











 text new page (beta)
text new page (beta) Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkIntroducción
Uno de los grandes retos del sector forestal con relación a su manejo para mitigar los impactos del cambio climático es la necesidad de conocer los almacenes de carbono de estos ecosistemas. En lo particular, la biomasa aérea de los bosques requiere del uso de ecuaciones alométricas (Brown, 1997), donde las variables diámetro a la altura del pecho (1.3 m) o diámetro normal (D), altura total de los árboles (H) y densidad de la madera (ρ) son utilizadas normalmente en forma individual o combinada (Brown, 1997; Chave et al., 2005; Vargas-Larreta et al., 2017). La selección del modelo alométrico es una de las principales fuentes de incertidumbre en la propagación de los errores de estimación de la biomasa aérea (B) (Pelletier, Kirby y Potvin, 2012; Picard, Boyemba y Rossi, 2015).
Para las estimaciones confiables de la biomasa aérea de especies de árboles en un determinado sitio es necesario el conocimiento de la ecuación alométrica de cada especie en el área de análisis. Esto conlleva a contar con un catálogo de ecuaciones (Jenkins, Chojncky, Heath y Birdsey, 2003; Henry et al., 2011; Rojas-García, de Jong, Martínez-Zurimendi y Paz-Pellat, 2015) para la selección adecuada. Evidentemente este esquema es costoso en tiempo y en recursos, además de que no garantiza que la ecuación seleccionada para una especie sea representativa de la población particular en análisis (p. ej. Méndez González, Turlan Medina, Ríos Saucedo y Nájera Luna, 2012), ya que los parámetros de los modelos alométricos son función del tipo de vegetación, clima, estructura de la población, arquitectura de las plantas, condición del sitio de muestreo, ontogenia, entre otros factores (Wutzler, Wirth y Schumacher, 2008; Genet et al., 2011; Chave et al., 2014; Paul et al., 2016; Forrester et al., 2017). El uso de un modelo alométrico en un sitio diferente al que fue desarrollado conlleva alta incertidumbre no cuantificada en las estimaciones (Jenkins et al., 2003; Temesgen, Affleck, Poudel, Gray y Sessions, 2015), por lo que se debe tener cuidado en la implementación a ciegas de este enfoque.
Una alternativa a la complejidad del problema que ha sido explorada es el desarrollo de modelos generalizados por tipo de ecosistema o de tipo pantropical (p. ej. Chave et al., 2005 y 2014) que consiste en la recopilación de datos medidos en campo y laboratorio de sitios alrededor del mundo, donde cada sitio consta de un conjunto de especies característico del ecosistema terrestre en evaluación. El modelo generalizado obtenido se espera que sea representativo del ecosistema y que genere estimaciones no sesgadas y precisas. Este enfoque ha sido seriamente cuestionado con relación al uso de modelos locales (a nivel de sitio), que generalmente realizan mejores estimaciones (Basuki, Vaan Laake, Skidmore y Hussin; 2009; Henry et al.; 2011; Van Breugel, Ransijn, Craven, Bongers y Hall, 2011; Álvarez et al.; 2012; Ngomanda et al.; 2014; Sato et al.; 2015; Manuri et al., 2016; Ploton et al., 2016). Lo ideal es el desarrollo de un modelo alométrico adaptativo que considere datos locales (D, H, ρ) para las estimaciones de la biomasa aérea (B) y que sea comparable al uso de ecuaciones alométricas locales con relación a la incertidumbre de estas.
Un problema asociado al desarrollo de modelos alo-métricos tipo Y = aX b , es el proceso de estimación de sus parámetros. La práctica común es transformar el espacio aritmético a uno logarítmico, Ln(Y) = Ln(a) + bLn(X), para estimar a y b usando regresión (ordinaria) lineal simple, minimizando el error cuadrático de estimación. La transformación inversa del espacio logarítmico al aritmético introduce sesgos que requieren ser corregidos (Zar, 1968). Al respecto, existen diferentes estimadores para corregir los sesgos fundamentados en diferentes hipótesis y modelos (Finney, 1941; Bradu y Mundlak, 1970; Baskerville, 1972; Beauchamp y Olson, 1973; Duan, 1983; Snowdon, 1991; El-Shaarawi y Viveros, 1997; Shen y Zhu, 2008). En el proceso de evaluación de los métodos de corrección de sesgos (Lee, 1982; Smith, 1993; Hui, Terblance, Chown y McGeoch, 2010; Zeng y Tang, 2011; Clifford, Cressie, England, Roxburgh y Paul, 2013) se han encontrado resultados mixtos dependientes del grado en que los datos representan las hipótesis utilizadas. En esta perspectiva, se ha argumentado que la mejor opción para evitar la incertidumbre de los métodos de corrección de sesgos es el uso de técnicas de regresión no lineal aplicada
Objetivos
En este trabajo se analizan los enfoques típicos de desarrollo de modelos alométricos clásicos, así como la corrección de sesgos más utilizada, con el objetivo de desarrollar un modelo a escala global (multiespecie y multisitio) que puede ser parametrizado empíricamente a escala local (sitio y multiespecie), aproximando el ideal del uso de alo-metría en bosques tropicales.
