










Services on Demand
Journal
Article
 text in
text in  English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkInvestigación bibliotecológica
On-line version ISSN 2448-8321Print version ISSN 0187-358X
Investig. bibl vol.28 n.62 Ciudad de México Jan./Apr. 2014
Article
Rebroadcasting of bibliographic catalogues in MARC-XML format
1Universidad Complutense de Madrid,España. manuel.blazquez@pdi.ucm.es
By using MARC-XML to modify the RSS code format, the technique habitually used by the media to rebroadcast news, bibliographical catalogues can also be re-disseminated. Among other things, this procedure offers the advantages of greater dissemination of collections, the possibility of sharing catalogues with other libraries, and allowing users to read and download catalogues. Researchers performed an array of trials to measure the building and recovery times for such bibliographical collections, while determining the sort of applications and functions needed to control these files. These experiences allow researchers to conclude that it is possible to generate, transmit and retrieve bibliographical catalogues using content syndication practices and methods.
Keywords: Content syndication; MARC-XML; Transmission of bibliographic records; Bibliographic syndication channels
Keywords: Content syndication; MARC-XML; Transmission of bibliographic records; Bibliographic syndication channels
La técnica de redifusión de noticias habitualmente empleada en los medios de comunicación social puede ser utilizada en el contexto de los catálogos bibliográficos, modificando su formato de codificación RSS por MARC-XML. Las ventajas que se desprenden de este uso son una mayor difusión de los fondos, la posibilidad de compartir los catálogos con terceras bibliotecas y permitirles a los usuarios la descarga y lectura de éstos. Para lograrlo se han llevado a cabo diversas pruebas que miden el tiempo de creación y recuperación de tales colecciones bibliográficas. Por otro lado se determina qué tipo de programas se necesitan para operar con dichos archivos y cuál es su funcionamiento. Como resultado de estas experiencias se concluye que es factible generar, transmitir y recuperar catálogos bibliográficos mediante técnicas inspiradas en la sindicación de contenidos.
Palabras clave: Redifusión de contenidos; MARC-XML; Transmisión de registros bibliográficos; Canales de sindicación bibliográficos
Introduction
Online bibliographic catalogues are basic tools in any information and documentation unit. The services commonly offered to the user range from the export of titles consulted for bibliographic management uses, their social labeling, referencing in new scientific works, subsequent consultation, and access to and retrieval of full texts. One of the challenges arising from the ongoing evolution of catalogues is to provide greater dissemination of the catalogues so that these are eventually evenly shared in their entirety with users at no cost. This goal can be achieved by converting bibliographic catalogues to MARC-XML format and their treatment using parser and XML-based structural analyzer programs.
The transfer of bibliographic records via http using MARC-XML files can be based on content syndication or association techniques, as suggested by Blázquez Ochando (2010: 228-392). This doctoral dissertation submits that content syndication techniques, first used in re-broadcasting news in social media, could be used to transmit and recover bibliographic catalogues completely or partially, something that is now underway in the Digital Library of Munich only a year after its publication (Münchener Digitalisierungszentrum Digitale Bibliothek, 2011). Another early experience demonstrating the interest of information centers in adopting MARC-XML as a standard is the doctoral dissertation catalogue initiative of the University of Seville, which allows export and free download of its records in this format (Universidad de Sevilla, 2011).
In the field of Documentation, the most commonly used syndication application consists of the creation of general information channels, the implementation of bibliographic alert services (1), re-dissemination of journal articles and contents (Rodríguez Gairín et al., 2006) or the grouping of consultations in personalized syndication channels (PUBMED, 2011; Dolan, 2011), where the field of bio-sanitary document management is particularly active.
This paper discusses how to create bibliographical catalogues in MARC-XML format for subsequent retrieval by means of parser programs similar to those used by readers of syndication channels. To verify this process, researchers have provided a trial to show the viability of the transmission of the bibliographic catalogues through the internet and subsequent execution of the programs in the OrangeUP platform set up for this purpose (Blázquez Ochando, 2011).
