











 nova página do texto(beta)
nova página do texto(beta) Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
PermalinkIntroducción
Los datos demográficos, ya sea que provengan de censos, de encuestas o de estadísticas vitales, comúnmente sufren diversas anomalías. Si bien algunas de ellas son atribuibles a errores humanos (de los informantes, de los encuestadores o del personal encargado de transcribir y capturar los datos), ésta no es la única fuente de errores ni necesariamente la más importante, pues ciertas cuestiones climáticas (como los huracanes, las sequías, etcétera) o fuera del control de los analistas (terremotos, huelgas, etcétera) provocan también la generación de errores en las bases de datos. Desde luego, estos errores distorsionan el patrón verdadero del fenómeno que los datos pretenden cuantificar y su presencia hace necesaria la aplicación de herramientas que corrijan, o al menos mitiguen, el efecto perverso de tales distorsiones en lo que respecta a los resultados de posibles análisis que se efectúen con los datos. Ello ocurre de esta manera sin importar lo elaborados que puedan ser tales análisis, los cuales pueden ir desde una mera descripción superficial de los patrones más relevantes en los datos, hasta un análisis confirmatorio de alguna teoría que explique el comportamiento de la población bajo estudio.
Una de tales “herramientas correctoras”, que se utiliza con mucha frecuencia en la práctica, es la graduación de datos. Puede aplicarse tanto en las instituciones gubernamentales, con fines muy generales para percibir de manera lo más clara posible los patrones subyacentes en los datos, o en organizaciones privadas con fines muy particulares, para tomar decisiones específicas de las mismas. Esto se debe en buena medida a que es muy fácil efectuar la graduación de datos debido a que se basa en ideas muy simples y su instrumentación computacional es relativamente fácil; asimismo porque el costo asociado con su aplicación es muy bajo (un programa computacional sencillo permite hacer la aplicación).
Tanto la sencillez de representación como la facilidad y el bajo costo de implementación computacional se mantienen en la propuesta que aquí se presenta. Adicionalmente, el nuevo método que se sugiere produce ganancias en cuanto a la operatividad de conceptos como la fidelidad a los datos originales, la suavidad de los datos graduados y la cercanía de éstos a una estructura que se considera como meta. Para ello primero se formalizan estas ideas mediante una representación de los datos disponibles a través de un modelo estadístico de componentes no-observables, para el cual se asocia en forma natural el método de estimación de parámetros denominado Mínimos Cuadrados Generalizados (MCG). Posteriormente se muestra que es posible cuantificar la suavidad y la cercanía a la estructura meta por medio de unos índices expresables en forma de porcentajes, con lo cual se sigue que es factible controlar estas características de la graduación propuesta simplemente al fijar valores para tales índices, de acuerdo con el criterio del analista.
La importancia de efectuar el control mencionado radica en que con ello se pueden realizar comparaciones válidas entre datos con suavidades y cercanías a estructuras límites similares, algo que de otra manera no tendría mucho sentido intentar siquiera comparar. Finalmente, los cálculos de la graduación aquí propuesta se realizan de manera muy sencilla al emplear una herramienta de cálculo muy poderosa conocida como Filtro de Kalman, que es aplicable cuando el Modelo de Componentes No-Observables se interpreta en la forma de un Modelo de Espacio de Estados.
La estructura del documento es la siguiente: en la próxima sección se presentan brevemente algunos modelos y técnicas no-paramétricas que suelen usarse en la graduación de datos; en la tercera se mencionan algunas técnicas de carácter demográfico que sirven para analizar y proyectar datos. Posteriormente, en la cuarta sección se presenta el método propuesto para llevar a cabo la graduación; ahí se muestran las ideas fundamentales, que se expresan por medio de ecuaciones y dan origen al Modelo de Componentes No-Observables por utilizar. En la quinta sección se presentan los índices de estructura y suavidad que se utilizan para cuantificar los respectivos conceptos y que permiten fijar los porcentajes deseados para los mismos. Una vez que se han fijado los valores para los índices, se demuestra que se pueden deducir los valores para las constantes respectivas, las cuales forman parte de la especificación del modelo. En la sexta sección se pretende mostrar, mediante diversas aplicaciones a datos demográficos de la realidad mexicana, la utilidad de la metodología propuesta y el tipo de resultados que se pueden obtener de la misma. En la última sección se exponen algunas conclusiones para destacar los pros y contras del uso de la metodología propuesta.
Métodos no-paramétricos
Haberman y Renshaw (1996) definen la graduación como un grupo integral de técnicas y principios que permiten realizar el ajuste de probabilidades o datos en general para suavizarlos de manera que se puedan realizar inferencias y análisis del tipo que sea necesario. La graduación de datos puede efectuarse mediante procedimientos que típicamente se clasifican en paramétricos o no-paramétricos. La segunda clase de técnicas no requiere del supuesto de que una cierta función represente el comportamiento de los datos globalmente y en forma estricta; por el contrario, se pretende suavizar las fluctuaciones que básicamente oscurecen la tendencia subyacente en los datos observados y obtener representaciones localmente aceptables. Los métodos no-paramétricos son más flexibles y robustos, en tanto que son menos los supuestos que respaldan su uso. Además, en muchas ocasiones resulta más fácil emplear los métodos no-paramétricos que su contraparte paramétrica, debido al menor rigor implícito en su aplicación.
La propuesta de este trabajo se encuentra dentro del ámbito de los métodos no-paramétricos, ya que se pretende simplificar el análisis de los datos observados después de que se les ha eliminado una parte de la variabilidad que no es intrínseca de ellos. De hecho, los datos originales se convierten en estimaciones una vez que se les han cancelado las fluctuaciones que oscurecen su tendencia. Dentro de las técnicas no-paramétricas que se utilizan más frecuentemente se encuentran los métodos gráficos, los promedios móviles ponderados, el método del núcleo y la graduación en general, en especial la que se aplica a los datos demográficos (Copas y Haberman, 1983; Papaioannou y Sachlas, 2004). Por ejemplo, algunas aplicaciones de los modelos no-paramétricos en demografía permiten obtener estimaciones de mortalidad en edades avanzadas (Fledelius et al., 2004). Asimismo, en el trabajo de Debón et al. (2006) se muestran diversas comparaciones entre métodos no-paramétricos y de suavizamiento realizado con Modelos Aditivos Generalizados, en particular con splines, también dentro de un contexto demográfico.
La técnica de graduación que se usa más frecuentemente en la práctica es la de Whittaker y Henderson. Esta forma de graduación se aplica a los datos originales para obtener datos suavizados de manera tal que se satisfagan dos criterios: bondad de ajuste (es decir, fidelidad a los datos originales) y suavidad de los datos resultantes. Al lector interesado en detalles acerca de este tipo de graduación y otros métodos similares se le recomienda consultar el libro de London (1985). Para lograr que los dos criterios se cumplan, se pondera en forma relativa su importancia mediante una constante o parámetro de suavizamiento. De hecho, el método surge al resolver un problema de minimización de la función siguiente:
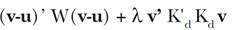 [1]
[1]en donde sobresale la constante de suavizamiento λ > 0 recién mencionada, la cual se supone conocida al efectuar la minimización. El vector u = (u1, …, un)’ contiene los valores observados de la variable en cuestión, y el vector de valores graduados v = (v1, …, vn)’ es el que se desea obtener. Se usa también la matriz diagonal W = diag(w1,...,wn) que sirve para asignar ponderaciones a las diferencias entre valores observados y graduados. Finalmente, la matriz Kd, que permite aplicar diferencias a datos contiguos, es de dimensión (n - d) × n y está definida de forma tal que su ij-ésimo elemento está dado por la expresión
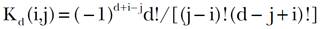 [2]
[2]la cual es válida para i = 1, ..., n-d y j = 1, ..., n, junto con Kd (i, j) = 0 para j < i ó j > d+i.
