











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
Los sonidos del pulmón (LS, por sus siglas en inglés) y los sonidos del corazón (HS, por sus siglas en inglés) son parte de las señales generadas por el cuerpo humano, las cuales son utilizadas para propósito de diagnóstico médico. En la actualidad existen distintos niveles de atención médica [1], pero incluso los niveles básicos deben contar con cierta funcionalidad, lo que involucra al menos equipo básico como un estetoscopio, e incluso por normatividad una computadora para el expediente electrónico [2]. Por lo tanto, las nuevas normatividades favorecen el uso de sistemas que permiten auscultar de manera digital los sonidos del corazón y del pulmón. Desafortunadamente, los distintos sonidos del corazón y del pulmón se traslapan en un rango de frecuencia importante [3, 4, 5, 6, 7, 8,9], además de que el ruido ambiental durante las sesiones de auscultación dificulta aún más la tarea del diagnóstico.
Del párrafo anterior se remarcan algunos elementos importantes, el uso de computadora y estetoscopio, que son convenientes cuando se aplica reconocimiento de patrones como apoyo en la auscultación médica de primer contacto, para la detección de enfermedades respiratorias [1-6]. La auscultación del pecho con estetoscopio, constituye una herramienta portable de bajo costo ampliamente utilizada para detección de enfermedades respiratorias. Desafortunadamente, como ya se mencionó, el estetoscopio presenta varios retos, como el ruido ambiental y el traslape de los sonidos del corazón (HS) con los sonidos del pulmón (LS). Esto ha atraído la atención de la comunidad científica para enfocar esfuerzos en esta dirección. Existen técnicas con esquema jerárquico de Modelos Mesclados Gaussianos (GMM) y Maquinas de Soporte Vectorial (SVM), logrando resultados del 90% en sensitividad y especificidad [7].
Algunas aproximaciones son dirigidas a patologías que son problemáticas regionales, como el enfoque de extraer características acústicas de la tos y crepitaciones para reforzar vectores de coeficientes cepstrales en frecuencia Mel (MFCC) y la aplicación de ondículas [8]. Otros trabajos se dirigen al análisis y monitoreo de las ondas sonoras del corazón [9]. Estos evidencian que hay características que cambian durante stress cardiaco, y que el cambio es más significativo para personas con problemas cardiacos [9]. Otros autores mencionan que si bien el uso de estetoscopio es una herramienta de bajo costo, la agitación sobre todo en niños contamina los registros de los sonidos [10]. Por lo tanto, ellos proponen un esquema automatizado multi-banda para supresión de ruido, y mejorar la calidad de las señales de auscultación contra fuerte contaminación de fondo [10].
El estetoscopio puede también ser de utilidad en la detección de enfermedades del corazón, i.e., los sonidos de las válvulas aortica (A2) y pulmonar (P2) pueden diagnosticarse con la duración de la energía de frecuencias instantáneas (EIF), en particular el segundo sonido del corazón (S2) [11].
Además, proponen medir los parámetros relevantes identificando el inicio y fin de A2 y P2, pero incluyendo el diagnóstico de los EIFs de A2 y P2 examinados. Por lo tanto, este método conduce explícitamente a distinguir los S2s Normales/Anormales y los tipos de separación [11]. Otra alternativa para separar la señal S2 de HS, es una descomposición no estacionaria que permite lidiar con traslapes y energía modelando subcomponentes de S2 [12]. Los autores proponen el método de descomposición de vibración de Hilbert (HVD) [12]. Además, proponen localizar A2 y P2 usando un suavizado con la distribución de Wigner-Ville seguida por el método de reasignación. Finalmente, las separaciones son calculadas tomando las diferencias entre el promedio de los índices de tiempo de A2 y P2 [12].
