











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
La modelación de curvas de mortalidad es bastante antigua y se tiene como primera propuesta la de Moivre (1725). Posteriormente son de destacar las elaboradas por Gompertz (1825; 1860; 1862) y Makeham (1867; 1890). Asimismo, se fueron afinando las propuestas de modelaje de la mortalidad donde sobresale la incorporación de patrones cada vez más específicos y característicos de las distintas etapas de la vida humana, como se hace originalmente en Thiele (1871), idea que se retoma tiempo después en los modelos desarrollados por Heligman y Pollard (1980). En Forfar (2006) se hace un amplio recorrido cronológico de las diversas propuestas existentes en la literatura en cuanto a curvas (leyes) de mortalidad.
El modelo de Heligman y Pollard (HP) (1980), además de ser útil para la graduación, entre varias aplicaciones, también ha sido empleado para analizar o predecir el comportamiento de la mortalidad futura. Por ejemplo, en Felipe, Guillen y Pérez-Marín (2002) se realiza un estudio de la evolución de sus parámetros con modelos ARIMA y se pronostica su comportamiento para la población española. También se ha recurrido al modelo para detectar los cambios en la mortalidad en edades jóvenes, la joroba, debido a los efectos del VIH en África (Sharrow, Clark, Collinson, Kahn y Tollman, 2013). En Hartmann (1987) y Yuen (1997) se lleva a cabo una comparación entre diferentes modelos para ajustar la mortalidad y se concluye que Heligman y Pollard (1980) proporciona un mejor ajuste. Por otra parte, Kostaki (1991), Irnawati (2008) y Syahmi, Md Yusuf, Suhaylah y Yazis (2015) han utilizado esta herramienta para crear tablas de mortalidad a partir de datos agregados.
El modelo de HP tiene diferentes formas de ser estimado: una posibilidad es por medio de optimización no lineal, donde es fundamental utilizar valores iniciales, y otra es a través de técnicas bayesianas. Se considera que, en ambos casos, se requiere del conocimiento de herramientas teóricas que permitan su estimación con el fin de facilitar la convergencia del modelo, al igual que tener acotados intervalos y la distribución para los parámetros. Por ejemplo, en Sharrow, Clark, Collinson, Kahn y Tollman (2013) se propone el uso de distribuciones uniformes continuas para sus parámetros de la siguiente manera: A ~ U [0,0.25 ], B y C ~ U [0,1 ], D ~ U [0,0.25 ], E ~ U [0,20 ], F ~ U [15,55 ], G ~ U [0,0.01 ] y H ~ U [1,1.5 ]. La relevancia de los rangos de referencia de dichos parámetros resulta orientativa para intentar la estimación del modelo, sin embargo, puede no resultar atractivo por las exigencias técnicas que más adelante se implican.
En este trabajo se tienen por objetivos: 1) ilustrar la aplicación de un método para estimar tendencias con suavizamiento controlado (método propuesto por Guerrero, 2008), es decir, en el presente contexto, curvas de mortalidad donde se impone la suavidad por medio de un índice (o porcentaje); así como 2) proponer un método para medir la suavidad inducida, sujeta a funciones de pérdida, ejemplificado para estimaciones previas citadas en la literatura con el modelo HP. El índice de suavizamiento se sustenta en el llamado filtro de Hodrick y Prescott (1997), mismo que ha tomado una gran aceptación en el campo de la economía en el marco de series de tiempo. En este documento se puede concebir a los valores de las q x como una serie de tiempo.
Se tienen entonces como preguntas centrales de investigación: ¿desde la perspectiva de suavizamiento, con una técnica no paramétrica, es posible aproximar de mejor manera curvas de mortalidad en comparación con otros métodos?, ¿qué tan factible es medir la suavidad inducida en curvas de mortalidad estimadas con el modelo HP, para que con esa información se pueda orientar en cómo poder fijar la suavidad y luego se puedan estimar curvas de mortalidad en general?, y ¿resulta satisfactoria la propuesta para todas las edades de las curvas de mortalidad?
Es importante reconocer que en la propuesta existen problemas al aproximar la curva de HP en las colas, esto es, no se logra un ajuste “idóneo” tanto al inicio como al final de la curva de mortalidad, como se verá más adelante; sin embargo, para edades centrales es notable su potencial. Adicionalmente, se entiende en el trabajo como términos equivalentes la tendencia en estadística y la curva de mortalidad en demografía. Se emplean estimaciones provenientes de HP (1980), Kostaki (1991), Felipe, Guillen y Pérez-Marín (2002) y Jos (2014).
Se considera que la relevancia de este trabajo radica en que algún analista interesado en estimar curvas de mortalidad, con no mucha holgura de tiempo y con una formación estándar en la profesión demográfica, pueda realizarlo de una manera sencilla y expedita, en términos de la aproximación aquí propuesta, con los beneficios agregados que más abajo se enuncian. En principio, este tipo de herramientas no sólo es útil para analizar series económicas, sino que por su objetividad, que se verifica en este trabajo, también es útil en tópicos demográficos. Como se menciona en Guerrero (2008), la necesidad de estimar la tendencia para fines informativos de una serie de tiempo es de suma importancia para cualquier tipo de análisis, y puede ser apoyada desde la gráfica de los datos.
El trabajo está organizado como sigue. En la primera sección (Introducción) se describe el tema de investigación. En la segunda se enmarca el modelo HP, así como algunas de sus variantes. En la tercera se aborda la estimación de tendencias de mortalidad con suavizamiento controlado. En el cuarto apartado se exponen ejemplos y comparativos en la aplicación del llamado índice de suavidad, con estimaciones previamente elaboradas, y se señala la manera de aproximar las curvas generadas mediante HP de los artículos seleccionados. Posteriormente se exponen aplicaciones diversas con la presentación de los patrones observados en funciones de pérdida, y el comportamiento del parámetro de suavizamiento, donde se hace una ilustración de las aproximaciones y se presentan cuadros resumen de los resultados obtenidos. Finalmente se señalan las principales conclusiones a partir de los hallazgos encontrados en el presente trabajo.
El modelo de Heligman y Pollard (HP)
El modelo HP es utilizado en la literatura demográfica para estimar la mortalidad de una población. En el artículo seminal de 1980 se presentan distintas expresiones matemáticas que generan las correspondientes curvas de mortalidad basadas en la siguiente propuesta:
donde q
x
es la probabilidad de morir durante un año de una persona a edad x
De la ecuación previa, en Heligman y Pollard (1980) se proponen otras expresiones de la curva de mortalidad, que se presentan de manera reducida y en donde sólo se expresa el valor de q x . Sus expresiones son las siguientes:
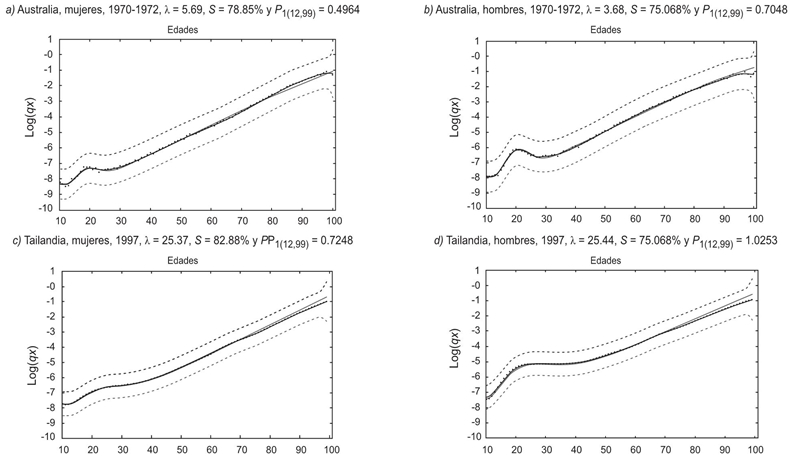
Las ecuaciones anteriores muestran una diferencia en el tercer sumando. Como lo mencionan Heligman y Pollard (1980), ambas formas presentan un mejor ajuste en la joroba de accidentes y en edades avanzadas. En este trabajo se utiliza la respectiva expresión, en función de lo que fue elegido en cada una de las fuentes bibliográficas seleccionadas y consultadas para este fin. Algunos ejemplos de las curvas estimadas con sus valores observados de q x , en escala de logaritmo natural, se muestran en la Gráfica 1.