El caso particular d = 2 del método de Whittaker y Henderson fue redescubierto por Hodrick y Prescott en un trabajo que elaboraron dichos autores en 1980 dentro de un contexto de análisis económico, aunque el artículo correspondiente se publicó apenas en 1997 (véase Hodrick y Prescott, 1997). Por este motivo dicho método se conoce como Filtro de Hodrick y Prescott (HP) en el área económica, donde se utiliza ampliamente para estimar tendencias y realizar análisis de ciclos económicos (véase Guerrero, 2008, para mayores detalles sobre el citado Filtro HP). El problema de minimización correspondiente al valor d = 2 puede plantearse como
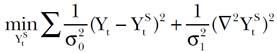 [3]
[3]donde ahora se define a Yt como la variable observada en el tiempo de observación t, mientras que Yt S es su correspondiente valor suavizado de tendencia, que no es observable y se pretende estimar, σ2 0 es la varianza del componente cíclico, definido como la desviación del dato observado respecto a la tendencia {Yt - YS t}, mientras que σ2 1 es la varianza del crecimiento de la tendencia, ∇2YS t. Por su lado, el parámetro de suavizamiento es de la forma λ = σ2 0/σ2 1, lo cual permite interpretarlo como una constante con la cual se puede establecer un balance entre la fidelidad de la serie suavizada a los datos originales y la suavidad de la tendencia que se obtiene. Al resolver el problema de minimización, en términos del vector de datos observados Y = (Y1, ..., Yn)’ se produce el siguiente estimador de la tendencia de los datos. Para detalles acerca de este resultado véase Hodrick y Prescott (1997) o Guerrero (2008),
 [4]
[4]con ŶS = ŶS 1, …, ŶS n)’, In, la matriz identidad de dimensión n × n y K2 la matriz definida mediante la expresión [2], con el valor d = 2, es decir, es de la forma
 [5]
[5]La expresión [4] es precisamente el estimador producido por el Filtro HP cuyo uso requiere, además del vector de datos Y, conocer el valor del parámetro de suavizamiento λ, puesto que los demás elementos de esa expresión son conocidos. La solución que dieron Hodrick y Prescott para elegir dicha constante de suavizamiento está basada en argumentos del dominio de las frecuencias, aplicables al análisis de ciclos económicos, con los cuales se obtuvo como resultado el valor λ = 1600, para series económicas trimestrales de Estados Unidos en la época de la posguerra, de longitud aproximada a los 100 datos. Para otros casos el analista debe ser responsable de elegir el valor más apropiado, teniendo en mente que un valor pequeño conducirá a una tendencia poco suave (muy semejante a los datos que se observaron originalmente). En cambio, al elegir un valor elevado para dicha constante la tendencia será muy suave (i. e., se aproximará a la línea recta estimada para los datos observados mediante el método de Mínimos Cuadrados Ordinarios).
Dado el éxito del Filtro HP para realizar análisis de ciclos económicos, Laxton y Tetlow (1992) propusieron una extensión de dicho resultado y desarrollaron el filtro conocido como Filtro HP Multivariado (HPMV), con el cual se extiende la aplicabilidad de la herramienta original, en el sentido de que además de las ideas de fidelidad a los datos y suavidad se puede incorporar la cercanía a una estructura dictada por algún tipo de teoría del fenómeno en estudio. De esta forma se obtiene el filtro correspondiente al minimizar nuevamente una función de los valores estimados y que ahora considerará también la existencia de un error aleatorio asociado con la discrepancia entre lo que indica la teoría y lo que muestran los datos observados. En consecuencia, el Filtro HPMV sirve para estimar la tendencia Yt S (que no es observable) de una variable Yt (observable) mediante la solución del siguiente problema de minimización:
 [6]
[6]donde aparecen ahora dos parámetros de suavizamiento, λ1 y λ2. Desde luego debe notarse la similitud entre las expresiones [3] y [6], ya que esta última es una extensión de la anterior, en tanto que ahora incluye también el error aleatorio ξ t asociado con alguna teoría del fenómeno que involucra a Yt S. Una presentación ampliada y con detalle del desarrollo del Filtro HPMV se puede consultar en Boone (2000).
Algunas técnicas demográficas de modelación
La metodología que se propone en este trabajo para corregir anomalías en los datos demográficos parte de la idea de que se puede representar el comportamiento de tales datos mediante un modelo estadístico muy general. Conviene, por lo tanto, conocer algunas técnicas que también se basan en representaciones o modelos generales para tratar de encontrar similitudes en los distintos enfoques. El Método de Componentes es, sin lugar a dudas, el que más se utiliza en la práctica para efectuar proyecciones demográficas. El método como tal no ha variado en su esencia, y en términos generales se ha usado para estudiar el comportamiento futuro de los diversos componentes demográficos en forma separada, esto es, la fecundidad, la migración y la mortalidad para horizontes previamente determinados (George et al., 2004).
El Método de Componentes presenta variantes que permiten hacer supuestos acerca del patrón que siguen, por ejemplo, las tasas de mortalidad. A partir de los supuestos, las técnicas pueden agruparse de la siguiente manera: a) técnicas extrapolativas; b) métodos en que se piensa que la mortalidad de cierta área geográfica es válida para otras áreas; y c) modelos estructurales en que los cambios de las tasas de mortalidad se asocian con cambios en ciertas variables socioeconómicas. Para los grupos de técnicas a) y b), las posibilidades existentes incluyen el uso de modelos del tipo Auto-Regresivo Integrado y de Promedios Móviles (ARIMA), como sucede con el método que propusieron Lee y Carter (1992), o bien modelos paramétricos como los de Makeham, Gompertz o Helligman y Pollard, entre otros. De igual manera, las tablas de vida de diferentes lugares del mundo se pueden utilizar como tablas base de referencia, dentro de las cuales están las tablas modelo que presentan diferentes niveles de mortalidad y estructuras, así como la función logit y otras más.
Otros métodos que también se encuentran dentro de las categorías a) y b) tienen su fundamento en tablas límite de mortalidad, de manera que hacen uso de los niveles más bajos alcanzados para interpolar las tablas intermedias. La primera propuesta de tablas límite de mortalidad fue presentada por Bourgeois-Pichat (1952) con el supuesto principal de que los niveles límite se alcanzarían en el largo plazo. La hipótesis que subyace en este tipo de métodos surge de la idea de que la mortalidad cambia como función del nivel y la estructura de la mortalidad, dependiendo de la región del mundo a la que corresponda. Por otra parte, en lo que toca a los límites de la sobrevivencia humana los trabajos de Olshansky et al. (1990, 2001) y de Oeppen y Vaupel (2002) ofrecen aportaciones importantes a la literatura porque estudian la reducción en mortalidad que se necesita para alcanzar una esperanza de vida al nacer que aumente de 80 a 120 años y cómo puede afectar esto a distintas áreas de la política pública.
En el caso b), por ejemplo, se utiliza la técnica de alcanzar una meta establecida de antemano. Dicha técnica se basa en la idea de que, para una población dada, las tasas de mortalidad convergen con las que se observan en otra población y se consideran como una meta por alcanzar. La población meta en cuestión debe elegirse de manera tal que brinde un conjunto de metas creíbles que puedan ser alcanzadas por la población que se proyecta. La elección de la población meta se basa comúnmente en similitudes que se refieren a características culturales, socioeconómicas, avances en la medicina y a las causas primarias de mortalidad (Olshansky, 1988). Una alternativa de presentar las metas consiste en referirlas a lo que se conoce como retraso de la causa; con este tipo de enfoque la población meta que se elige es una cohorte más joven de la misma población en estudio, en lugar de la misma cohorte de una población diferente. El objetivo se ubica por lo general en las implicaciones que conllevan el retraso o la eliminación total de la ocurrencia de una o más causas de mortalidad (Manton et al., 1980 y Olshansky, 1987).