Materiales y métodos
Modelos alométricos utilizados
Para posicionar el problema de estimación usando modelos alométricos de la biomasa aérea, esta puede ser puesta como B = ρV (Cannell, 1984), donde V es el volumen que puede ser aproximado por el volumen de un fuste cilíndrico, V = (π/4) (D2H), con un factor de corrección para otras geometrías, además de la consideración del volumen de las ramas y hojas de la corona del árbol usando un factor de expansión de la biomasa. Este enfoque geométrico plantea una ecuación del tipo B =a c(ρD2H), donde a c es un factor de corrección general (forma del fuste y volumen de la corona y sus componentes). La densidad de la madera se considera como representativa de todas las componentes estructurales de los árboles. En la perspectiva discutida, los modelos alométricos considerados son:
donde a y b representan constantes del ajuste estadístico.
Usando el modelo M2 como referencia, comparándolo con el modelo M1 y M3, se obtiene:
En términos algebraicos, el modelo M1 y M2 son equivalentes entre sí por la relación (4) de sus parámetros. En el caso del modelo M3, la equivalencia entre parámetros está dada por la relación (5), para el caso de bvd = bv =1.
Estimación de los parámetros de los modelos alométricos
La ecuación alométrica dada por:
puede transformarse logarítmicamente como:
para estimar los parámetros a y b por regresión lineal simple, donde ε es el error de estimación [Y’medido - Y’estimado].
Aunque hay diferentes estimadores del factor de corrección de la transformación inversa del espacio logarítmico al aritmético, el estimador simple o ES (“naive estimator”, Duan, 1983) de Baskerville (1972) es el más utilizado:
donde FCES = Exp(σ/2) es el factor de corrección del estimador simple y σ es la desviación estándar (error estándar residual o EER) del error ε, el cual es supuesto como distribuido normalmente con media cero y desviación estándar σ, definida como:
Donde
Otro estimador utilizado (e.g. Búrquez y Martínez-Yrízar, 2011) es el estimador de razón (ER) de Snowdon (1991):
donde FCER = Promedio (Bmed)/Promedio (Best), donde Best es obtenida de la aplicación del modelo alométrico en el espacio logarítmico, sin realizar ninguna corrección, y el término est se refiere a estimada y med a medida.
El ajuste de los modelos alométricos se analizó a través del uso de diferentes métricas de incertidumbre, incluyendo el coeficiente de determinación (R2), como la raíz del error cuadrático medio (RECM):
y el error relativo medio (ERM) y error absoluto medio (EAM), ambos en porcentaje:
Los resultados del proceso de estimación pueden ser analizados con relación entre lo medido (med) y lo estimado (est):
donde para una estimación perfecta se espera que q y s sean igual a 0.0 y los parámetros r y s igual a 1.0.
La estimación de los parámetros de los modelos alo-métricos generalmente se obtiene por un proceso de regresión lineal simple al minimizar el error cuadrático de estimación (ε2), lo cual implica una simetría (término cuadrático) que no necesariamente es la mejor opción de estimación. Una alternativa de estimación es minimizar el error absoluto de estimación (|ε|) (Journel, 1984).