De acuerdo con Dellaportas, Smith y Stavropoulos (2001), Debón, Montes y Sala (2006) y Congdon (1993), el modelo HP tiene algunos inconvenientes: los errores estándar para las estimaciones de los parámetros son muy grandes, ya que cuentan con una alta correlación entre ellos; se tienen dificultades cuando se estima el parámetro K, que en muchas ocasiones resulta insignificante y que imposibilita la estimación del modelo; no siempre se logra la convergencia en rutinas iterativas de estimación no lineal; las correlaciones entre los parámetros del modelo HP son altas, especialmente entre A y B, A y C, B y C, G y H, en ambos sexos, así como entre G y K, H y K para hombres. Todas estas desventajas que presenta el modelo HP son significativamente superadas con la propuesta que se realiza en el presente documento.
Estimación de curvas de mortalidad con suavizamiento controlado
Al analizar series de tiempo se puede llegar a distintas formas de interpretar los datos. Una de ellas es considerar una serie de tiempo cualquiera, como la suma de una tendencia no observable, pero sí subyacente, que varía dinámicamente a lo largo del tiempo, adherida a un componente aleatorio, es decir,
donde τ t es la tendencia, η t es el componente aleatorio y N el número de datos.
Existen otras técnicas para calcular la tendencia de una serie de tiempo, como pueden ser, por ejemplo, promedios móviles, suavizamiento exponencial, regresión no paramétrica, entre varias. Todos los métodos anteriores funcionan aplicando filtros a las series
El llamado filtro de Whittaker (1923) ha tenido extensiones como las elaboradas por Knorr (1984) y Nocon y Scott (2012). Con los parámetros de orden de diferenciación d = 2 y la matriz de pesos idénticos en las observaciones, W = I, el método de Whittaker se utilizó por Hodrick y Prescott (1997) para estimar tendencias y ciclos económicos y se le conoce en el ámbito de la econometría como filtro de Hodrick y Prescott. En él se reduce gradualmente el componente aleatorio, induciendo a una suavidad, y a través de éste se estiman valores suavizados que representan mejor a los valores verdaderos no observables. En el filtro se considera además un parámetro de suavizamiento, λ, mismo que simultáneamente pondera tanto la bondad del ajuste como la suavidad. En este filtro se sustenta el método de Guerrero (2008). Es importante mencionar que, en general, cuando se realizan estimaciones de manera automática, es decir, utilizando herramientas implementadas en los softwares estadísticos, no se puede decidir qué valor otorgarle al parámetro λ; por lo tanto, se ignora la suavidad alcanzada y no se tienen elementos válidos, desde el punto de vista estadístico, para hacer comparativos con otras estimaciones.
El filtro es relativamente sencillo de aplicar para cualquier serie de datos y, como lo menciona y demuestra Guerrero (2008), produce resultados idénticos a otros métodos de suavizamiento. En Kaiser y Maravall (2001) se proporciona una explicación más detallada de la teoría matemática detrás del filtro. La estructura del filtro Hodrick y Prescott proviene de la siguiente expresión:
donde λ es el parámetro que penaliza la ausencia de suavidad. El primer término tiene como propósito el ajuste de la tendencia con los datos observados, en tanto que el segundo a la inducción de la suavidad. Puede apreciarse que cuando
donde
La solución al problema que se propone es alcanzable tras aplicar mínimos cuadrados generalizados, con lo que se obtiene el resultado
La serie
Dada la solución anterior a la tendencia
en donde tr(.) representa la traza de la matriz. Puede notarse que la suavidad no depende de los datos, sino exclusivamente del valor del parámetro λ y del número total de datos N. De hecho, a mayor cantidad de datos se requerirá un índice más alto para suavizar. Es claro que cuando
Una crítica que existe a esta propuesta de índice radica en cómo justificar la imposición de determinado porcentaje de suavidad, aun cuando se argumenta que es relevante para hacer comparativos. Por ejemplo, en Alba y Gómez (2012) se abona al respecto desde la perspectiva bayesiana y se propone un método para tal fin. En este trabajo, justamente, la propuesta para imponer la suavidad pertinente se resume en realizar mediciones de suavidades inducidas en aplicaciones previamente construidas. Otras opciones podrían ser ejercicios de simulación o a través de indicadores de cobertura. Para esto último, dada una determinada suavidad impuesta, el indicador de cobertura podría indicar cuántas observaciones están contenidas dentro del intervalo de estimación e imponer aquella en la que se tengan coberturas de órdenes específicos como: 90, 95 o 99%.
Desde una óptica usual, para suavizar datos, se podría obtener un valor del parámetro de suavizamiento λ óptimo mediante criterios automáticos como el Akaike, Schwarz, validación cruzada generalizada (VCG) o el de validación cruzada ordinaria (VCO). En Cortés-Toto, Guerrero y Reyes (2017) se mide la suavidad alcanzada cuando el parámetro de suavizamiento λ es elegido a través de esta clase de criterios. En tal trabajo se concluye que en principio el analista depende de la cantidad de datos y del tipo de tendencia subyacente a los mismos, y que son menos relevantes la eventual presencia de estacionalidad y la varianza existente. Además, se dimensiona la suavidad inducida y se evidencia que escapa la misma de la decisión del analista. En la Gráfica 2 se presentan algunos ejemplos y comparativos que ponen de manifiesto la necesidad y la ventaja de imponer suavidades como es factible con el uso de la propuesta aquí expuesta.
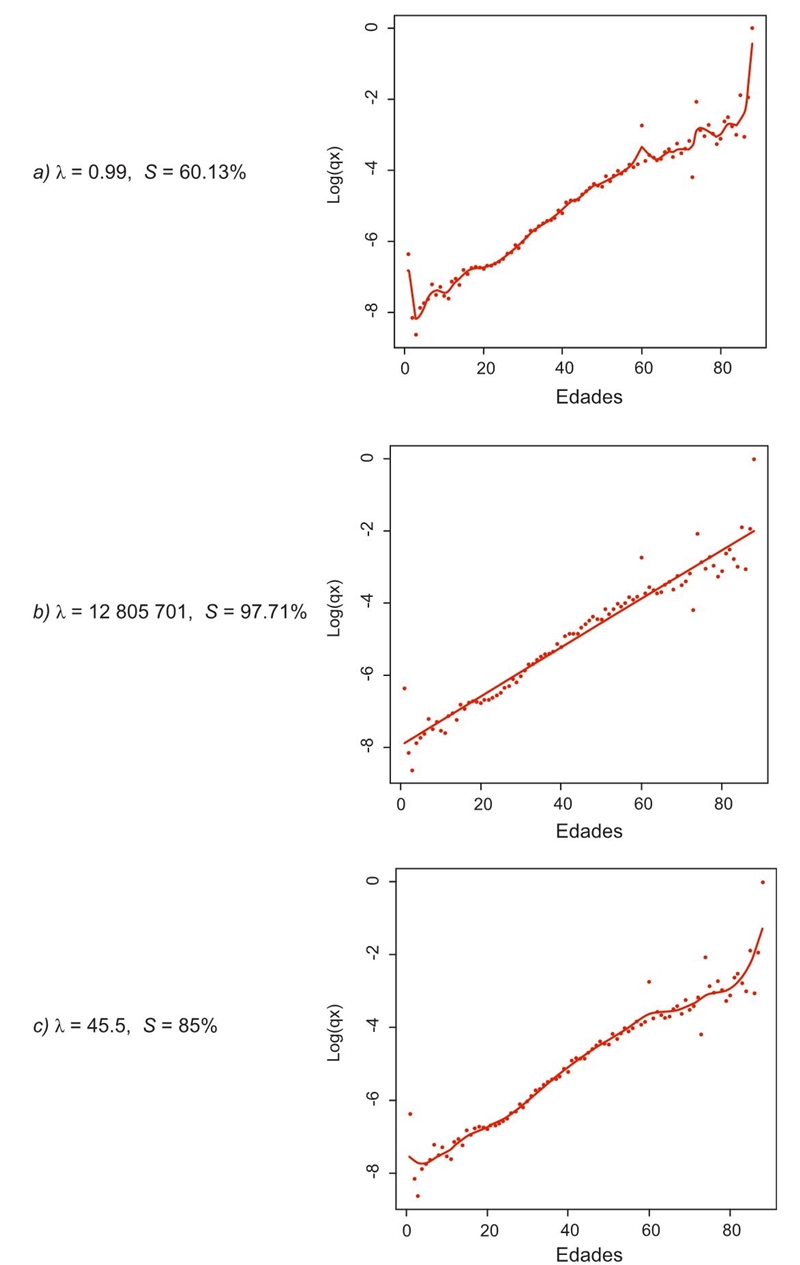
Fuente: Elaboración propia.
