











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
El fuego forma parte integral de los procesos asociados a la vegetación a nivel global (Flannigan, Krawchuk, de Groot, Wotton y Gowan, 2009); su presencia en los ecosistemas forestales es un componente fundamental y natural que ha contribuido a su formación (Chandler, Cheney, Thomas, Traubaud y Williams, 1983; Turner y Dale, 1998). Sin embargo, los incendios de la vegetación, especialmente aquellos generados por alguna influencia humana, son uno de los principales factores que causan disturbio y deterioro en los ecosistemas forestales, ya que modifican su estructura y la del paisaje (Dansereau y Bergeron, 1993; Lloret, Calvo, Pons y Díaz-Delgado, 2002), lo que resulta en cambios en procesos y funciones ecológicas (Turner, 1989), y cambios en las propiedades de la vegetación y del suelo (Driscoll, Arocena y Massicotte, 1999; Moody y Martin, 2009).
Los incendios forestales pueden representarse espacialmente con puntos que requieren un par de coordenadas para su localización, y pueden estudiarse a través del análisis de los patrones espaciales de puntos (Taylor, Woolford, Dean y Martell 2013). Un patrón espacial de puntos es una serie de puntos (p 1 , p 2 , p 3 ,..., p n ) distribuidos en una región específica (Gatrell, Bailey, Diggle y Rowlingson, 1996), que resulta de un proceso espacial, que es, a su vez, un mecanismo estocástico teórico que genera estos eventos o puntos (Diggle, 2003). La caracterización del tipo de patrón permite indagar sobre el proceso puntual que lo ha originado y puede hacerse, por una parte, con la densidad, que es una propiedad espacial de primer orden que mide la distribución de puntos usando el número de puntos por unidad de superficie, y, por otra parte, con las propiedades de segundo orden, que miden el tipo e intensidad de la interacción entre puntos (Ceyhan, Ertuğay y Düzgün, 2013). El proceso espacial más simple es la aleatoriedad espacial completa (CSR, Complete Spatial Randomness), con una intensidad λ dada. Para las propiedades de segundo orden se define si existe una desviación de los puntos observados con respecto a la distribución CSR para determinar si a una escala determinada, se detectan patrones agrupados o regulares, y es la distribución CSR la línea divisoria entre estos dos patrones espaciales (Diggle, 2003).
Una vez que se define si existe un patrón espacial (i.e. eventos de incendios) es posible explicarlo identificando las variables que influyen en la generación del patrón de puntos. En muchas ocasiones, los factores relacionados con la presencia de incendios forestales se estudian para definir el peligro o riesgo e incluyen las características topográficas (por ejemplo: altitud, pendiente, orientación de la pendiente), el clima (por ejemplo: precipitación, temperatura, humedad relativa) vegetación y uso del suelo, material combustible (Pew y Larsen, 2001; Romero-Ruiz, Etter, Sarmiento y Tansey, 2010) y factores antropogénicos, frecuentemente estimados indirectamente, como la accesibilidad a las áreas de vegetación, proximidad a caminos y asentamientos humanos (Romero-Calcerrada, Novillo, Millington y Gomez-Jimenez, 2008). Por otra parte, se puede considerar a los incendios como variable de respuesta binaria o categórica en modelos de regresión logística (Preisler, Brillinger, Burgan, y Benoit, 2004) o en modelos de evaluación multi-criterio (Muñoz-Robles, Treviño, G. Verástegui, Jiménez y Aguirre 2005; Setiawan, Mahmud, Mansor, Shariff y Nuruddin, 2004). Por otra parte, el estudio de los incendios forestales como una variable de respuesta continua mediante la conversión de puntos a una superficie espacial que representa su densidad, se ha abordado en menor proporción (Amatulli, João Rodrigues y Trombetti, 2006; Sebastián-López, Salvador-Civil, Gonzalo-Jiménez y SanMiguel-Ayanz, 2008). De esta manera, el estudio de la dinámica espacial de los incendios es fundamental para generar modelos que expliquen su ocurrencia en el paisaje y que faciliten la toma de decisiones relacionadas con los incendios (Andrews, Finney y Fischetti, 2007).
Objetivos
El objetivo de esta investigación fue estudiar las propiedades espaciales de primero y segundo orden de los puntos de calor en la Sierra Madre Oriental de San Luis Potosí (2000-2012). Específicamente, el estudio se enfocó en caracterizar los patrones espaciales de puntos e identificar los factores ambientales y de antropogénicos que influyen en la densidad de puntos. Para este último aspecto, se representó la ocurrencia de puntos de calor como una variable continua (i.e. número de puntos km-1), en contraste con la visión más común de considerarla como una variable binaria (i.e. presencia-ausencia de incendios). Esto permitió analizar los puntos de calor a nivel de paisaje y describir las condiciones bajo las cuales se presentan, en un gradiente continuo de ocurrencia (por ejemplo: ¿cuáles son las condiciones que deben prevalecer para que se presente una mayor o menor cantidad de puntos de calor?).