Base de datos de alometría pantropical analizada
Para tener un base de datos representativa de los bosques tropicales en el mundo, se analizó la publicada por Chave et al. (2014), disponible públicamente, la cual consiste en 4004 mediciones de D (cm), H (m) y ρ (g cm-3) en 58 sitios en diferentes partes del mundo, donde 53 sitios son de vegetación no perturbada. La densidad de la madera de la base de datos fue medida o estimada; en un 58% de los datos se midió y en el resto fue estimada por el valor promedio de la especie, género o familia usando una base de datos global (Chave et al., 2009; Zanne et al., 2009). La documentación de los sitios y de la base de datos se encuentra en Chave et al. (2014), por lo que solo se presenta una descripción mínima en este trabajo. Adicionalmente, Burt et al. (2020) analizaron la base de datos con relación a errores, y discuten sus implicaciones y limitaciones.
Las unidades de las variables de la base de datos son las mismas que las usadas en todos los análisis presentados en este trabajo, por lo que no serán incluidas en lo siguiente.
En la tabla 1 se muestran los sitios incluidos en la base de datos, además del número de datos y el valor máximo de D en cada sitio.
Tabla 1 Sitios y características generales incluidos en la base de datos.
| Sitio | n | D máx. (cm) | Sitio | n | D máx. (cm) | Sitio | n | D máx. (cm) |
| Australia | 46 | 24.9 | Kaliman1 | 23 | 77.6 | PuertoRi | 30 | 45.7 |
| BraMan2 | 123 | 38.2 | Kaliman2 | 69 | 130.5 | PuertoRi2 | 25 | 45.0 |
| BraPara1 | 127 | 138.0 | Kaliman4 | 40 | 68.9 | SaoPaulo3 | 75 | 67.8 |
| BraPara3 | 21 | 55.0 | Kaliman6 | 25 | 84.4 | Sarawak | 21 | 44.1 |
| BraRond | 8 | 89.0 | Karnataka | 189 | 60.9 | SouthAfrica | 469 | 79.3 |
| Cambodia | 34 | 133.2 | Llanosec | 24 | 23.3 | SouthBrazil1 | 150 | 95.0 |
| Cameroon | 5 | 79.4 | Llanosol | 27 | 156.0 | SouthBrazil1 | 50 | 124.8 |
| Cameroon3 | 59 | 212.0 | Madagascar1 | 76 | 54.0 | SouthBrazil3 | 64 | 34.5 |
| CentralAfric | 12 | 52.2 | Madagascar2 | 90 | 35.0 | Sumatra | 29 | 48.1 |
| ColombiaC1 | 60 | 126.7 | Madagascar3 | 87 | 31.8 | Sumatra2 | 11 | 114.6 |
| ColombiaG1 | 36 | 70.9 | Madagascar4 | 80 | 37.0 | Tanzania1 | 38 | 78.0 |
| ColombiaG2 | 10 | 12.5 | Madagascar5 | 90 | 36.0 | Tanzania2 | 42 | 110.0 |
| ColombiaM1 | 24 | 111.9 | Malaysia | 139 | 101.6 | Tanzania3 | 38 | 79.0 |
| ColombiaM2 | 9 | 11.8 | Malaysia2 | 24 | 66.7 | Tanzania4 | 34 | 95.0 |
| CostaRic | 97 | 116.0 | MFrenchG | 29 | 42.0 | Venezuela2 | 40 | 136.8 |
| FrenchGu | 360 | 117.8 | MGuadel | 55 | 40.7 | WestJava | 41 | 31.8 |
| Gabon | 103 | 109.4 | Moluccas | 25 | 41.7 | Yucatan | 175 | 63.4 |
| Ghana | 37 | 180.0 | Mozambique | 28 | 72.0 | Zambia | 141 | 37.4 |
| IndiaCha | 23 | 34.7 | NewGuinea | 42 | 110.1 | |||
| Jalisco | 124 | 44.9 | Peru | 51 | 169.0 |
La figura 1 muestra la relación entre la biomasa B con relación a ρD2H, donde se muestra una gran dispersión, por lo que el uso de un modelo alométrico generalizado tendrá limitaciones en explicar la variabilidad observada.

Posicionamiento del problema
Para posicionar el problema planteado en este trabajo, la figura 2 muestra los modelos alométricos (M2) locales (58) ajustados por regresión no lineal a la base de datos, además del modelo global (curva punteada). En la figura se observa que el modelo global solo aproxima algunos modelos locales, por lo que en muchos casos se sobre o subestima con relación a los modelos alométricos de sitios particulares. La solución al modelo planteado de una solución general que sea aplicable a nivel local requiere redefinir el problema de estimación.

Resultados
Los ajustes por regresión estadística fueron realizados usando la función SolverMR de ExcelMR, minimizando el error cuadrático de estimación.