Otros trabajos en segmentación de sonidos del corazón (HSS) para localizar el primer (S1) y segundo sonido del corazón (S2), aplican descomposición en modo ensamble empírico (EEMD) combinando curtosis y a la técnica le llaman HSS-EEMD/K [13]. Cuando se efectúan registros sobre el pecho, la interface tórax-micrófono genera una distorsión en la medición, con el propósito de restaurar el sonido del pulmón se propone una ecualización de sonidos crepitantes, para lo cual se aplican tonos entre 100 y 1200 Hz en la boca, midiéndolos en la boca y en el pecho, y generando curvas de atenuación promedio y un ecualizador de tiempo discreto en sonidos crepitantes [14]. Algunas técnicas no invasivas, se orientan en ayudar a regular la respiración mediante realidad virtual (VR), se apoyan en vectores MFCC con técnicas de segmentación. Además, usan detección de actividad de voz (VAD) y establecen umbrales lineales a la señal acústica de la respiración, capturándola y usando un micrófono para representar las diferencias entre inhalar y exhalar en el dominio de la frecuencia [15]. Otro enfoque para disminuir la interferencia de los sonidos del corazón en los sonidos del pulmón, es la localización de los componentes primarios de sonidos del corazón. Aquí, el análisis de espectro singular (SSA), es una técnica de análisis de series de tiempo que puede ser utilizada [16].
Un estudio sobre pérdida de paquetes en internet y su efecto en reconocimiento de voz y de locutor, desarrollada con una base de señales con 7080 registros de tres frases distintas leídas por 295 locutores, muestra el comportamiento basado en modelos acústicos con cúmulos como Modelos Mesclados Gaussianos (GMM) y modelos acústicos con Modelos Ocultos de Markov (HMM); estos últimos han mostrado fortaleza en la detección secuencias de eventos, i.e., palabras [17, 18]. Los resultados indican que los modelos acústicos con cúmulos son más sensibles a distorsión constante como codificación, pero menos a las pérdidas de segmentos de información; mientras que los modelos acústicos con HMM son más sensibles a perdida de información, pero menos a la distorsión constante [17-19]. Esto es de utilidad, si se piensa en zonas remotas o donde sería conveniente un escenario de internet, y que la información requiera codificarse o comprimirse para respaldarla o transmitirla. Además, los modelos HMM ya han demostrado su fortaleza en reconocimiento del habla, donde el significado depende de la secuencia de los fonemas [18], por lo cual se propone validar estas metodologías en sonidos del pulmón y del corazón, donde la secuencia de eventos es significativa.
Metodología y base de datos
Los extractores de características destacan las diferencias entre clases mediante valores, de tal manera que mejoran el proceso de clasificación. Una buena clasificación requiere de modelos robustos por lo cual es importante la mejor configuración y tamaño. En esta sección se revisan algunas metodologías visuales como dendrogramas y siluetas como un primer criterio del tamaño. Además, el Criterio de Información Bayesiana (BIC), es también aplicado como un intento para dimensionar los modelos. Posteriormente, se describen los modelos GMM y HMM con base para la clasificación.
Vectores MFCC
En MFCC, los sonidos son parametrizados, haciendo un preénfasis con filtros FIR, seguido por una ventana Hamming aplicada a cada trama de análisis [20, 21, 22, 23]. En este trabajo, se experimentó con ventanas Hamming de 30 ms y 15 ms de corrimiento en las señales HS, a las cuales se aplica la Transformada Rápida de Fourier (FFT); posteriormente, se obtiene el módulo y se multiplica por un banco de filtros donde sus rangos de frecuencia y frecuencias centrales están distribuidos en la escala de Mel. A esto le sigue una etapa de logaritmo de la energía obtenida de cada filtro y posteriormente la transformada inversa de Fourier. Dado que la energía será real y par, la transformada de Fourier inversa es un producto interno donde subsisten únicamente las partes pares, resultando igual a calcular la Transformada Discreta Cosenoidal (DCT). El resultado final es un vector de características llamado MFCC [15, 18, 24]
Vectores cuantílicos
Otro tipo de vectores acústicos son los Cuantiles, estos se basan en la función de distribución acumulativa (CDF). El Cuantíl qp de una variable aleatoria está definido como el número q más pequeño tal que la función de distribución acumulativa es mayor o igual a una probabilidad p, donde p se encuentra entre 0 < p < 1. Esto se puede definir con la función de densidad de probabilidad continua f (x) a través de la ecuación (1):
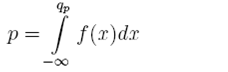 1
1
En caracterización acústica, la idea es encontrar un número dado de coeficientes Cuantílicos qp, por lo que se parte de la transformada inversa de la CDF. Específicamente, en señales acústicas como LS y HS es necesario realizar los cálculos en el límite de la estacionariedad; este límite está determinado por el tiempo en que los eventos conservan sus características estadísticas. Considerando una tasa de 15 respiraciones por minuto (normalmente el rango está entre 12-20 respiraciones por minuto para sujetos adultos saludables, y mucho mayor para niños pequeños). La estacionariedad de LS está relacionada con la duración de la fase de inspiración (~1.5 s.) y la fase de espiración (~2.5 s.) para la mayoría de las señales LS utilizadas. 400 ms por vector Cuartílico con corrimientos de 300 ms, nos arroja alrededor de 5 o más vectores por fase [25, 26]. En HS la duración promedio deS1esde0.1sa0.12 s, y S2 de 0.8 a 0.14 s [27]. Esto posibilita vectores MFCC de 30 ms con corrimientos de 20 ms.