Materiales y Métodos
Área de estudio
El área de estudio se localiza entre los 21° 09’ 01” y los 22° 46’ 35” de latitud norte y los 98° 37’ 26” y los 99° 47’ 15” de longitud oeste. La región comprende un área de 8467 km2 que cubren total o parcialmente los municipios de Ciudad del Maíz, Rayón, Alaquines, Lagunillas, Cuidad Valles, El Naranjo, Tamasopo, Santa Catarina, Aquismón y Xilitla (Fig. 1). Estos municipios se encuentran dentro de una zona de alto riesgo de incendios, declarada en la Ley para la Prevención y Manejo Integral e Institucional de los Incendios Forestales para el Estado de San Luis Potosí (Poder Legislativo del Estado de San Luis Potosí, 2013).

Figura 1 Localización del área de estudio dentro del estado de San Luis Potosí. Se muestra la distribución y densidad de puntos en el periodo de estudio.
La región comprende las subprovincias fisiográficas Gran Sierra Plegada y Karst Huasteco que se encuentran dentro de la región Sierra Madre Oriental. El sustrato en su mayoría es de rocas calizas que ha propiciado topografía kárstica en un intervalo altitudinal entre los 37 m y los 2705 m snm. Los climas de la región son semicálidos subhúmedos (A)C, cálidos húmedos A, cálidos subhúmedos Aw y en menor proporción templados subúmedos C(w) de acuerdo con la clasificación climática de Köppen modificada por García (García, 1973). La precipitación total anual va de los 400 mm a los 3000 mm distribuidos en verano y en invierno, mientras que la temperatura media anual oscila entre los 12 °C y 24 °C. La presencia de estos climas y la topografía de la región favorecen comunidades vegetales arbóreas de selva baja, selva mediana, selva alta, bosque de pino, encino y mesófilo de montaña; también hay presencia de matorral submontano, chaparral, palmar, pastizal y áreas agrícolas (Rzedowski, 2006).
Métodos
El proceso metodológico para el estudio de las propiedades espaciales de los puntos de calor y las variables asociadas incluyó cinco pasos (Tabla 1) descritos en las siguientes secciones.
Tabla 1 Secuencia metodológica para el análisis espacial de los puntos de calor y variables asociadas.
| Paso 1 | Paso 2 | Paso 3 | Paso 4 | Paso 5 | |
| Método | Correlación de Pearson | Prueba de Chi cuadrada | Función K heterogénea | Densidad de kernel | Árboles de regresión |
| Objetivo del método | Explorar la relación entre número de incendios y puntos de calor. | Verificar supuestos de estacionariedad e isotropía de los puntos de calor. | Caracterizar los patrones espaciales de los puntos de calor. | Representar los puntos de calor como variable continua. | Identificar las variables que influyen en la densidad de puntos de calor. |
Bases de datos de puntos de calor
Se utilizaron los puntos de calor mensuales en formato shapefile publicados por la Comisión Nacional para el Uso y Conocimiento de la Biodiversidad [Conabio] (1998a) del periodo 2000-2012 y de los meses de marzo, abril, mayo y junio, que corresponden a la temporada de incendios de la región. La longitud del periodo histórico de registro de datos de puntos de calor era mayor al de la base de datos disponible de incendios registrados en el terreno en San Luis Potosí, por lo que se capturó una mayor variabilidad espacio-temporal para el análisis de los patrones espaciales. Los datos de puntos de calor tienen la ventaja de ser obtenidos diariamente, estar disponibles de manera gratuita y contar con referencia geográfica y son una fuente de datos muy útil para efectuar trabajos regionales (Hantson, Padilla, Corti y Chuvieco, 2013). Estos datos son obtenidos de los sensores AVHRR y MODIS de los satélites NOAA y Terra; los detalles acerca de los algoritmos empleados para la detección de los puntos de calor se encuentran en Galindo, López-Pérez y Evangelista-Salazar (2003) y en Giglio, Descloitres, Justice y Kaufman (2003). Dado que se utilizaron los puntos de calor para representar de manera indirecta los incendios forestales, un factor importante a conocer era si se encuentran relacionados entre sí, y con esto fortalecer el uso de puntos de calor como una variable proxy de los incendios. Para esto, se realizó un análisis de correlación de Pearson entre el número de incendios publicados por la Comisión Nacional Forestal [Conafor] (2016) y el número de puntos de calor registrados para el estado de San Luis Potosí en el periodo 2000-2012. Este análisis no consideró la localización geográfica de los incendios publicados, ya que no se contó con datos geo-referenciados para la totalidad del periodo de estudio.