Metodología propuesta
Esta metodología surge al reconocer que existe una fuerte conexión entre suavizar una serie de tiempo y estimar su tendencia (Guerrero y Silva, 2010). De hecho, al suavizar una serie se busca un valor central que represente el comportamiento local de la variable, y eso es lo que en esencia se busca también al estimar la tendencia. Debido a ello conviene recordar algunos resultados importantes acerca de la estimación de tendencias para series de tiempo univariadas. En ese contexto la extracción de señal con el Filtro de Wiener y Kolmogorov, el Filtro de Kalman con suavizamiento y Mínimos Cuadrados Penalizados produce resultados que son equivalentes a los que arroja el Filtro HP que emplean los analistas de ciclos económicos. De manera semejante se ha demostrado que el método estadístico de estimación de MCG produce resultados idénticos a los que resultan de los filtros anteriores (Guerrero, 2007). Además, también se puede apreciar que el inverso de la matriz de Error Cuadrático Medio (ECM) es la suma de dos matrices de precisión. A partir de estos hechos Guerrero propuso medir la participación a la precisión de la tendencia estimada, que corresponde al elemento de suavidad del modelo estadístico implícito en el proceso de estimación. Esa medida de participación de la suavidad conduce a un índice de suavidad que depende sólo del parámetro de suavizamiento y del número de datos de la serie en estudio. Por lo tanto, dada una serie de longitud fija, el índice de suavidad brinda la posibilidad de decidir el valor del parámetro de suavidad como función sólo de un porcentaje deseado de suavidad, el cual puede elegirse en forma anticipada.
El enfoque tradicional para suavizar una serie de datos utiliza el parámetro de suavizamiento λ seleccionado con ayuda de algún criterio numérico, por ejemplo el criterio de Akaike, conocido como AIC, que se minimiza en forma automática sin que el analista se entere de los efectos de la elección que surja (a este respecto véase Hastie y Tibshirani, 1990). Sin embargo debe reconocerse que al suavizar los datos con un valor específico de λ se obtiene también un porcentaje de suavidad específico para la tendencia. Así pues, desde un punto de vista meramente descriptivo, un analista de los datos de la serie que aplique el suavizamiento debería, por lo menos, reportar el porcentaje de suavidad alcanzado con el parámetro λ que utilice. En esta línea de pensamiento se considera aun mejor fijar por adelantado un monto deseado de suavidad para la tendencia, en lugar de elegir el valor de λ en forma automática. Esta idea es semejante a la que respalda la costumbre actual de fijar de antemano el nivel de confianza (digamos en 95%) para estimar parámetros en un análisis estadístico, ya que así se pueden establecer comparaciones válidas entre dos o más intervalos de confianza. Este argumento se extiende en el presente trabajo al caso de fijar el porcentaje de suavidad, junto con el de estructura, que se pretende alcanzar con la estimación de la tendencia. Lo cual es necesario, de nuevo, para poder establecer comparaciones válidas. En resumen, lo que aquí se propone es calibrar los parámetros de suavidad y estructura que intervienen en el proceso de estimación de la tendencia de datos demográficos, de manera que se reduzca la subjetividad en el uso del procedimiento.
Es importante reconocer que el solo hecho de poder medir la suavidad con el índice propuesto permite al analista comparar los resultados de dos series suavizadas no sólo mediante inspección visual, sino numéricamente. Es en este sentido que la decisión acerca de cuál de las dos series tiene mayor suavidad se puede tomar objetivamente, o al menos con base en los datos disponibles, no en creencias subjetivas. Por estos motivos, la sugerencia que aquí se hace es usar el Filtro HPMV para estimar tendencias en datos demográficos incorporando las ideas de suavidad y estructura. Para presentar la propuesta formalmente se usará primero un modelo de señal más ruido, o sea,
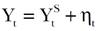 [7]
[7]donde Yt denota la variable de interés (digamos la mortalidad), Yt S es la señal, que en el presente caso representa la tendencia de la mortalidad suavizada, y ηt es el ruido, que básicamente oscurece el comportamiento de la tendencia, ya que en la práctica sólo se observa Yt. Al penalizar por falta de suavidad y alejamiento de estructura respecto a Yt S surge el siguiente problema de minimización:
 [8]
[8]Con δ t el error aleatorio asociado con un modelo demográfico en donde se hace uso de la variable Yt S. Este problema es similar al que plantea Boone (2000), mediante el cual se intenta estimar ahora los valores de Yt S como solución de [8].
Esta perspectiva consiste en definir primero un índice de suavidad que sirva de ayuda para elegir las constantes (1 y (2. La metodología propuesta brinda la posibilidad de interpretar entonces los resultados de acuerdo con una teoría demográfica que permite realizar comparaciones válidas entre tendencias de los datos. Dicha estimación se efectúa mediante un balance de los siguientes tres elementos: los datos observados originalmente, la suavidad de la tendencia que se obtenga como resultado, y la cercanía de dicha tendencia a cierta estructura teórica presupuesta como meta. El modelo estadístico que se emplea surge del planteamiento de las siguientes representaciones: i) los datos observados pueden expresarse como una tendencia oscurecida por un error aleatorio; ii) el patrón de suavidad subyacente de la tendencia es de carácter polinomial de orden uno; y iii) la estructura teórica que se supone como meta proviene de una fuente de información externa a los datos originales y sirve para incorporar una meta en los datos suavizados. Estas tres representaciones dan origen a las expresiones que siguen y que, en conjunto, forman el modelo
 [9]
[9]
 [10] y
[10] y
 [11]
[11]donde el símbolo ~ significa “distribuido como” (vector de medias, matriz de varianza-covarianza). De esta forma la ecuación [8] expresa el vector de datos originales como un vector de valores de tendencia Y S más un vector de ruido aleatorio η, con varianza de cada elemento dada por σ2 η. En [9] se tiene una ecuación que induce suavidad en el comportamiento Y S al suponer un patrón polinomial de grado uno, esto es, YS t = 2YS t-1 + YS t-2 + εt para t = 3, ..., n donde εt es un error aleatorio con varianza σ2 ε. Por último, en [10] se postula una experiencia demográfica con estructura límite o, dicho de otra manera, se hace uso de otra fuente de información para combinar sus datos con los que se observaron originalmente. A partir de las ecuaciones [9] a [11] se obtiene el sistema:
 [12]
[12]Por ello, se puede emplear MCG para estimar Y S y así se obtiene lo siguiente:
 [13]
[13]Entonces, si se hace λ1 = σ2 η/σ2 ε y λ2 = σ2 η/σ2 δ, se llega a
 [14]
[14]que es el estimador buscado, cuya matriz de varianza-covarianza está dada por
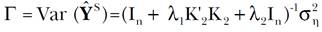 [15]
[15]Una manera alternativa de expresar los resultados anteriores surge al reconocer que Ŷ S = M(Y + λ2U) y que Γ = M σ2 n con M = (In + λ1 K’2 K 2 + λ2In)-1. Por lo tanto, si ahora se escribe
 [16]
[16]la ecuación [13] puede reescribirse como
 [17]
[17]Esta última expresión permite apreciar que Ŷ S → U si α → 0, de forma que la suavidad inducida por [10] desaparece y la tendencia converge a la estructura indicada en [11]. Por otro lado, si α → 1, Ŷ S → (In + λ1 K’2 K 2)-1Y y se obtiene entonces el resultado usual del Filtro HP. Debe notarse que el valor de α tiene que conocerse de antemano para calcular Ŷ S . Además, esta tendencia puede interpretarse como la combinación de dos fuentes de información cuyos pesos los decide implícitamente el analista al elegir el valor de la constante α. Existen dos posibles perspectivas para elegir los valores de las constantes de suavizamiento. La primera, llamada (A), indica elegir los valores de (1 y (2, de manera que se establezca un balance entre la suavidad y la estructura. A partir del conocimiento de (2 se obtiene el correspondiente valor de α. La perspectiva (B), en cambio, indica elegir los valores de (1 y α, de manera que se tiene que decidir en principio el porcentaje de suavidad y después cuál de las dos fuentes de información (la observada y la propuesta como meta) tiene mayor credibilidad. Desde el punto de vista del cálculo de la estimación numérica de los valores de tendencia, el vector suavizado Ŷ S se puede obtener directamente al aplicar el Filtro de Kalman con suavidad. Para aplicar este filtro se debe notar que los modelos [9] y [11] producen las expresiones siguientes, válidas para todo valor de t,
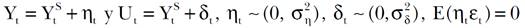 [18]
[18]por lo cual se sigue que
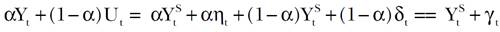 [19]
[19]con
 [20] y
[20] y
 [21]
[21] A partir de estas ecuaciones puede escribirse un Modelo de Espacio de Estados con las siguientes ecuaciones de medición y transición, respectivamente:
 [22] y
[22] y
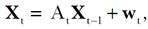 [ 23]
[ 23]donde los vectores y matrices involucrados son de la forma
 [24]
[24]Una vez expresado el modelo en forma de espacio de estados es factible utilizar el Filtro de Kalman como en Guerrero, 2008, pero en lugar de usar los datos originales Yt como en aquel artículo, ahora se hace uso de los datos combinados αYt + (1 - α)Ut, para lo cual se requiere que el valor de α sea conocido.