En el cálculo de los cuartiles, el primer paso es la lectura de la señal, partiendo de archivos *.wav; posteriormente, se aplica la FFT. Cumpliendo con un principio básico para una función de densidad de probabilidad, la distribución espectral se normaliza en la Ecuación (2).
 2
2
La Ecuación (2) garantiza que la suma de la distribución de valores frecuenciales obtenidos a partir de la FFT será igual a 1, por lo cual N implica la normalización. Un ejemplo particular de Cuantiles son los Cuartiles, calculados aquí mediante la Ecuación (3), cuyos valores frecuenciales f 0.25, ..., f 0.75 corresponden a cada uno de los respectivos coeficientes Cuartílicos. El cálculo del último Cuantíl no es importante ya que siempre es igual a 1, lo que resulta en un vector de 3 dimensiones.
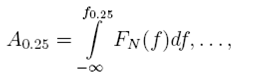 3
3
 4
4
Algorítmicamente, Ap se calcula mediante una suma iterativa para obtener el área y detectar los valores frecuenciales correspondientes a A = 0.25,..., A = 0.75. Si bien éste fue el caso de Cuartiles, el mismo principio puede aplicarse a Octiles u otro tipo de Cuantíl. Para una descripción más extensa, se puede revisar el trabajo [26].
Análisis de la cantidad de cúmulos para el desarrollo del modelo
Existen diferentes técnicas para determinar la cantidad de cúmulos existes en una clase. Específicamente, visualizar la cantidad de conglomerados o cúmulos en una clase es importante para dimensionar la configuración de un modelo. En esta sección se revisan algunas técnicas para visualizar la cantidad de cúmulos por clase. Las técnicas aquí discutidas son el análisis con dendrogramas, siluetas y BIC.
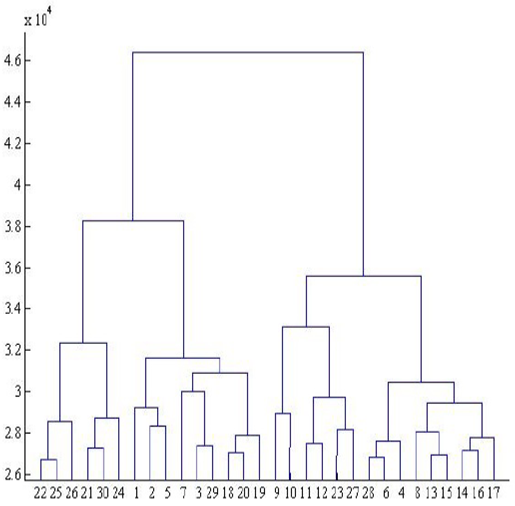
Un dendrograma es básicamente un diagrama de árbol invertido que se basa en la distancia de cada uno de los datos con respecto a todos los demás, y busca asociar aquellos que se encuentran más cerca entre sí (considerando una métrica de distancia, e.g. Euclidiana). Partiendo de esto, los datos se van asociando uno a uno hasta haber asociado la totalidad de los datos en cúmulos como se muestra en la Figura 1[28].
Las siluetas permiten representar el número de cúmulos existentes en una serie de tiempo. El índice de silueta es el indicador del número ideal de cúmulos en una clase. En nuestro estudio (Figura 2), se calcularon todos los vectores acústicos para todas las señales de una clase y se aplicaron las siluetas. Conforme se aproxima al valor a 1 en el eje x, indica que el número de cúmulos en el eje y es más representativo de la clase. Por el contrario, los datos del lado izquierdo presentan incertidumbre de pertenecer a la clase [29, 30].