Caracterización de los patrones de puntos de calor
La función K de Ripley es una de las técnicas más útiles para describir patrones de puntos (i.e. propiedades espaciales de segundo orden) a diferentes escalas. Uno de los supuestos de esta función es que el patrón de puntos es homogéneo y que posee una intensidad (número promedio de puntos por unidad de área) constante λ en el espacio, es decir, es estacionario e isotrópico (Hering, Bell y Genton, 2008). Si el patrón de puntos no cumple con estos supuestos, entonces se utiliza una variante de la función K para patrones de intensidad heterogénea. Para comprobar esto con los puntos de calor, se realizó una prueba de Chi cuadrada de independencia para determinar si la intensidad de puntos en un área difería significativamente de la intensidad de puntos en otras áreas. Para esto, se dividió el área de estudio en ocho regiones donde se contaron los puntos para cada mes, y esta cantidad de puntos se comparó con el número de eventos esperados bajo el supuesto de homogeneidad para cada región (Diggle, 2003). Con esta prueba se determinó que los puntos de calor observados no cumplían con estacionariedad e isotropía, ya que todas las pruebas de Chi cuadrada con un 99% de probabilidad arrojaron valores mayores que el esperado
La estimación de la función K genera una serie de círculos concéntricos que van incrementando su distancia de manera constante en cada punto; estos círculos permiten tener una perspectiva para observar un área de estudio en diferentes escalas. La función cuantifica el número de puntos localizados dentro de cada circunferencia, y obtiene su promedio acumulado, y el radio de cada círculo concéntrico se representa en el eje horizontal de una gráfica (Gatrell et al., 1996). Para facilitar su interpretación visual y estabilizar la varianza, K(r) se transforma con la raíz cuadrada, que resulta en la función L(r), donde la función K se representa con una línea recta y CSR es igual a cero. La variante para intensidades heterogénea de la K de Ripley´s [Kinhom(r)] se transformó con la raíz cuadrada [Linhom(r)]:
Donde:
|
= Valor de la función L para distribuciones heterogéneas; |
λ |
= intensidad (número de puntos por unidad de área); |
área (W) |
= superficie del área de estudio; |
λ |
= estimado de la función de intensidad; |
|
= corrección por efecto de borde |
La estimación de las funciones Linhom(r) mensuales se realizaron con el paquete spatstat (Baddeley, Rubak y Turner, 2015) incluido en el programa R versión 3.3.0 (R Development Core Team, 2015). Se utilizó la corrección de borde “translate” dada la geometría irregular del área de estudio. El valor de λ fue definido mediante la función “Kinhom” incluyendo el argumento “leave-one-out” sugerido por Baddeley et al. (2015). Para comprobar la hipótesis nula de aleatoriedad CSR, se estimaron límites críticos a 95% de significancia con 999 simulaciones Monte Carlo. Un patrón agregado se definió cuando el patrón observado Linhom(r) estuvo fuera del límite crítico superior (significativamente mayor que cero), los valores fuera del límite crítico inferior (significativamente menor que cero) definieron patrones regulares y los valores dentro de los límites críticos indicaron patrones aleatorios (Ripley, 1979).
Densidad de puntos de calor y selección de variables explicativas
Los puntos de calor fueron transformados a un continuo espacial mediante la función de densidad de kernel, que produce un mapa regionalizado de una función acumulada (i.e. densidad; propiedad espacial de primer orden). Una de las ventajas de tratar a los incendios como una variable de respuesta continua es que disminuye los posibles errores de localización de los puntos (Amatulli et al., 2006). Los mapas de densidad de puntos de calor mensuales se generaron usando la función “kernel2d” de la librería “splancs” del programa R versión 3.3.0. Un parámetro importante a definir para la estimación de la función kernel es el ancho de banda, que depende en gran medida del propósito para el cual se usa la estimación de la densidad, por lo que su definición puede ser difícil y ambigua, además de que existen diversos métodos para su estimación (Koutsias, Kalabokidis y Allgöwer, 2004; Silverman, 1986). Anchos de banda pequeños dan más peso a las observaciones más cercanas, mientras que valores altos favorecen a localizaciones más distantes que generan superficies más suavizadas (Seaman y Powell, 1996).
Para el presente estudio, el ancho de banda se definió considerando dos criterios; por una parte, la minimización del error medio cuadrático y, por la otra, la escala de trabajo y el nivel de detalle de las variables independientes seleccionadas para explicar la densidad de puntos de calor. Para el primer criterio, se calculó el valor mínimo del error medio cuadrático que se considera como el ancho de banda óptimo (Rowlingson y Diggle, 1993) con la función “mse2d”, que indicó anchos de banda ≈ 6500 m para cada mes. Sin embargo, se consideró que un valor de ancho de banda mayor representaría mejor las condiciones a nivel de paisaje, y su nivel de detalle sería más compatible con la escala de variables independientes como la temperatura y precipitación (Tabla 2).
