










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkRevista Chapingo. Serie horticultura
On-line version ISSN 2007-4034Print version ISSN 1027-152X
Rev. Chapingo Ser.Hortic vol.14 n.2 Chapingo May./Aug. 2008
Problemas y métodos comunes del análisis de experimentos factoriales
Common problems and methods of the analysis of factorial experiments
J. Sahagún–Castellanos1*, A. Martínez–Garza2† y J. E. Rodríguez–Pérez1
1 Programa Universitario de Investigación en Olericultura, Departamento de Fitotecnia. Universidad Autónoma Chapingo. Km. 38.5 Carretera México–Texcoco. Chapingo, Estado de México. México. C. P. 56230. Tel. (01595 9521500 Ext. 6185) Fax (01595 9521642) Correo–e: jsahagun@correo.chapingo.mx (*Autor responsable)
2 Instituto de Socioeconomía, Estadística e Informática. Colegio de Postgraduados. Km. 36.5 Carretera México–Texcoco, Montecillo, Estado de México. C. P. 56230. México.
Recibido: 3 de diciembre, 2007
Aceptado: 12 de febrero, 2008
Resumen
En la investigación agronómica frecuentemente se hacen experimentos factoriales; éstos constituyen herramientas que hacen un uso óptimo de recursos, producen estimaciones de contrastes de medias de tratamientos más precisas y hacen posible el estudio de las interacciones entre los factores. Sin embargo, el aprovechamiento integral de estas ventajas no siempre se obtiene debido a uno o varios de los problemas siguientes: interpretación deficiente del concepto de interacción; abuso de las comparaciones múltiples de medias; subutilización y hasta omisión de técnicas de regresión, contrastes y polinomios ortogonales, etc. Para contribuir a la solución de esta problemática, y con ello mejorar la calidad de los artículos científicos que se pretende publicar, en este estudio se analizan varias acepciones del concepto de interacción, incluyendo desde aspectos etimológicos hasta su significado como fuente de variación en el análisis de varianza. Además, en el contexto de factoriales, se analizan tópicos relacionados con la pertinencia, aplicación y ventajas de las técnicas de regresión, contrastes y polinomios ortogonales. Para hacer más objetiva la presentación se recurrió a ejemplos hipotéticos. Se espera que el lector mejore su percepción conceptual y su capacidad para asociar exitosamente casos de experimentación factorial con metodologías de análisis apropiadas, y que esto redunde en un mejor análisis de la información experimental, interpretación de sus resultados y en una mayor calidad de sus publicaciones científicas.
Palabras clave: experimentos factoriales, interacción, contrastes, contrastes ortogonales, comparaciones múltiples de medias.
Abstract
Factorial experiments are frequently carried out in agronomic research. These are tools that make an optimus resources use; produce more precise estimates of treatment means constrasts, and make possible the interactions among factors study. The full release of these advantages, however, is not always obtained due to one or several of the following common problems: interaction concept poor interpretation; multiple comparison procedures abuse; regression techniques sub utilization or omission, orthogonal contrasts and polynomials, etc. In order to contribute to solve these problems and thereby to improve the scientific articles to be published quality, in this paper several interaction concept meanings, including from its etymological aspects until its analysis of variance variation source meaning , were analyzed. In addition, cases related with the pertinence, use and advantages of regression, contrasts, and orthogonal contrast and polynomial techniques were analyzed in the factorial experiments context. Factorial experiments hypothetical cases were considered to make a more objective presentation. It is hoped that the reader's conceptual perception and capacity to successfully associate cases of factorial experiments and statistical methods to analyze them properly will be improved and thereby will enable them to increase the results interpretation and their scientific publications quality.
Key words: factorial experiments, interaction, contrasts, orthogonal contrasts, multiple comparisons.
INTRODUCCIÓN
El estudio de varios factores en un experimento factorial permite ahorrar recursos; incrementa la precisión de las estimaciones de medias de efectos, y hace posible el estudio de la interacción entre tales factores. Precisamente, uno de los conceptos más distintivos de los experimentos factoriales, aunque no siempre bien entendido por el usuario, es el de la interacción entre factores. En el Diccionario de la Real Academia Española (DRAE) del 2001, la interacción se define como "la acción que se ejerce recíprocamente entre dos o más objetos, agentes, fuerzas, funciones, etc." En el contexto estadístico, particularmente en el de la investigación agrícola, frecuentemente la interacción entre dos factores se define como una medida de la variación de las diferencias observadas entre los efectos de los niveles de un factor a través de los niveles del otro (v.g., Knight, 1970; Mather y Caligari, 1976). Al parecer, referirse a la interacción en formas diferentes contribuye a dificultar su entendimiento y, con ello, a incrementar la ocurrencia de errores en la elección y aplicación de métodos para analizar los datos de un experimento factorial e interpretar y manejar debidamente los resultados de su análisis de varianza (ANAVA).
En el ANAVA, la magnitud de la suma de cuadrados de la interacción entre dos factores A y B se relaciona directamente con la variación de las diferencias entre las medias de los niveles de A a través de los niveles de B (o viceversa). A pesar de que está bien definida la peculiaridad de la interacción en el ANAVA, su interpretación no siempre es apropiada. Por ejemplo, supóngase que dos variedades de jitomate (Lycopersicon esculentum Mill.) se evaluaron en dos dosis de una solución nutritiva y que en la dosis baja (D1) el rendimiento de una variedad (V1) superó al de la otra (V2). Supóngase además que con la dosis alta (D2) V2, por su capacidad genética, respondió con un incremento en rendimiento que la hizo superar al rendimiento que produjo V1 con esa misma dosis. Si, por lo que respecta a tratamientos, el ANAVA sólo detectará significancia de la interacción entre los factores, sería erróneo afirmar que estadísticamente no hay diferencia entre efectos de las variedades (entre medias de variedades) ni entre efectos de dosis (entre medias de dosis). Lo que procedería sería la comparación de los rendimientos de las variedades en cada dosis y viceversa. Con esta estrategia se podría determinar si una variedad es estadísticamente superior en rendimiento a la otra cuando se aplica D1 (o bien cuando se aplica D2). También se podría definir, en su caso, qué variedad aumenta significativamente su rendimiento cuando se fertiliza con D2. El tipo de error de interpretación anterior no es el único posible; con frecuencia se hacen evidentes algunas deficiencias conceptuales y metodológicas en los análisis de datos de experimentos factoriales.
Entre los errores que más frecuentemente ocurren en los análisis de datos de experimentos factoriales se encuentran: 1) Ignorar indebidamente la estructura factorial y, en caso de significancia de los tratamientos, comparar sólo las medias de todas las combinaciones de niveles; 2) Hacer sólo comparaciones entre las medias de los efectos de los niveles de cada factor (efectos principales) cuando la interacción es significativa; 3) Omitir análisis ad hoc cuando se estudian factores cuantitativos (por ejemplo, análisis de regresión o, en su caso, de polinomios ortogonales), y en su lugar hacer comparaciones múltiples de medias, y 4) Omisión no pertinente de técnicas de análisis de factores cualitativos (contrastes y estimación de diferencias de medias mediante intervalos de confianza, por ejemplo).
Toda investigación experimental debe incluir una definición clara de los métodos de experimentación y de análisis de datos utilizados, congruentes con la consecución de los objetivos perseguidos. El final de la investigación debe ser una publicación cuya responsabilidad no recae exclusivamente en los investigadores y en sus asesores; los revisores técnicos, editores, etc., también tienen injerencia en la calidad del documento científico que se pretende producir.
Reconociendo su responsabilidad en la calidad de sus publicaciones, el Comité Editorial de la Revista Chapingo Serie Horticultura, ha promovido acciones cuyo objetivo es contribuir a mejorar la calidad de sus artículos. En particular, con este trabajo se pretende mejorar la percepción de los investigadores con respecto al concepto de interacción y a la debida correspondencia entre métodos de análisis y casos de experimentación factorial.
Los métodos de análisis a que se hará referencia no son nuevos, han sido descritos en numerosas ocasiones desde hace tiempo (v.g., Cochran y Cox, 1973; Steel y Torrie, 1960; Chew, 1976; Nelson y Rawlings, 1983; Lindman, 1992). En primera instancia se trabajará el aspecto conceptual y posteriormente el de los métodos estadísticos. Todo con un enfoque, eso sí, propio de los autores.
MODELOS Y CONCEPTOS BÁSICOS
Para definir un modelo que explique el dato de cada parcela de un experimento factorial en términos de los efectos de las combinaciones de los a niveles de un factor A con los b niveles de un factor B se considerará que, independientemente del diseño experimental utilizado, será posible hacer comparaciones entre los niveles de un factor libres de los efectos de los niveles del otro u otros factores (condición que se denomina ortogonalidad entre los efectos de los factores). Por esta consideración, los efectos de los niveles de los factores A y B y de su interacción podrán ser estudiados más fácilmente con base en un modelo que no incluya factores adicionales aunque los haya (como bloques, por ejemplo). Así, con las suposiciones usuales (distribución normal, independencia de errores, homogeneidad de varianzas, etc.), la observación de la parcela que recibe los niveles i y j de A y B, respectivamente, en su repetición k (Yijk) se explica como:

en donde ì es la media general; αi, βj y (αβ) son los efectos (fijos) de los niveles i de A, j de B y de la interacción entre αi y βj, respectivamente, y εijk es el efecto aleatorio de error asociado a Yijk .
Para facilitar el entendimiento de conceptos, en esta parte se eliminará el ruido que causan los efectos aleatorios del error. Para ello, los efectos de los niveles de los factores y su interacción se describirán en términos de valores esperados de las Yijk del modelo 1 (que ya no incluyen error) y éstos se expresarán de acuerdo con la expresión general E(Yijk) = yijk. En estas y's se usará la notación en que un punto puesto en el lugar de un subíndice querrá decir que se han promediado las y's que corresponden a los valores de ese subíndice. Así, para los términos de la Ecuación 1:

De acuerdo con las expresiones en (2) resulta que:

Como consecuencia, las medias de los efectos son siempre iguales a cero. Como se expresó en (2), el efecto de interacción (αβ) es una diferencia entre dos efectos del nivel j de B: El primero es en presencia del nivel i de A, (yij –yi.. ), y el segundo es el efecto promedio general, (y.j. –y... ). Por otra parte, el intercambio de yi.. y y.j. hace que (αβ)ij también sea expresable como una diferencia entre dos efectos del nivel i de A:
(αβ)ij = (yij. –y.j. )–(y.j. –y... )
Ambas expresiones se reflejan en la suma de cuadrados de la interacción:

Ésta a su vez se relaciona directamente con la variación del comportamiento relativo de los niveles de A a través de los niveles de B (o viceversa).
En el ANAVA la suma de cuadrados debida a la variación entre los efectos de las ab combinaciones de los a niveles de A con los b niveles de B (Ecuación 1) puede ser descompuesta en tres partes debidas a la variación entre las medias experimentales de: 1) Los efectos de los niveles de A; 2) los efectos de los niveles de B, y 3) los efectos de la interacción AB. Cada una de estas tres partes a su vez puede ser descompuesta en porciones asociadas a contrastes, deseablemente congruentes con los objetivos de la investigación.
En un experimento con los factores A, B y C con a, b y c niveles, respectivamente, la suma de cuadrados de las abc combinaciones puede ser dividida en siete partes debidas a: Los efectos principales de los tres factores (A, B y C); las tres interacciones entre dos factores (AB, AC y BC), y la interacción entre los tres factores (ABC). El modelo básico para explicar el valor de la observación de la repetición l que recibió los niveles i, j y k de los factores A, B y C (Yijkl), respectivamente, es:

