










Servicios Personalizados
Revista

Articulo
 Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por emailIndicadores
 Citado por SciELO
Citado por SciELO Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkAgrociencia
versión On-line ISSN 2521-9766versión impresa ISSN 1405-3195
Agrociencia vol.42 no.1 Texcoco ene./feb. 2008
Matemáticas aplicadas, estadística y computación
Ajuste regional de la distribución GVE en 34 estaciones pluviométricas de la zona Huasteca de San Luis Potosí , México
Regional fit of GEV distribution in 34 pluviometric stations of the Huasteca area in San Luis Potosi State, Mexico
Daniel F. Campos–Aranda
Universidad Autónoma de San Luis Potosí. Genaro Codina # 240. 78280 San Luis Potosí, San Luis Potosí. (campos_aranda@hotmail.com)
Recibido: Septiembre, 2006.
Aprobado: Noviembre, 2007.
Resumen
El análisis probabilístico regional de las lluvias máximas diarias anuales representa la base de las estimaciones de crecientes cuando no hay información hidrométrica. Los métodos regionales definen con mayor exactitud la cola derecha de la distribución de probabilidades, la cual permite realizar las predicciones de lluvia. El presente estudio está basado en información de 34 estaciones pluviométricas de la zona Huasteca de San Luis Potosí, que cuentan con más de 30 años de registro. La metodología consiste en aplicar cuatro procedimientos de ajuste regional de la distribución General de Valores Extremos (GVE), basados en el método de los momentos L: 1) método de las estaciones–años; 2) ajuste por momentos de probabilidad pesada ponderados; 3) método de los valores estandarizados medianos; 4) ajuste por momentos L regionales. Se concluye que los métodos regionales expuestos son confiables y que los dos procedimientos desarrollados (3 y 4) permiten acotar las predicciones.
Palabras clave: Métodos regionales, momentos L, precipitación máxima diaria.
Abstract
The regional probabilistic analysis of annual maximum daily rainfall represents the base of the estimations of flooding when there is no hydrometric information. The regional methods define more precisely the right tail of the distribution of probabilities, which makes it possible rainfall predictions. The present study is based on information of 34 pluviometric stations of the Huasteca area in San Luis Potosí, which have over 30 years of records. The methodology consists in applying four procedures of regional fit of the General Extreme Values distribution (GEV), based on the method of the L moments: 1) stations–years method; 2) fit by moments of weighted heavy probability; 3) method of the median standardized values; 4) fit by regional L moments. It is concluded that the regional methods shown are reliable and that both procedures developed (3 and 4) make it possible to restrict the predictions.
Key words: Regional methods, L moments, maximum daily rainfall.
INTRODUCCIÓN
El análisis probabilístico de la precipitación máxima diaria es la base de las estimaciones de las tormentas de diseño cuando no hay registros pluviográficos y se realiza un estudio hidrológico de la relación lluvia–escurrimiento para estimar las crecientes de diseño, porque tampoco hay información hidrométrica. El método de análisis consiste en ajustar un modelo probabilístico a partir de los datos históricos disponibles, para realizar las predicciones requeridas. El ajuste permite estimar los parámetros de escala, ubicación y forma de tal modelo, cuya exactitud depende del número de datos y de la posibilidad de modelar el extremo derecho de la distribución, donde ocurren los eventos extremos máximos y donde están las predicciones que interesan por estar asociadas a bajas probabilidades de excedencia o largos periodos de retorno.
El ajuste satisfactorio a una serie histórica de crecientes o lluvias máximas no garantiza estimaciones confiables para periodos de retorno superiores a 100 años; por ello se requieren otras series históricas para mejorar la reproducción de la cola extrema de la distribución (Buishand, 1991). Esta dificultad se presenta cuando hay valores dispersos (outliers) en la gráfica probabilidades y por ello se han interpretado como pertenecientes a otra población. Esta necesidad de más datos frecuentemente se satisface usando los registros disponibles en la zona o región, lo cual constituye el enfoque de los métodos regionales (Santillán, 2000; Escalante y Reyes, 2002), cuya ventaja es que algunos parámetros de una distribución, por ejemplo el de forma, no varían mucho a través de un área especifica o región (Buishand, 1991).
El propósito de este trabajo fue realizar un ajuste regional de la distribución General de Valores Extremos (GVE), basado en el método de los momentos L y usando cuatro criterios: 1) método de las estaciones–años; 2) ponderación de los momentos de probabilidad pesada; 3) método de los valores estandarizados medianos; 4) ajuste por momentos L regionales. Los dos últimos se desarrollaron durante el ajuste regional de la GVE a las estaciones pluviométricas de la zona Huasteca del Estado de San Luis Potosí, México.
MATERIALES Y MÉTODOS
Información pluviométrica utilizada
Ésta corresponde a la disponible sobre precipitación máxima diaria anual (mm) en el sistema ERIC II (IMTA, 2000), para las estaciones pluviométricas de la zona Huasteca, San Luis Potosí, con más de 30 años de datos. Con esa restricción se obtuvieron 34 estaciones (Figura 1) cuyas características generales y estadísticas de sus registros pluviométricos se presentan en el Cuadro 1; estas últimas incluyen la media  la desviación estándar (Sd), el coeficiente de variación (Cv) y el coeficiente de asimetría (Cs) (Yevjevich, 1972). El archivo de datos (xi, 1,222 en total ), está disponible con el autor.
la desviación estándar (Sd), el coeficiente de variación (Cv) y el coeficiente de asimetría (Cs) (Yevjevich, 1972). El archivo de datos (xi, 1,222 en total ), está disponible con el autor.