Otra alternativa para determinar la cantidad de cúmulos en una clase, es aplicando el Criterio de Información Bayesiano (BIC), como se muestra en la Figura 3 . El modelo que tenga el valor más alto de BIC se considera el "mejor" modelo [31]. BIC es útil para estimar qué tan bien se ajustan el tipo de covarianza y numero de cúmulos a los datos, para nuestro caso en un GMM, pero además los vectores medias y ponderaciones [31].

Figura 3 Curvas de BIC que muestran distinto número de cúmulos por tipo de covarianza para clase LS Normal.
Este criterio se aproxima con:
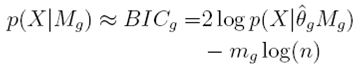 5
5
Donde X son las observaciones por clase, Mg
es el modelo, mg es el número" de parámetros independientes,
Si bien las Figura 1, 2 y 3 corresponden todos los vectores acústicos obtenidos para señales LS Normales, el procedimiento se puede efectuar para cada clase de LS, o HS.
Modelos mezclados Gaussianos (GMM)
Un modelo GMM es una tripleta A compuesta por las medias, covarianzas y ponderaciones. El modelado GMM se sirve del algoritmo EM para calcular las tripletas
 6
6
En la ecuación 5,
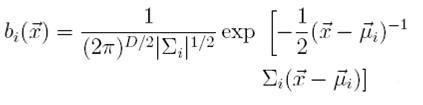 7
7
Modelos ocultos de Markov (HMM)
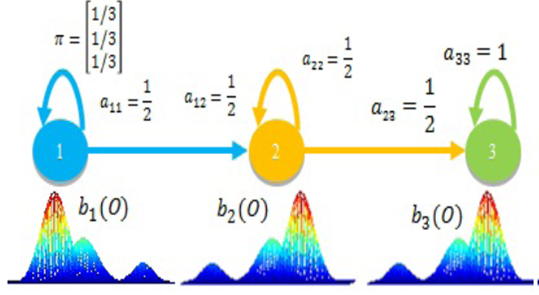
Un HMM es un autómata finito basado en estados que no son directamente observados. En nuestra metodología, cada estado en un HMM está constituido por un GMM, el cual modela las observaciones correspondientes a ese estado. Formalmente, un HMM es definido con los siguientes componentes [35]:
S = {S1, S2, ..., SN ) el conjunto finito de los posibles estados (ocultos);
La matriz de transiciones
La función de emisión de cada estado
En el caso de los experimentos de este estudio, las observaciones pueden ser vectores acústicos MFCC, Cuartiles u Octiles.
Al igual que en el caso de los modelos GMM, es convencional expresar los modelos HMM como tripletas λ = (A.,B,
El entrenamiento o aprendizaje de los parámetros HMM, dado un conjunto o secuencia de observaciones {Oi}, es típicamente efectuado aplicando el algoritmo Baum-Welch [35], el cual determina los parámetros maximizando la verosimilitud o probabilidad P(Oiλ). En la etapa de evaluación, se requiere calcular P(Ol\λ), dado el modelo λ y una secuencia O de observaciones; aquí se aplicó el algoritmo de forward-backward [35].
La arquitectura HMM fue de tipo izquierda-derecha (Bakis), como lo muestra la Figura 4. Aquí, el vector
Base de datos
El conjunto de señales HS utilizadas para los experimentos provienen de bases de datos que están disponibles para propósitos 0cadémicos o científicos [37, 38]. De ellas, se utilizó un conjunto de grabaciones HS, el cual consta de 21 señales HS, con una frecuencia de muestreo de 11025 Hz, una duración de entre 9 y 12 segundos, formato tipo *wav monoaural. Las señales originales fueron capturadas a una tasa de 44 kHz y 22 kHz, pero se sub-muestrearon a 11 kHz. De éstas señales se tomaron 7 HS Normales, 7 de Estenosis y 7 de Defecto Septal-Ventricular (VSD). Las señales utilizadas fueron particionadas para la etapa de entrenamiento y de evaluación aplicando Validación Cruzada (VC).
