grupos de m individuos cada uno (ciclo 0). Supóngase además que el genotipo del individuo p (p = 1, 2,..., m) del grupo i ( i = 1, 2,..., n) es Api1Api2. La frecuencia de este genotipo es 1/(mn) y el arreglo genotípico de la muestra será 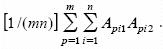 Como cada uno de los gametos que producen los individuos de esta muestra aparecen con una frecuencia de 1/(2mn) su arreglo es
Como cada uno de los gametos que producen los individuos de esta muestra aparecen con una frecuencia de 1/(2mn) su arreglo es  En consecuencia, el arreglo genotípico del ciclo 1 (AGC1), producido por el apareamiento aleatorio de la muestra o ciclo 0 será (Kempthorne, 1969):
En consecuencia, el arreglo genotípico del ciclo 1 (AGC1), producido por el apareamiento aleatorio de la muestra o ciclo 0 será (Kempthorne, 1969):
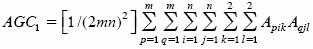
El coeficiente de endogamia del ciclo 1 (F1), de acuerdo con los conceptos de probabilidad (P) y de identidad de genes por descendencia (=), es:

El ciclo 2 (C2) se formará con los mn individuos que resultan de una muestra aleatoria del ciclo 1 constituida por n individuos, cada uno de los cuales producirá una familia de m medios hermanos maternos. Los ciclos siguientes se formarán de una manera similar.
En el ciclo 1 (C1), el arreglo genotípico de la i–ésima familia (de la muestra) cuyo progenitor común es la hembra p de la muestra tomada del ciclo 0 [AGFC1)pi ; p = 1,2,..., m; i = 1,2,...., n] resulta del producto de su arreglo gamético por el del ciclo 0, es decir:

Por analogía, el arreglo genotípico de otra familia de la muestra, la i–ésima  por ejemplo, cuyo progenitor común tiene genotipo Ap,i,1 Ap,i,2 (p' = 1, 2,..., m) debe ser de la forma:
por ejemplo, cuyo progenitor común tiene genotipo Ap,i,1 Ap,i,2 (p' = 1, 2,..., m) debe ser de la forma:

Los arreglos genotípicos de las Ecuaciones 6 y 7 serán utilizados para describir la formación del arreglo genotípico del ciclo siguiente (C2) que se producirá por el apareamiento aleatorio de los individuos de las n familias que produce la muestra de n individuos con m semillas cada uno tomada del C1. El apareamiento aleatorio de los mn individuos resultantes produce cruzas de tres tipos: 1) autofecundaciones; 2) cruzas entre individuos de una misma familia; 3) cruzas entre individuos de familias diferentes. Los coeficientes de endogamia de las progenies que producen estos tres tipos de cruzas se derivan a continuación:
a) La autofecundación de Apik Aqjl (Ecuación 6) produce una progenie cuyo arreglo genotípico es:

El coeficiente de endogamia de esta progenie del ciclo 2 (FA2) es:

2) La cruza entre dos individuos de una misma familia es de la forma (Ecuación 6) Apik Aqil x Apik' Aq,j,l  = 1, 2,..., m; j, j' = 1, 2,..., n; k, k', l, l' = 1, 2). Dado que el arreglo genotípico de la progenie que produce esta cruza es (1/4) Apik Apik Apik'+ (1/4) Apik Aq,j,l' + Aqil Aq,j,l su coeficiente de endogamia (Fcw2) debe ser:
= 1, 2,..., m; j, j' = 1, 2,..., n; k, k', l, l' = 1, 2). Dado que el arreglo genotípico de la progenie que produce esta cruza es (1/4) Apik Apik Apik'+ (1/4) Apik Aq,j,l' + Aqil Aq,j,l su coeficiente de endogamia (Fcw2) debe ser:

3) La cruza entre individuos de familias diferentes es de la forma (Ecuaciones 6 y 7): Apik Aqjl x Ap,i,k q,j,l'  = 1, 2,..., n; p, p' = 1, 2,..., m; k, k' l, l = 1, 2). El arreglo genotípico que produce esta cruza es:
= 1, 2,..., n; p, p' = 1, 2,..., m; k, k' l, l = 1, 2). El arreglo genotípico que produce esta cruza es:
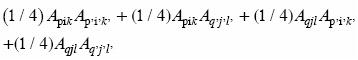
Por tanto, el coeficiente de endogamia de la progenie de la cruza entre individuos de familias diferentes de la muestra del C1 (FcB2) debe ser:

Con base en los coeficientes de endogamia de las Ecuaciones 8, 9, 10, y en las frecuencias con que ocurren las autofecundaciones, las cruzas entre individuos de una misma familia, y las cruzas entre individuos de familias diferentes que son: [1/(mn), [(m–l)/(mn)] y [(n – 1) / n], respectivamente, el coeficiente de endogamia del ciclo 2(F2) se debe expresar como:

Dado que en este caso F0 = 0, F2 se reduce a la ecuación:

Con un razonamiento análogo al que condujo a la Ecuación 11 se obtendrá que para t = 2, 3, 4, 5, ...