Tabla 2 Variables seleccionadas para explicar la densidad de incendios forestales usando árboles de regresión.
| Variable/tipo | Unidades | Descripción y Fuente |
| Variable de respuesta | ||
| Puntos de Calor | ||
| Densidad de puntos de calor (variable de respuesta/continua) | Puntos de calor 110 km-1 | Mapa de celdas derivado de mapas de puntos de calor. Conabio. |
| Variables explicativas | ||
| Factores Ambientales | ||
| Precipitación pluvial mensual/continua | mm | Mapas mensuales obtenidos de TRMM, producto 3B43. NASA. |
| Temperatura máxima mensual/continua | °C | Mapas mensuales de temperatura diurna de la superficie, obtenidos por el sensor MODIS, producto MOD11A2. NASA. |
| Altitud sobre el nivel del mar/continua | msnm | Modelo Digital de Elevaciones. SRTM. |
| Pendiente/continua | % | Derivado del Modelo Digital de Elevaciones. SRTM. |
| Exposición de laderas/categórica | N, NE, E, SE, S, SW, W, NW | Derivado del Modelo Digital de Elevaciones. SRTM. |
| Tipo de vegetación/categórica | Comunidades vegetales | Tipos de vegetación: BP=Bosque de pino; BQ=Bosque de encino; BPQ=Bosque de pino-encino; BQP=Bosque de encino-pino; BMM=Bosque mesófilo de montaña; SA=Selva alta; SB=Selva baja; SM=Selva mediana; PAL=Palmar; MAT=Matorral submontano; CH=Chaparral; PAC=Pastizal cultivado; PAI=Pastizal inducido; AGR=Agricultura. Inventario Nacional Forestal 2000. I. de Geografía UNAM. |
| Factores Antropogénicos | ||
| Distancia a caminos pavimentados/continua | m | Distancia euclidiana calculada en el Conjunto de Datos Vectoriales de Carreteras y Vialidades Urbanas Edición 1.0. Inegi. |
| Distancia a caminos de terracería /continua | m | Distancia euclidiana calculada en el Conjunto de Datos Vectoriales de Carreteras y Vialidades Urbanas Edición 1.0. Inegi. |
| Distancia a asentamientos humanos/continua | m | Distancia euclidiana a partir del mapa de asentamientos humanos (localidades rurales y áreas urbanas). Inegi. |
| Distancia a áreas agrícolas/continua | m | Distancia euclidiana a áreas de agricultura vecinas a zonas con vegetación natural contenidas en el Inventario Nacional Forestal 2000. I. de Geografía de la UNAM |
| Tenencia de la tierra/categórica | Ejidal/ comunitario/ privado | Polígonos del Catálogo de Núcleos Agrarios. Ciudad de México. México. RAN. |
Por estas razones, se decidió aplicar un ancho de banda de 10 000 m, con el que se cumplía con la compatibilidad de escalas sin comprometer el detalle requerido para el nivel de paisaje. Los mapas de densidad de puntos fueron exportados al programa ArcMap versión 10.1 y reescalados para ser registrados como número de puntos de calor 110 km-1 para evitar el truncado de valores decimales durante el análisis. Para explicar la densidad de puntos de calor, se seleccionaron variables que se agruparon en ambientales y antropogénicas y estaban disponibles como capas de información geográfica (Tabla 2). Las variables tuvieron distintas resoluciones espaciales nominales y fueron re-muestreadas a una resolución espacial de 90 m y referidas a la Proyección Cónica Conforme de Lambert.
Identificación de variables de influencia y umbrales
Se generaron árboles de regresión mensuales para determinar los umbrales necesarios de cada variable para explicar la densidad de puntos de calor. Los datos usados para construir los árboles de regresión se obtuvieron con un muestreo de 1024 puntos independientes de los puntos de calor, distribuidos aleatoriamente dentro del área de estudio. Este tamaño de muestra aseguró la representatividad estadística con un margen de error aceptable de 5% y un nivel de confianza de 95%. Para cada punto de muestreo, se extrajo la información de los mapas de la variable de respuesta y de cada variable explicativa en ArcMap versión 10.
Se utilizó el método CART (Classification and Regression Trees) implementado en el programa SPSS 22.0 versión de prueba. Este método no-paramétrico divide de manera recursiva un espacio multi-dimensional definido por variables explicativas tanto continuas como categóricas en subgrupos tan homogéneos como sea posible utilizando algoritmos para minimizar la varianza (Steinberg y Colla, 1995). Los datos de la variable de respuesta son divididos en una serie de nodos internos descendientes hacia la izquierda y hacia la derecha que se derivan de nodos parentales, y una vez que la división finaliza, se generan nodos terminales (Breiman, Friedman, Olshen y Stone, 1984). Inicialmente se construyeron árboles completos de hasta ocho niveles, y más de 80 nodos.
Siguiendo el principio de parsimonia y para evitar un sobre-ajuste, los árboles se podaron utilizando un error estándar de uno en la máxima diferencia en el riesgo. Con esto, se obtuvieron árboles más simples y descriptivos, capaces de representar la estructura sistemática de la relación entre densidad de puntos de calor y las variables de influencia. La muestra se dividió en dos bases de datos, una para la fase de entrenamiento (70%) y la otra para su validación (30%). Para determinar la robustez de los árboles se calcularon los errores medios cuadráticos (RMSE) y los coeficientes de determinación (R2 = 1-riesgo/varianza; siendo el riesgo el error esperado). Se calculó la importancia relativa de cada variable en cada árbol de regresión para detectar la contribución de cada variable a la mejora del modelo en los nodos con más varianza. Estas mejoras se sumaron a través de cada nodo y se estandarizaron con relación a la mejor variable explicativa, a la que se le asignó el valor de 100, y a partir de esta las demás variables explicativas tuvieron valores más bajos hasta llegar a cero (Steinberg y Colla, 1995).