Gráfica 2 Estimaciones de tendencias con criterios automáticos e impuesto
Con el software estadístico R, con la librería pspline, los criterios VCG y VCO están disponibles (véase el código genérico en los Anexos). Al emplearlo con datos de Mendoza, Madrigal y Gutiérrez-Peña (2001), con el criterio VCG se obtiene de manera automática λ = 0.99, lo cual implica un índice de suavidad de aproximadamente el S = 60.13% y grados de libertad de 35.09. Se observa cómo la tendencia se dispone próxima a los datos. Con el criterio VCG se obtiene λ = 12 805 701, un índice de suavidad de S = 97.71% y grados de libertad de 2.01, lo cual hace que la tendencia sea prácticamente una recta. En ambos casos queda sin sentido demográfico la estimación de la curva de mortalidad. Por un lado, es demasiada rugosa la estimación, y por el otro, en principio la curvatura de la mortalidad en edades jóvenes es ignorada y se evoca a la añeja propuesta de Moivre.
Es claro que para un mismo conjunto de datos, dos criterios automáticos estadísticos ad hoc generan estimaciones totalmente distintas. Si se impone un índice de suavidad, por ejemplo de S = 85% como el sugerido en Ovin y Silva (2016a; 2016b), con λ = 45.5 y grados de libertad de 13.18, se obtienen resultados con más sentido demográfico. En términos operativos, para obtener determinado índice de suavidad, en la ecuación para S(λ; N), se calibra dando distintos valores de λ, hasta que de manera heurística se obtiene la suavidad deseada.
Con la finalidad de sensibilizar al usuario de la presente propuesta, en la Gráfica 3 se muestra un ejemplo con diferentes valores de λ, con datos simulados. Se puede observar cómo con valores pequeños de λ, como en la Gráfica 3a, la tendencia estimada se aproxima bastante a los valores observados. En cambio, cuando λ crece la suavidad se vuelve más evidente como muestra el hecho de que los datos quedan alrededor de la curva suavizada, y para λ mayores a 1000 la tendencia comienza a parecerse a una recta, como en la Gráfica 3d.

Comparativo con otras curvas de mortalidad y funciones de pérdida
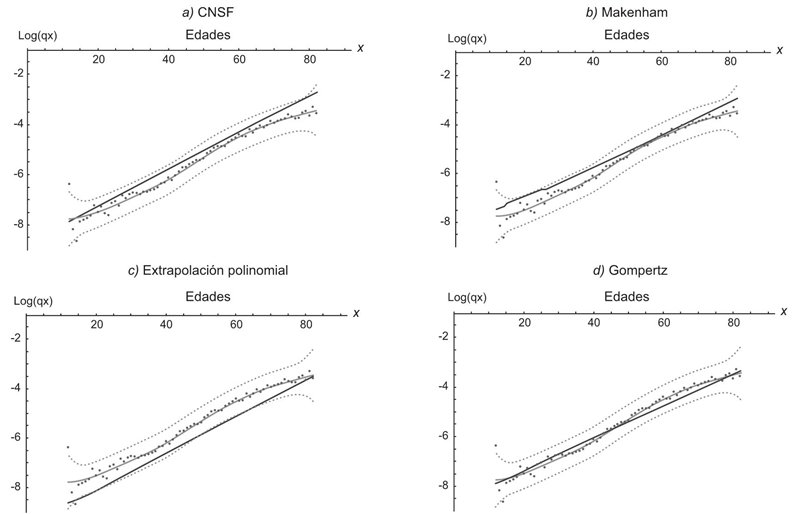
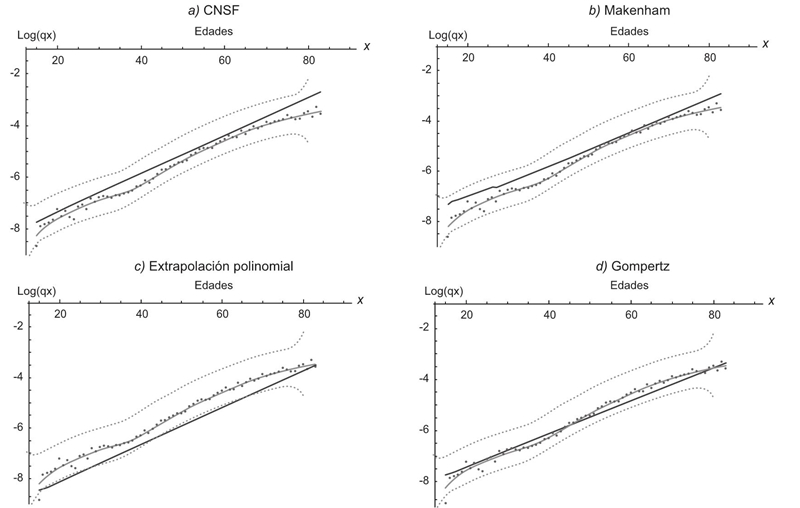
En esta sección se contrastan resultados desde la perspectiva aquí propuesta con algunas curvas de mortalidad obtenidas en Vargas (2014) y comparables con aquellos estimados por medio de índices de suavidades impuestas del S = 85% y S = 90%, respectivamente. En todos los casos se utiliza el logaritmo natural de las q x y sin pérdida de generalidad se ilustra con una población selecta; la lógica de la ilustración sería la misma para cualquier otra población que cuente con estimaciones de curvas de mortalidad. Se eligen los que ahí se refieren como tablas de mortalidad mexicana ajustada mediante el modelo de: a) CNSF, b) Makeham, c) extrapolación polinomial, y d) Gompertz. En particular, el modelo HP empleado no resultó ser comparable pues en casi todas las edades se tiene una estimación constante hasta casi los 75 años (véase Vargas, 2014, p. 88). Debe tenerse presente que cada estimación hecha de a a d, así como las de otros modelos de mortalidad, tienen una complejidad superior a lo que sencillamente se realiza con la estimación y/o medición de tendencias y suavidades respectivamente, pues tienen el común denominador de emplear criterios matemáticos de optimización lineal o no lineal con sus respectivos valores iniciales.
En general, con base en las Gráficas 4 y 5, se aprecia cómo las estimaciones seleccionadas y realizadas por la autora están comprendidas dentro del intervalo de estimación de la tendencia o en algunos casos cercanos a alguna de las fronteras del mismo. También se tiene un mejor patrón en la estimación de la respectiva curva de mortalidad con la propuesta no paramétrica sobre todas las propuestas paramétricas expuestas por la autora. Es probable que en términos numéricos la diferencia parezca insignificante, pero deja de serlo si se consideran indicadores demográficos como esperanza de vida, que considera todas las q x .
Fuente: Elaboración propia.
Gráfica 4 Comparativos de estimaciones de curvas de mortalidad con intervalos de estimación de dos desviaciones estándar (líneas sólidas tenues), con λ = 293.7 y S = 90% (líneas sólidas): CNSF, Makeham, Extrapolación polinomial y Gompertz
Fuente: Elaboración propia.
Gráfica 5 Comparativos de estimaciones de curvas de mortalidad con intervalos de estimación de dos desviaciones estándar (líneas sólidas tenues), con λ = 49.25 y S = 85% contra (líneas sólidas): CNSF, Makeham, Extrapolación polinomial y Gompertz
Dado que uno de los propósitos del trabajo es estimar la suavidad necesaria para aproximar lo mejor posible la curva de mortalidad que proporciona el modelo de HP, y así tener un parámetro de referencia en cuanto a la suavidad necesaria para estimar una curva de mortalidad, se propone conseguirlo a través de medir la diferencia punto a punto que hay entre la tendencia estimada y los valores de la mortalidad estimados por el modelo HP. Por medio de dos de las funciones de pérdida propuestas en Carriere (1992), se logra el objetivo. Sin pérdida de generalidad, sean {q
x
} los valores observados, y
Ahora se realizan las siguientes tareas. La primera, encontrar el valor de λ que minimiza las expresiones anteriores. Después, encontrar el porcentaje de suavidad logrado para cada uno de los dos valores de λ obtenidos mediante la expresión que se define para S(λ; N). Por último, se analiza el valor mínimo obtenido por las funciones de pérdida para poder comparar las distintas series de datos entre sí. Este valor representará la distancia total que existe entre la serie suavizada
Resultados con el modelo de Heligman y Pollard (HP)
Se utilizan estimaciones realizadas en los trabajos de Heligman y Pollard (1980), Kostaki (1991), Felipe, Guillen y Pérez-Marín (2002) y Jos (2014), en donde se encuentran los valores de los respectivos parámetros para el modelo de HP. Los valores observados de HP y Kostaki se encuentran en los anexos correspondientes; los de Jos (2014) en Asian Mortality Table, ubicados en la página web de la sociedad actuarial de Hong Kong. Los datos observados de Felipe, Guillen y Pérez-Marín (2002) fueron obtenidos de la página HumanMortality.com. El número total de series, es decir tablas de mortalidad utilizadas, es de 42. Los cálculos de este apartado se elaboraron con el software de R versión 3.4.1 y Mathematica de Wolfram, versión 10 (véase el código genérico en los Anexos).