Los índices de suavidad y su empleo para elegir las constantes de suavizamiento
Para medir la proporción de suavidad relativa σ-2 ηIn respecto a la precisión total que se logra con el proceso de estimación, que está dada por σ-2 ηIn + σ-2 δIn + σ-2 ε K ’ 2 K 2 se propone utilizar el índice
 [25]
[25]en donde tr(.) denote la traza de una matriz, mientras que σ-2 ηIn, σ-2 δIn y σ2 ε K ’ 2 K 2 son matrices positivas definidas de dimensión n × n. Este índice es una medida que cuantifica la precisión relativa y que tiene las siguientes cuatro propiedades: 1) toma valores dentro del intervalo (0, 1), de manera que puede interpretarse como una proporción propia; 2) es invariante bajo transformaciones lineales de la variable Y involucrada, por lo cual los resultados son válidos aun si se transforma la variable linealmente; 3) se comporta en forma lineal, de manera que pueden aplicarse directamente herramientas de álgebra lineal para hacer los cálculos necesarios; 4) la suma de las precisiones relativas es la unidad, lo cual significa que
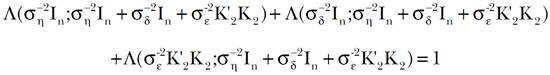 [26]
[26]La demostración de que Λ es la única medida escalar que cumple con las cuatro propiedades enunciadas previamente, se sigue de la prueba que aparece en Theil, 1963, para el caso de dos matrices positivas definidas A y B, donde el índice está dado por Λ(A; A+B). Lo que se requiere para adaptar la prueba a la situación presente es reconocer que, por ejemplo, ahora σ-2 ηIn juega el papel de A y la matriz σ-2 δIn + σ2 ε K ’ 2 K 2 juega el de B. Este índice es útil para cuantificar la precisión relativa atribuible a la suavidad y a la estructura inducida en el modelo, que forman parte de la matriz de precisión Γ-1 dada por el inverso de [15]. En consecuencia, se define el índice de suavidad
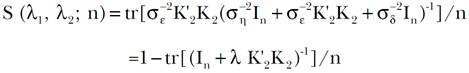 [27]
[27]Con
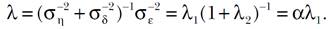 [28]
[28]Ahora bien, como el parámetro ( está asociado con la suavidad de αY + (1 - α)U, su valor se puede elegir con la ayuda del índice de suavidad S((1, (2; n). Posteriormente, ya que el parámetro (1 se asocia con la suavidad de los datos originales Y, puede obtenerse a partir de los valores de ( y α; esto se debe a que (1=(/α con α > 0. Otra forma de seleccionar los parámetros necesarios comienza por elegir a (1 de manera que se fije la suavidad deseada para Y y después se elige el valor de α ∈(0,1) entonces se deduce el valor de (=α(1 que sirve para determinar la suavidad de la combinación convexa αY + (1 - α)U.
Debe notarse que el porcentaje de suavidad para Y debe ser mayor o igual que el de la combinación debido a que: i) λ = αλ1 ≤ λ1, pues 0 < α ≤ 1, y ii) el índice de suavidad es una función monótona creciente de λ. Además, el parámetro λ1 se elige a partir del índice de suavidad S(λ1; n) = 1- tr[In + λ1K'2K2)-1]/n, el cual se asocia con la suavidad de Y, puesto que equivale a usar el índice de suavidad aplicable a αY + (1 - α)U cuando α = 1, en cuyo caso λ2 = 0 y el estimador de la tendencia resulta ser Ŷ S = (In + λ1 K’2 K 2)-1Y. Desde luego, para incluir tanto la suavidad como la estructura demográfica en la solución, se debe elegir α ϵ (0, 1), de manera que se obtenga λ2 > 0 y se utilice el estimador dado por Ŷ S = (In + αλ 1 K’2 K 2)-1 (αY + (1- α)U). Por último, es importante hacer la siguiente aclaración acerca del máximo porcentaje de suavidad que puede lograrse con un conjunto de datos determinado. Debido a que tr[(In + λK'dKd)-1] → d conforme λ → ∞ con d el orden de las diferencias en la matriz Kd (Eilers y Marx, 1996: 94), se sigue que la máxima suavidad que se puede alcanzar con n observaciones cumple con S(λ; n) → 1 - d/n conforme λ → ∞. Este resultado es útil para conocer de manera anticipada el máximo porcentaje de suavidad que es factible alcanzar en aplicaciones prácticas y con base en ello decidir la suavidad deseada para la tendencia.
A continuación se muestra la estrategia para suavizar un conjunto de datos {Y1, ..., YN} con el Filtro HPMV, de manera que se incorpore la información de los datos de estructura demográfica {U1, ..., UN}. Se aplican las siguientes etapas, las cuales difieren sólo en la segunda para las perspectivas (A) y (B): 1. Suavizar los datos {Y1, ..., YN} sin considerar la existencia de {U1, ..., UN}. Para esto se fija primero un porcentaje de suavidad deseado para la tendencia y se aplica el procedimiento de Guerrero, 2008. Como resultado se deduce el valor de λ1 y se obtiene la tendencia con suavidad de 100S(λ1; n)% (por ejemplo, de 80%). 2. A. Decidir el porcentaje de suavidad que será intercambiado por estructura de manera que el porcentaje de suavidad de la tendencia se reduzca (digamos de 80% a 75%). Para lograr esto se fija el valor de 100S(λ1, λ2; n)% y se obtiene el valor que corresponda para α ∈(0,1). 2. B. Decidir la credibilidad que se le asigna a cada una de las estructuras de datos disponibles (la observada y la considerada como meta) al fijar el valor de α ∈(0,1), y simplemente medir la suavidad que se haya obtenido como resultado. 3. Aplicar el procedimiento de suavizamiento con estructura mediante la aplicación del Filtro de Kalman al conjunto de datos {αYt + (1 - α)Ut}. El suavizamiento que se logre con esto tendrá suavidad de 100S(λ1, λ2; n)% y porcentaje de estructura (es decir, cercanía a U) de 100[S(λ1; n) -S(λ1; n)]%.