Análisis estadístico previo de los datos
Para que los resultados de los análisis probabilísticos sean teóricamente válidos, la serie de datos históricos debe satisfacer ciertos criterios estadísticos: aleatoriedad, independencia, homogeneidad y estacionalidad (Campos, 2006). La aleatoriedad significa que las fluctuaciones de la variable son originadas por causas naturales; la independencia se refiere a que ningún dato de la serie está influenciado por valores anteriores, o que él no influye a los posteriores; la homogeneidad implica que los datos proceden de una misma población y, finalmente, la estacionalidad significa que las propiedades estadísticas de los datos no cambian en el tiempo. Los registros de lluvias máxima diaria anual en general son aleatorios y muestran independencia, lo cual se comprobó con el coeficiente de correlación serial de orden 1 que no fue significativo. El registro puede ser considerado homogéneo verificando que la ubicación del pluviómetro no haya cambiado. La estacionalidad se acepta debido a que las condiciones geográficas de la zona Huasteca no se han modificado sustancialmente.
Ajuste de la distribución GVE a través del método de momentos L
La solución inversa de la función GVE que permite el cálculo de una predicción X es (Stedinger et al., 1993; Metcalfe, 1997; Campos, 2001):

donde, y es la variable reducida igual a:

donde, u es el parámetro de ubicación, α es el de escala y k el de forma, denominados parámetros de ajuste; F(x) es la probabilidad de no excedencia [P(X< x)] cuyo recíproco de su diferencia con la unidad corresponde al periodo de retorno o intervalo promedio de recurrencia en años (Tr). Las expresiones de los parámetros de ajuste según el método de momentos L son (Stedinger et al., 1993; Metcalfe, 1997; Campos, 2001):

donde, λ1 , λ2 y λ3 son los momentos L de orden uno, dos y tres; Γ(•) es la función gamma que se estima con la ecuación de Stirling (Davis, 1972):

La evaluación de los momentos L (λr) comienza con el cálculo de los momentos de probabilidad pesada muestrales (br ), ya que los primeros son combinaciones lineales de los segundos. Los estimadores insesgados de los br son (Stedinger et al., 1993):

donde, xi es la precipitación máxima diaria anual en mm, ordenada de mayor a menor, y n es el número de datos. Los momentos L son:

El error estándar de ajuste (EEA) que es un criterio numérico de bondad de ajuste para comparar modelos probabilísticos, es también aplicable al primero y último de los métodos regionales expuestos, es decir aquellos en que la distribución GVE se ajusta a los datos transformados; es igual a (Kite, 1977):
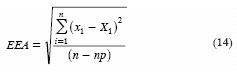
donde, n es el número de datos de cada registro y np es el número de parámetros de ajuste, np = 3 para la distribución GVE; xi son los datos ordenados en forma creciente y Xi las predicciones obtenidas con la ecuación 1. Las probabilidades de no excedencia F(x) se obtienen con la ecuación de Weibull (Benson, 1962):

donde m es el número de orden, con 1 para el menor de los datos y n para el mayor.
Método de las estaciones–años
En este método los datos máximos anuales (crecientes o lluvias) procedentes de varios sitios son conjuntados y tratados como un solo registro. Este enfoque acepta que los datos son variables aleatorias independientes, lo cual en el caso de la precipitación no es estrictamente válido debido a la dependencia espacial entre las lluvias observadas y a la relación que guarda ésta con la altitud. Para evitar lo anterior, una modificación importante consiste en estandarizar los datos, dividiéndolos entre su media aritmética o entre su mediana. Estos valores generalmente presentan homogeneidad regional, mostrando un coeficiente de variación aproximadamente constante (Buishand, 1991). Otro aspecto importante en este criterio es el riesgo que implica el uso de registros cortos con desigual inicio y final que las series largas, pues entonces valores muy bajos o muy altos pueden proceder de éstos y originarán sesgo en las estimaciones.
Ajuste por momentos de probabilidad pesada ponderados
La regionalización de los momentos de probabilidad pesada (br) comprende su estandarización, consistente en dividirlos entre la media o b0:

