











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
INTRODUCTION
The retina plays an essential role in vision since it transforms the received optical signals into electrical and transfers them to the brain. It provides a clear window to blood vessels and other essential parts of the neural tissue[1]. Since it is an extension of the brain, it could also indicate possible mental health conditions [1].
Ophthalmologists diagnose retinal diseases by identifying specific signs on retinal images. Such signs could be related to diseases such as diabetes, diabetic retinopathy (DR), macular degeneration, glaucoma, and cardiovascular problems. Some of them are progressive and asymptomatic until advanced states [2]. Retinal image analysis turned into an essential matter in the medical area. Many kinds of research are being published to provide predictive information about many diseases even before clinical eye disease becomes detectable [3] [4].
Retinal disease detection has been widely studied using artificial intelligence (AI) methods, specifically machine learning (ML). The ML area has constantly grown in recent years because of the rapid increase in the performance of their methods [5]. They can detect if a retina presents DR and which grade of disease is [6], or the lesion location in the image by segmentation [7] [8]. Most approaches train the algorithms from scratch, meaning the model must learn the parameters without a reference.
This work presents a methodology using transfer learning (TL) to segment different lesions using prior knowledge of what a lesion looks like in the retinal image using an encoder-decoder network and a variant of a traditional convolutional neural network (CNN) [9]. The model's output is an image highlighting the target pixels (commonly referred to as segmentation). The proposed method uses the knowledge learned with a simple classification, whether an image has or not a lesion. Then, applying TL [10], a new model segmented three injuries: exudates, hemorrhages, or microaneurysm. This process reduces the training time significantly, and the pre-trained model is less susceptible to overfitting. It could be implemented in different tasks, for example, a classification of the anatomical parts or segmentation of different diseases like DR with retinal images.
Background
Retinal analysis is an area of much interest. It is not only used to know whether an eye has or not a disease but to segment areas of interest such as the optic disc, fovea area, veins, and arteries [11] [12] [13]. Those tasks have been evaluated with classical ML algorithms like support vector machines [14], or with more classic methods like mathematical morphological algorithms and naive Bayesian for image segmentation [15]. Classical algorithms have attractive advantages because the models do not need many examples to perform well, which is a significant advantage since datasets are typically small.
Deep learning (DL) has been the preferred method to detect, classify, and segment medical images because of its power to generalize data; the only inconvenience is the need for many examples for model training. Lately, researchers have found new methods to confront this problem. Contributions like [16] generate patches of the images to increase the number of examples of retina datasets. Another example implements the superpixel algorithm to generate patches [17].
Most researchers focus on classifying a specific lesion [7] [18] [19] [20]. Others use pre-trained models of different datasets before starting the parameters fine-tuning. It may help, but in many cases, the fine-tuning dataset is not similar to the pre-trained one, making it almost the same as if the training started from scratch [21]. Many researchers widely used datasets like IDRiD, Drive, CHASE-B, MESSIDOR, KAGGLE, and the papers focus are almost the same, detecting lesions [4] [22] [23] [24], classifying DR [6], or segmenting some anatomical parts [25], or injuries [26]. Nevertheless, the models are trained from scratch or using different pre-trained parameters in a different original dataset like IMAGENET.
Different DL models’ effort is to improve the metrics related to the task [22], but not many works try to improve the methodology to avoid starting it from scratch. Works like [27] [28] try to identify a relationship between the vessels caliber and cardiovascular risk problems; an example of exudates segmentation using variants of the classical UNET model [21], with almost the same idea [29], take the dataset and train a model from scratch to segment microaneurysms or some other lesions [24], that classify their presence or absence. All the models achieve high performance, but they will not achieve good results if we try to generalize for different lesions for a specific task.
Most researchers focused on segmenting anatomical areas such as the optic disk, macula [11], veins, and artery [30], training DL models from scratch. Other authors use TL with pre-trained models in a completely different dataset [8] that helps start, but the parameters need to fit the new dataset.
MATERIALS AND METHODS
This methodology consists of two principal stages: stage 1 trains DL models to classify whether or not a retinal image has a lesion, and in stage 2, the objective is to segment a specific lesion employing the knowledge obtained in stage 1 using an encoder-decoder model. The proposed encoder-decoder model has the classifier model's feature extractor as its encoder, and therefore only training the decoder parameters to segment retinal lesions such as exudates, hemorrhages, or microaneurysms. However, this central idea could be applied to other diseases or segment anatomical parts.
Preprocessing data
As we can see in Figure 1, the proposed methodology starts with image preprocessing, which increases the contrast and luminosity by equalizing the original images using CLAHE [31]. This treatment improves the contrast of some structures like red dots, vessels, and microaneurysms that are difficult to visualize. Then, a data augmentation process is applied to generate two new images of each example consisting of rotations, image slides, or zoom.