Aplicaciones a datos demográficos de México
En las siguientes aplicaciones se ilustran las dos perspectivas que se sugieren en el marco teórico del trabajo. Por un lado, se presentan ejemplos donde se combinan fuentes de información para obtener tendencias estimadas a partir del nivel de credibilidad que el analista otorgue a cada fuente. Por otra parte, se presentan aplicaciones donde se maneja una estructura por edades de un indicador demográfico para algún país que esté en su última etapa de transición demográfica y se considera a esta estructura como meta futura, a la cual se pretende que aspire la situación actual mexicana para un determinado horizonte de previsión. De acuerdo con estas dos perspectivas, se rebasa la eventual dificultad que pudiese representar la distinta longitud de las series de indicadores demográficos utilizados, gracias a la utilización del Filtro de Kalman. En general se hablará de tendencias en un sentido amplio y no exclusivamente en términos predictivos.
Mortalidad en la Ciudad de México en el siglo XVIII
Se muestra que la metodología presentada constituye una herramienta útil en la tarea de aproximar la mortalidad de la población de la Ciudad de México en el siglo XVIII. Se tienen datos de naturaleza paleodemográfica que se obtuvieron en dos momentos diferentes: 1976 y 1982 (Hernández, 1999). Tales datos fueron generados a partir de restos óseos ubicados en la Catedral Metropolitana de la Ciudad de México. En el primer momento de 1976 se observó un total de 1 642 individuos, con una esperanza de vida promedio de 24 años. Estos restos corresponden a una población civil integrada mayoritariamente por criollos y españoles peninsulares, y en menor medida por mestizos e indígenas (Márquez y Civera, 1987). El segundo momento fue en 1982, cuando se tuvo acceso a una serie de datos de restos para otra población civil, principalmente mestiza y probablemente contemporáneos a los estudiados en 1976. Estos últimos con una esperanza de vida de 22.6 años (Hernández, 1991).
La idea es estimar una tendencia única que proporcione una visión de la mortalidad en dicho siglo en la Ciudad de México, es decir, se pretende combinar la información generada en ambos momentos. Al hacer esto se puede otorgar mayor o menor credibilidad a las fuentes de acuerdo con las creencias o conocimientos que tenga a priori el analista. En la gráfica 1, donde se usan logaritmos de la mortalidad (Log(qx)), se aprecia que el tamaño de las series es distinto. Sin embargo esto no representa un problema adicional, pues con la metodología propuesta se genera una tendencia tan larga como sea la serie de mayor longitud, en este caso la de 1976. Se puede apreciar que las tasas de mortalidad de 1976 son más bajas desde los 20-24 años de edad que con la base de datos recabados en 1982 y ocurre a la inversa para antes de los 20 años de edad. Se decidió iniciar el procedimiento con los datos de la serie más reciente, es decir, con los correspondientes a 1982 (CMT82). Cabe advertir que se podría haber elegido como datos iniciales los de 1976 (CMT76) y se tendría una gran similitud de los resultados en general. Con 70% de suavidad, se puede apreciar en la gráfica 2 la tendencia de dichos datos y, con base en la tendencia estimada, se podría apreciar cuáles hubiesen sido los niveles de mortalidad para grupos de edades que rebasan incluso los que no se estimaron en dicha fuente.
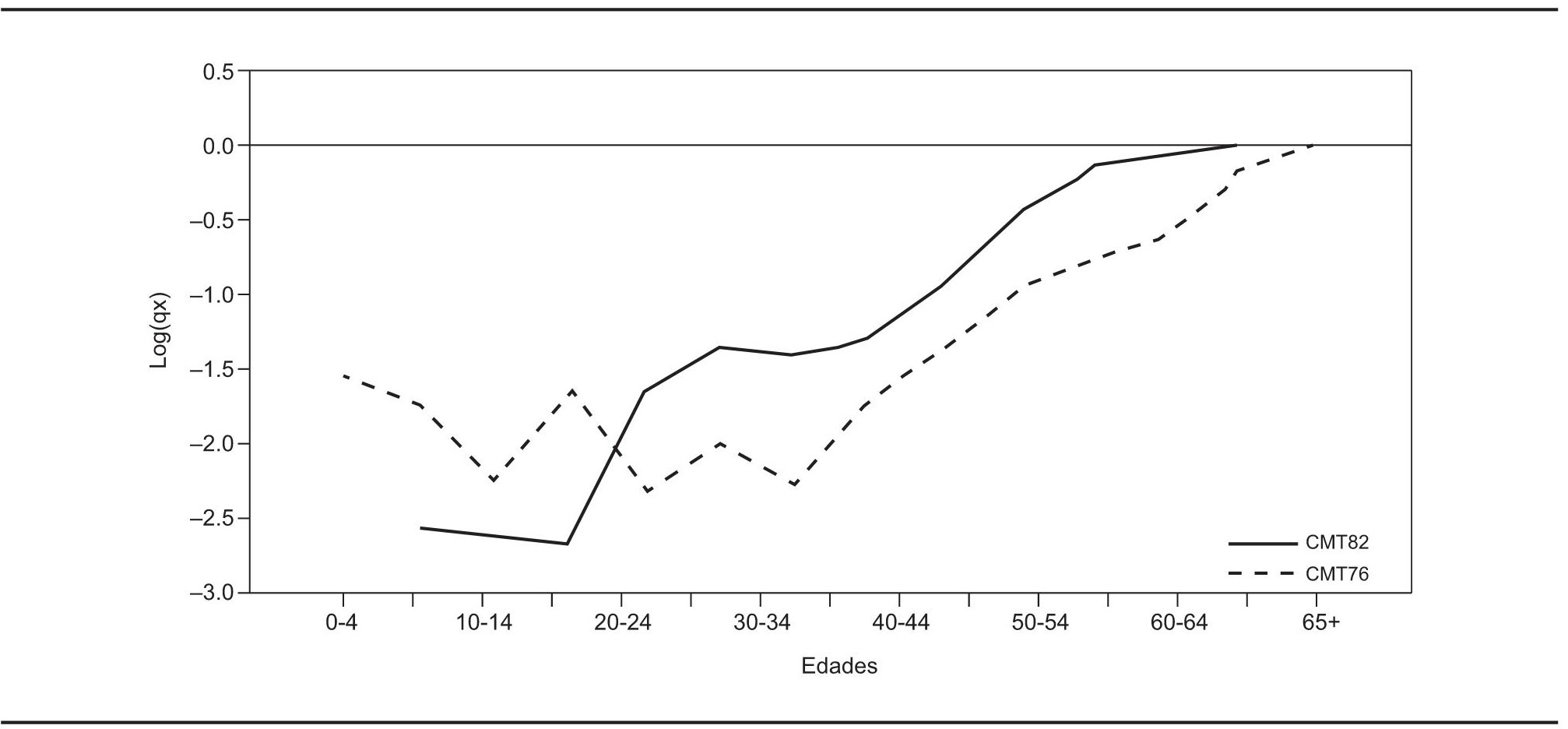
FUENTE: Logaritmos de tasas de mortalidad de Hernández, P. (1999), “Los estudios paleodemográficos en México”, Revista Argentina de Antropología Biológica, vol. 2, pp. 335-355.