Con respecto a los experimentos de señales LS se utilizaron dos bases de datos: RALE y BDITM. RALE consiste en un conjunto de grabaciones *wav de sonidos LS adventicios y Normales, la cual fue desarrollada por la universidad de Winnipeg, Canadá. Dichas señales fueron filtradas con un pasa-altas a 7.5 Hz para suprimir cualquier offset DC mediante un filtro Butterworth de primer orden. Además, se aplica un filtro Butterworth pasa-bajas de octavo orden a 2.5 kHz para evitar traslape. Las señales en la base de datos están muestreadas a 11025 Hz. De RALE, sólo se utilizaron señales adventicias Crepitantes y Sibilantes (en inglés: Crackles y Wheeze).
La otra base de datos utilizada fue BDITM. Sus señales fueron obtenidas a partir de auscultaciones realizadas a 7 estudiantes del Instituto Tecnológico de Mexicali, todas con un estetoscopio digital. El rango de edad de los individuos fue de 21 a 26 años. Se realizaron de una a cuatro sesiones por sujeto, totalizando 13 sesiones. Cada sesión comprendió una auscultación traqueal, 8 puntos de auscultación en el pecho, y 8 puntos de auscultación en la espalda (es decir, 17 puntos en total), lo cual coincide con el protocolo de RALE [26]. El tamaño de muestra fue de 16 bits, en formato *wav monoaural. Adicionalmente, se les removió la componente en DC.
En LS también se utilizó validación cruzada para la evaluación. Esto consistió en dejar una señal para evaluación y el resto para el cálculo de los modelos. Pero la señal de evaluación cambió de manera iterativa, de modo que se efectuaron tantas evaluaciones como señales existentes en todas las clases. El corpus utilizado en LS consistió de 7 LS Normales de BDITM, así como 7 crepitantes y 7 sibilantes de RALE.
Por observaciones experimentales, se concluye que la duración en fases de las señales del repositorio de datos RALE y de BDITM está en el orden de 1.5 segundos para la inspiración y 2.5 para la espiración. Para HS, la fase S1 está alrededor de 0.1 a 0.12 Segundos; la fase S2 se encuentra entre 0.8 a 0.14 Segundos [27]. Considerando estos tiempos, los vectores Cuartílicos de 400 ms y corrimiento de 300 ms están en el rango de estacionariedad de las fases de la respiración. Por su parte, los vectores MFCC de 30 ms y corrimientos de 20 ms están en el rango de estacionariedad de S1 y S2.
Resultados
La Tabla 1 muestra los experimentos con el mejor valor de BIC con señales LS Normal, Crepitancias y sibilancias, donde el número de densidades corresponde a 10, 3 y 4 respectivamente. Para señales HS, los resultados se muestran en la Tabla 2, para el mejor valor de BIC. Para ambas tablas se aplicaron vectores Cuartílicos con tramas de 400 ms, corrimientos de 300 ms y una covarianza tipo completa.
Tabla 1: Número de cúmulos y respectivo tipo de covarianza que arrojan los mejores valores de BIC por clase LS, aplicando cuartiles

Tabla 2: Número de cúmulos y respectivo tipo de covarianza que arrojan los mejores valores de BIC por clase HS, aplicando cuartiles

En la evaluación de la eficiencia de HMM con señales LS y HS (mostrados en la Tabla 3 y Tabla 4), los vectores Octílicos y Cuartílicos fueron calculados sobre tramas de 400 ms y corrimientos de 300 ms (i.e., 100 ms de traslape). En lo que se respecta a vectores MFCC, éstos se calcularon sobre tramas de 30 ms con corrimientos de 15 ms y 12 coeficientes Cepstrales. En los experimentos no se efectuó reducción de dimensión.
Los valores de eficiencia mostrados a partir de la Tabla 3 están representados en términos de Probabilidad de Correcta Clasificación (PCC). Debido al limitado número de señales adventicias, se aplicó VC en las evaluaciones (tipo leave one-out) [34]. Esto consistió en 21 evaluaciones; es decir, 7 evaluaciones por cada clase. En cada evaluación se utiliza una señal de una de las tres clases para evaluar los tres modelos. A su vez, el modelo de clase se entrena con las señales restantes de su respectiva clase. Se efectuará una evaluación por cada una de las señales existentes en el corpus, (i.e. 21). Este proceso es el mismo para la evaluación de HS y LS.
En cada evaluación se considera un acierto si el clasificador identifica la señal correctamente con su clase, de otra manera, se toma como un error de clasificación. En total, se efectúan 21 evaluaciones con modelos HMM para señales LS, así como 21 evaluaciones para señales HS, siguiendo el mismo proceso para ambas.