En donde αI, βJ y Γ, son los efectos (fijos) de los niveles i, j y k de A, B y C; (αβ)ij, (αΓ)ik, (βΓ)jk y (αβΓ)ijk son las interacciones entre los efectos indicados y εijkl es el término aleatorio de error correspondiente a Yijkl. Por extensión de las expresiones en (2), resulta que, por ejemplo:

Del conjunto de expresiones en (5) y (2) y en sus extensiones se obtiene que:

En la Ecuación 5 el efecto de interacción (αβΓ)ijk es interpretable como la diferencia entre el efecto (βΓ)jk en presencia del nivel i de A, (yijk.–yij..) – (yi.k–yi...), y el efecto (βΓ)jk en todo el experimento, (y.jk.–y.j..)–(y..k.–y....). Análogamente, (αβΓ)ijk también puede ser interpretable con base en (αβ)ij o (αΓ)iksegún las expresiones, respectivamente:

Estas dos expresiones del efecto (αβΓ)ijk [Ecuaciones 7 y 8] son una extensión de la definición del efecto de interacción (αβ)ij (Ecuación 2) en el sentido de que se describen como una diferencia entre dos efectos. Análogamente, para cuatro o más factores el efecto de su interacción se definiría como una diferencia entre dos efectos de interacción que involucran todos los factores excepto uno.
Para ejemplificar numéricamente los efectos de los niveles de los factores y de sus interacciones, considérese un factorial hipotético con dos variedades de tomate de cáscara (Physalis ixocarpa Brot.) (G1 y G2), dos dosis de fertilización (D1 y D2) y dos formas de regar (R1 y R2). De acuerdo con una extensión de las expresiones en la Ecuación (2), para los rendimientos medios (t·ha–1 x 10) hipotéticos (sin error) del Cuadro 1, la determinación de la media (µ), del efecto de la variedad 1 (Γ1), de la dosis de fertilización 1 δ1, de la forma de regar 1 λ1 y de un efecto de interacción, Γδ11, se hace a continuación:


En el Cuadro 2 se muestran las medias de las combinaciones de niveles de cada dos de los tres factores, D, R y G, del Cuadro 1. Se puede afirmar que los efectos de interacción de los tipos (Γλ) y (δλ) son iguales a cero, ya que las diferencias entre las medias de los efectos de los niveles de cada uno de los factores en RG y DR no cambian cuando se pasa de uno al otro de los niveles de D y G, respectivamente. Gráficamente, la ausencia de interacción entre dos factores hace que las líneas de los niveles de un factor sean paralelas cuando se grafica contra los niveles del otro (Figuras 1A y 1B), lo que no sucede para los factores D y G (Figura 1C), entre los que sí hay efectos de interacción de la forma (Γδ)diferentes de cero (Ec. 9).
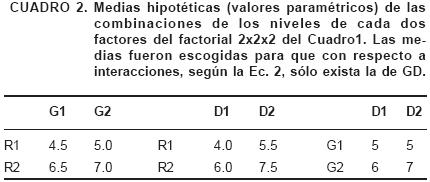

Respecto a la interacción DGR del Cuadro 1, por analogía con la Ecuación (6), como

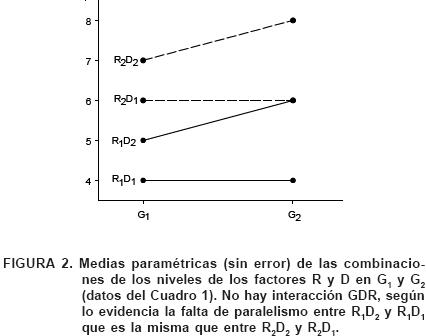
y como los términos del lado derecho (i = 1, 2,..., a; j = 1, 2,..., b; k = 1, 2,..., c) de esta expresión ya fueron calculados [resultados en (9)] se puede verificar que todos los efectos del tipo (Γδ)ijk son iguales a cero, y se dice, en consecuencia, que no hay interacción DGR. En términos gráficos, el patrón que se observa entre las líneas R1D1 y R1D2 (Figura 2) es el mismo que hay entre las líneas R2D1 y R2D2, lo que significa que todos los efectos de interacción DGR son iguales a cero; lo que también refleja el mismo comportamiento relativo de los efectos de D1 y D2 al pasar de R1 a R2. Otra forma de analizar la interacción entre tres factores se basa en la gráfica de los niveles de un factor contra los niveles de otro en cada uno de los niveles del tercer factor; si las líneas de cada gráfica tienen entre sí niveles de ausencia de paralelismo que no varían de una gráfica a otra, se concluirá que no hay interacción entre los tres factores. En cada una de las Figuras 3 y 4, construidas con los datos del Cuadro 1, hay una reproducción de patrones del comportamiento de las combinaciones de niveles de dos parejas de factores: D y R (Figura 3), y D y G (Figura 4), en los dos niveles del tercer factor.