Resultados
Ocurrencia de incendios forestales y puntos de calor
Se confirmó una relación significativa y positiva entre el número de puntos de calor ocurridos en vegetación forestal y la cantidad de incendios publicados por la Conafor para el periodo 2000-2012 en el estado de San Luis Potosí (P < 0.05; R = 0.88; Fig. 2a). Se detectó que en general, el número de puntos de calor sobreestima el número de incendios publicados por Conafor por alrededor de 67 eventos por año. Durante el periodo de estudio, se registraron 228 puntos de calor en marzo, 560 en abril, 838 en mayo y 240 en junio, dando un total de 1866 puntos de calor, en contraparte con los 990 incendios señalados por la Conafor.

Figura 2 Características generales de los puntos de calor en el estado de San Luis Potosí (2000-2012). (a) Relación entre el número total de incendios y el número total de puntos de calor y (b) ocurrencia mensual promedio de puntos de calor en relación con la precipitación total promedio (línea continua) y la temperatura media máxima (línea punteada).
Patrones espaciales y temporales de puntos de calor
La naturaleza multi-escala de la función L heterogénea permitió detectar las distancias a las cuales los puntos de calor exhiben patrones de distribución significativos. Para el mes de abril, los puntos se agruparon hasta distancias de 16 km y mostraron regularidad a distancias mayores a 18 km (Fig. 3). Los puntos de calor del mes de mayo mostraron un patrón agrupado a distancias menores a 15 km y un patrón regular a distancias mayores a 17 km. En contraste, los puntos de calor en junio mostraron agrupación a distancias menores a 6 km y regularidad a partir de los 9 km. La mayor intensidad en la agrupación de puntos (e.g. valores altos de la función L inhom ) ocurrió en los meses de marzo, abril y junio, principalmente en distancias menores a 5 km. El patrón más claro de regularidad en la distribución de puntos de calor ocurrió en el mes de junio, a partir de los 10 km de distancia. La amplitud de los límites críticos fue mayor en marzo y junio, indicando una mayor variabilidad en la intensidad estimada, así como un menor número de puntos de calor ocurridos en estos meses.

Figura 3 Función L heterogénea. Los valores positivos del patrón observado (línea continua) por encima de los límites críticos (líneas punteadas) indican un patrón agrupado, mientras que valores negativos por debajo de los límites críticos denotan un patrón regular. Valores dentro de los límites críticos indican un patrón aleatorio. Los puntos de calor y las superficies de densidad mensuales se muestran en el recuadro inferior izquierdo. La línea discontinua representa el valor teórico de la aleatoriedad espacial completa (CSR).
La distribución espacial de los puntos de calor varió temporalmente; en el mes de marzo se registraron principalmente en la parte norte del área de estudio; para el mes de abril, el número de puntos de calor aumentó y se mantuvo una distribución similar a la del mes de marzo. Sin embargo, en los meses de mayo y junio, los puntos ocurrieron en mayor concentración en la parte sur del área de estudio.
Variables relacionadas con la densidad de los puntos de calor
Las superficies de densidad de puntos de calor usadas como variable de respuesta en los árboles de regresión se muestran en la figura 3. El árbol de regresión del mes de marzo tuvo 19 nodos que clasificaron la densidad de puntos en 10 categorías (R2 entrenamiento = 0.51; R2 validación = 0.47; RMSE = 0.03). El primer criterio de partición fue la precipitación pluvial (Fig. 4); aquellas áreas con precipitación > 18.76 mm, temperatura diurna de ≤ 28.39 °C y distancia a zonas agrícolas mayor a 1 772.77 m presentaron densidades altas de puntos.

Figura 4 Árbol de regresión del mes de marzo. Se indica la proporción (%) de puntos de muestreo usados para la fase de entrenamiento. El valor estimado indica la densidad de puntos de calor predicha por el árbol de regresión. Los nodos terminales se muestran en color gris.
El árbol de regresión de abril tuvo 21 nodos que clasificaron la densidad de puntos en 11 categorías (R2 entrenamiento = 0.58; R2 validación = 0.34; RMSE = 0.26). El primer criterio de partición fue la temperatura diurna (Fig. 5). Existieron dos nodos terminales en los que se clasificaron las densidades de puntos más altas. El primero, incluyó áreas con temperatura ≤ a 29.23 °C y distancia a asentamientos humanos > 2719.63 m, y el segundo con distancias a asentamientos humanos > 1622.00 m y altitud ≤ 1059.18 m.