La Tabla 4 muestra los mejores resultados en términos de eficiencia de PCC de los experimentos realizados con señales HS. En este caso, también se evaluó al clasificador HMM como en la Tabla 3, i.e. con VC. Sin embargo, las clases utilizadas en HS son:
Tabla 3: Mejores resultados con modelos HMM con 3 Gaussianas por estado, 3 estados y 3 iteraciones para todas las señales LS.
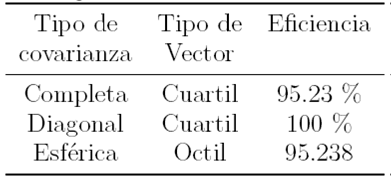
Tabla 4: Mejores resultados con modelos HMM con 3 Gaussianas por estado, 3 estados y 3 iteraciones para todas las señales HS.

Normales, estenosis y VSD. De la misma manera, se utilizaron 7 señales de cada clase, obteniendo una base de datos de 21 señales. Al final, se efectuaron 21 evaluaciones distintas, en donde los modelos HMM (tipo izquierda-derecha) fueron calculados con 3 estados (Ns = 3) y 3 Gaussianas (k = 3) por estado, para cada tipo de covarianza.
Para efectos de observar una tendencia en términos de eficiencia de clasificación variando el número de Gaussianas por estado y el número de estados, se efectuaron numerosos experimentos, pero aquí sólo se muestran configuraciones de 2 a 4 Gaussianas por estado y de dos a cuatro estados por modelo HMM. La Tabla 5 muestra estos experimentos para señales LS aplicando covarianza diagonal con las 21 señales de las 3 clases, resaltando el mejor resultado con 3 Gaussianas por estado y 3 estados. La Tabla 6 muestra un experimento similar, pero para señales HS, obteniendo también uno de los mejores resultados con la configuración de 3 Gaussianas por estado y 3 estados para el modelo HMM.
Tabla 5: Eficiencia en términos de PCC con distintos números de Gaussianas por estados y cantidad de estados, aplicando vectores Cuartílicos (400, 300) para señales LS.

Tabla 6: Eficiencia en términos de PCC con distintos números de Gaussianas por estados y cantidad de estados, aplicando vectores MFCC (30, 15) para señales HS.

A partir de los resultados de la Tabla 5 y la Tabla 6, se decidió adoptar la configuración 3-Gaussianas/estado y 3 estados por HMM para sucesivos experimentos.
Se puede observar en la Tabla 5, que se logró una eficiencia de hasta 100%, utilizando Cuartiles con una covarianza diagonal para señales LS. Por otro lado, en la Tabla 6 se logra hasta un 100% utilizando vectores MFCC con varias configuraciones.
La covarianza es importante para modelar la forma, volumen y orientación de los cúmulos de las clases. La covarianza completa es teóricamente más versátil, pero al ser completa, implica más parámetros que calcular y se requieren más datos en la etapa de entrenamiento. Sin embargo, cuando no se cuenta con estas condiciones, es más difícil lograr la convergencia de los modelos.
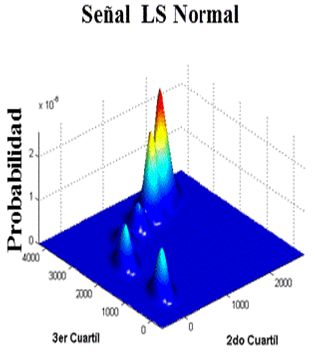
Las imágenes de la Figura 5, Figura 6 Figura 7 intentan visualizar la cantidad de cúmulos existentes por clase, aunque sólo se muestran los experimentos para la clase LS Normal.


Posteriormente, se efectúan experimentos con distintas configuraciones de número de Gaussianas por estado y cantidad de estados en un modelo HMM, observando resultados alentadores con HMM de 3 Gaussians por estado y 3 estados.