Cuando se busca la minimización de las funciones de pérdida, se obtienen valores pequeños de λ que están entre 0.07 y 0.08 en los dos casos, siendo prácticamente el mismo resultado para todas las series analizadas. Usando este valor de λ, la suavidad alcanzada está en el rango de S = 23% a S =25%, con lo cual se tienen estimaciones demasiado rugosas. Los patrones de comportamiento de las funciones de pérdida se muestran a continuación. Nótese que en las series el mínimo se localiza relativamente pronto y luego hay un crecimiento de manera aparentemente cuadrática. El mecanismo utilizado para construir las gráficas de las funciones de pérdida fue a través de asignar paulatinamente distintos valores crecientes del parámetro de suavizamiento λ (véase la Gráfica 6).
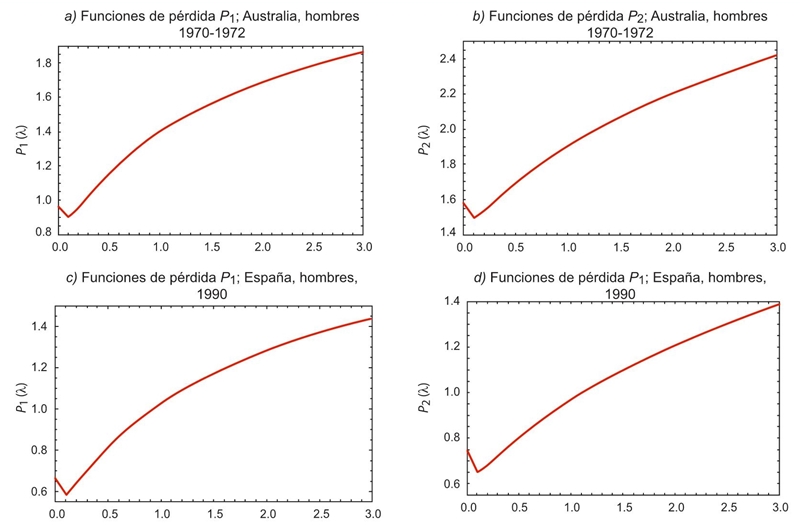
Fuente: Elaboración propia.
Gráfica 6 Comportamiento de funciones de pérdida P1 y P2 ; Australia, hombres, 1970-1972, y España, hombres, 1990
Al realizar este procedimiento de análisis para todas las series mencionadas, se tienen los siguientes resultados, mostrados en los histogramas de la Gráfica 7. La descriptiva de los mismos, así como los demás hallazgos, aparecen más adelante en el Cuadro 2. En ambos casos se aprecia una asimetría a la derecha, con una cola pesada.
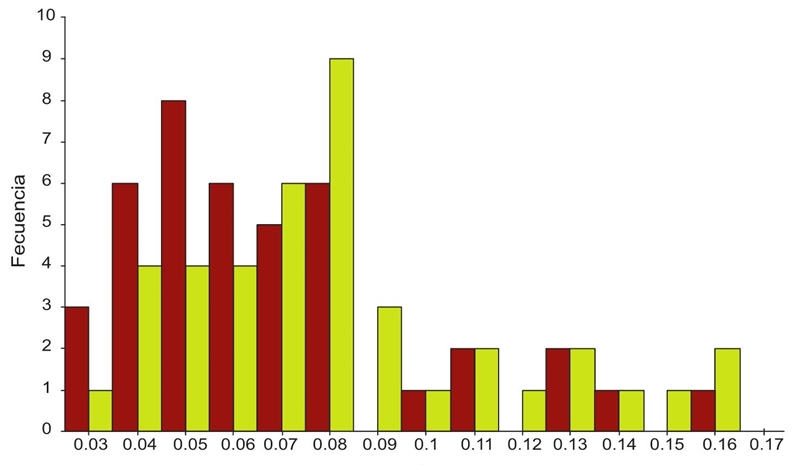
Fuente: Elaboración propia.
Gráfica 7 Distribución de los valores de λ que minimizan P1 versus P2 (rojo obscuro y verde claro, respectivamente)
Cuadro 2 Estimación de λ y S para cada una de las series considerando P1, P2, P1(12,99) y P2(12,99)
Autor (año) |
Serie (año) |
λ |
S% |
P1 |
λ |
S% |
P2 |
λ |
S% |
P1(12,99) |
λ |
S% |
P2(12,99) |
1970-1980 |
|||||||||||||
HP (1980) |
Australia, mujeres, 1970-1972 |
0.08 |
25.35 |
0.77 |
0.09 |
27.06 |
0.82 |
5.69 |
75.06 |
0.50 |
6.56 |
75.96 |
0.53 |
Kostaki (1991) |
Suecia, mujeres, 1976-1980 |
0.11 |
29.87 |
0.56 |
0.14 |
33.50 |
0.52 |
16.79 |
80.73 |
0.17 |
13.92 |
79.82 |
0.16 |
Felipe et al. (2002) |
España, mujeres, 1976 |
0.05 |
18.99 |
1.97 |
0.06 |
21.36 |
1.86 |
93.22 |
87.49 |
1.50 |
80.77 |
87.06 |
1.43 |
Felipe et al. (2002) |
España, mujeres, 1977 |
0.08 |
25.35 |
1.67 |
0.08 |
25.35 |
1.60 |
143.65 |
88.69 |
1.08 |
136.86 |
88.56 |
1.10 |
Felipe et al. (2002) |
España, mujeres, 1978 |
0.06 |
21.36 |
1.53 |
0.08 |
25.35 |
1.54 |
105.40 |
87.84 |
1.05 |
91.75 |
87.44 |
1.07 |
Felipe et al. (2002) |
España, mujeres, 1979 |
0.05 |
18.99 |
2.35 |
0.07 |
23.47 |
2.18 |
215.50 |
89.70 |
1.50 |
211.10 |
89.65 |
1.44 |
Felipe et al. (2002) |
España, mujeres, 1980 |
0.05 |
18.99 |
1.67 |
0.07 |
23.47 |
1.79 |
96.35 |
87.58 |
1.18 |
94.77 |
87.53 |
1.29 |
HP (1980) |
Australia, hombres, 1970-1972 |
0.07 |
23.47 |
0.90 |
0.08 |
25.35 |
1.49 |
3.74 |
72.17 |
0.70 |
4.29 |
73.16 |
1.26 |
Kostaki (1991) |
Suecia, hombres, 1976-1980 |
0.05 |
18.88 |
0.41 |
0.04 |
16.20 |
0.40 |
16.26 |
80.58 |
0.07 |
16.44 |
80.64 |
0.07 |
Felipe et al. (2002) |
España, hombres, 1976 |
0.05 |
18.99 |
0.73 |
0.07 |
23.47 |
0.83 |
23.77 |
82.62 |
0.37 |
27.57 |
83.24 |
0.41 |
Felipe et al. (2002) |
España, hombres, 1977 |
0.04 |
16.30 |
0.71 |
0.05 |
18.99 |
0.77 |
14.63 |
80.39 |
0.47 |
14.44 |
80.33 |
0.52 |
Felipe et al. (2002) |
España, hombres, 1978 |
0.04 |
16.30 |
0.85 |
0.04 |
16.30 |
0.93 |
22.39 |
82.36 |
0.47 |
22.16 |
82.31 |
0.52 |
Felipe et al. (2002) |
España, hombres, 1979 |
0.06 |
21.36 |
0.88 |
0.08 |
25.35 |
1.40 |
26.48 |
83.07 |
0.54 |
37.42 |
84.44 |
0.97 |
Felipe et al. (2002) |
España, hombres, 1980 |
0.08 |
25.35 |
0.48 |
0.10 |
28.62 |
0.61 |
12.26 |
79.50 |
0.16 |
13.78 |
80.10 |
0.25 |
Media (total) |
0.06 |
21.40 |
1.11 |
0.08 |
23.85 |
1.20 |
56.87 |
82.70 |
0.70 |
55.13 |
82.87 |
0.79 |
|
Media (mujeres) |
0.07 |
22.70 |
1.50 |
0.08 |
25.65 |
1.47 |
96.66 |
85.30 |
1.00 |
90.82 |
85.15 |
1.00 |
|
Media (hombres) |
0.06 |
20.09 |
0.71 |
0.07 |
22.04 |
0.92 |
17.08 |
80.10 |
0.40 |
19.44 |
80.60 |
0.57 |
|
Desviación (total) |
0.02 |
3.97 |
0.61 |
0.03 |
4.65 |
0.56 |
64.22 |
5.20 |
0.48 |
60.92 |
4.90 |
0.49 |
|
Desviación (mujeres) |
0.02 |
4.25 |
0.63 |
0.03 |
3.91 |
0.59 |
71.97 |
5.37 |
0.50 |
70.38 |
5.15 |
0.48 |
|
Autor (año) |
Serie (año) |
λ |
S% |
P1 |
λ |
S% |
P2 |
λ |
S% |
P1(12,99) |
λ |
S% |
P2(12,99) |
| 1981-1990 | |||||||||||||
Felipe et al. (2002) |
España, mujeres, 1981 |
0.06 |
21.36 |
2.02 |
0.07 |
23.47 |
1.93 |
170.64 |
89.13 |
1.26 |
186.83 |
89.36 |
1.23 |
Felipe et al. (2002) |
España, mujeres, 1982 |
0.08 |
25.35 |
1.86 |
0.08 |
25.35 |
2.41 |
129.96 |
88.42 |
1.36 |
161.71 |
89.00 |
1.81 |
Felipe et al. (2002) |
España, mujeres, 1983 |
0.08 |
25.35 |
1.62 |
0.09 |
27.06 |
1.58 |
96.78 |
87.60 |
1.13 |
97.21 |
87.61 |
1.12 |
Felipe et al. (2002) |
España, mujeres, 1984 |
0.16 |
35.73 |
1.93 |
0.16 |
35.73 |
2.47 |
110.31 |