Nótese que con m = 1 en la Ecuación 12 resulta:

Esta fórmula, como se esperaba, es la del coeficiente de endogamia de la población ideal básica (Falconer y Mackay, 2001) en la que el paso de la generación t–í a la generación t (t = 1, 2, 3,...) se hace mediante el apareamiento aleatorio de los individuos de una muestra al azar de tamaño n de la generación t –1.
Con una muestra aleatoria donde m = 1 y n = 1 el avance de una generación a la siguiente mediante apareamiento aleatorio sólo puede ocurrir por autofecundación. La fórmula para el coeficiente de endogamia de la generación t debe ser, por tanto, la que corresponde a este sistema recurrente de endogamia (Ecuación 2). En efecto, con m = 1 y n = 1 la Ecuación 12 se reduce a la forma del coeficiente de endogamia para la autofecundación: Ft = (1/2)(1 + Ft_1). Los ensayos con m = 1 y m = n = 1 son consistentes con la veracidad de la fórmula 12.
Comparación de la ecuación 12 con las ecuaciones 4 y 5
La Ecuación 4 no tiene las dos propiedades observadas en los dos párrafos anteriores a la Ecuación 12 aquí derivada; ésta y la 4 tienen en común las frecuencias de ocurrencia de los tres tipos de cruzas. Sin embargo, en los coeficientes de endogamia de las progenies que producen estas cruzas hay diferencias en dos de los tres términos. La coincidencia ocurre en el coeficiente de endogamia de las progenies producidas por cruzas entre individuos de familias diferentes. En la autofecundación la diferencia está en que el coeficiente de endogamia es Ft–1 en la Ecuación 12 y Ft – 3 en la Ecuación 4, según Falconer y Mackay (2001). La derivación aquí efectuada (Ecuación 8) y su extensión obvia, sólo la presencia de Ft_l es correcta.
Para los individuos producidos por cruzas entre miembros de una misma familia de medios hermanos, la fórmula de la Ecuación 4 presenta el término Ft – 2, pero aquí se encontró el término ( 1 + Ft-2 + 6Ft-1) / 8 (Ecuación 12). Como en el caso anterior, este resultado es acorde con lo mostrado por Falconer y Mackay (2001). Como un argumento en términos explícitos de lo que subyace en la derivación del presente resultado (Ecuación 9), y de su generalización (segundo término de la Ecuación 12), considérese lo siguiente: dos medios hermanos maternos de la generación t –1 tienen en común haber recibido un gen de su progenitor común de la generación t–2 (este tipo de progenitores comunes de medios hermanos tiene, en promedio, un coeficiente de endogamia Ft-2); el otro gen del genotipo de cada uno de estos dos medios hermanos es aportado al azar por el arreglo gamético masculino (que es igual al de las hembras) de la generación t–2. El apareamiento entre estos dos medios hermanos de la generación t–1 debe producir una progenie formada por una frecuencia de ¼ de cada uno de los cuatro tipos de genotipos formados por: 1) dos genes maternos; 2) un gen materno de un medio hermano y un gen del arreglo gamético de los machos de la generación t–2; 3) un gen materno del otro medio hermano y otro del arreglo gamético de la generación t–2; 4) los dos genes del arreglo gamético de los machos de la generación t–2. Claramente, el coeficiente de endogamia de los genotipos descritos en (1) es equivalente al de la autofecundación de una hembra de la generación t–2; es decir, es igual a (l + Ft_2)/2 . El coeficiente de endogamia de los genotipos producidos por las tres formas restantes es, en cada caso, el de los genotipos formados por dos genes tomados de sendos e idénticos arreglos gaméticos de la generación t–2. Esto implica que el coeficiente de endogamia buscado es igual a la coancestría de la generación t–2 que, en apareamiento aleatorio, es igual al coeficiente de endogamia de la generación siguiente, la t–2 (Ft_l). Por tanto, el coeficiente de endogamia de las progenies producidas por apareamiento entre medios hermanos maternos de la generación t–1 (FMH,t) es:

Finalmente, considérense los argumentos siguientes para la derivación del coeficiente de endogamia de las progenies de la generación t producidas por el apareamiento entre individuos de familias diferentes de medios hermanos. El genotipo de cualquier individuo así producido (individuo t) está formado por sendos genes aleatorios de dos de sus cuatro abuelos (individuos t–2). Estos cuatro abuelos son a su vez progenitores de los progenitores (individuos t–1) del individuo t. Esto implica que el arreglo genotípico que producen las cruzas entre dos miembros de familias diferentes de medios hermanos (individuos t–1) sea igual al que produce el apareamiento al azar de los individuos del ciclo t–2, que produce individuos t–1. Por esta razón el coeficiente de endogamia de este arreglo genotípico debe ser Ft_l , como ya fue consignado en la derivación de la Ecuación 10.
Las consideraciones de los dos párrafos anteriores, relativas a la derivación del segundo y tercer términos de la Ecuación 12, que difieren de los que en su lugar tiene la Ecuación 4, conducen a determinar que la Ecuación 12 aquí derivada es correcta.
En relación con la fórmula de la Ecuación 5 para el coeficiente de endogamia de la población ideal en estudio, se considera que a diferencia de la Ecuación 4, sí satisface las dos propiedades descritas para la Ecuación 12. Sin embargo, la Ecuación 5 no es exacta; por principio, ésta se puede escribir también como:

La fórmula de la Ecuación 14 es la del coeficiente de endogamia de la generación t de la población ideal base que describen Falconer y Mackay (2001), con un tamaño de muestra de mn individuos tomados al azar, sin estructura familiar. Este coeficiente, por tanto, no refleja la endogamia de la población objeto de estudio en este trabajo. Por ejemplo, no incluye la contribución al coeficiente de endogamia Ft de los individuos producidos por los apareamientos entre dos individuos de una misma familia de medios hermanos de la generación anterior. Esta contribución se debería dar en términos que incluyan Ft_2, el coeficiente de endogamia del progenitor común, pero este término no aparece en la Ecuación 14.
Ciclo 0: Individuos no endogámicos (F0 = 0) emparentados
Supóngase ahora que la muestra original está formada por n familias de m medios hermanos cada una. En este ciclo, por tanto, hay individuos emparentados aunque su coeficiente de endogamia (F0,F) es igual a 0; es decir, F0.F = 0. Este caso puede tener mayor grado de realismo que el anterior en términos del manejo inicial de una población que es objeto de selección masal. Por supuesto, el ciclo 1, producido por el apareamiento aleatorio de los mn individuos de este ciclo 0, y el subsecuente muestreo asociado a la generación del C1, debe tener un coeficiente de endogamia mayor que el del ciclo 1 del caso anterior en el cual el ciclo 0 está formado por mn individuos no endogámicos y no emparentados. Pero, ¿cuál es el coeficiente de endogamia de este nuevo caso? El apareamiento aleatorio de los mn individuos del ciclo cero (C0) produce una población (ciclo 1) donde la formación de genotipos con dos genes idénticos por descendencia tiene dos fuentes: 1) la autofecundación; 2) el apareamiento entre medios hermanos cuyas frecuencias de ocurrencia son 1/(mn) y (m–1)/(mn) pero sus coeficientes de endogamia son Vi y, por similitud con la del resultado de la Ecuación 9, (1/4)(1/2). Por tanto, el coeficiente de endogamia del C1 (F1,F) se debe expresar como F1,F = 1 / (2mn) + (m – 1) (8mn).
El ciclo 2 (C2), como el C1, se formará por las progenies producidas por autofecundación, cruzas de medios hermanos y cruzas de individuos de familias diferentes, con frecuencias de ocurrencia de 1/(mn), (m–1)/(mn) y (n–1) / n. El coeficiente de endogamia de la progenie producida por autofecundación, por analogía de la derivación de la Ecuación 8, debe ser (1 + F1,F/ 2 . Del apareamiento entre dos medios hermanos del C1, ¼ de su progenie tendrá un genotipo formado por dos genes tomados al azar, con reemplazo, del genotipo del progenitor común, tal como se forma la progenie producida por autofecundación. Por tanto, el coeficiente de endogamia de esta cuarta parte del C2 debe ser (1 + F0,F) / 2 . De la progenie restante, el genotipo de cada individuo está formado por dos genes tomados al azar de sendos arreglos gaméticos del C0 (de machos y de hembras). Así, el coeficiente de endogamia de % de la progenie de la cruza entre medios hermanos debe ser F1,F . Por tanto, el coeficiente de endogamia del subconjunto de individuos producidos por cruzas entre medios hermanos del C1 (Fw2,F) debe ser:

Finalmente, la cruza entre dos individuos de familias diferentes del C1 produce genotipos formados por dos genes tomados al azar, sin reemplazo, de sendos arreglos gaméticos del ciclo 0. Como cada genotipo del ciclo 1 se forma con genes como estos dos, el coeficiente de endogamia de la progenie de cruzas entre individuos de familias diferentes debe ser F1,F.
Por lo determinado para los tres tipos de progenies del C2, el coeficiente de endogamia de este ciclo F2,F, considerando que F0,F = 0, se debe expresar como:

Generalizando, para t = 2, 3, 4,...
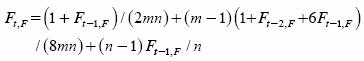
Este coeficiente de endogamia (Ecuación 15) siempre es mayor que el de la Ecuación 12 que corresponde al caso en que el C0 es un conjunto de mn individuos no emparentados cuyo coeficiente de endogamia es igual a cero. Esto se debe a que si bien en C0 ambos coeficientes de endogamia son iguales a cero (F0 = F0,F 0 , en el C1 los coeficientes de endogamia son F1=1 (2/ mn) y F1,F = 1 / (2mn) + (m – 1) / (8mn), y esta superioridad de F1,F sobre F1 por tener las dos fórmulas (Ecuaciones 12 y 15) exactamente la misma estructura y porque el coeficiente de endogamia es creciente a través de los ciclos, hace que para t = 2, 3,... Ft < Ft,F. Por supuesto, cuando 
Coeficientes de endogamia y selección
Los coeficientes de endogamia derivados en el presente trabajo (Ecuaciones 12 y 15) no dan cuenta del efecto de la presión de selección. Se espera que este efecto incremente el valor de dichos coeficientes debido a que la selección tiende a aumentar la frecuencia de los genes favorables para la expresión del carácter que interesa al fitomejorador.
Márquez–Sánchez (1998) analizó este problema con base en el número efectivo en términos de varianza [la varianza de la frecuencia génica debida al tamaño finito de población (Crow y Kimura, 1970)]. Para el caso en estudio, Crossa y Vencovsky (1997) encontraron, para muestras de tamaño grande, que este número efectivo (Ne(v)) es:
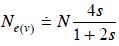
donde, N = mn y s es la presión de selección.
Para el caso en estudio, Márquez–Sánchez (1998) definió s = f/N, donde, f es el número de plantas seleccionadas (cada planta significa una familia de m medios hermanos para el ciclo siguiente). Para los valores de n = 200 y m = 20 considerados por este autor, s = n/(nm) corresponde a un 5% de presión de selección. Por ejemplo, cuando el C0 es un grupo de mn individuos no endogámicos (porque su coeficiente de endogamia es igual a cero) y no emparentados, el coeficiente de endogamia (Ecuación 12) es:

Para incluir el efecto de la selección en el coeficiente de endogamia, en lugar de nm se deberá escribir el número efectivo Ne(v) = 4Ns/(1 + 2s) = 727.27; y con respecto a n y a m, por separado, Márquez–Sánchez (1998) consideró que la proporción n/m se debe mantener para las n' y m' que satisfacen la ecuación Ne(v) = n' / m. Así, si Q = n/m = n'/m', m' = Ne(v) /n' y (m')2= Ne(v) m'/n' = Ne(v) Q–1. Y de aquí resulta que m', = [Ne(v)Q –1]0.5 y, similarmente, que n' = [Ne(v)Q]0.5.Una vez que Ne(v) y Q son conocidos, se pueden determinar los valores m' y n'. Así, en términos generales, el coeficiente de endogamia para la selección masal en el caso en que el ciclo cero está formado por un grupo de mn individuos no endogámicos y no emparentados (Ecuación 12), que refleja el efecto de la selección (F't,), es:

Obviamente, en este caso, F'0 = 0 y F'1 = l / [2Ne(v)] = 0.00068.
Así, para el caso en que n = 200 y m = 20, Q = 10, Ne(v)Q = 727.7, Ne(v) / Q = 72.72, y