Lo anterior conduce a un be0= 1.000, para luego promediarlos. Cunnane (1988) y Buishand (1991) han sugerido ponderarlos en función de la amplitud del registro en años de la estación (nj), por lo cual:
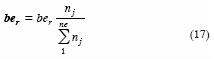
donde, ne es el número de estaciones pluviométricas usadas. El procedimiento consiste en calcular los momentos de probabilidad pesada de orden 0, 1 y 2 por medio de las ecuaciones 8 a 10, en cada estación pluviométrica de la región. Después se estandarizan éstos y se ponderan para obtener sus valores medios. Con base en tales promedios se calculan los momentos L de primero, segundo y tercer orden, por medio de las ecuaciones 11 a 13 y luego se ajusta la distribución GVE con el método de los momentos L (ecuaciones 1 a 7).
Método de los valores estandarizados medianos
Este procedimiento es una modificación del método tradicional de la avenida índice, o cociente entre una creciente de cierto periodo de retorno y el gasto considerado como medio anual (Dalrymple, 1960; Cunnane, 1988; Campos, 1994). Se apoya en que la mayoría de las 34 estaciones pluviométricas de la zona Huasteca tienen un registro de 37 años (1961 a 1997) (Cuadro 1) y consistió en ajustar por momentos L la distribución GVE (ecuaciones 1 a 13) a cada registro de valores estandarizados con su media aritmética.
Ajuste de la distribución GVE por momentos L regionales
Buishand (1991) propone estimar los parámetros de ajuste de la distribución GVE regional mediante la maximización de una función de verosimilitud conjunta, describiendo varios enfoques para alcanzar tal objetivo. El procedimiento adoptado consiste en ajustar una distribución GVE por momentos L (ecuaciones 1 a 15), mediante el procedimiento de las estaciones–años, con la siguiente variable estandarizada:

donde, u y α corresponden a los parámetros de forma regional de la distribución GVE, pero son los requeridos por cada registro para ajustar un modelo GVE. Por ello, al obtener la función GVE de los datos conjuntados se obtiene un nuevo parámetro de forma k regional que no cambia y requiere un nuevo cálculo de parámetros u y α de cada registro con las ecuaciones 5 y 6. El proceso se repite hasta que el valor del parámetro de forma regional (k) no varía de un intento a otro.
RESULTADOS Y DISCUSIÓN
Método de las estaciones–años
Al dividir cada dato de un registro entre su valor medio y conjuntar los 34 registros de la zona Huasteca (Cuadro 1) se obtuvieron 1222 valores, cuyo ajuste de la distribución GVE mediante el método de los momentos L (ecuaciones 1 a 15), condujo a los estimadores de los parámetros de ubicación, escala y forma siguientes: u=0.7897, α=0.2861 y k= –0.1444, con un error estándar de ajuste de 0.044 y los valores tabulados en el Cuadro 2 para las predicciones estandarizadas obtenidas con las ecuaciones 1 y 2.
Entonces, al multiplicar las magnitudes estandarizadas respectivas del Cuadro 2 por la media aritmética de cada registro, indicada como b0 en el Cuadro 3, se obtienen las predicciones respectivas del método de las estaciones–años, para las ocho estaciones pluviométricas seleccionadas por ser la primera y la última y las números 5, 10, 15, 20, 25 y 30 del Cuadro 1.
Ajuste por momentos de probabilidad pesada ponderados
En el Cuadro 4 se presentan los resultados numéricos del procedimiento de ponderación descrito, con base en los cuales se obtuvieron los siguientes estimadores de los parámetros de la distribución GVE: u=0.7845, α=0.2816 y k =–0.1669, con los valores de las predicciones estandarizadas indicadas en el Cuadro 2. Nuevamente, al multiplicar las magnitudes tabuladas por la media aritmética de cada registro se obtienen las predicciones respectivas de este método (Cuadro 3).
Método de los valores estandarizados medianos
Las predicciones de valores estandarizados con la media obtenidas para cada serie histórica se presentan en el Cuadro 5, así como los valores mínimos, medianos y máximos correspondientes a cada periodo de retorno. Con base en los valores medianos se obtienen las predicciones indicadas en el Cuadro 3, con sólo multiplicarlos por la media respectiva (b0) de cada registro o estación pluviométrica.
Ajuste de la distribución GVE por momentos L regionales
En el Cuadro 6 están los valores de u y a obtenidos con el método de momentos L en cada registro. El primer ensayo consistió en emplear los valores promedio de u y α del Cuadro 6 (107.6 y 38.9) como valores constantes en la aplicación de la ecuación 18, y se obtuvo un k regional de –0.1645; en el segundo ensayo se utilizaron los valores de u y α del Cuadro 6, es decir los que corresponden a los k locales indicados, y el valor de k fue –0.1684. Para el tercer ensayo se adoptó un k regional de –0.168 y para cada registro se calcularon con las ecuaciones 5 y 6 sus correspondientes valores de y α, los cuales se usaron en la ecuación 18. El ajuste conjunto de la GVE conduce a k=–0.1421, con u=0.0124 y α=0.9829. Un cuarto ensayo se hizo con el valor de k anterior y el obtenido fue el mismo. Las magnitudes finales de u y a se presentan el Cuadro 6 y las predicciones estandarizadas  están al final del Cuadro 2.
están al final del Cuadro 2.
En cada estación pluviométrica, con base en sus valores finales de u y α (Cuadro 6) y el de la magnitud  (Cuadro 2) se despeja la predicción buscada con la ecuación 18. Por ejemplo, para un periodo de retorno de 100 años en Altamira se obtiene una precipitación máxima diaria de:
(Cuadro 2) se despeja la predicción buscada con la ecuación 18. Por ejemplo, para un periodo de retorno de 100 años en Altamira se obtiene una precipitación máxima diaria de:
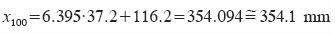
En el Cuadro 3 se concentran las predicciones estimadas con el procedimiento expuesto.
Análisis de resultados
En la mayoría de las estimaciones realizadas (Cuadro 3), el método regional de los valores estandarizados medianos, el cual corresponde básicamente a la aplicación del método de la avenida índice (Dalrymple, 1960; Cunnane, 1988; Campos, 1994) al análisis probabilístico regional de lluvias máximas diarias anuales, es el que conduce a las predicciones más elevadas o estimaciones de valores asociados a una determinada probabilidad de no excedencia. En cambio, el método de ajuste regional de la distribución GVE, reporta las predicciones más bajas en la mayoría de las estimaciones.
Conviene destacar que, en general, las predicciones mostradas en el Cuadro 3 tienen extraordinaria coincidencia en los bajos periodos de retorno (Tr < 50 años) y son bastante similares en los valores altos de éstos (Tr>100 años), cumpliéndose esto hasta el periodo de retorno de 10 000 años, lo cual origina una gran confianza en tales estimaciones. Finalmente, la comparación entre las predicciones de 10 000 años de Tr y las estimaciones estadísticas de la precipitación máxima probable (Campos, 1998) en la zona Huasteca son bastante coincidentes, lo cual ratifica la confiabilidad de las estimaciones del Cuadro 3.
Para realizar un contraste gráfico de los ajustes regionales de la distribución GVE, se muestran en el Cuadro 7, columnas 3 y 4, las magnitudes ordenadas de manera creciente de la precipitación máxima diaria anual observada y estandarizada con la media de cada serie histórica (xi) y, mediante la ecuación 18 (zi), en intervalos de 50 valores hasta el dato 1201 y después para los números de orden indicados. También en el Cuadro 7, columna 2, está la probabilidad de no excedencia evaluada según la ecuación 15. En la Figura 2 se muestra el ajuste de la distribución GVE según el método de las estaciones–años y en la Figura 3 de acuerdo al método de los momentos L regionales. Los valores de las predicciones que definen a ambas distribuciones GVE proceden del Cuadro 2. Se observa que ambos ajustes tienen un comportamiento similar y reproducen la tendencia probabilística de los datos hasta un número de orden de 1200. En los restantes 22 valores extremos empíricos ambos modelos probabilísticos tienen una tendencia mayor.