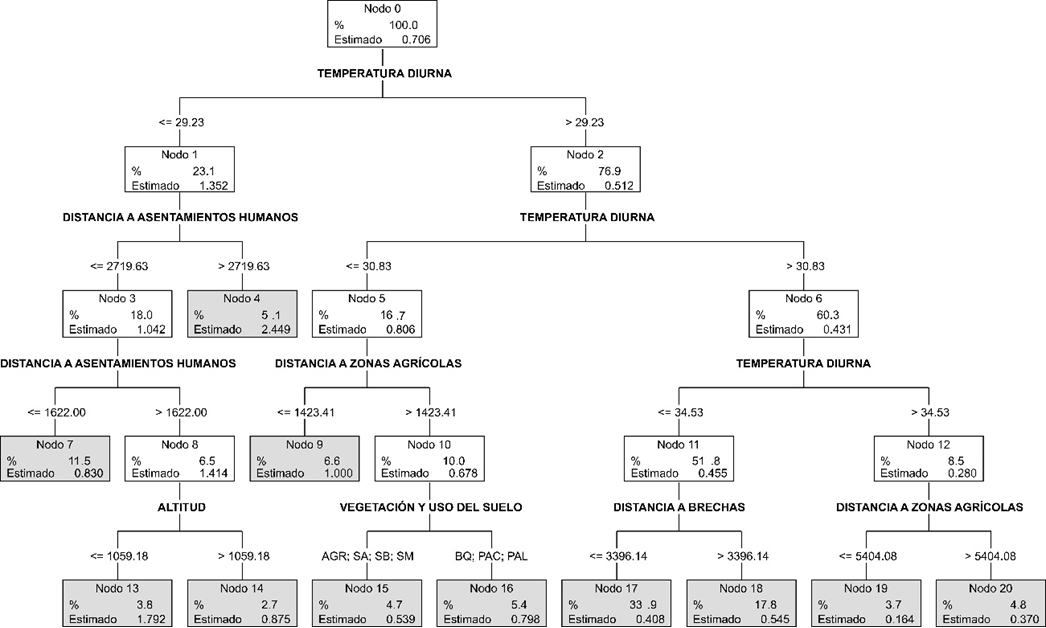
Figura 5 Árbol de regresión del mes de abril. Se indica la proporción (%) de puntos de muestreo usados para la fase de entrenamiento. El valor estimado indica la densidad de puntos de calor predicha por el árbol de regresión. Los nodos terminales se muestran en color gris.
En mayo se presentaron los valores de densidad de puntos de calor más altos con respecto a los otros tres meses (Fig. 6), y fueron clasificados en 12 categorías con un árbol de regresión de 23 nodos (R2 entrenamiento = 0.58; R2 validación = 0.38; RMSE = 0.36). Dos grupos de condiciones determinaron densidades de puntos altas. El primero, en áreas con precipitación entre 57.49 mm y 70.74 mm, y con una distancia a brechas > 6227.05 m, y el segundo en áreas con distancia a brechas ≤ 6,227.05 m, precipitación entre 69.23 mm y 70.74 mm con bosque de pino, selva mediana y pastizal cultivado.

Figura 6 Árbol de regresión del mes de mayo. Se indica la proporción (%) de puntos de muestreo usados para la fase de entrenamiento. El valor estimado indica la densidad de puntos de calor predicha por el árbol de regresión. Los nodos terminales se muestran en color gris.
El árbol de regresión para junio tuvo 17 nodos que clasificaron la densidad de puntos de calor en nueve categorías (R2 entrenamiento = 0.42; R2 validación = 0.33; RMSE = 0.05). El primer criterio de partición fue la vegetación y uso del suelo (Fig. 7). Las áreas con selva alta, selva mediana, matorral, chaparral y bosque de pino con precipitación ≤ 212.60 mm y distancia a brechas > 5720 m se clasificaron como áreas con densidad de puntos alta.

Figura 7 Árbol de regresión del mes de junio. Se indica la proporción (%) de puntos de muestreo usados para la fase de entrenamiento. El valor estimado indica la densidad de puntos de calor predicha por el árbol de regresión. Los nodos terminales se muestran en color gris.
En general, 70% de los puntos de muestreo se ubicó en áreas con densidades de incendios bajas, mientras que 30% de los puntos de muestreo tuvieron densidades de incendios altas. La importancia relativa de cada variable explicativa varió temporalmente (Fig. 8). Las variables que más contribuyeron de manera frecuente a la mejora de los árboles en los nodos con mayor varianza fueron precipitación, temperatura diurna, vegetación y uso del suelo, altitud, distancia a asentamientos humanos y distancia a terracerías. Las variables que menor contribución tuvieron en los árboles de regresión fueron tenencia de la tierra, pendiente, orientación de la pendiente y distancia a zonas agrícolas.