Generation of MARC-XML catalogues
Generating catalogues in MARC-XML format (Library of Congress, 2011) requires the availability of bibliographic records in a data base for complete management and treatment. Otherwise, it will be necessary to migrate the information. One method of executing the transfer of the bibliographic catalogue is by exporting it in CSV format, a frequent option used by most bibliographic managers and librarians. For the purposes of this study, we have put together diverse collections ranging from one thousand to one million records from the Library of Congress (Blázquez Ochando, 2010: 299). These collections are shown in Table 1.
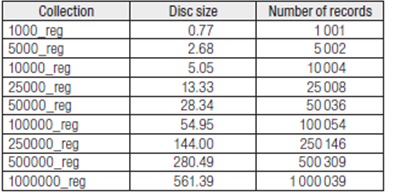
By taking this step and by means of a PHP-based export program, a MARC-XML catalogue corresponding to the initial bibliographic catalogue can be generated (Blázquez Ochando, 2010: 268-271). To this end, the basic structure of the record is reproduced as are the record node and its dependents as many times as there are tomes and volumes in the collection in question (see Table 2).

The intervening factor in the process described above is the volume of codifications of the bibliographic records and associated descriptive extension. With regard to the catalogue extension, it should be noted that for collection sizes of 5000+ records the file size is more than 2 MB. This fact, which has also been subsequently contrasted and verified by IndexData (Schafroth, 2010), implies that generation of the corresponding catalogue in a single XML file multiples the size; since it includes characters devoted to its label making treatment, visualization and later retrieval difficult, something that was stated previously (Blázquez Ochando, 2010: 257-258).
The solution to this problem is to create an XML file for each one thousand records, which generally do not surpass 1 Mb in size. This makes file management easier. This approach means that large collections shall require many XML files, which encumbers access to the information in the catalogue. This difficulty can be overcome by employing an OPML file to group the files, as specified for this purpose by Winer (2007). In this way it is possible to retrieve complete catalogue in block (Blázquez Ochando, 2010: 278).
Catalogue retrieval in MARC-XML
The method for MARC-XML format catalogue retrieval entails the use of parser programs capable of analyzing the structure of the XML file and transferring the information for use, whether for display, filtration or retrieval and storage in a data base. This is definitely a process that any aggregator or syndicated reader commonly executes, transposed to the context of bibliographical contents and especially relevant to the field of Documentation.
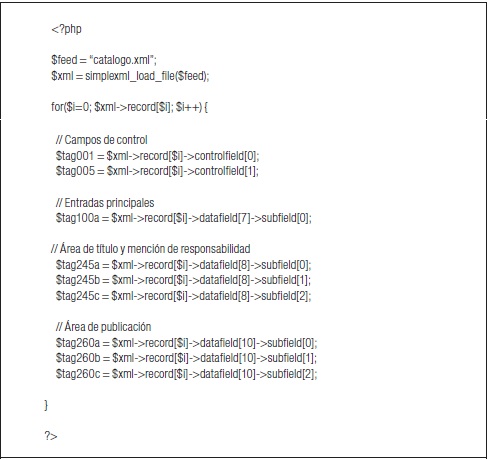
The example appearing in Table 3 below is a parser program created in PHP capable of reading and recovering a bibliographic catalogue coded in MARC-XML, such as that shown in Table 4. The key to its operation lies in the simplexml_load_file() function, available in PHP GROUP (2011a). As specified, this function interprets any XML-based file and converts it into an object that can be accessed in all of its parts by means of DOM (PHP GROUP, 2011b).

To verify this end, once the catalogue is loaded in the variable $xml, one can simply print to screen, using the print_r($xml) function, in order to obtain a result similar to that shown in Figure 1.