87.97 |
1.34 |
151.42 |
88.83 |
1.84 |
Felipe et al. (2002) |
España, mujeres, 1985 |
0.11 |
30.04 |
2.06 |
0.13 |
32.57 |
2.80 |
143.93 |
88.69 |
1.67 |
217.50 |
89.72 |
2.25 |
Felipe et al. (2002) |
España, mujeres, 1986 |
0.07 |
23.47 |
1.86 |
0.08 |
25.35 |
2.73 |
150.84 |
88.82 |
1.42 |
296.20 |
90.42 |
2.17 |
Felipe et al. (2002) |
España, mujeres, 1987 |
0.14 |
33.69 |
2.04 |
0.16 |
35.73 |
2.67 |
234.30 |
89.98 |
1.29 |
283.50 |
90.32 |
1.77 |
Felipe et al. (2002) |
España, mujeres, 1988 |
0.08 |
25.35 |
1.82 |
0.12 |
31.35 |
2.81 |
182.30 |
89.29 |
1.38 |
246.30 |
90.01 |
2.16 |
Felipe et al. (2002) |
España, mujeres, 1989 |
0.07 |
23.47 |
1.71 |
0.08 |
25.35 |
2.30 |
219.60 |
89.74 |
1.24 |
261.60 |
90.14 |
1.69 |
Felipe et al. (2002) |
España, mujeres, 1990 |
0.04 |
16.30 |
1.49 |
0.06 |
21.36 |
1.74 |
42.83 |
84.94 |
1.11 |
55.47 |
85.85 |
1.36 |
Felipe et al. (2002) |
España, hombres, 1981 |
0.05 |
18.99 |
0.97 |
0.08 |
25.35 |
1.05 |
30.45 |
83.64 |
0.58 |
36.42 |
84.34 |
0.62 |
Felipe et al. (2002) |
España, hombres, 1982 |
0.04 |
16.30 |
0.46 |
0.05 |
18.99 |
0.63 |
11.44 |
79.14 |
0.23 |
12.62 |
79.65 |
0.34 |
Felipe et al. (2002) |
España, hombres, 1983 |
0.04 |
16.30 |
0.51 |
0.04 |
16.30 |
0.76 |
5.00 |
74.21 |
0.31 |
9.85 |
78.34 |
0.55 |
Felipe et al. (2002) |
España, hombres, 1984 |
0.04 |
16.30 |
0.60 |
0.05 |
18.99 |
0.91 |
21.54 |
82.19 |
0.31 |
24.58 |
82.76 |
0.54 |
Felipe et al. (2002) |
España, hombres, 1985 |
0.03 |
13.21 |
0.61 |
0.03 |
13.21 |
1.02 |
2.58 |
69.30 |
0.47 |
3.16 |
70.91 |
0.89 |
Felipe et al. (2002) |
España, hombres, 1986 |
0.03 |
13.21 |
0.71 |
0.05 |
18.99 |
0.78 |
10.82 |
78.85 |
0.41 |
10.85 |
78.86 |
0.47 |
Felipe et al. (2002) |
España, hombres, 1987 |
0.10 |
28.62 |
0.61 |
0.11 |
30.04 |
0.71 |
24.13 |
82.68 |
0.24 |
26.41 |
83.06 |
0.29 |
Felipe et al. (2002) |
España, hombres, 1988 |
0.05 |
18.99 |
0.77 |
0.06 |
21.36 |
1.06 |
22.93 |
82.46 |
0.44 |
27.71 |
83.26 |
0.63 |
Felipe et al. (2002) |
España, hombres, 1989 |
0.13 |
32.57 |
0.67 |
0.13 |
32.57 |
0.79 |
26.71 |
83.11 |
0.29 |
29.05 |
83.45 |
0.39 |
Felipe et al. (2002) |
España, hombres, 1990 |
0.07 |
23.47 |
0.58 |
0.08 |
25.35 |
0.65 |
22.12 |
82.31 |
0.20 |
27.05 |
83.16 |
0.27 |
Media (total) |
0.07 |
22.90 |
1.25 |
0.09 |
25.22 |
1.59 |
82.96 |
84.12 |
0.83 |
108.27 |
84.95 |
1.12 |
|
Media (mujeres) |
0.09 |
26.01 |
1.84 |
0.10 |
28.33 |
2.34 |
148.15 |
88.46 |
1.32 |
195.77 |
89.13 |
1.74 |
|
Media (hombres) |
0.06 |
19.80 |
0.65 |
0.07 |
22.12 |
0.84 |
17.77 |
79.79 |
0.35 |
20.77 |
80.78 |
0.50 |
|
Desviación (total) |
0.04 |
6.78 |
0.63 |
0.04 |
6.35 |
0.84 |
77.98 |
5.57 |
0.52 |
105.61 |
5.21 |
0.71 |
|
Desviación (mujeres) |
0.04 |
5.77 |
0.19 |
0.04 |
5.13 |
0.45 |
57.46 |
1.44 |
0.16 |
80.10 |
1.43 |
0.40 |
|
Desviación (hombres) |
0.03 |
6.49 |
0.14 |
0.03 |
6.11 |
0.16 |
9.56 |
4.67 |
0.12 |
10.76 |
4.07 |
0.19 |
|
Autor (año) |
Serie (año) |
λ |
S% |
P1 |
λ |
S% |
P2 |
λ |
S% |
P1(12,99) |
λ |
S% |
P2(12,99) |
| 1991-2000 | |||||||||||||
Felipe et al. (2002) |
España, mujeres, 1991 |
0.06 |
21.36 |
1.42 |
0.07 |
23.47 |
1.52 |
135.09 |
88.53 |
1.06 |
140.62 |
88.63 |
1.14 |
Felipe et al. (2002) |
España, mujeres, 1992 |
0.13 |
32.57 |
1.90 |
0.15 |
34.74 |
2.80 |
86.43 |
87.26 |
1.40 |
120.23 |
88.21 |
2.25 |
Felipe et al. (2002) |
España, mujeres, 1993 |
0.07 |
23.47 |
2.38 |
0.11 |
30.04 |
7.41 |
51.69 |
85.60 |
1.86 |
159.44 |
88.96 |
6.71 |
Jos (2012) |
Tailandia, mujeres, 1997 |
0.56 |
53.52 |
0.74 |
0.56 |
53.52 |
1.22 |
22.53 |
82.38 |
0.72 |
28.37 |
83.35 |
1.20 |
Felipe et a (2002) |
España, hombres, 1991 |
0.06 |
21.36 |
0.64 |
0.07 |
23.47 |
0.62 |
43.83 |
85.02 |
0.21 |
45.72 |
85.17 |
0.23 |
Felipe et al. (2002) |
España, hombres, 1992 |
0.05 |
18.99 |
0.66 |
0.06 |
21.36 |
0.72 |
60.96 |
86.17 |
0.25 |
63.43 |
86.29 |
0.27 |
Felipe et al. (2002) |
España, hombres, 1992 |
0.06 |
21.36 |
0.79 |
0.09 |
27.06 |
1.00 |
86.07 |
87.25 |
0.22 |
99.03 |
87.66 |
0.40 |
Jos (2012) |
Tailandia, hombres, 1997 |
4.20 |
73.00 |
1.06 |
3.94 |
72.54 |
1.89 |
22.90 |
82.45 |
1.02 |
24.50 |
82.73 |
1.84 |
Media (total) |
0.65 |
33.20 |
1.20 |
0.63 |
35.78 |
2.15 |
63.69 |
85.58 |
0.84 |
85.17 |
86.38 |
1.76 |
|
Media (mujeres) |
1.09 |
33.68 |
0.79 |
1.04 |
36.11 |
1.06 |
53.44 |
85.22 |
0.43 |
58.17 |
85.46 |
0.69 |
|
Media (hombres) |
0.21 |
32.73 |
1.61 |
0.22 |
35.44 |
3.24 |
73.94 |
85.94 |
1.26 |
112.17 |
87.29 |
2.83 |
|
Desviación (total) |
1.45 |
19.69 |
0.65 |
1.35 |
18.08 |
2.24 |
37.83 |
2.24 |
0.61 |
52.03 |
2.41 |
2.13 |
|
Desviación (mujeres) |
2.07 |
26.24 |
0.19 |
1.93 |
24.40 |
0.58 |
26.75 |
2.06 |
0.40 |
31.55 |
2.09 |
0.77 |
|
Desviación (hombres) |
0.24 |
14.69 |
0.70 |
0.23 |
12.91 |
2.86 |
48.42 |
2.66 |
0.49 |
58.11 |
2.64 |
2.64 |
|
Fuente: Elaboración propia.