Discusión
Relación entre puntos de calor e incendios forestales
El análisis de correlación demuestra que el número de incendios forestales se relaciona con el número de puntos de calor, lo que da pauta a utilizar a éstos para estudiar aspectos importantes de la distribución de los incendios cuando no se cuenta con bases de datos geo-referenciados con series completas o de suficiente longitud histórica para capturar la variabilidad espacial y temporal de los incendios. Así, los puntos de calor son una fuente aceptable para dar seguimiento a la actividad de incendios forestales, pero es necesario considerar que por las características de los sensores utilizados para detectarlos (i.e. baja resolución espacial), los errores de omisión de incendios pequeños suelen ser altos, aunque se ha demostrado que estos errores son menores en áreas arboladas, como en la mayor parte de nuestra área de estudio (entre 36 y 86%; Hantson et al., 2013).
Distribución espacial y temporal de puntos de calor
El estudio de los patrones espaciales de incendios forestales es esencial para entender el efecto de la interacción de variables que influyen en su distribución y poder generar hipótesis sobre los procesos subyacentes que los originan. Los patrones de puntos son el resultado de la interacción de diferentes factores y procesos que se manifiestan en distintas escalas (Wiegand y Moloney, 2004) y están relacionados con la heterogeneidad ambiental (Condit et al., 2000).
En el presente estudio se encontraron los tres patrones teóricos de distribución espacial: agrupado, aleatorio y regular y, de manera similar a los estudios realizados por Parente et al. (2016) y Vadrevu et al. (2008), se encontró que los patrones de agrupación en los incendios forestales decrecen conforme la distancia de análisis aumenta. De esta manera, se ha demostrado que los patrones agrupados son una característica común y propia de los incendios forestales, aunque no necesariamente indican una fuerte dependencia entre puntos, sino que el nivel de agrupación espacial de las variables que influyen en los incendios puede también explicar los patrones agrupados de los incendios (Yang et al., 2007). Esto también concuerda con los resultados encontrados respecto a las variables de influencia discutidas en la siguiente sección. Los patrones agrupados indican que las características del territorio son heterogéneas, debido a que las variables explicativas se conjuntan solo en ciertas porciones del territorio (Podur, Martell y Csillag, 2003), aumentando la probabilidad de ocurrencia de puntos vecinos con distancias cortas entre sí e incrementando su densidad. Esto confirma que el mayor grado de agrupación de los incendios forestales está limitado a ciertas zonas y concuerda con la noción de que los incendios forestales son un fenómeno mayormente raro en términos de ocurrencia espacial (Taylor et al., 2013). Por el contrario, los patrones regulares que detectamos en distancias mayores indican una interacción negativa entre los puntos, lo que reduce la probabilidad de encontrar puntos vecinos a distancias cortas debido al aumento de homogeneidad espacial en el ambiente a estas escalas. Algunos estudios han señalado que es más común encontrar patrones agrupados y en ocasiones un patrón regular se atribuye a que la misma área no se quema frecuentemente, lo que imposibilita la agrupación de incendios (Podur et al., 2003). Los patrones aleatorios se encontraron en todos los meses a distancias intermedias; estos patrones suponen una ausencia de interacción entre los puntos de calor y el ambiente, y entonces cualquier porción del territorio tiene la misma probabilidad de contener un punto (Cressie, 1993).
Un aspecto importante a considerar para caracterizar patrones de incendios son los agentes causales, ya que distintas causas de incendios pueden dar lugar a diferentes patrones de puntos. Se ha encontrado que los incendios ocasionados por rayos, es decir, de causa natural, tienden a tener patrones aleatorios, mientras aquellos de origen humano se agrupan en el territorio (Hering et al., 2008). Para el caso del uso de puntos de calor, no es posible conocer su causa, por lo que la necesidad de bases de datos de incendios en el terreno con información asociada se vuelve de vital relevancia para el entendimiento de la dinámica de incendios forestales en el área de estudio.
Factores que determinan la densidad de puntos de calor
El enfoque de considerar la ocurrencia de incendios como una variable continua ha sido empleada en estudios enfocados principalmente en las técnicas para su representación espacial (Amatulli, Pérez-Cabello y De la Riva, 2007; De la Riva, Pérez-Cabello, Lana-Renault y Koutsias, 2004; Koutsias et al., 2004) y en menor proporción para explicar las variables relacionadas con la densidad de incendios forestales (Amatulli et al., 2006). La importancia de representar a los incendios como una variable continua es que se pueden conocer los umbrales de algunas de las características climáticas, topográficas y antropogénicas necesarios para identificar las condiciones que deben prevalecer en el paisaje para que ocurran tanto densidades de incendios bajas como altas. Los incendios forestales son un fenómeno complejo, por lo que los árboles solo pudieron explicar hasta 60% de su variabilidad. Se identificó que la precipitación pluvial, la temperatura diurna, la distancia a asentamientos humanos, la altitud, la vegetación y el uso del suelo, la distancia a terracerías y las brechas fueron las variables que explicaron la densidad de puntos de calor. Sin embargo, en algunos casos, la influencia de estas variables y la densidad de incendios no fue la esperada, especialmente en relación con los supuestos que se emplean en los modelos de peligro y riesgo de incendios.