Figure1. Bibliographic catalogue edition and publication sequence: http://mblazquez.es/documents/orange-process.jpg
To retrieve each bibliographic record, one must run all the <record> nodes of the MARC-XML catalogue. This task is executed by means of a for loop whose execution parameter is exactly the total number of XML file entries to be processed. Within this execution, one can discern how the MARC format encoded labels, stored in variables that have their exact names, are selected. For example, the label 100$a, which represents the lead author, is stored in variable $tag100a and corresponds to the node <datafield> placed in position number 7, whose value, in turn, is stored in label <subfield>. One can observe that in order to reach the value contained in these labels, the selection route from beginning to end must be indicated, starting with the matrix variable $xml, which as has been previously explained contains the entire catalogue content.
Trials with marc-xml bibliographic catalogues
To confirm the operation of the method of generating and retrieving the MARC-XML format bibliographic catalogues, a sync program was developed (Blázquez Ochando, 2010: 235-310), which allows execution of such operations while providing the execution times and the determining the success or failure of the experiment. The results obtained in Table 5 demonstrate that the automatic generation of the catalogues takes longer than 15 minutes when the collection in question contains one million records.
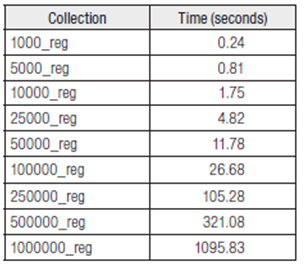
Even at that the values obtained with relatively large collections of 50,000 records come in at around 10 seconds. These data stand in contrast to those obtained in the catalogue recovery process. This makes sense because the information transfer operation only requires reading and writing from a known information source, i.e., the data base.
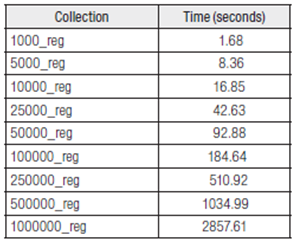
When the process is reversed, the parser program must read the XML file, generate an object that is accessible in DOM, select the route in which the information is found, display it on screen and, finally, insert it into the data base.
As shown in Table 6, this routine considerably increases the execution time and significantly encumbers the work, with times above three minutes, when processing large collections approaching 100,000 records.
Edition and publication test of MARC-XML and RSS catalogues
In order to identify the differences between the development of MARC-XML and RSS format bibliographic catalogues, an online edition and publication test was carried out. 1 Its operation responds to a chain of clearly delimited processes (Figure 1).
The OrangeUP system has been specifically developed to handle syndication channels and to demonstrate that regardless of format used to describe the bibliographic records or the information contents all of the XML-based formats will have the same transmission, sharing, edition, publication and reading properties. Figure 1 shows the first steps of the creation of bibliographic catalogues in either MARC-XML or RSS by means of the same method of edition and formularies. Keeping its key code, the bibliographic records can be edited as per the MARC21 bibliographic description standards. Each bibliographic record is assigned a bibliographic syndication channel.In all events, the records created are practicable and modifiable, i.e., their meta-information, bibliographic fields, category, classification, title areas and mention of party responsible, etc. can be edited. During this process, the program stores the information in the MySQL data base for subsequent publication and encoding in files whose MARC-XML or RSS formats shall be selected by the user.
Subsequently, the registered user can employ the test bench function. This is a code editor for testing parser programs, which allows testing of codes such as the one summarized in Table 3 and executing them in such a way that the results are displayed on the same screen. The result of this process is the complete display of all of the bibliographical records described in the catalogue in the same way the respective items would be displayed by a syndication channel reader. As such, the parallel between the technique of re-dissemination or syndication of contents and the re-dissemination of bibliographical catalogues is undeniable, though there are differences in encoding and evident bias favoring RSS over MARC-XML. To observe the process of edition and publication of the program, see the original video demonstration using OrangeUp, available at: http://youtu.be/kS2WiXuRFpM
Conclusions
Bibliographical catalogues can be retrieved in MARC-XML format using parser programs similar to those used to read syndication channels. This allows bibliographic catalogues to be shared between libraries using the methodology previously cited.