GRÁFICA 1. Mortalidad en la Ciudad de México en el siglo XVIII con CMT76 y CMT82
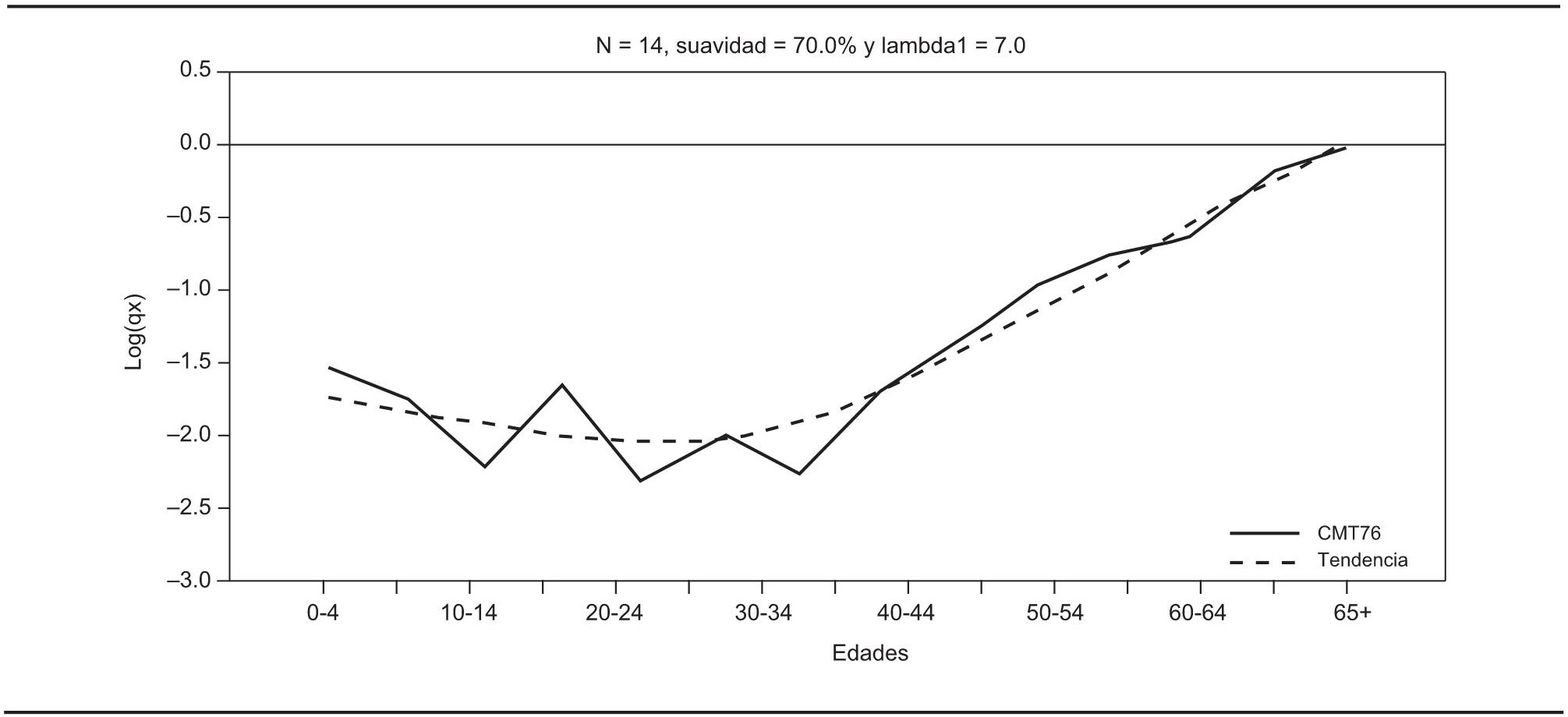
FUENTE: Cálculos propios y logaritmos de tasas de mortalidad de Hernández, 1999.
GRÁFICA 2. Tendencia estimada para los datos de 1982
Si se estima la tendencia considerando la mortalidad de 1976 se observa en la gráfica 3 que el procedimiento trata de conciliar las dos fuentes y que se preservan las características de ambas tendencias. Al intercambiar suavidad por estructura, se eligió 65% de suavidad y, en este caso, se otorgó la misma credibilidad a ambas fuentes, i. e., se usó α = 0.50.
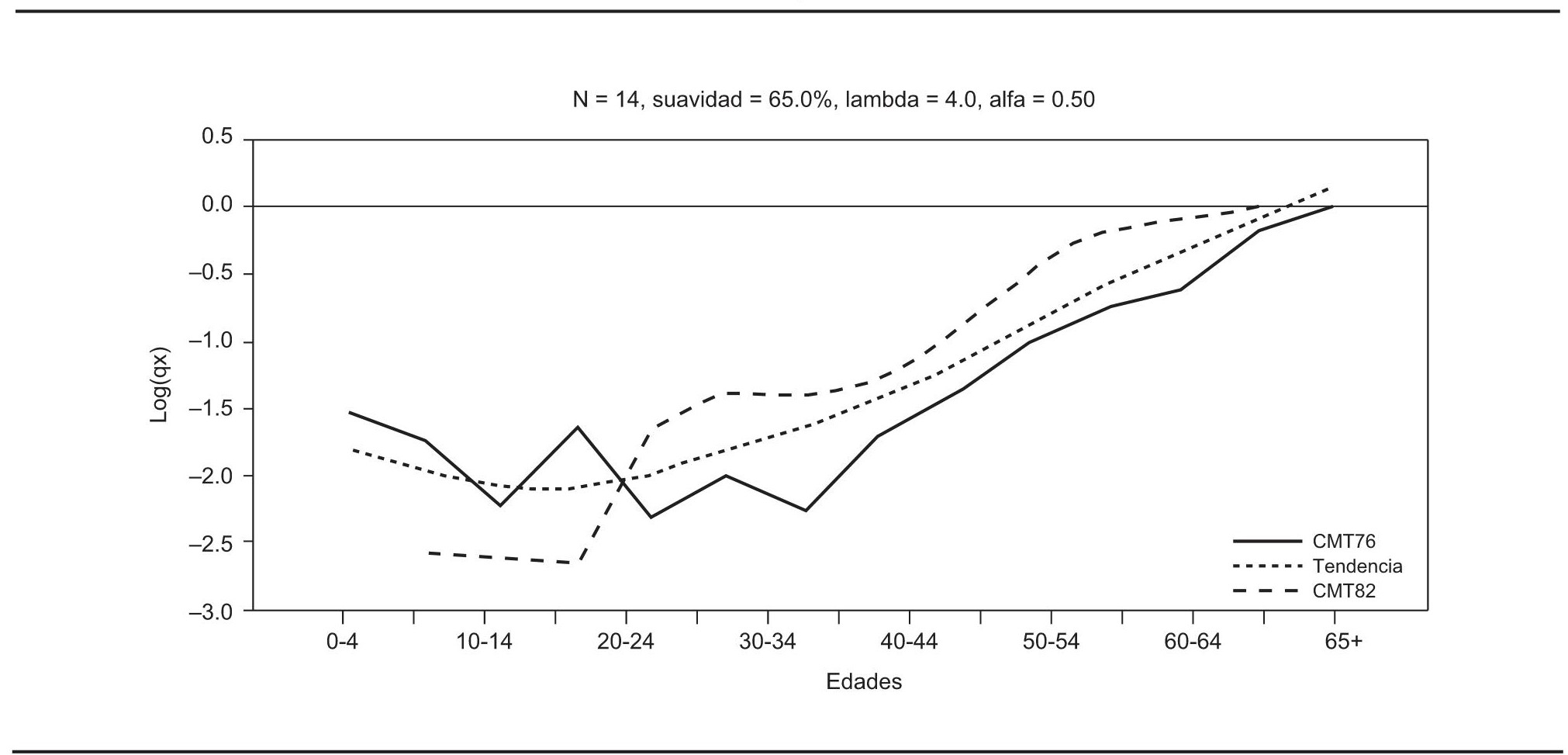
FUENTE: Cálculos propios y logaritmos de tasas de mortalidad de Hernández, 1999.