Al lector que considere que ya tiene un buen entendimiento de lo que es la interacción se le sugiere pasar al apartado de métodos de análisis.
Un conjunto hipotético de medias paramétricas (sin error) de un factorial con 2, 3 y 3 niveles de los factores A, B y C, respectivamente, construido para que sólo haya efectos diferentes de cero para A(αi), AB(αβij) y ABC [(αβΓ)ijk] se muestra en el Cuadro 3. De esta información, con base en las expresiones para la media, un efecto de un nivel de un factor, una interacción entre dos factores y una interacción entre tres factores (Ecuación 6) se obtiene que:
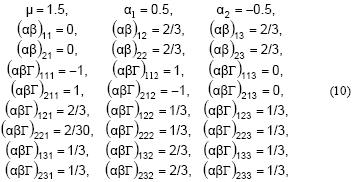
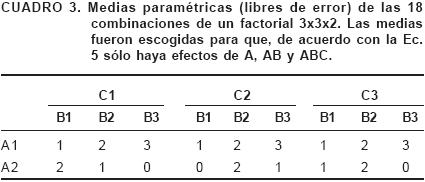
En el ejemplo hipotético de los datos del Cuadro 3, la interacción AB y la ausencia de interacción BC son muy fácilmente discernibles en la forma en que se presenta la misma información en el Cuadro 4. Las diferencias entre los efectos de niveles de A cambian cuando se pasa de un nivel de B a otro de sus niveles, y no hay diferencias entre niveles de C ante cada nivel de A, respectivamente.

Las representaciones gráficas de los efectos de un factorial de tres factores no siempre son un instrumento de fácil manejo para determinar la existencia o inexistencia de una interacción. Aún en los casos hipotéticos (sin error) que se está analizando puede suceder que, por lo que sólo a la figura geométrica concierne, una misma representación gráfica pueda corresponder a un caso con interacción ABC o a un caso sin esta interacción. Por ejemplo, en la Figura 5 no existe interacción ABC; sin embargo, si en la gráfica para A2 se intercambiaran los niveles C1 y C2 (sólo estos símbolos) no cambiaría la figura geométrica pero sí se detectaría interacción ABC.

MÉTODOS DE ANÁLISIS
A diferencia de los datos hipotéticos de los Cuadros 1 a 4 (2,3) y de las Figuras 1 a 5 (2,3,4), los datos obtenidos en la investigación experimental, además de los efectos de los niveles de los factores y de sus interacciones, también reflejan efectos aleatorios de error. Éstos generan la necesidad de diseñar experimentos y métodos de análisis de datos que tiendan a contrarrestar los efectos aleatorios que enmascaran los verdaderos efectos de los niveles de los factores y los de sus interacciones.
Comparaciones de medias
En este apartado sólo se considerarán los casos, poco frecuentes, en que por la naturaleza de los factores la comparación de cada media con cada una de las restantes es apropiada. Esto puede ocurrir con factores de carácter cualitativo cuyos niveles no poseen características que hagan más importantes algunas comparaciones (a nivel individual o de grupos) que otras.
Cuando en un factorial la interacción entre dos factores es estadísticamente significativa, las medias experimentales de los niveles de cada factor se deben comparar en cada uno de los niveles del otro, independientemente de que los factores sean estadísticamente significativos. Se debe proceder así porque con interacción significativa las magnitudes de las diferencias observadas entre las medias de los niveles de un factor no son iguales a través de los niveles del otro factor. Y esto puede hacer que las diferencias que no son estadísticamente significativas ante un nivel del segundo factor sí lo sean ante otro(s) nivel(es) de este segundo factor y viceversa. Además, se genera información que permite un mejor acercamiento para detectar e interpretar las causas de la interacción.
Sin la variación aleatoria de error, cuando no hay interacción ABC cada una de las diferencias entre las medias de cada par de niveles de C (por ejemplo) en cada una de las combinaciones de los b niveles de B con el mismo nivel de A, tienen cambios de una misma magnitud cuando se pasa a otro nivel de A. Cuando esto no suceda habrá interacción ABC. Así, sólo cuando los cambios referidos sean siempre de una magnitud igual a cero, con datos experimentales las comparaciones estadísticas de las medias de los niveles de C deben producir los mismos resultados en cada uno de los niveles de A.
Estrictamente, comparar los niveles de C en cada una de las ab combinaciones de los a niveles de A con los b niveles de B también puede visualizarse como la consecuencia de la existencia de interacción significativa entre C y el "factor" cuyos niveles fueran las ab combinaciones de los niveles de A con los de B. Pasar de tres a dos factores puede tener valor aplicado si el manejo de cada combinación de niveles de los factores A y B tuviera sentido para el investigador o para el usuario de la tecnología que se llegara a derivar. Un ejemplo hipotético de la ocurrencia de este tipo de interacción es la información del Cuadro 3 con respecto a la comparación de los dos niveles de A en cada combinación de niveles de B y C.
Varios autores (v.g., Chew, 1976; Petersen, 1977; Carmer y Walker, 1982; Lindman, 1992) han descrito numerosos procedimientos para hacer inferencia sobre contrastes que involucran medias de tratamientos; destacan el de Tukey para la comparación de todas las medias entre sí; el de Dunnett para comparar la media de un testigo con cada una de las medias restantes; el de Scheffé para probar y estimar contrastes que resultan interesantes después de un examen preliminar de datos de experimentos exploratorios, etc. Carmer y Walker (1982) discuten el valor relativo de algunos procedimientos para comparar medias.
En general, no siempre (y en realidad en menos casos de los que los usuarios lo hacen) las comparaciones de medias son el procedimiento estadístico que se debe aplicar. Cómo proceder después de que el análisis de varianza se ha efectuado depende de la naturaleza de los factores y de los objetivos de la investigación.
Factores cuantitativos
Para un factor cuyos niveles pueden asociarse con puntos en una escala numérica, como distancia entre plantas, dosis de fertilización, etc., un análisis estadístico más adecuado que la comparación de medias se basa en el ajuste de una función de respuesta mediante técnicas de regresión. Es usual que la relación entre la variable respuesta (Y) y los niveles de un factor cuantitativo (X) se aproxime mediante un polinomio de la forma:

El proceso se puede iniciar con el polinomio de orden más bajo, aumentándolo sucesivamente hasta que se encuentre uno que explique la mayor parte de la variabilidad. Con frecuencia, un polinomio de segundo grado es suficiente [cuando esta metodología se extiende a más de un factor cuantitativo se puede recurrir al concepto de superficie de respuesta (y.g., Martínez, 1988; Montgomery, 1991)]. Con este enfoque, la interpretación cambia radicalmente; en lugar de comparar las medias asociadas a niveles de factores se recur re a la estimació n. Por eje mplo, para sólo u n factor P0 (X) = 1 .fifWltafvX orsXejp/duede estimar el efecto que p ara la va riable respuesta (Y) tiene un valor cualquiera de la variable independiente X (de preferencia dentro del intervalo explorado con los niveles del factor). Por ejemplo, si se adoptara el modelo:
Y = 13.2 + 2.5X,
se estimaría que por cada unidad en que se incremente X, Y experimentaría un aumento de 2.5 unidades. Similarmente, si, por ejemplo, los niveles del factor fueran 6, 8, 10, 12, 16, para X=14, el valor estimado de Y sería 48.2 [calculado como 13.2+2.5(14)]. Además, cualquier cambio de X (dentro del intervalo explorado) debe producir un cambio en la variable respuesta Y, por pequeño que éste sea. Si, en cambio, el modelo adoptado fuera:
Y = 3.17 + 20X – 2X2
se estimaría que con X = 5 la variable respuesta Y alcanzaría su máximo valor (esto se debe a que X = 5 es la solución de la ecuación que resulta al igualar con cero la derivada de Y con respecto a X, además de que la segunda derivada es negativa).
Con niveles igualmente espaciados se puede obtener las sumas de cuadrados de los contrastes [SC(C)] debidas a los efectos lineal, cuadrático, cúbico, etc. (y.g., Cockerham, 1954; Lindman, 1992) y con base en la significancia de estos efectos también se puede construir un polinomio ortogonal. Por ejemplo, para un factor cuantitativo con tres niveles igualmente espaciados, si los totales experimentales son T1, T2 y T3, se calcula las sumas de cuadrados debidas al efecto lineal (el promedio de los dos incrementos en la respuesta que se obtienen cuando se pasa del nivel bajo al intermedio y de éste al superior) y al efecto cuadrático (desviación de la respuesta con respecto a la linealidad) según la expresión:

en donde los conjuntos de coeficientes para estos efectos son: {C1 = 1, C2 = 0, C3 = –1} y {C1 = 1, C2 = –2, C3=1}, respectivamente, y n es el número de observaciones que forman cada total. La suma de estas dos sumas de cuadrados representa toda la variabilidad que hay entre las medias de los tres tratamientos debido a que además de asociarse a sendos grados de libertad, son ortogonales; es decir, dan cuenta de variación de origen y significado independiente. Si el cuadrado medio del error y sus grados de libertad se representan por CM(E) y GL(E), respectivamente, entonces, como en cualquier contraste, si
Fc = [SC(C)]/ [CM(E)]
igualara o superara al valor de la distribución de F1, GL(E) que corresponde al nivel α de significancia, se declararía que el efecto (lineal o cuadrático) que se pruebe es estadísticamente significativo. Si ambos efectos fueran significativos se ajustaría un polinomio cuadrático de la forma

donde Pi(X) es el polinomio ortogonal de orden i (i = 0, 1, 2). Los primeros tres polinomios ortogonales, para niveles igualmente espaciados, son (Lindman, 1992):

en donde d = distancia entre los niveles de X y  es la media de estos niveles. Los estimadores de mínimos cuadrados de α0, α1 y α2 para este caso son (v.g., Montgomery, 1991):
es la media de estos niveles. Los estimadores de mínimos cuadrados de α0, α1 y α2 para este caso son (v.g., Montgomery, 1991):

Así, con los valores de T1, T2, T3, X, y d se construye el polinomio según las Ecuaciones (11) a (13)
Para tres o más niveles igualmente espaciados la construcción de los polinomios ortogonales correspondientes ha sido descrita por numerosos autores (v.g., Steel y Torrie, 1960; Montgomery, 1991; Lindman, 1992).
Para dos factores cuantitativos si se tuviera una regresión significativa para las dos variables independientes (las asociadas con estos dos factores) cada combinación de dos niveles cualesquiera (incluidos o no en el estudio) debe producir efectos en la variable respuesta Y. Por ejemplo, el modelo de primer grado es de la forma general:
Y= β0+β1X1+β2X2
Con mínimos cuadrados se puede estimar β0, βt y β2, y con base en la ecuación de predicción construida con los estimadores 