Bibliographic catalogue reading and retrieval times are greater than those needed for their creation, because of two key factors: on one hand, the MARC-XML encoding is considerably longer than that for RSS; and, on the other, because of the length of the catalogue document descriptions.
The use of syndication techniques for bibliographic catalogues, as currently in place the Digital Library of Munich, is becoming more and more common. In other cases, export of bibliographic records in MARC-XML format for sharing and reuse by third parties is already a reality. Such is the case of the doctoral dissertation catalogue of the University of Seville. This seems to indicate the initial phase of the implementation of such systems, and a new wave of interest in experimentation in the library and document management milieu.
REFERENCES
ANU Library: new titles (2011), disponible en: ANU Library: new titles (2011), disponible en: http://anulib.anu.edu.au/about/news/newbooks/ (Fecha de consulta: 12 de septiembre del 2011). [ Links ]
Blázquez Ochando, M. (2010), Aplicaciones de la sindicación para la gestión de catálogos bibliográficos, Madrid: Universidad Complutense. [ Links ]
Blázquez Ochando, M. (2011), OrangeUp, disponible en: (2011), OrangeUp, disponible en: http://mblazquez.es/testbench/orangeup/ (Fecha de consulta: 17 de marzo del 2011). [ Links ]
Dolan, F. (2011), MedWorm, disponible en: (2011), MedWorm, disponible en: http://www.medworm.com/ (Fecha de consulta: 15 de marzo del 2011). [ Links ]
Library of Congress (2011), MARC21 XML Schema, disponible en: Library of Congress (2011), MARC21 XML Schema, disponible en: http://www.loc.gov/standards/marcxml/ (Fecha de consulta: 17 de septiembre del 2011). [ Links ]
Münchener Digitalisierungszentrum Digitale Bibliothek (2011), disponible en: Münchener Digitalisierungszentrum Digitale Bibliothek (2011), disponible en: http://www.digital-collections.de/index.html?c=rss&l=en (Fecha de consulta: 12 de septiembre del 2011). [ Links ]
PHP GROUP (2011a), simplexml_load_file, disponible en: PHP GROUP (2011a), simplexml_load_file, disponible en: http://php.net/manual/es/function.simplexml-load-file.php (Fecha de consulta: 26 de septiembre del 2011. [ Links ]
PHP GROUP (2011b), Document Object Model, disponible en: PHP GROUP (2011b), Document Object Model, disponible en: http://php.net/manual/es/book.dom.php (Fecha de consulta: 26 de septiembre del 2011). [ Links ]
PUBMED (2011), disponible en: PUBMED (2011), disponible en: http://www.ncbi.nlm.nih.gov/pubmed (Fecha de consulta: 15 de marzo del 2011). [ Links ]
Rodríguez Gairín, J.M. et al. (2006), "Sindicación de contenidos en un portal de revistas: Temaria", en El Profesional de la Información, 15 (3), pp. 214-221. [ Links ]
Schafroth, D. (2010), Turbomarc, faster XML for MARC records, disponible en: (2010), Turbomarc, faster XML for MARC records, disponible en: https://www.indexdata.com/blog/2010/05/turbomarc-faster-xmlmarc-records (Fecha de consulta: 18 de marzo del 2011). [ Links ]
Universidad de Sevilla (2011), Tesis Doctorales: fondos digitalizados, disponible en: Universidad de Sevilla (2011), Tesis Doctorales: fondos digitalizados, disponible en: http://fondosdigitales.us.es/tesis/ (Fecha de consulta: 17 de marzo del 2011). [ Links ]
Winer, D. (2007), OPML 2.0, disponible en: 0, disponible en: http://www.opml.org/spec2 (Fecha de consulta: 17 de marzo del 2011). [ Links ]
1See OrangeUP demonstration program available at: http://www.mblazquez.es/testbench/orangeup/
Received: May 12, 2013; Accepted: August 07, 2013
 This is an open-access article distributed under the terms of the Creative Commons Attribution License
This is an open-access article distributed under the terms of the Creative Commons Attribution License