Para P1 los valores más frecuentes se ubican entre 0.04 y 0.08; para P2 los valores más comunes estuvieron alrededor de 0.08. En la Gráfica 8 se tienen dos segmentos de la serie suavizada de España 1990 con un parámetro de suavizamiento de λ = 0.07. Así, el índice de suavidad en este caso es de S = 23.47%. Se observa claramente cómo la tendencia estimada se aproxima a casi todos los valores observados de la serie; esto debido al valor pequeño del parámetro λ, lo cual se manifiesta prácticamente con la totalidad de las series utilizadas. El problema no es tan evidente, pues el desbalance (o desajuste) generado en las colas de los datos hace que el valor de la función de pérdida crezca con gran rapidez conforme el valor de λ crece por apenas valores mayores a 0.1, lo cual ocurre para los primeros valores observados y para los últimos. La falta de precisión en los primeros datos hace que las funciones de pérdida crezcan rápidamente, haciendo que el valor de λ que minimiza dichas funciones sean valores muy pequeños. El problema se presenta en menor escala en los valores finales de la serie (entre 90 y 99 de los valores observados) y sólo en algunos casos de las 42 series.
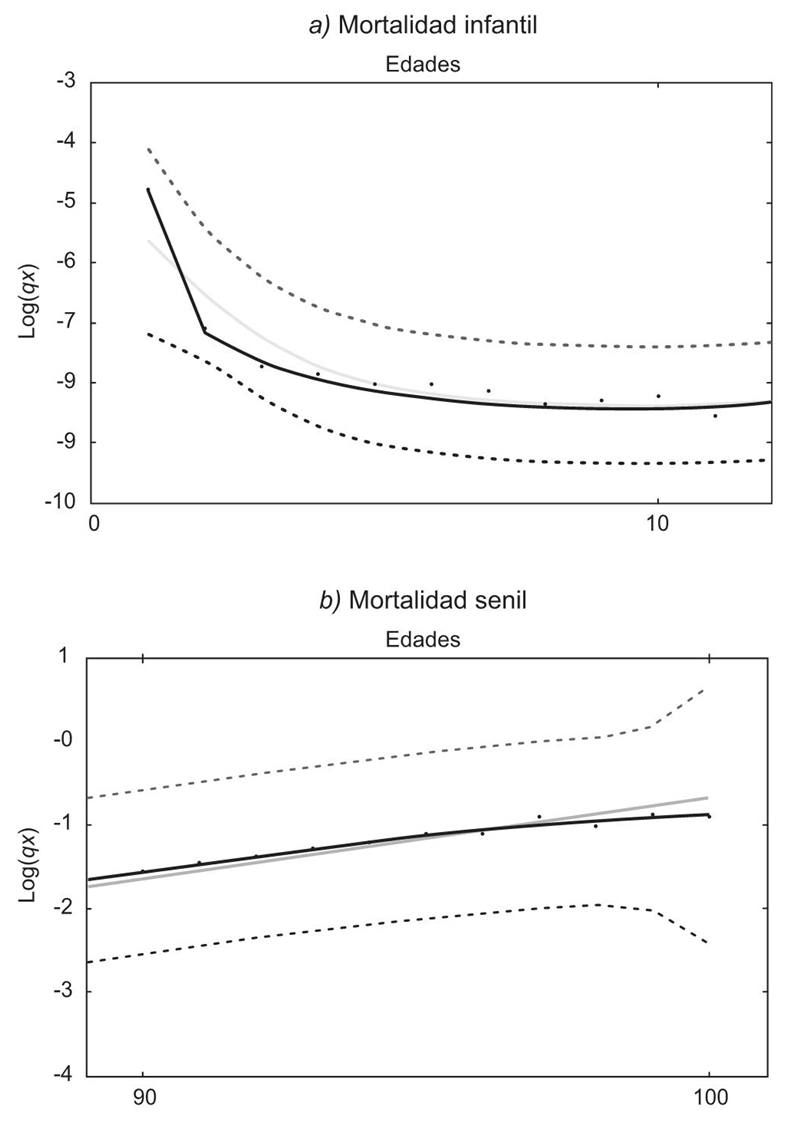
Datos observados: puntos; curva estimada (tendencia) con el modelo HP: línea gris; tendencia estimada: línea negra. Fuente: Elaboración propia.