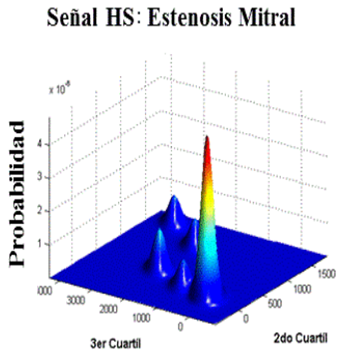
De manera complementaria, se pretendió visualizar la cantidad de cúmulos presentes en cada clase, por lo que se realizaron gráficas 3-dimensionales utilizando vectores Cuartílicos. De la Figura 5 a la Figura 10 se muestran los cúmulos de las clases LS Normal, sibilante y crepitante (respectivamente), donde cada clase está construida por todas laS señales de ésta. Cada clase cuenta con dos representaciones: la primera es el 1er y 2do cuartil con probabilidad en el eje z; mientras que la segunda es el 2de y 3er cuartil. De la Figura 11 a la Figura 16 se muestran los cúmulos de las clases HS Normal, regurgitación y estenosiS. Al igual que con LS, las gráficas se presentan con dos vistas de la misma señal.








Concerniente a señales LS Normales se observa una mayor cantidad de cúmulos con el 1er y 2do cuartil. Esto hace pensar que el mayor contenido de frecuencias y energía se encuentra en una región frecuencial correspondiente a los primeros dos cuartiles.
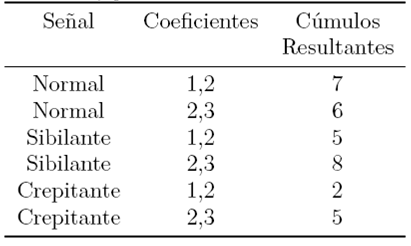
En señales LS sibilantes, se visualizan más cúmulos definidos aplicando el 2do y 3er cuartil, lo que implica que hay más contribución en frecuencias más altas que en la señal Normal. Un comentario similar se puede extender al caso de las crepitaciones, pero aquí hay pagamiento de Gaussianas con la aparición de contribuciones intermedias. La Tabla 7 resume la cantidad de cúmulos observados por cada clase y en términos de los pares de 1ro-2do y 2do-3er cuartil.
En señales HS aplicando cuartiles, la clase LS Normal exhibe más cúmulos con la combinación del 2do y 3er cuartil, lo que implica más variaciones en la parte superior de su espectro. En la clase regurgitación presenta más aglomeraciones con el 2do y 3er cuartil. Además, las aglomeraciones están bien definidas aunque es una la que destaca. La Estenosis presenta más cúmulos bien definidos en el 2er y 3er cuartil. El resumen de estas observaciones se muestra en la Tabla 8.

Las figuras de cúmulos para señales LS y HS con vectores MFCC no se presentan en este trabajo, pero los resultados se muestran en la Tabla 9 y Tabla 10.


En señales LS con MFCC, la cantidad de cúmulos observados no cambió entre la visualización de los pares 1er-2do coeficientes y 2do-3ero. Esto está relacionado con bandas de frecuencia del orden de 50 hasta 350 Hz, donde no existe mucha variabilidad entre LS Normales y adventicias. Con respecto a la Tabla 10, se trabajó con señales HS Normales y adventicias aplicando MFCC: se hizo un análisis utilizando del 1er hasta el 5to coeficiente MFCC (barriendo desde 50 hasta 500 Hz), que es la mayor parte del espectro donde se encuentran las señales HS (incluyendo los casos patológicos). Debido a la naturaleza de los vectores MFCC, se pueden observar menos cúmulos por par de coeficientes, ya que MFCC está compuesto por más coeficientes que los cuartiles [15, 26].
En el caso de señales HS, requerimos menos coeficientes MFCC que para señales LS debido al rango de frecuencias que forma su espectro.
Otra manera de representar la eficiencia de clasificación, en la práctica clínica [39], es en términos de tablas de contingencia. La Tabla 11 es una tabla de contingencia donde la señal de entrada es denotada por p y n, mientras la hipótesis del sistema está dada por P y N.
Tabla 11: Tabla de contingencia aplicando HMM de 3 estados y 3 Gaussianas por estado, para señales Normales HS-LS (p) vs HS-LS con patología (n), con cuartiles.

En estas evaluaciones, se trabajó con 14 señales LS Normales, así como 14 HS Normales. En cuanto a patologías, se contó con 7 sibilantes, 7 crepitantes, 7 regurgitaciones y 7 estenosis. En la tabla puede observarse un excelente compromiso del sistema para detectar correctamente a los verdaderos positivos (Normales) de los verdaderos negativos (Patologías).