se puede predecir el Y( ) que corresponda a cualquier combinación de X1 y X2; se puede determinar qué valores de X1 y X2 maximizan Y, etc. Algo similar se puede hacer con modelos de mayor grado (v.g., Montgomery, 1991; Lindman, 1992). Si los niveles fueran igualmente espaciados se podría hacer una descomposición ortogonal de la suma de cuadrados debidas a las combinaciones de estos factores. Por ejemplo, si los factores A y B tuvieran tres niveles cada uno, los ocho grados de libertad de las nueve combinaciones de niveles podrían ser asignados a los ocho contrastes ortogonales correspondientes a los efectos: 1) Lineal A, 2) Lineal B, 3) Cuadrático A, 4) Cuadrático B, 5) Lineal A x Lineal B, 6) Lineal A x Cuadrático B, 7) Cuadrático A x Lineal B y 8) Cuadrático A x Cuadrático B. Fasoulas y Allard (1962) generaron los nueve genotipos posibles de cebada (Hordeum vulgare L.) para dos loci con dos alelos en cada locus e hicieron el análisis como si se tratara de un factorial 3x3, en donde, por ejemplo para el locus O, los genotipos OO, Oo y oo fueron los niveles, igualmente espaciados, 2, 1 y 0 (número de genes O en el genotipo); con los contrastes se determinó para varios caracteres la significancia de los efectos aditivos (lineales) y de dominancia (cuadráticos) en cada locus y la de los cuatro efectos epistáticos. Russell y Eberhart (1970) hicieron un análisis similar para tres toe; del genoma de maíz (Zea mays L). Por su parte, Montgomery (1991) muestra un análisis de los datos de un experimento en que se probó el efecto de la cantidad (15, 20, 25, 30 y 35%) de algodón (Gossypium hirsutum) en la resistencia de una fibra; el análisis se hizo mediante técnicas de regresión y, como los niveles son igualmente espaciados, mediante polinomios ortogonales; con cada técnica se ajustó un modelo, y ambos modelos coincidieron.
) que corresponda a cualquier combinación de X1 y X2; se puede determinar qué valores de X1 y X2 maximizan Y, etc. Algo similar se puede hacer con modelos de mayor grado (v.g., Montgomery, 1991; Lindman, 1992). Si los niveles fueran igualmente espaciados se podría hacer una descomposición ortogonal de la suma de cuadrados debidas a las combinaciones de estos factores. Por ejemplo, si los factores A y B tuvieran tres niveles cada uno, los ocho grados de libertad de las nueve combinaciones de niveles podrían ser asignados a los ocho contrastes ortogonales correspondientes a los efectos: 1) Lineal A, 2) Lineal B, 3) Cuadrático A, 4) Cuadrático B, 5) Lineal A x Lineal B, 6) Lineal A x Cuadrático B, 7) Cuadrático A x Lineal B y 8) Cuadrático A x Cuadrático B. Fasoulas y Allard (1962) generaron los nueve genotipos posibles de cebada (Hordeum vulgare L.) para dos loci con dos alelos en cada locus e hicieron el análisis como si se tratara de un factorial 3x3, en donde, por ejemplo para el locus O, los genotipos OO, Oo y oo fueron los niveles, igualmente espaciados, 2, 1 y 0 (número de genes O en el genotipo); con los contrastes se determinó para varios caracteres la significancia de los efectos aditivos (lineales) y de dominancia (cuadráticos) en cada locus y la de los cuatro efectos epistáticos. Russell y Eberhart (1970) hicieron un análisis similar para tres toe; del genoma de maíz (Zea mays L). Por su parte, Montgomery (1991) muestra un análisis de los datos de un experimento en que se probó el efecto de la cantidad (15, 20, 25, 30 y 35%) de algodón (Gossypium hirsutum) en la resistencia de una fibra; el análisis se hizo mediante técnicas de regresión y, como los niveles son igualmente espaciados, mediante polinomios ortogonales; con cada técnica se ajustó un modelo, y ambos modelos coincidieron.
Factores cualitativos
Para un factor cualitativo (uno cuyos niveles no pueden ser ordenados de acuerdo con su magnitud; por ejemplo: variedades, tipos de sustratos, tipos de herbicidas, etc.) algunas veces es posible planear y efectuar comparaciones de tratamientos estrechamente relacionados con los objetivos de la investigación. Por ejemplo, considérese el caso hipotético en que se va a estudiar el rendimiento de fruto de tres variedades de jitomate en una localidad de El Bajío, una (V1) desarrollada por el Instituto de Horticultura, otra (V2) por el Instituto Nacional de Investigaciones Forestales, Agrícolas y Pecuarias, en tanto que la tercera (V3) es la variedad que más se siembra en la región objeto de estudio. Supóngase que debido a que el pulgón (Diuraphis noxia) empieza a ser un problema en la región, la evaluación de las tres variedades se hará con (I1) y sin (I2) la aplicación de un insecticida. Con relación a los 5 grados de libertad correspondientes a variedades (2), insecticidas (1) e interacción (2), con este trabajo se pretende dar respuesta a las cinco preguntas siguientes: 1) ¿Rinden igual las variedades nuevas (en promedio) y la variedad más sembrada?; 2) ¿Rinden igual las dos variedades nuevas?; 3) ¿Tiene un efecto en el rendimiento la aplicación del insecticida?; 4) ¿Responden igual a la aplicación del insecticida las dos variedades nuevas?; 5) ¿Afecta la aplicación del insecticida la diferencia que se observa entre el promedio de las variedades nuevas y el de la más sembrada cuando no se usa insecticida? El análisis de los datos de la evaluación de campo debe orientarse a la producción de respuestas para las cinco preguntas. Para ellas, en el Cuadro 5 se muestran, en el orden de las cinco preguntas, sendos contrastes mutuamente ortogonales (dos contrastes son ortogonales si  , las Ck y Ck son los coeficientes de un contraste y otro, respectivamente). Por ejemplo, si el contraste 1 fuera significativo querría decir que el promedio de las medias de las variedades nuevas (V1 y V2) difiere estadísticamente de la media de la variedad más sembrada (V3); similarmente, la significancia del contraste 2 haría concluir que las medias de los rendimientos de las variedades V1 y V2 difieren estadísticamente, etc.