Gráfica 8 España, hombres, 1990, con λ=0.07. Mortalidad infantil y mortalidad senil
En el Cuadro 1 se presenta la evolución del comportamiento de las funciones de pérdida, con distintos valores del parámetro de suavizamiento λ, pero considerándolas en dos partes. De esta manera las funciones de pérdida se reescriben como sigue:
y con un razonamiento similar se tiene:
Cuadro 1 Comportamiento de las funciones de pérdida seleccionadas para el caso de España, hombres, 1990
λ |
S% |
P1(0,11) |
P1(12,99) |
P1 |
P2(0,11) |
P2(12,99) |
P2 |
0 |
0.00 |
0.27 |
0.39 |
0.67 |
0.23 |
0.51 |
0.75 |
0.01 |
5.27 |
0.26 |
0.38 |
0.63 |
0.22 |
0.49 |
0.71 |
0.02 |
9.59 |
0.25 |
0.37 |
0.61 |
0.21 |
0.48 |
0.69 |
0.03 |
13.21 |
0.24 |
0.36 |
0.60 |
0.21 |
0.47 |
0.68 |
0.04 |
16.30 |
0.24 |
0.35 |
0.59 |
0.20 |
0.46 |
0.67 |
0.05 |
19.00 |
0.24 |
0.35 |
0.59 |
0.20 |
0.45 |
0.66 |
0.06 |
21.37 |
0.24 |
0.34 |
0.58 |
0.21 |
0.45 |
0.65 |
0.07 |
23.47 |
0.24 |
0.34 |
0.58 |
0.21 |
0.44 |
0.65 |
0.08 |
25.36 |
0.25 |
0.34 |
0.58 |
0.21 |
0.44 |
0.65 |
0.09 |
27.06 |
0.25 |
0.33 |
0.59 |
0.21 |
0.44 |
0.65 |
0.1 |
28.62 |
0.26 |
0.33 |
0.59 |
0.22 |
0.43 |
0.65 |
0.2 |
39.11 |
0.33 |
0.31 |
0.64 |
0.27 |
0.42 |
0.68 |
0.3 |
45.08 |
0.40 |
0.31 |
0.70 |
0.32 |
0.41 |
0.72 |
0.4 |
49.11 |
0.46 |
0.30 |
0.76 |
0.36 |
0.40 |
0.76 |
0.5 |
52.08 |
0.52 |
0.30 |
0.82 |
0.41 |
0.39 |
0.80 |
0.6 |
54.40 |
0.57 |
0.29 |
0.87 |
0.45 |
0.39 |
0.84 |
0.7 |
56.27 |
0.62 |
0.29 |
0.91 |
0.49 |
0.39 |
0.88 |
0.8 |
57.83 |
0.67 |
0.29 |
0.95 |
0.52 |
0.38 |
0.91 |
0.9 |
59.18 |
0.71 |
0.28 |
0.99 |
0.56 |
0.38 |
0.94 |
1 |
60.33 |
0.75 |
0.28 |
1.03 |
0.59 |
0.38 |
0.97 |
2 |
67.14 |
1.02 |
0.26 |
1.28 |
0.86 |
0.36 |
1.21 |
3 |
70.51 |
1.19 |
0.25 |
1.44 |
1.05 |
0.34 |
1.39 |
4 |
72.66 |
1.32 |
0.24 |
1.55 |
1.20 |
0.33 |
1.53 |
5 |
74.22 |
1.41 |
0.23 |
1.64 |
1.33 |
0.32 |
1.65 |
6 |
75.40 |
1.49 |
0.23 |
1.71 |
1.45 |
0.31 |
1.76 |
7 |
76.36 |
1.55 |
0.22 |
1.77 |
1.55 |
0.31 |
1.85 |
8 |
77.16 |
1.60 |
0.22 |
1.82 |
1.64 |
0.30 |
1.94 |
9 |
77.84 |
1.65 |
0.21 |
1.86 |
1.72 |
0.30 |
2.01 |
10 |
78.42 |
1.69 |
0.21 |
1.90 |
1.79 |
0.29 |
2.08 |
20 |
81.86 |
1.91 |
0.20 |
2.11 |
2.31 |
0.27 |
2.58 |
30 |
83.58 |
2.01 |
0.20 |
2.21 |
2.64 |
0.27 |
2.91 |
40 |
84.69 |
2.06 |
0.21 |
2.27 |
2.89 |
0.27 |
3.17 |
50 |
85.49 |
2.10 |
0.22 |
2.32 |
3.11 |
0.28 |
3.39 |
60 |
86.11 |
2.14 |
0.23 |
2.36 |
3.30 |
0.29 |
3.60 |
70 |
86.61 |
2.17 |
0.24 |
2.41 |
3.48 |
0.31 |
3.79 |
80 |
87.03 |
2.21 |
0.25 |
2.46 |
3.64 |
0.32 |
3.96 |
90 |
87.38 |
2.24 |
0.27 |
2.51 |
3.80 |
0.34 |
4.14 |
100 |
87.69 |
2.28 |
0.29 |
2.57 |
3.94 |
0.36 |
4.30 |
200 |
89.53 |
2.77 |
0.46 |
3.23 |
5.15 |
0.56 |
5.71 |
300 |
90.45 |
3.31 |
0.64 |
3.95 |
6.07 |
0.77 |
6.84 |
400 |
91.05 |
3.83 |
0.81 |
4.64 |
6.81 |
0.97 |
7.77 |
Fuente: Elaboración propia.
Se puede observar cómo para valores pequeños del parámetro de suavizamiento λ, entre 0.03 y 0.5, P1(0,11) alcanza su mínimo y se incrementa rápidamente cuando λ crece, mientras P1(12,99) alcanza su mínimo para valores entre 4 y 20, pero el total de P1 es fuertemente influenciado por el crecimiento rápido de P1(0,11). Un escenario similar ocurre en la función de pérdida P2. De hecho, también se aprecia cómo el valor P2(0,11) para valores entre 8 y 20 es considerablemente mayor que P2(12,99), donde su mínimo se encuentra de modo aproximado. Se debe recalcar que P2(0,11) contiene solamente 12 de los 100 datos, mientras P2(12,99) el resto. La presente situación se manifiesta análogamente en las demás series analizadas en el documento.
Dado que el desajuste empieza a crecer más significantemente en la parte de la mortalidad infantil, se decide omitirles y así la propuesta, en relación a la curva de la mortalidad del modelo HP, como se notará más adelante, crea un ajuste casi perfecto en el resto de los datos. Con esta restricción del número de datos a emplear, la máxima suavidad a la que se puede aspirar es de S = 97.7%. Las funciones de pérdida quedan como sigue:
(11)
(12)
En la Gráfica 9 se presentan los comportamientos de las funciones P1(12,99), y P2(12,99). Cabe notar que el patrón a continuación expuesto es similar en el resto de las series elegidas y, una vez localizado el mínimo, el patrón de las funciones de pérdida, a diferencia de los anteriores, crece de manera menos acelerada. Al igual que con las otras funciones de pérdida, se tiene una distribución asimétrica a la derecha.
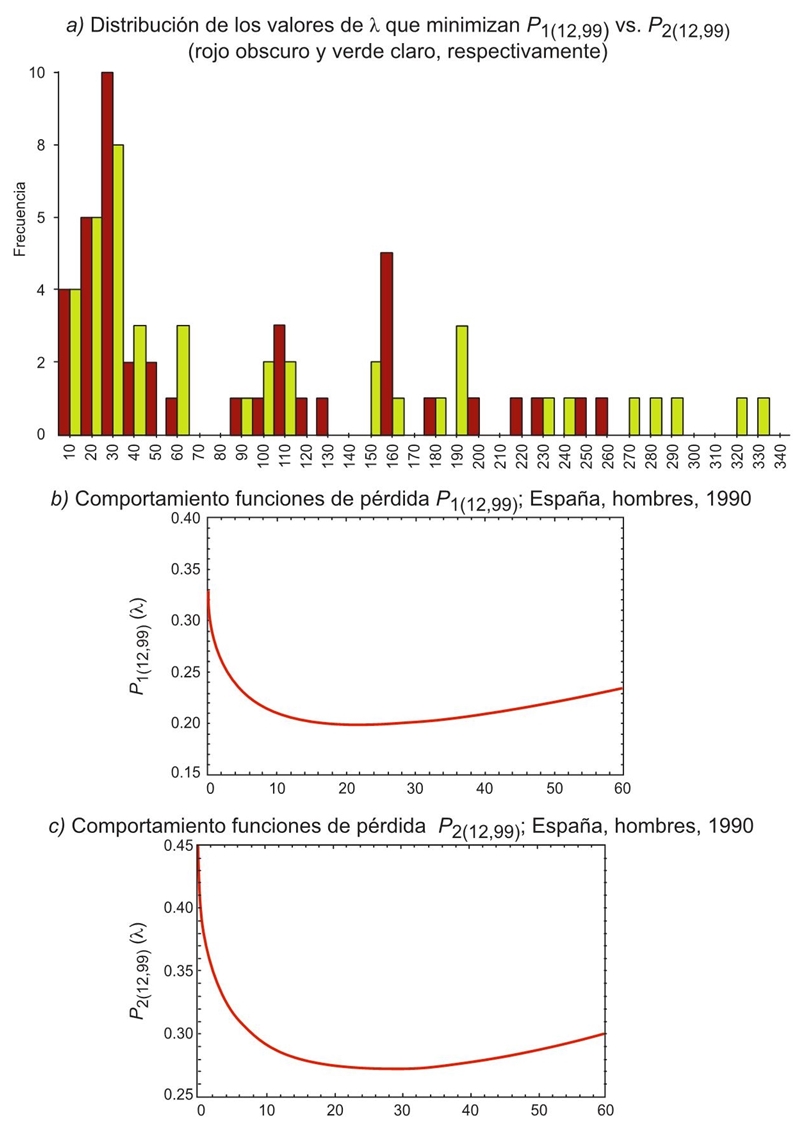
Fuente: Elaboración propia.
Gráfica 9 Distribución de los valores de λ que minimizan P1(12,99) vs. P2(12,99); y comportamiento funciones de pérdida. España, hombres, 1990
Ahora el valor que minimiza la función P1(12,99) es λ = 23.12, que implica una suavidad de S= 82.5%, y para P2(12,99) el valor obtenido es λ = 28.36 con una suavidad alcanzada de S = 83.25%. En otras palabras, los dos valores de λ fueron muy similares para las dos funciones de pérdida. La mayor discrepancia fue encontrada en la última parte de las series.