En general, estos modelos suponen una relación negativa entre la precipitación y la ocurrencia de incendios y una relación positiva entre la temperatura y el número de incendios (Abbott, Leblon, Staples, Maclean y Alexander, 2007; Andrews et al., 2007; Vadrevu et al., 2010). En algunos casos (marzo y abril) se identificó que las densidades de incendios más altas ocurren en áreas con mayor precipitación o menor temperatura. Esto parecería en primera instancia un resultado contradictorio, sin embargo, esto puede ser explicado en el contexto de los valores mensuales promedio de ambas variables (Fig. 2b). Por ejemplo, aunque se presente mayor precipitación, los valores de sus umbrales son cercanos al promedio esperado y la densidad de puntos depende también de otros factores como la temperatura, la distancia a zonas agrícolas y la distancia a brechas. Algo similar ocurre con la temperatura: aunque en algunas ocasiones ocurran incendios con temperaturas menores en comparación con áreas con temperaturas mayores, los valores de temperatura corresponden a una condición frecuente en la región y muy cercanas a los valores promedio mensuales. Los resultados indican que la precipitación y la temperatura son determinantes para la ocurrencia de incendios, pero se tienen que cumplir otras condiciones en el territorio para que se presenten las densidades más altas de incendios forestales.
Los factores antropogénicos influyen en los patrones de distribución de los incendios forestales, y en muchas ocasiones estos ocurren en la proximidad a infraestructura urbana y caminos. En este estudio se encontró que la densidad de incendios no siempre es mayor en áreas cercanas a asentamientos humanos, a vías de acceso o a zonas agrícolas. Esto indica que no solo se queman áreas cercanas a estos rasgos, sino también aquellas lejanas y que cumplen con otras condiciones identificadas en los árboles de regresión. Estos resultados coinciden con los publicados en otras investigaciones que han mostrado que la frecuencia de los incendios es mayor a niveles intermedios de influencia humana, pero, a niveles altos y bajos de influencia humana, la actividad de incendios es menor (Keeley, 2005; Syphard et al., 2007). Por otra parte, Lozano, Suárez-Seoane, Kelly y Luis (2008) también encontraron que en algunos casos la probabilidad de incendios aumenta cuando existe una mayor distancia a la infraestructura humana y a caminos.
En el caso del presente estudio, es posible que naturaleza incompatible entre las variables medidas a través de la distancia y la densidad de incendios puede ocasionar que la distancia pierda un significado cuando se relaciona con un valor de densidad en lugar de la localización del punto de localización exacto del incendio, como lo señalan Amatulli et al. (2006).
El uso del suelo y la vegetación influyen en la ocurrencia de incendios forestales. En el área de estudio, las densidades de puntos de calor mayores ocurrieron en los siguientes tipos de vegetación, agrupados de acuerdo con la clasificación de la susceptibilidad de la vegetación al fuego de la Conabio (1998b): (1) bosques de encino, encino-pino, bosque mesófilo de montaña, selva mediana subperennifolia, selva alta perennifolia y matorrales, que tienen baja probabilidad de incendio y baja recuperabilidad; (2) bosques de pino-encino, que poseen alta probabilidad de incendio con alta recuperabilidad y (3) selva baja, con alta probabilidad de incendios y con baja recuperabilidad. Estos resultados resaltan la importancia de conocer la dinámica de incendios en función de los tipos de vegetación para implementar acciones de prevención y manejo ecológico del fuego de manera adecuada en la región.
Conclusiones
El presente estudio demuestra que la caracterización de las propiedades espaciales de los puntos de calor es útil para detectar patrones espacio-temporales y las variables relacionadas con incendios forestales en la Sierra Madre Oriental de San Luis Potosí.
Los patrones espaciales de los puntos de calor varían en función de la escala de análisis. En general, para distancias menores a 15 km, se encontraron patrones agrupados que resultan de la heterogeneidad del territorio. Esta heterogeneidad ocasiona que los puntos de calor se concentren donde se cumplen, en términos espaciales, ciertas condiciones ambientales y antropogénicas. Conforme la distancia de análisis aumenta, se encuentran patrones aleatorios o regulares que indican condiciones ambientales y antropogénicas más homogéneas en el territorio e independencia espacial entre los puntos de calor.
El análisis con árboles de regresión permitió cuantificar la influencia de las variables ambientales y antropogénicas en la densidad de puntos de calor a escala de paisaje. La densidad de puntos de calor a escala de paisaje está determinada principalmente por interacciones entre la precipitación, la temperatura diurna, la vegetación y el uso del suelo, la altitud, la distancia a asentamientos humanos y a terracerías.
Los resultados proporcionan los umbrales de cada una de las variables de mayor influencia en la densidad de puntos de calor; estos umbrales son de utilidad práctica para generar cartografía de riesgo de incendios forestales que facilite la toma de decisiones en el ámbito de programas de prevención y control de incendios en la región.