Modelos alométricos globales
Los resultados de los ajustes estadísticos están mostrados en la tabla 2 para el espacio logarítmico y la tabla 3 para el aritmético. En el modelo M3 de la relación (3), este representa el caso donde a v0 fue estimada por regresión lineal en el espacio logarítmico y el modelo 3b utiliza la relación (5) para el modelo M3, donde ρ representa valores específicos en cada sitio de la base datos y el valor a vd = 0.0524 fue estimado en el análisis realizado. El modelo M2a (Chave et al., 2014) fue estimado usando regresión lineal en el espacio logarítmico y el modelo M2b fue parametrizado por regresión no lineal directamente en el espacio aritmético y los parámetros mostrados son simples conversiones al espacio logarítmico (FC = 1.0). Para el espacio aritmético, la conversión utilizó FCES.
Tabla 2 Parámetros y estadísticos de los ajustes en el espacio logarítmico de modelos globales.
| Modelo | Parámetros | q | r | R 2 | ERM | EAM | RECM |
| M1 | Ln(a v)=-3.0626, b v=0.9535 | 0.1954 | 0.9590 | 0.9590 | -2.4131 | 10.1037 | 0.4294 |
| M3a | Ln(a v)=-3.4443, b v=1 | -0.0274 | 1.0057 | 0.9590 | -1.0066 | 10.0904 | 0.4412 |
| M3b | Ln(a v0) =Ln(0.0524ρ), b v=1 | 0.0210 | 0.9956 | 0.9716 | -0.7326 | 7.9350 | 0.3612 |
| M2a | Ln(a vd)=-2.7628, b vd=0.9759 | -0.1354 | 0.9716 | 0.9716 | -1.4706 | 8.0312 | 0.3575 |
| M2b | Ln(a vd)=Ln (0.0164), b vd=1.0906 | -0.8703 | 1.0858 | 0.9716 | 14.7458 | 15.9937 | 0.6333 |
Tabla 3 Parámetros y estadísticos de los ajustes en el espacio aritmético de modelos globales.
| Modelo | Parámetros | FC ES | s | t | R2 | ERM | EAM | RECM |
| M1 | av=Exp (-3.0626), bv=0.9535 | 1.0966 | 206.88 | 0.8278 | 0.8259 | -21.2015 | 41.0710 | 1634.8729 |
| M3a | av=Exp (-3.4443), bv=1 | 1.1023 | 185.30 | 1.0675 | 0.8246 | -22.3489 | 42.4035 | 1964.1605 |
| M3b | av0=0.0524ρ, bv=1 | 1.0674 | 153.50 | 0.9641 | 0.9116 | -13.9983 | 31.5284 | 1190.0537 |
| M2a | avd=Exp (-2.7628), bvd=0.9759 | 1.0660 | 168.60 | 0.8478 | 0.9091 | -13.7583 | 31.3052 | 1207.8154 |
| M2b | avd=0.0164, bvd=1.0906 | 27.82 | 0.9205 | 0.9161 | 30.7668 | 38.5995 | 1136.3307 |
En la figura 3 se muestran los resultados espacio logarítmico y aritmético de los modelos M2a (Chave et al., 2014) y el modelo M2b de la regresión no lineal. De la tabla 3, el modelo de regresión no lineal es el mejor modelo usando el criterio de la métrica RECM, la cual es la única relevante, dado que el proceso de regresión, lineal y no lineal busca minimizarla. Las otras métricas de error son estimadas como consecuencia del proceso de minimización del error cuadrático. De las tablas 2 y 3, tener un error menor en el espacio logarítmico no implica que al transformar el modelo al espacio aritmético este siga teniendo un error menor. El caso del modelo M2b (regresión no lineal) ejemplifica esta situación.