CONCLUSIONES
El coeficiente de variación es un parámetro estadístico usado para verificar homogeneidad regional y, al respecto, los de las series históricas procesadas (Cuadro 1) muestran una gran similitud, verificando la regionalización de la zona Huasteca.
La concordancia numérica (Cuadro 3) de todas las predicciones de los métodos regionales expuestos, incluso en los altos periodos de retorno (Tr> 100 años), destaca su confiabilidad ya que están basados en enfoques muy diferentes. Tal confiabilidad se ratifica con base en los contrastes gráficos (Figuras 1 y 2), que muestran un ajuste excelente a los datos empíricos.
Los métodos regionales desarrollados, el de los valores estandarizados medianos y el ajuste de la distribución GVE por momentos L regional, conducen en general, a las predicciones más altas o severas y a las más bajas, por lo cual se recomienda su aplicación con la idea de acotar resultados.
El establecimiento en la zona Huasteca de un criterio para estimar la precipitación máxima diaria anual promedio (b0), permitirá realizar predicciones en localidades sin información pluviométrica, al aplicar los resultados de los Cuadros 2 y 5, como se hizo para integrar el Cuadro 3. Tal criterio podrá ser gráfico (isoyetas) o analítico [b0=f(altitud)].
AGRADECIMIENTOS
Se agradece al editor y árbitro anónimos sus comentarios y observaciones, las cuales permitieron hacer más explícito este estudio. Al Profesor Juan Antonio Araiza Rodríguez (jaraiza@uaslp.mx) del Área de Cómputación Aplicada de la Facultad de Ingeniería de la UASLP, se agradece el haber proporcionado la información pluviométrica procesada.
LITERATURA CITADA
Benson, M. A. 1962. Plotting positions and economics of engineering planning. J. Hydraulics Division 88: 57–71. [ Links ]
Buishand, T. A. 1991. Extreme rainfall estimation by combining data from several sites. J. Hydrological Sci. 36: 345–365. [ Links ]
Campos A., D. F. 1994. Aplicación del método del índice de crecientes en la región hidrológica número 10, Sinaloa. Ing. Hidráulica Méx. IX: 41–55. [ Links ]
Campos A., D. F. 1998. Estimación estadística de la precipitación máxima probable en San Luis Potosí. Ing. Hidráulica Méx. XIII: 45–66. [ Links ]
Campos A., D. F. 2001. Contraste de cinco métodos de ajuste de la distribución GVE en 31 registros históricos de eventos máximos anuales. Ing. Hidráulica Méx. XVI: 77–92. [ Links ]
Campos A., D. F. 2006. Análisis previo de los datos hidrológicos. In: Análisis Probabilístico Univariado de Datos Hidrológicos. AMH–IMTA. Avances en Hidráulica 13. Jiutepec, Morelos. pp: 33–50. [ Links ]
Cunnane, C. 1988. Methods and merits of regional flood frequency analysis. J. Hydrology 100: 269–290. [ Links ]
Dalrymple, T. 1960. Flood–Frequency analysis. In: Manual of Hydrology (Part 3): Flood–Flow Techniques. U.S. Geological Survey, Water–Supply Paper 1543–A. USA. pp: 1–80. [ Links ]
Davis, P. J. 1972. Gamma function and related functions. In: Abramowitz, M., and I. A. Stegun (eds). Handbook of Mathematical Functions. Dover Publications, Inc. New York, USA. pp: 255–296. [ Links ]
Escalante S., C., y L. Reyes Ch. 2002. Análisis regional hidrológico. In: Técnicas Estadísticas en Hidrología. Facultad de Ingeniería de la UNAM. México, D. F. pp: 157–202. [ Links ]
IMTA (Instituto Mexicano de Tecnología del Agua). 2000. ERIC II: Extractor Rápido de Información Climatológica 1920–1998. 1 CD. Comisión Nacional del Agua–Secretaría de Medio Ambiente y Recursos Naturales–IMTA. Jiutepec, Morelos. [ Links ]
Kite, G. W. 1977. Comparison of frequency distributions. In: Frequency and Risk Analyses in Hydrology. Water Resources Publications. Fort Collins, Colorado, U.S.A. pp: 156–168. [ Links ]
Metcalfe, A. V. 1997. Extreme value and related distributions. In: Statistics in Civil Engineering. Arnold Publishers. London, England. pp: 81–115. [ Links ]
Santillán H., O. D. 2000. Criterio de homogeneidad hidrológica con parámetros fisiográficos y climatológicos. In: Memoria del 16° Congreso Nacional de Hidráulica. Morelia, Michoacán. pp: 761–766. [ Links ]
Stedinger, J. R., R. M. Vogel, and E. Foufoula–Georgiou. 1993. Frequency analysis of extreme events. In: Maidment, D. R. (ed.). Handbook of Hydrology, McGraw–Hill, Inc. New York, U.S.A. pp: 18.1–18.66. [ Links ]
Yevjevich, V. 1972. Parameters and order–statistics as descriptors of distributions. In: Probability and Statistics in Hydrology. Water Resources Publications, Fort Collins, CO., USA. pp: 99–117. [ Links ]