GRÁFICA 3. Tendencia estimada con ambas fuentes de información: 1976 y 1982
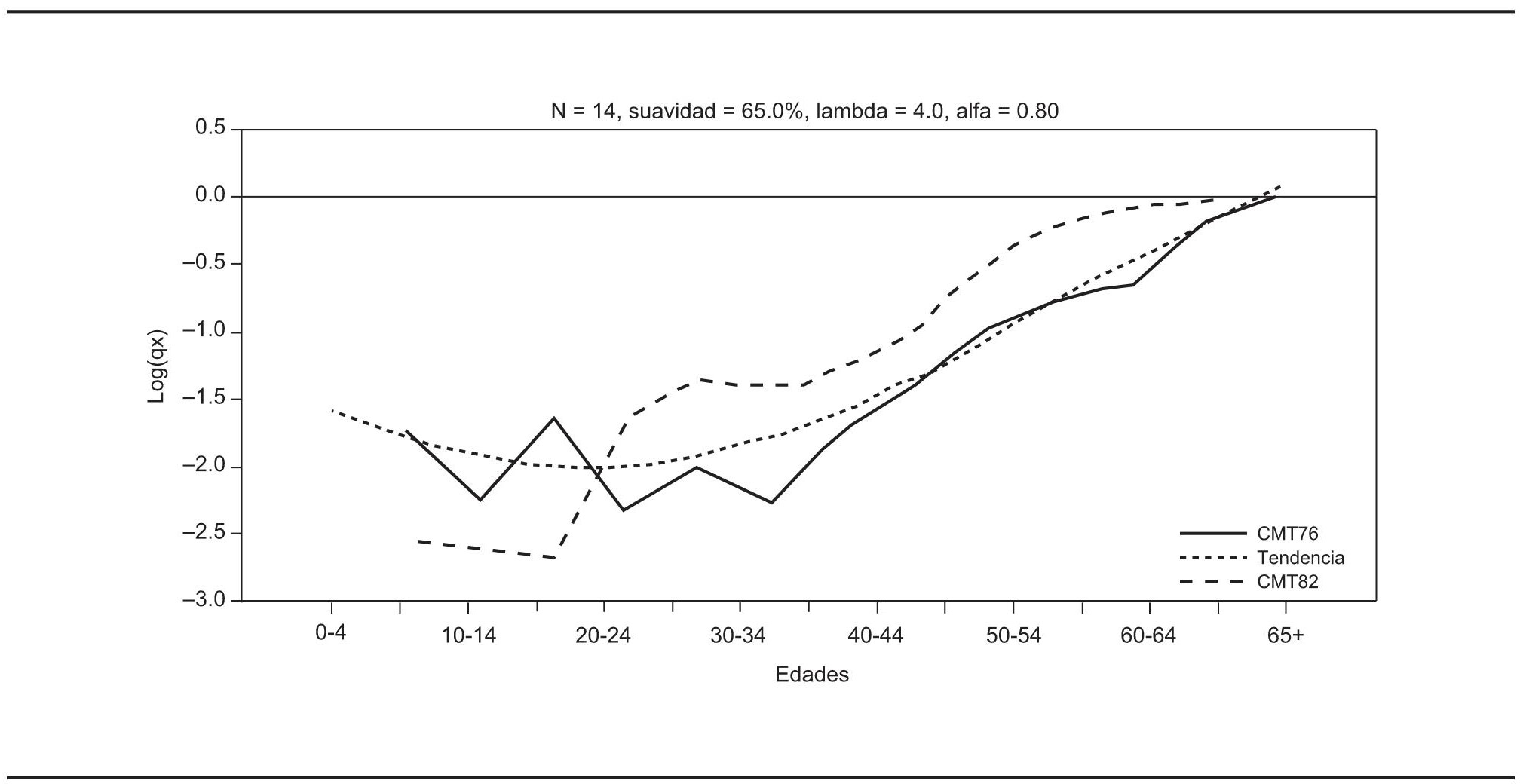
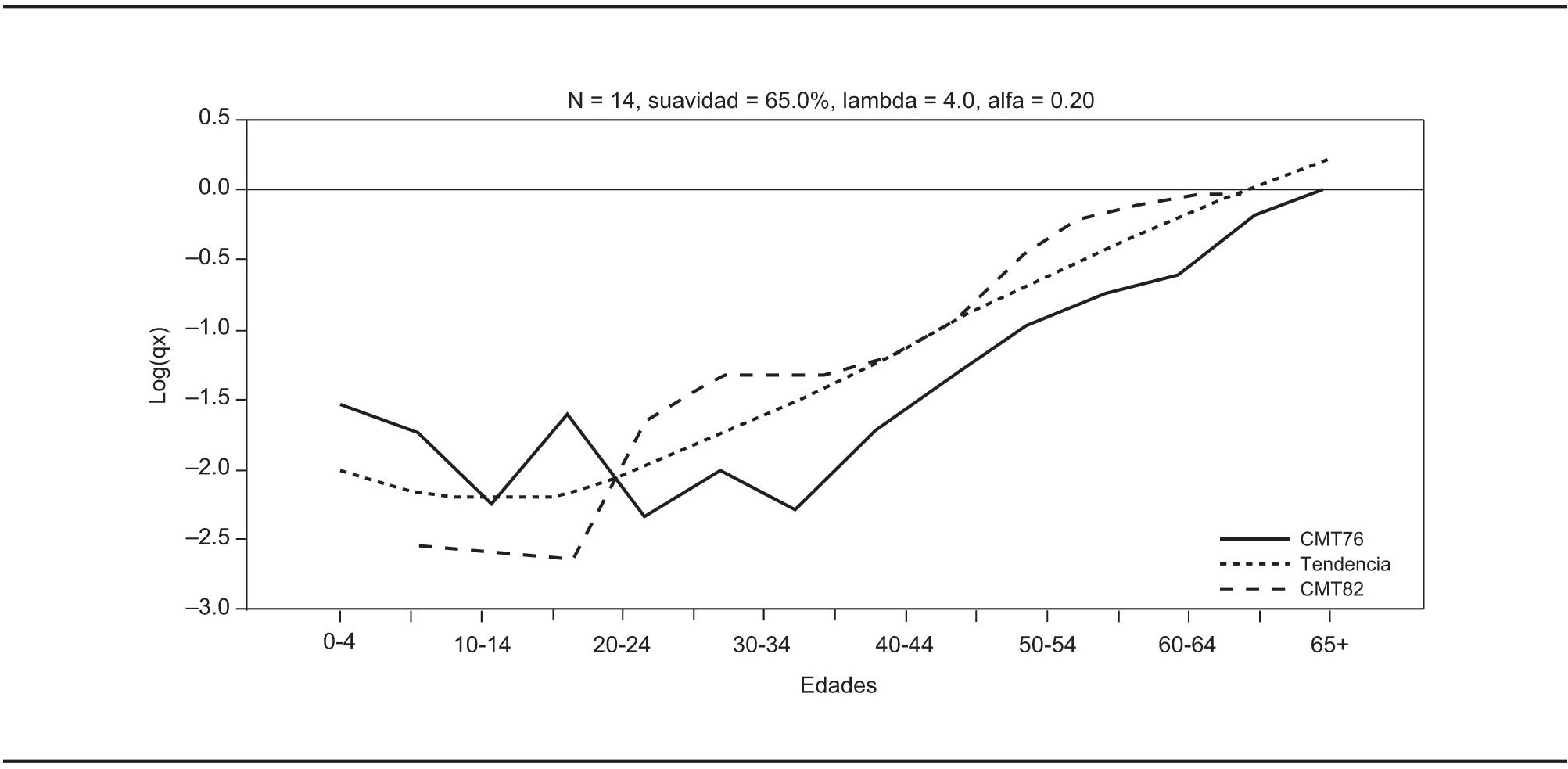
La propuesta metodológica de ninguna manera excluye la posibilidad de que el analista decida asignar distinta credibilidad a las fuentes, con base en sus conocimientos adicionales derivados de su cercanía con el tema de investigación. Así pues, con fines puramente ilustrativos se supondrá que se desea otorgar distinta credibilidad a las fuentes y con ello se puede apreciar que la tendencia estimada se apega más a la fuente que el analista considera más confiable. En primer lugar, al otorgar mayor credibilidad a los datos de 1976 con α = 0.20 se obtiene la gráfica 4. Posteriormente se asigna mayor credibilidad a los de 1982 al elegir α = 0.80 y se obtiene la gráfica 5. Así pues, la credibilidad de las fuentes se otorga mediante el valor del parámetro α de la expresión [17], de manera que una situación neutra o de misma credibilidad para ambas fuentes conduce a utilizar α = 0.50.