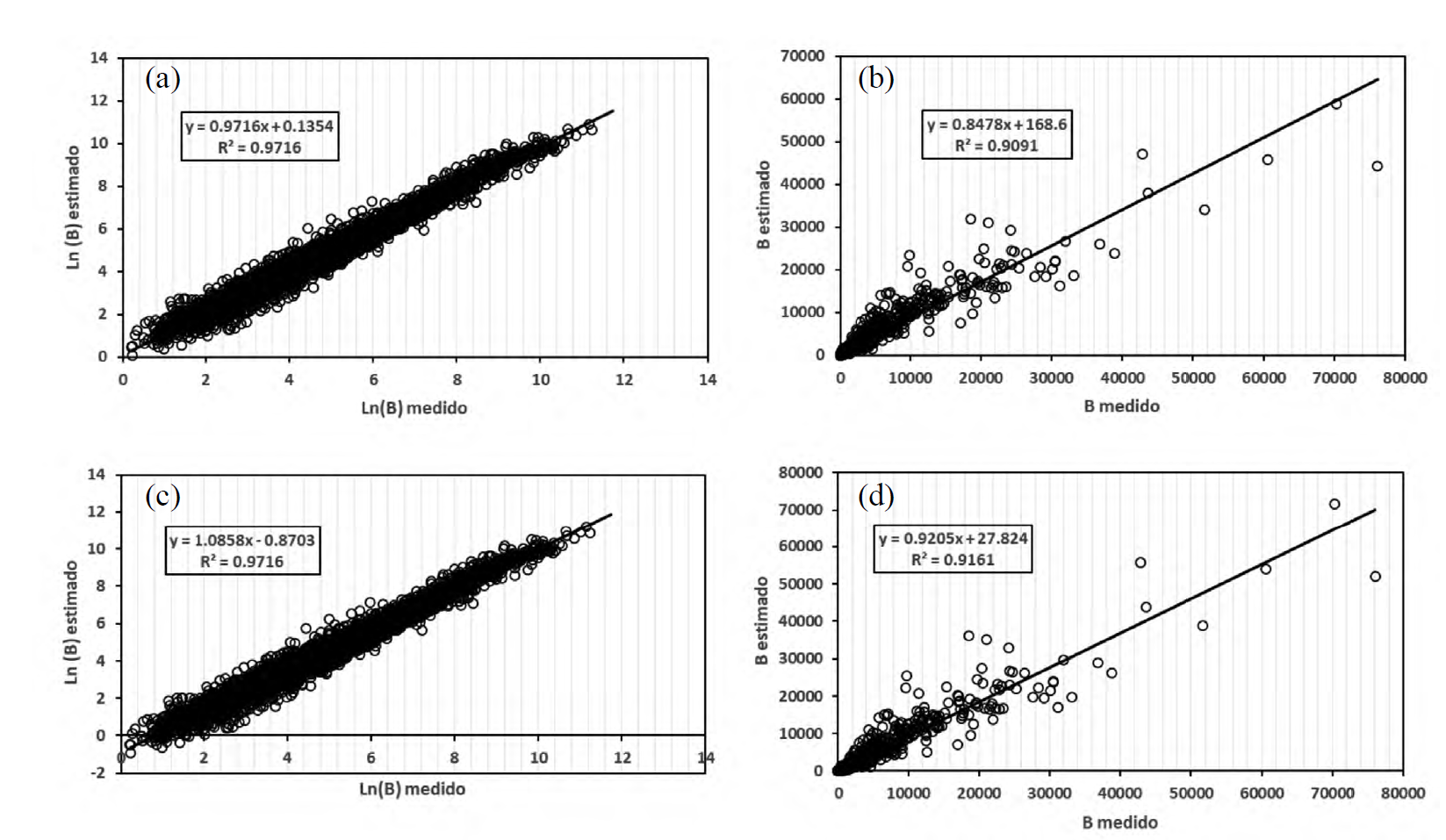
Figura 3 Resultados del proceso de estimación de modelos globales. (a) Modelo M2a en espacio logarítmico, (b) Modelo M2a en espacio aritmético, (c) Modelo M2b en espacio logarítmico y (d) Modelo M2b en espacio aritmético.
El modelo M1 (no inclusión de ρ) muestra resultados pobres con relación a los otros modelos analizados, mostrando que el no considerar la densidad de la madera produce resultados con errores mayores a los de su consideración, algo similar ocurre con el modelo M3a. Ahora bien, el caso del modelo M3b (inclusión de ρ a nivel de sitio) (Fig. 4) que utiliza la hipótesis de que b vd = 1, muestra estadísticos de errores menores que el caso del modelo de Chave et al. (2014) (Tabla 2 y 3), que además reduce la dimensionalidad del problema (modelo con un solo parámetro).