Se aprecia, con base en la Gráfica 10, que existe una mejora sustantiva en el ajuste para casi todos los valores. Al eliminar los primeros valores de la serie de las funciones de pérdida se logra que el método proporcione resultados más consistentes e interpretables en función de los valores de λ y de la suavidad S. El resumen de todos los valores de λ obtenidos para las 42 series se presenta en el Cuadro 2; en él se realiza una comparativa de las funciones P1, P2, P1(12,99) y P2(12,99), así como su media y desviación estándar. La información está organizada tanto por décadas como por sexo.
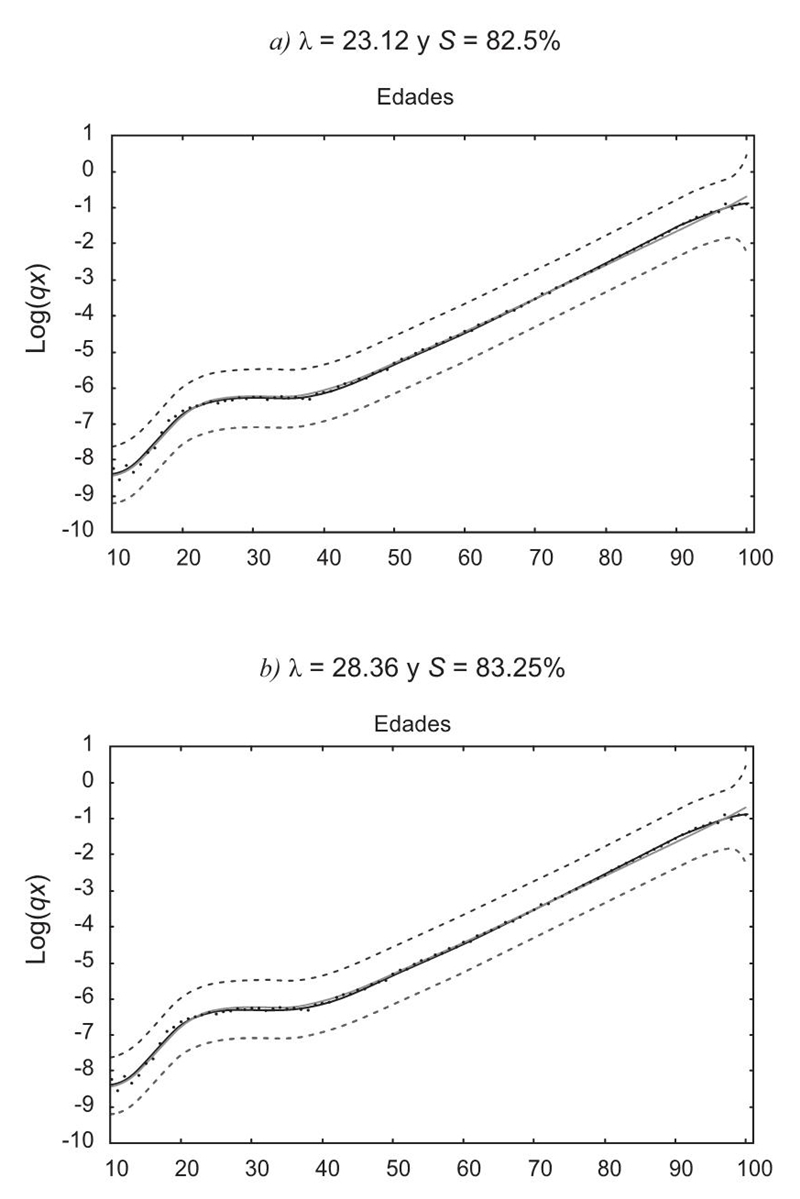
Datos observados: puntos; curva estimada (tendencia) con el modelo HP: línea gris; tendencia estimada: línea negra. Fuente: Elaboración propia.
Gráfica 10 España, hombres, 1990, con: a) λ = 23.12 y S = 82.5%; b) λ = 28.36 y S = 83.25%
En la Gráfica 11 se presentan ejemplos de los resultados obtenidos con sus respectivos valores de λ. Aunque otra vez la falta de ajuste se da en los últimos valores, se observa en general un aumento en el ajuste por medio de la aplicación del método no paramétrico propuesto; además, adicionalmente a las estimaciones puntuales, ahora se tienen intervalos de estimación de dos desviaciones estándar de tamaño. Así pues, una buena guía para el analista es seleccionar el valor de la media de valores de λ (o su equivalente medido en suavidad alcanzada) presentados en el Cuadro 2.
Conclusiones
Con base en los resultados comparativos con curvas de mortalidad previamente elaboradas, se tiene con la aplicación expuesta, una estimación altamente acertada en relación con las que se estimaron en Vargas (2014). Con el valor agregado de que el proceso para la generación de tales estimaciones es expedito y satisfactorio para los rangos de edades establecidos. Con ello queda de manifiesto lo que al menos con los comparativos mostrados aquí se aprecia: se cuenta con una estimación apropiada.
Se encontró que el valor de la función de pérdida para las series de Felipe, Guillen y Pérez-Marín (2002) de hombres es bajo, comparado con el de las mujeres, lo cual se puede observar en el Cuadro 1. Aunque se resolvió el problema del mal ajuste para los primeros datos de la serie, no se puede observar un patrón de distribución que siga los valores de λ. Es evidente que los resultados sugieren que el estudio de la suavidad inducida a través del modelo HP es perfectible para abarcar toda la experiencia de mortalidad.
Los resultados son más convincentes cuando se omite de las estimaciones la mortalidad infantil y para menores de 12 años. Ahora se puede afirmar un rango adecuado de índices de suavidades para obtener curvas de mortalidad similares a aquellas que se obtendrían con la aplicación del modelo HP. En cada uno de los casos se encontró un valor de λ que aproxima lo suficientemente bien las estimaciones del modelo HP y además se proporciona un intervalo de dicha estimación.
Los porcentajes de suavidad dependen claramente de la cantidad de datos. Por ejemplo, para el rango de edades de 12-99 años, ellos están entre S = 85.26% y S = 89.29%, y S = 75% y S = 87.71% para mujeres y hombres, respectivamente. Es posible encontrar casos en los cuales los valores de las funciones de pérdida sean altos con respecto a lo que se espera, lo cual sugiere que no hay un valor de λ que se aproxime lo suficiente a la tendencia estimada con la curva de mortalidad objetivo.
Se detectó homogeneidad en los resultados si se agrupan las estimaciones por décadas. De hecho, en muchos casos el índice de suavidad requiere ser más alto para el caso de las mujeres que para el de los hombres. Así pues, se tienen dos conclusiones sustantivas: cuando sólo se tiene una serie con tendencia lineal ascendente, es decir, cuando se omite la mortalidad infantil y de menores de 12 años, el índice de suavidad es alto, en tanto que cuando hay una tendencia no lineal en un segmento y otra tendencia lineal en el otro, es decir, cuando se toman todas las edades, entonces el índice de suavidad es más bajo.
Se puede afirmar que con la perspectiva del suavizamiento controlado se aproximan de manera más sencilla curvas de mortalidad en comparación con otros métodos que exigen al analista más herramientas técnicas que no necesariamente se traducen en mejores estimaciones: aquí es sólo un índice que genera tendencias. También queda evidenciado que sí es factible medir la suavidad inducida en curvas de mortalidad estimadas con el modelo HP con funciones de pérdida, con lo que el analista ahora tiene información útil para poder estimar curvas de mortalidad en general; es decir, se tiene la suavidad que se puede imponer para obtener resultados satisfactorios. La limitante se tiene para las edades iniciales de la vida, así como en igualar la calidad de las estimaciones para los dos sexos.
Una futura línea de investigación justamente consiste en realizar la aproximación no paramétrica a través de tres segmentos, por medio de la propuesta de Guerrero y Silva (2015), con lo que se podría replicar y adecuar el procedimiento aquí señalado, pero para cada una de las tres etapas de la vida, a saber: mortalidad infantil, mortalidad en edades jóvenes-adultas y mortalidad senil. Se considera que bajo dicha óptica se podría superar la limitante de la estimación que se manifiesta para la primera etapa de la vida.
El enfoque no paramétrico se puede utilizar en cualquier otro modelo de mortalidad, siguiendo el mismo criterio aquí expuesto. Aun cuando la mortalidad es un fenómeno que se va transformando por lo general lentamente en el tiempo y que los niveles pueden variar de contexto a contexto, es verdad que los patrones son sistemáticos en muchos países del mundo. Es meritorio recalcar que ésta es una primera aproximación a resultados derivados de la aplicación del modelo HP y que también es factible realizar pronósticos de la tendencia, es decir, de la edad máxima estimada a partir de propuestas ya existentes en torno al suavizamiento controlado.