Figure 1 Methodology: 1) Preprocessing, 2) binary classification, where A is an image with a lesion and B is a healthy image, and 3) segmentation of injuries (A: exudates, B: microaneurysm, and C: hemorrhages).
The data sets used in stage 1 are the Messidor 1 [32], with 1054 images and Kaggle [33], with 36000. These data sets contain retinal images to classify DR grades. Our study uses them only to identify if an image has an injury, being a binary classification. We obtain 100046 training images and 11116 validation images by applying the preprocessing step.
The datasets used in stage 2 are 48 IDRiD [34] and 30 E-Optha [35], images. These datasets have exudates, hemorrhages, and microaneurysm annotations to execute a pixel-to-pixel classification. This stage uses patches of (160, 160, 3) to train the encoder-decoder model, which means that original images are divided in order to in- crease the number of examples to 36840 images. Figure 2 shows the two different sets of ima-ges used in stage 2.

Stage 1
As previously described, the main objective of stage 1 is to generate the knowledge to identify whether the mentioned lesions appear or not in the image; it does not matter where they are located. The models used for classification are shown in Figure 3. These models are the VGG-16 [36], ResNet50 [37], VGG-16 CBAM and ResNet50 CBAM. The last two models include CBAM [38], which pays attention to the channel and spatial axes. The models contain L2 regularizers [39], batch normalization layers [40], and dropouts [41], to prevent overfitting. The feature extractor of these models is used as an encoder in stage 2. The model's input is a tensor of shape (1, 480, 480, 3).

Stage 2
In stage 1, our models classify only whether an image has a lesion or not. However, now we want to know the lesion position in the image. The segmentation task consists of locating the required object pixels in the image. For this, we use an encoder-decoder model, the most classical architecture for image segmentation using DL. The segmentation model is not generated from scratch; it uses the feature extractor of the classifier model of stage 1 as the encoder. Typically, the proposed models in the literature are trained with random knowledge parameters meaning that the model must learn what feature extractor maps are helpful to classify the images correctly; it takes more training time and could be more challenging to achieve good results.
The segmentation models, shown in Figure 4, are trained to segment a specific lesion, but not all the parameters are trained.
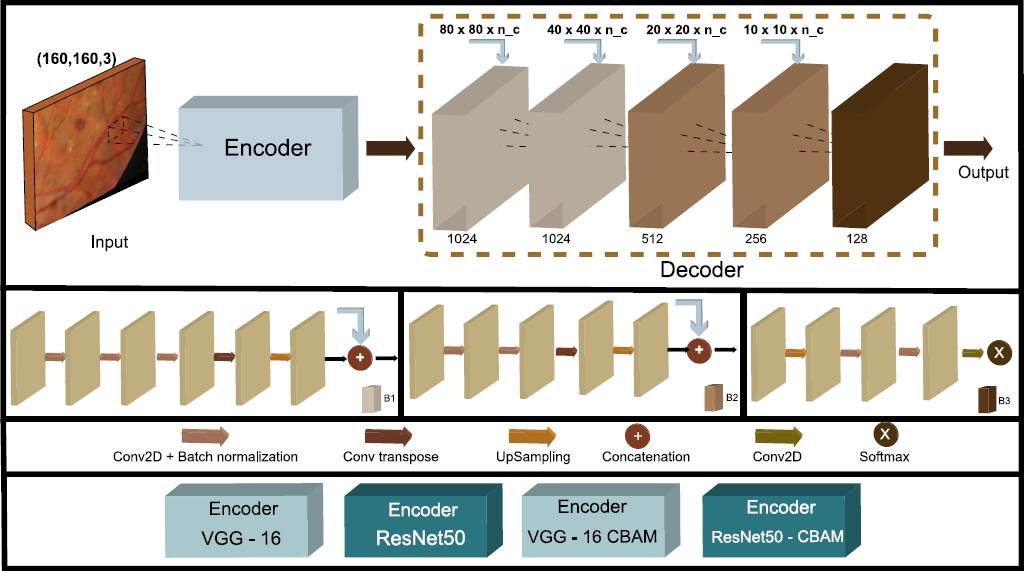
Figure 4 The proposed encoder-decoder model to segment the patch images consists of the feature extractor of the classifiers models as the encoder, with a residual operation at the end of each block.
As we mentioned earlier, in stage 1, the encoder generates the knowledge to identify how a lesion looks, so it is unnecessary to train the encoder parameters again, so we freeze them. The decoder parameters are trained to separately identify exudates, hemorrhages, and microaneurysms. We use three different datasets, one for each injury.
Software and Hardware
The models presented in this work were implemented in python 3 with TensorFlow and Keras libraries. OpenCV was used in the preprocessing part.
The classification and segmentation stages were trained in Colab with a GPU accelerator. The code is available in https://github.com/MetaDown/RMIB-TL.
RESULTS AND DISCUSSION
We divide the results into two parts: the binary classification model and the segmentation task. The second part has three different metrics for each injury (exudates, hemorrhages, and microaneurysm).
The classifier model obtains the metrics shown in Table 1.
Table 1 Binary classification results, showing whether an image has a lesion or not.
| Model | Accuracy | Recall | Precision | Training time |
|---|---|---|---|---|
| VGG-16 | 87% | 92% | 80% | 24 hrs. |
| VGG-16 CBAM | 89% | 81% | 98% | 26 hrs. |
| RESNET 50 | 86.6% | 80.3% | 90% | 16 hrs. |
| RESNET 50 CBAM | 87.1% | 82% | 90.02% | 18 hrs. |
This model does not pretend to achieve the best performance; the main task is to generate the knowledge to generalize how a lesion looks in the retinal images.
The classifier model can detect if an image has or does not have a lesion, and it pays attention to the lesion's shape, color, or composition. The knowledge is transferred to the segmentation model to classify pixel by pixel, and then the output is rebuilt to get the original image shape. Figure 5 compares the model segmentation with the ground truth and the original input image to have a better idea of the results; the metrics could show high performance, but it is challenging to observe the actual result due to most of the image being black.