Modelos alométricos locales
Para el caso de los ajustes de modelos alométricos locales (en cada sitio), la tabla 4 (espacio logarítmico) y tabla 5 (espacio aritmético) muestran los resultados obtenidos, donde el mejor ajuste fue el modelo M2b (regresión no lineal) y después el modelo M2a de regresión lineal en el espacio logarítmico (Fig. 5). El modelo M3b, que considera la densidad de la madera a nivel local (sitio), mostró un comportamiento ligeramente no mejor que el caso global.
Tabla 4 Parámetros y estadísticos de los ajustes en el espacio logarítmico de modelos locales.
| Modelo | Parámetros | q | r | R 2 | ERM | EAM | RECM |
| M1 | Locales | 0.1250 | 0.9738 | 0.9738 | -1.9888 | 8.2688 | 0.3435 |
| M3a | Locales | 0.0306 | 0.9936 | 0.9708 | -1.3119 | 8.5545 | 0.3659 |
| M3b | Ln(a vo)=Ln(0.0524ρ), b v=1 | 0.0210 | 0.9956 | 0.9716 | -0.7326 | 7.9350 | 0.3612 |
| M2a | Locales | 0.0905 | 0.9810 | 0.9810 | -1.0681 | 6.5724 | 0.2923 |
| M2b | Locales | -0.0718 | 2.0136 | 0.9570 | 0.6735 | 9.8212 | 0.4564 |
Tabla 5 Parámetros y estadísticos de los ajustes en el espacio aritmético de los modelos locales.
| Modelo | Parámetros | FC ES | s | t | R2 | ERM | EAM | RECM |
| M1 | Locales | Locales | 176.77 | 0.8431 | 0.8501 | -13.8864 | 30.5121 | 1516.9626 |
| M3a | Locales | Locales | 159.03 | 0.9303 | 0.8317 | -16.1245 | 33.4404 | 1663.8007 |
| M3b | a vo=0.0524ρ, b v=1 | Locales | 165.04 | 0.9434 | 0.9062 | -14.144 | 31.5702 | 1213.4614 |
| M2a | Locales | Locales | 86.191 | 0.9200 | 0.9371 | -9.2284 | 24.2851 | 984.8277 |
| M2b | Locales | 48.444 | 0.9593 | 0.9595 | -10.5418 | 35.7043 | 788.0718 |

Figura 5 Resultados del proceso de estimación de modelos locales. (a) Modelo M2a en espacio logarítmico, (b) Modelo M2a en espacio aritmético, (c) Modelo M2b en espacio logarítmico y, (d) Modelo M2b en espacio aritmético.
En la figura 5 y de la tabla 4 se observa que el mejor modelo (M2b) muestra los peores resultados en el espacio logarítmico, por lo que es necesario considerar la inversión de los modelos del espacio logarítmico al aritmético, ya que estos están orientados a la minimización de errores en el formato logarítmico que, si no se usa un factor de corrección adecuado, pueden tener errores grandes de estimación en el espacio aritmético.
Minimización del error absoluto
Para el caso del modelo M3b se realizó un proceso de minimización del error absoluto (EAM), obteniéndose resultados en el espacio logarítmico con el menor sesgo (ERM y EAM), con resultados mejores de RECM a los de la minimización del error cuadrático. La figura 6 muestra los resultados obtenidos. El modelo fue parametrizado con el valor a v0 = 0.0595, cuyo valor será utilizado en lo siguiente.

Uso del factor de corrección FCER
El uso del factor de corrección FCER, relación (11), fue analizado para la conversión de los modelos locales ajustados en el espacio logarítmico al espacio aritmético, particularmente para el caso del modelo M3b que es de solo un parámetro e incorpora la densidad de la madera en forma explícita. La figura 7 muestra los resultados de la aplicación de FCER al modelo M3b, donde se observa una RECM menor al caso del resto de los modelos, con excepción del M2b de regresión lineal; aunque los valores del error de estimación (RECM) no están alejados del mínimo observado y las métricas ERM y EAM son mejores que el modelo de regresión no lineal.

Modelo empírico para parametrizar FCER
El factor de corrección FCER requiere del promedio de la biomasa medida, por lo que es necesario estimarla. Aunque la relación entre Best y Bmed está bien caracterizada (Fig. 8), los errores de estimación producen una relación inestable para la estimación de FCER. El promedio de la biomasa estimada se refiere a las estimaciones del modelo ajustado en el espacio logarítmico, modelo M3b, convertidas al espacio aritmético usando FC=1: Best=Exp[Ln(0.0595ρ)+Ln(D2H)].