Cuando el ciclo cero está formado por n familias de m medios hermanos cuyo coeficiente de endogamia es igual a cero, la fórmula para el coeficiente de endogamia que incluye el efecto de la selección, en la generación (F't,F) , con base en la Ecuación 15, para t = 2, 3, 4,... es:

Para el ejemplo en que n = 200 y m = 20, las Ecuaciones 16, 17 y 18 muestran que la mayor parte del coeficiente de endogamia de una generación se debe a las cruzas entre individuos de familias diferentes de la generación anterior. La comparación de la Ecuación 17 (que incluye el efecto de la selección) con la Ecuación 16 (que no incluye el efecto de la selección) permite apreciar que la selección produce un incremento de hasta 4 y 2 veces de la contribución al coeficiente de endogamia debido a la autofecundación y a las cruzas entre medios hermanos, respectivamente. No obstante este aumento, su contribución sigue siendo pequeña en relación a la de las cruzas entre individuos de familias diferentes.
CONCLUSIONES
Las fórmulas previas del coeficiente de endogamia de una población ideal donde la muestra inicial (ciclo cero) es un conjunto de mn individuos no emparentados que tienen un coeficiente de endogamia igual a cero, y en que la muestra en ciclos posteriores es de n familias de m medios hermanos cada una, no proporcionan con exactitud el coeficiente de endogamia. El coeficiente de endogamia exacto de la generación t (Ft) (t = 2, 3, 4, 5,...), derivado en este trabajo, es una combinación lineal de las tres contribuciones producidas por el apareamiento aleatorio de los individuos de la muestra de la generación anterior: 1) la autofecundación; 2) el apareamiento entre medios hermanos; 3) el apareamiento entre individuos de familias diferentes; las contribuciones a Ft (t = 2, 3, ...) son: (l + Ft–1) / (2mn), (m – 1) (1 + Ft_2 + 6Ft–1) / (8mn) y (n–1)Ft–1 / n, respectivamente; además, F0 = 0 y F1 = (2mn)–1. Cuando el ciclo cero es un conjunto de n familias de m medios hermanos cada una, el coeficiente de endogamia de la generación t (Ft,F) tiene los mismos términos que Ft excepto que para el primer ciclo F1,F = 1 / (2mn) + (m –1) / (8mn). Así, F2,F se expresará en términos de F1,F; F3,F etc. Por esta razón, para t = 2,3,... Ft,F = +(1+ Ft–1,F) / (2mn) + (m –1) (1+ Ft–2,F+ 6Ft–1,F ) / (8mn) + (n–1) Ft–1,F / n. Como estas dos, las fórmulas para el coeficiente de endogamia que reflejan el efecto de la selección masal para los dos casos estudiados, también tuvieron la misma estructura.
LITERATURA CITADA
Crossa, J., and R. Vencovsky. 1997. Variance effective population size. Crop Sci. 37: 14–26.
Crow, J. F., and M. Kimura. 1970. An Introduction to Population Genetics Theory. Burgess Ed. Minneapolis. 591 p. [ Links ]
Falconer, D. S., and T. F. C. Mackay. 2001. Introducción a la Genética Cuantitativa. 4a. edición. Ed. Acribia. Zaragoza. España. 469 p. [ Links ]
Kempthorne, 0. 1969. An Introduction to Genetic Statistics. Wiley, New York. 545 p. [ Links ]
Márquez–Sánchez, F. 1998. Expected inbreeding with recurrent selection in maize: I. Mass selection and modified ear–to–row selection. Crop Sci. 38: 1432–1436. [ Links ]
Márquez–Sánchez, F. 2005. Nuevas ecuaciones endogámicas para el mejoramiento genético del maíz. Universidad Autónoma Chapingo. Chapingo, Méx. 129 p. [ Links ]
Robertson, A. 1960. A theory of limits in artificial selection. Proc. Royal Soc. London 153: 234–239. [ Links ]
Sahagún C., J. 1994. Sobre el cálculo de coeficientes de endogamia de variedades sintéticas. Agrociencia serie Fitociencia 5: 67–78. [ Links ]
Sahagún C., J. 2006. Determinación de las fuentes endogámicas de la población ideal bajo muestreo continuo y apareamiento aleatorio. Agrociencia 40(4): 471–482. [ Links ]
Wright, S. 1922. The effects of inbreeding and cross–breeding on guinea pigs. Tech. Bull. U.S. Dep. Agric. 1112. Washington D.C. [ Links ]