Figure 5 Exudates, hemorrhages, and microaneurysms segmentation results. Red pixels are false negatives, green pixels are false positives, yellow pixels represent true positives, and black pixels are true negatives.
Table 2 shows the performance of the four models, which have similar values, but the sensibility is the lower value of all. The accuracy or AUC metric could be misleading due to most of the pixels being black (No lesion presented). If we only pay attention to the accuracy or AUC metric, we are committing a mistake due to the pixel imbalance. We decide to compare the predictions directly with the ground truth to have a complete idea of the model performance, as shown in Figure 5. Microaneurysms are the most challenging lesions to segment; their shape and color could confuse other anatomical landmarks and other injuries. Metrics presented in other microaneurysms segmentation papers are high because the authors focused on improving the model in that specific task. Our proposed methodology focused on generalizing the model to achieve fast convergence in whatever assignment implies retinal images.
Table 2 Metrics results with the validation data.
| Author | Accuracy/ AUC/ F1 SCORE | Sensitivity | Specificity |
|---|---|---|---|
| Exudates | |||
| Zong et al. [21] | Accuracy: 96.38% | 96.14% | 97.14% |
| Wisaeng et al. [42] | Accuracy: 98.35% | 98.40% | 98.13% |
| VGG-16 | Accuracy: 98.1 % | 88.12% | 96.1 % |
| VGG-16 CBAM | Accuracy: 98.23% | 89.46% | 94.09% |
| RESNET 50 | Accuracy: 98.09% | 89.05% | 96.05% |
| RESNET 50 CBAM | Accuracy: 97.04% | 89.5% | 97.2% |
| Hemorrhages | |||
| Grinsven et al. [43] | AUC: 89.4% | 91.9% | 91.4% |
| Aziz et al. [19] | F1 Score 72.25% | 74% | 70% |
| VGG-16 | Accuracy: 92.1 % | 80.21% | 94 % |
| VGG-16 CBAM | Accuracy: 92.09% | 81.4% | 94.9% |
| RESNET 50 | Accuracy: 93.5% | 81.6% | 93.02% |
| RESNET 50 CBAM | Accuracy: 93.6% | 82.01% | 95.03% |
| Microaneurysms | |||
| Long et al. [18] | AUC: 87 % | 66.9 % | - |
| Kou et al. [29] | AUC: 99.99% | 91.9% | 93.6% |
| VGG-16 | Accuracy: 93.1 % | 73.13% | 95.1 % |
| VGG-16 CBAM | Accuracy: 95.04% | 74.6% | 96.9% |
| RESNET 50 | Accuracy: 95.69% | 70.1% | 97.8% |
| RESNET 50 CBAM | Accuracy: 96.2% | 77.7% | 98% |
The training time in the segmentation stage by lesion was about one epoch or 28 min, achieving the results shown previously We have excellent time training thanks to the TF applied in stage 1. The model doesn't need to fit the parameters from scratch.
If we only assess the segmenting accuracy, we could conclude that the metrics are very high. Nevertheless, this metric could be misleading since the imbalance present in retinal images is high. For example, the number of microaneurysms' pixels compared to the background pixels is very low. By showing the contrast between the actual and the predicted image, we can better understand the model's performance, Figure 5.
CONCLUSIONS
Training a model from scratch takes more time to fit the parameters until the excellent performance. TL is a powerful alternative to training models since it helps generalize faster than training from scratch. In this paper, using the knowledge learned in a binary classification, we proved that it is possible to perform a specific task like segmentation. The single requirement is a similar dataset as the main problem to solve.
Public datasets with segmenting masks are very limited because of the effort involved in preparing a single instance. This work proved that it is possible to take advantage of datasets created for detection/classification purposes to pre-train DL models to achieve better performance in segmentation tasks. The metrics achieved in our experiments are comparable to the state-of-the-art models and have the advantage of deploying a general methodology using a single fundus image database for the detection/segmentation of various retinal diseases achieving state-of-the-art results. This model could be in practice more valuable since it can be trained with a more realistic database containing a broad spectrum of conditions to detect/ segment illnesses without sacrificing performance.
Future work would be to apply the same methodology presented in this work to the new architectures named Transformers, given that they require much more examples than CNN's, and tasks like medical image prediction or classification need a large number of samples, as we could see in the presented work. The advantage of the Transformers is the attention that its model could pay to some specific image regions, converting the Transformers into a strong candidate to replace the conventional CNN's. But we can ask, could we apply TF from CNN to a Transformer achieving fast convergence?