, las Ck y Ck son los coeficientes de un contraste y otro, respectivamente). Por ejemplo, si el contraste 1 fuera significativo querría decir que el promedio de las medias de las variedades nuevas (V1 y V2) difiere estadísticamente de la media de la variedad más sembrada (V3); similarmente, la significancia del contraste 2 haría concluir que las medias de los rendimientos de las variedades V1 y V2 difieren estadísticamente, etc.
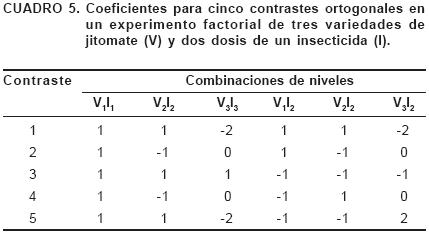
En general, cuando sea congruente con los objetivos de la investigación, la formación de contrastes ortogonales tiene ventajas: a) Cada una de las pruebas de hipótesis asociadas a contrastes ortogonales aporta información nueva, independiente; b) la interpretación de resultados es más sencilla, y c) el número máximo de contrastes es limitado. Por ejemplo, para las tres variedades de jitomate el número máximo de contrastes ortogonales es dos; éstos pueden ser los contrastes C1 y C2 ya definidos que no generan problemas de interpretación cualesquiera que sean los resultados respecto a su significancia estadística. En cambio, si los contrastes no ortogonales relativos a las comparaciones de V1 con V2 y de V2 con V3 fueran sometidos a prueba y se concluyera que, estadísticamente, V1 = V2 y V2 = V3 se podría interpretar que V1 = V3; sin embargo, esto no necesariamente es cierto, como si lo sería en el escenario de la más estricta lógica matemática.
Por otro lado, si para el mismo ejemplo se recurriera a las pruebas de F del análisis de varianza para variedades (V), para insecticidas (I) y para la interacción (IV), con significancia estadística para V y para IV no se produciría ninguna respuesta específica para ninguna de las cinco preguntas. Con la prueba de F para I, en cambio, se probaría la hipótesis de igualdad de efectos de los dos niveles del factor I, la misma que se prueba con el contraste 3. En otro escenario, si las tres variedades no tuvieran las características mencionadas y la interacción IV fuera significativa se debería interpretar que las variedades no responden igualmente a la aplicación del insecticida y posteriormente se podría determinar las particularidades de esta respuesta diferencial. Por ejemplo, se podría comparar las medias de las variedades en cada nivel del factor I para determinar, en su caso, qué variedades rinden más cuando no se aplica insecticida y, similarmente, cuando sí se aplica. Además, con la comparación de las dosis de insecticida en cada variedad se podría identificar, en su caso, las variedades que aumentan significativamente su rendimiento por efecto del insecticida o, aún mejor, se podría estimar mediante un intervalo de confianza la diferencia entre las medias de rendimiento de I1 e I2 en cada variedad (Steel y Torrie, 1960; Montgomery, 1991). Con esta estimación, además de darse una idea de la magnitud de la diferencia entre estas medias (lo que no se consigue con la prueba de hipótesis), se determinaría si tal diferencia es estadísticamente significativa (cuando el intervalo de confianza estimado no incluya el cero).
En el ejemplo objeto de análisis, ya sea con los contrastes o con la comparación de medias de los niveles de un factor en cada uno de los niveles del otro, se obtiene información que no se lograría con la comparación de cada media con las cinco restantes (son seis medias, una de cada combinación de niveles), cualquiera que fuera el procedimiento de comparación. Sin embargo, es innegable, particularmente desde una perspectiva pragmática, que si sólo se deseara identificar las combinaciones de niveles cuyas medias fueran las mayores, la comparación de cada media con cada una de las restantes sería adecuada.
En general, cuando se han definido contrastes congruentes con los objetivos del estudio, las pruebas de F para los efectos principales e interacciones pierden importancia. Por ejemplo, en el factorial sujeto a análisis no sería necesaria la prueba de F para determinar si la interacción IV es significativa puesto que lo interesante de esta interacción ya fue expresado en forma de dos contrastes: el 4 y el 5 (Cuadro 5); además, la prueba de F para I, como ya se mencionó, es la misma que la del contraste 3. Por otra parte, en la construcción de contrastes la guía básica es su congruencia con los objetivos de la investigación, no importa que los contrastes resultantes sean o no mutuamente ortogonales, ni que sean tantos como grados de libertad haya para tratamientos.
Considérese ahora un experimento factorial que involucre dos factores cualitativos; por ejemplo una evaluación de variedades de papa (Solanum tuberosum L.) en varios arreglos topológicos. Si de acuerdo con los objetivos se formara un conjunto de contrastes ortogonales con respecto a las variedades de papa y la interacción fuera significativa, las hipótesis asociadas a estos contrastes se podrían probar en cada arreglo topológico. Si, en cambio, la interacción no fuera significativa, estas hipótesis se probarían en forma global, con los totales o medias calculadas con toda la información del experimento. Esto es así porque en ausencia de interacción, se esperaría que la prueba de cualquiera de estas hipótesis en cada arreglo topológico produzca, estadísticamente, los mismos resultados.
COMENTARIOS FINALES