Una alternativa realizada, como prueba de concepto, fue ajustar un modelo multivariado lineal de regresión estadística para estimar FCER, usando para esto datos medidos en campo en los inventarios forestales (D, H y ρ). El modelo multivariado lineal ajustado a los datos experimentales fue:
donde se usaron los operadores P (promedio), DE (desviación estándar) y CV (coeficiente de variación). La relación (17)es aplicable a nivel de sitio (local).
Los estadísticos del ajuste estadístico multivariado de la relación (17) son: R2 = 0.987, R2 ajustada = 0.985, R2 predicción = 0.978, error estándar = 0.024, d de DurbinWatson = 2.648, autocorrelación de primer orden =-0.356, colinealidad = 0.000, coeficiente de variación = 2.353.
La figura 9 muestra los resultados del modelo desarrollado usando la relación (17) para estimar FCER a nivel de sitio para el modelo 3b. Los resultados obtenidos son comparables al uso de FCER medido (Fig. 7).

Discusión
Los diferentes análisis realizados para los ajustes de modelos alométricos en el espacio logarítmico muestran que el objetivo de minimización del error de estimación es de doble paso, ya que también se requiere de la estimación de un factor de corrección. Esta situación está ejemplificada por el modelo de regresión no lineal, donde los resultados del proceso de estimación en el espacio logarítmico son los peores de todos los modelos analizados.
La aproximación clásica de regresión lineal, espacio logarítmico, que minimiza el error cuadrático de estimación (estimación del promedio) fue revisada para considerar otros objetivos, particularmente los sesgos de las estimaciones (error relativo medio y error absoluto medio) por un proceso de minimización del error absoluto. Los resultados mostraron una reducción de los sesgos de estimación con errores de estimación (RECM) comparable al proceso de mínimos cuadrados.
Intentos previos de reducir la dimensionalidad del problema de estimación usando modelo alométricos (Zianis y Mencuccini, 2004; Zianis, 2008; Zhang et al., 2016) han generado resultados mixtos y requerimientos de contar con información de campo normalmente no disponible en los inventarios forestales.
El cambio de factor de corrección simple (Baskerville, 1972) al factor de corrección de estimador de razones de Snowdon (1991), para el caso de estimaciones locales o a nivel de sitio usando el modelo B = 0.0595ρ(D2H), mejora sustancialmente las estimaciones, aproximándolas a las del modelo de regresión no lineal aplicado a nivel de sitio y con errores de estimación menores al caso de aplicar modelos tipo el usado por Chave et al. (2015) a nivel local, con el uso de factores de conversión clásicos (Baskerville, 1972).
Si se considera que el factor de corrección de Snowdon (1991) requiere de la biomasa medida a nivel de sitio, el desarrollo de un modelo estadístico lineal multivariado usando información disponible en campo, permitió hacer estimaciones comparables al caso de conocer la biomasa medida y con errores de estimación cercanos al modelo de regresión no lineal local que resultó en el mejor modelo.
Conclusiones
El ideal de desarrollar un modelo alométrico general que permita hacer estimaciones a nivel local, considerando los factores específicos de cada sitio, es uno de los grandes retos en el proceso de estimación de la biomasa aérea, evitando así discusiones sesgadas relacionadas sobre si un modelo global es adecuado para las escalas locales, respuesta que es negativa en la gran mayoría de los casos; exceptuando donde la alometría local es similar a la global en todos los casos con el uso de técnicas de regresión estadísticas iguales.
En este trabajo se desarrolló un modelo alométrico generalizado que reduce la dimensionalidad del problema de estimación a un solo parámetro en el espacio logarítmico, pero que requiere un parámetro adicional (factor de corrección) para convertirlo al espacio aritmético usado en las estimaciones de la biomasa aérea. Como prueba de concepto, se desarrolló un modelo estadístico lineal multivariado para estimar el factor de corrección con resultados comparables al caso de conocer la biomasa aérea en cada sitio, requisito para calcular el factor de corrección.
Los resultados obtenidos en este trabajo son altamente promisorios y requieren un análisis de estabilidad de resultados al variar (simulación Monte Carlo) la estructura de las bases de datos de cada sitio (diferentes combinaciones de número de datos y su selección aleatoria); aunque dada la variabilidad de estas estructuras de datos en los sitios de la base de datos pantropical usada permite inferir que la estabilidad es buena.