Aparentemente, la configuración de 3 densidades por evento (o estado) y 3 estados por modelo HMM-GMM, resultó suficiente para modelar la mayoría de las clases.
Discusión
El análisis con BIC, siluetas y dendrogramas fue el punto de partida para construir un criterio antes de proponer una arquitectura final de reconocimiento HMM-GMM. En este trabajo se utilizó más la covarianza diagonal. En teoría, la covarianza completa es más versátil; sin embargo se requeriría contar con un número mayor de señales por clase, lo cual permitirá determinar el comportamiento de las distintas covarianzas.
A fin de formar un criterio preliminar para dimensionar el modelo, se hicieron pruebas visuales (siluetas, dendrograma y BIC). Desafortunadamente, no se contó con una gran cantidad de señales, lo que implica que con más datos la configuración de la arquitectura probablemente tenga que reconfigurarse. Sin embargo, los resultados sí dejan ver el potencial de los modelos HMM-GMM.
El gráfico de la Figura 3 muestra en el eje x la cantidad de cúmulos existentes en la clase y el valor de BIC en el eje y. BIC evalúa la probabilidad a-posteriori de la pertenencia de los datos con un modelo, pero a su vez penaliza la complejidad del modelo, como se observa en la Ecuación (4). Esto se evidencia con un punto de inflexión, el cual no se obtuvo en las curvas de BIC (Figura 3). Probablemente, para nuestros fines se requeriría una cantidad mayor de datos para obtener un punto de inflexión en las curvas BIC.
De la Figura 5 a Figura 16, se muestra la cantidad de cúmulos por clase en términos de pares de coeficientes. Si bien las cantidades no corresponden a las de los modelos experimentados, si está en el rango, lo que evita considerar arquitecturas HMM-GMM muy alejadas de las calculadas.
Los sonidos LS son parecidos a los fonemas /s/ o /f/, mientras que los HS están más relacionados con fonemas con frecuencias más definidas. En la literatura los sonidos HS se referencian como 'lub-dub'. MFCC fue concebido a partir del paradigma del funcionamiento del oído humano, el cual está relacionado con bandas a las cuales es sensible la audición humana [15, 40, 41]. Por tal motivo, los vectores MFCC podrían ser más aptos para el reconocimiento de HS.
Los modelos HMM-GMM son muy eficientes en señales acústicas, habiendo tenido un amplio éxito en señales del habla o reconocimiento de voz [17, 19, 41]. Además, las señales utilizadas por clase son de buena calidad, salvo las de BDITM que fueron colectadas en condiciones normales de un consultorio de atención médica primaria. De hecho, considerando la poca variedad de clases, facilita la tarea de los modelos HMM-GMM en clasificación, y dados los resultados de la Tabla 11, se observa que tienen gran potencial para este tipo de patrones.
Conclusión
Se efectuó un análisis de cúmulos y tamaño de modelo con siluetas, dendrogramas y BIC. Si bien no fue concluyente, resultó de utilidad para proponer una arquitectura HMM-GMM para clasificar señales LS y HS. En dicha arquitectura se aplicaron vectores Octílicos, Cuartílicos y MFCC, logrando hasta el 100 % de eficiencia de clasificación en LS y HS. El tipo de covarianza utilizada impactó el cálculo de un modelo GMM óptimo, que a su vez representó los estados en el modelo HMM. En términos de eficiencia, los mejores casos arrojaron 3 densidades por modelo GMM, en modelos de 3 estados, como una arquitectura genérica para cada una de las clases. Invariablemente, HS y LS presentan diferentes constituciones en términos de cúmulos entre sus clases Normales y Anormales.
Los modelos HMM-GMM mostraron su potencial para clasificación tanto para LS como HS; sin embargo, para validar una arquitectura genérica sería recomendable contar con un corpus extenso de registros normales y anormales para reconfigurar una arquitectura definitiva.
En un futuro sería interesante extender la clasificación a enfermedades definidas y a sectores específicos de la población local, ya que algunos sectores están más expuestos a contaminación y al clima que otros. Adicionalmente, sería conveniente incluir otro tipo de factores, tales como medidas de flujo de la respiración, con el fin de valorar su impacto en el diagnóstico de enfermedades específicas.