A continuación se presentan algunas reflexiones sobre el concepto de interacción entre dos factores. Con sólo dos factores, el efecto verdadero de interacción entre los niveles i y j de A y B, (αβ)ij, es la diferencia entre yij (el valor paramétrico de la media de los datos de las parcelas que recibieron la combinación de los niveles i de A y j de B) y µ+ αi+ βj (Ecuación 2) que son los valores esperados de la media de los niveles i de A y j de B con (yij) y sin (µ+ αi+ βj) interacción, respectivamente. Esta acepción de la interacción, que sólo involucra parámetros, es similar a la de Baker (1988), aunque ésta involucra un valor experimental (Yij) en lugar del valor esperado correspondiente (yij) pero difiere de la que interpreta a la interacción sólo en tér–minos de su etimología (DRAE, 2001) y de la que la visualiza como una fuente de variación en el análisis de varianza (y.g., Knight, 1970; Mather y Caliga–ri, 1976; Martínez, 1988; Sahagún, 1992). De las cuatro acepciones de interacción anteriores, la de diccionario es de carácter etimológico, y la de mayor valor lingüístico ya que hace referencia a una acción; sin embargo, no es propia del argot estadístico; las dos primeras se refieren al efecto resultante de esa acción que se ejerce recíprocamente entre los efectos de los niveles de los factores [denotado como (αβ)ij] en tanto que la que la ubica como una fuente de variación en el análisis de varianza es de tipo estadístico y pragmático [se refiere a la variabilidad entre los (αβ)ij's, más específicamente, se relaciona con la hipótesis nula que se prueba en el análisis de varianza [(H0: (αβ)11 = (αβ)12 = ... = (αβ)1b = (αβ)ab vs Ha: H0 es falsa]. Con la prueba de F de esta fuente de variación se determina, en su caso, su significancia estadística, interpretable como un reflejo de la variabilidad entre los efectos (αβ)ij's. Con la ausencia de tal significancia debe asumirse que todos los efectos de interacción de la forma (αβ)ij son iguales a cero.
En la práctica de la investigación experimental comúnmente no se discute la interacción desde un punto de vista científico, pero su significado estadístico se puede encontrar con ayuda de una gráfica. Además de su complejidad, probablemente en muchos casos no se tiene suficiente conocimiento científico del fenómeno; y conforme se involucra más factores esta deficiencia aumenta. Sin embargo, no es común experimentar con más de tres o cuatro factores, ni tampoco es frecuente la significancia estadística de las interacciones entre todos ellos (v.g., Montgomery, 1991; Lindman, 1992).
Con los datos hipotéticos de los Cuadros 1 a 4 (2,3) se determinó los efectos de los niveles de los factores y de sus interacciones con base en las fórmulas descritas en las expresiones de la Ecuación 2 o en sus extensiones (Ecuaciones 5 a 8). En esta visualización hipotética, no habrá interacción sólo cuando cada combinación de niveles de los factores involucrados tiene un efecto de interacción igual a cero. En la realidad, con datos de un experimento, los efectos aleatorios de error hacen necesaria la prueba de una hipótesis para dictaminar si una interacción es estadísticamente significativa (por ejemplo, mediante una prueba de F para una fuente de variación o para un contraste). Con el conocimiento del riesgo de rechazar una hipótesis que es cierta (nivel de significancia), una interacción que se declara estadísticamente significativa implica que los efectos de interacción (αβ)ij no son iguales. Para el análisis subsecuente a la significancia de la interacción que involucra un factor cuantitativo difícilmente se pueden justificar las comparaciones de las medias de sus niveles. Estas comparaciones parecen estar confinadas mayormente a los niveles de un factor cualitativo que no admiten la definición de un conjunto pertinente de contrastes.
AGRADECIMIENTOS
Al Dr. Rafael Mora Aguilar y al Dr. Aureliano Peña Lomelí por sus comentarios y observaciones que enriquecieron las primeras versiones de este artículo.
LITERATURA CITADA
BAKER, R. J. 1988. Differential response to environmental stress. In: Proceedings of the Second International Conference on Quantitative Genetics. BS Weir, EJ Eisen, MM Goodman and G Namkoong (eds.). Sinauer, Sunderland, Massachusetts, pp. 492–504. [ Links ]
CARMER, S. G.; WALKER W. M. 1982. Baby bear's dilemma: A statistical tale. Agronomy Journal 74: 122–124. [ Links ]
COCHRAN, W. G.; COX, G. M. 1973. Diseños Experimentales. Trillas. México. 661 p. [ Links ]
COCKERHAM, C. C. 1954. An extension of the concept of partitioning hereditary variance for analysis of covariances among relatives when epistasis is present. Genetics 39: 859–882. [ Links ]
CHEW, V. 1976. Comparing treatment means: A compendium: Hortscience 11: 348–357. [ Links ]
DRAE. 2001. Diccionario de la Real Academia Española. Vigésima Segunda Edición. Espasa Calpe. Madrid. 2366 p. [ Links ]
FASOULAS, A. C.; ALLARD, R. W. 1962. Nonallelic gene interactions in the inheritance of quantitative characters in barley. Genetics 47: 899–907. [ Links ]
KNIGHT, R. 1970. The measurement and interpretation of genotype–environment interactions. Euphytica 19: 225–235. [ Links ]
LINDMAN, H. R. 1992 Analysis of Variance in Experimental Design. Springer–Verlag. New York. 529 p. [ Links ]
MARTÍNEZ, G. A. 1988. Diseños Experimentales Métodos y Elementos de Teoría. Trillas. México. 756 p. [ Links ]
MATHER, K. P.; CALIGARI, D. D. 1976. Genotype x environment interactions IV. The effect of the background genotype. Heredity 36: 41–48. [ Links ]
MONTGOMERY, D. C. 1991. Design and analysis of experiments. John Wiley and Sons. New York. 649 p. [ Links ]
NELSON, L. A.; RAWLINGS, J. O. 1983. Ten common misuses of statistics agronomic research and reporting. Journal of Agronomic Education 12: 100–105. [ Links ]
PETERSEN, R. G. 1977. Use and misuse of multiple comparison procedures. Agronomy Journal 69: 205–208. [ Links ]
RUSSELL, W. A.; EBERHART, S. A. 1970. Effects of three loci in the inheritance of quantitative characters in maize. Crop Science 10: 165–169. [ Links ]
SAHAGÚN, C. J. 1992. El ambiente, el genotipo y su interacción. Revista Chapingo 16: 5–12. [ Links ]
STEEL, R. G.; TORRIE, J. H. 1960. Principles and Procedures of Statistics. McGraw–Hill Book Company. Inc. New York. 481 p. [ Links ]