FUENTE: Cálculos propios y logaritmos de tasas de mortalidad de Hernández, 1999.
GRÁFICA 4. Tendencia estimada con mayor credibilidad asignada a los datos de 1976
FUENTE: Cálculos propios y logaritmos de tasas de mortalidad de Hernández, 1999.
GRÁFICA 5. Tendencia estimada con mayor credibilidad en los datos de 1982
Hacia una fecundidad típica de la cuarta etapa de la transición demográfica
Por medio de la presente propuesta metodológica es posible hacer aplicaciones tocantes a la fecundidad, por ejemplo considerar la fecundidad masculina mexicana en relación con la de otro país más avanzado en su transición demográfica, o bien estimar la fecundidad “mixta” a partir de los reportes de la fecundidad femenina y masculina existentes en México (Quilodrán y Sosa, 2001). En particular, en la aplicación de esta sección se emplean las tasas específicas de fecundidad de Suecia de 2006 <http://www.humanfertility.org> y se les visualiza como una meta de estructura demográfica de fecundidad que se aspiraría fuera alcanzada por todas las edades de la población femenina de México en un horizonte de n décadas. Para el caso mexicano se parte de estimaciones de Conapo, 2006.
En la gráfica 6 se aprecia la diferencia estructural entre ambas experiencias de fecundidad. La mexicana es asimétrica a la derecha y parece bimodal, mientras que la sueca es sencillamente simétrica. También se observa que las colas de la distribución sueca son más consistentes con lo que plantea la teoría al inicio y al final de las edades fecundas. Dentro de este mismo rubro, en el caso mexicano se podría pensar que el registro de fecundidad no obedece necesariamente a los mejores estándares del mundo o, al menos, es claro que difiere bastante del de Suecia.
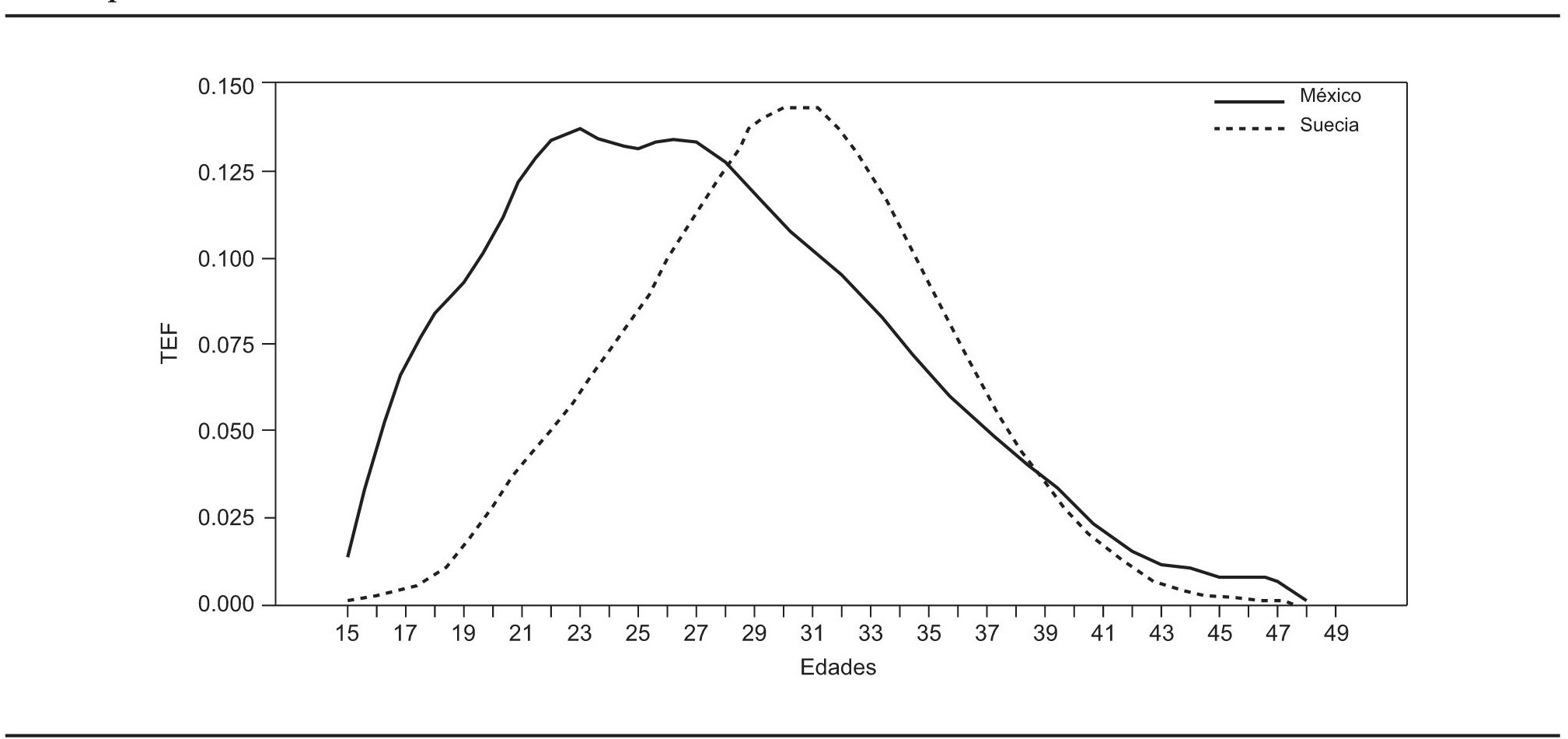
FUENTE: Tasas específicas de fecundidad de Suecia de 2006, disponible en <http://www.humanfertility.org> y Conapo, 2006, Indicadores demográficos básicos, México <http://www.conapo.gob.mx> (11 de marzo de 2006).
GRÁFICA 6. Tasas específicas de fecundidad
En este ejemplo se eligen como datos iniciales a los de México y se estima su tendencia con suavidad de 75%. Como se advierte en la gráfica 7, la tendencia estimada queda ligeramente por encima para las edades iniciales, en la parte superior la situación de aparente bimodalidad se atenúa, y al final de las edades la estimación se vuelve suave, pero la condición de asimetría se preserva. Como se expone en el algoritmo del procedimiento, ahora se reemplaza cierto porcentaje de suavidad por estructura. En este caso, al intercambiar suavidad por estructura, la gráfica 8 muestra que se alcanza una suavidad de 70.9 por ciento.

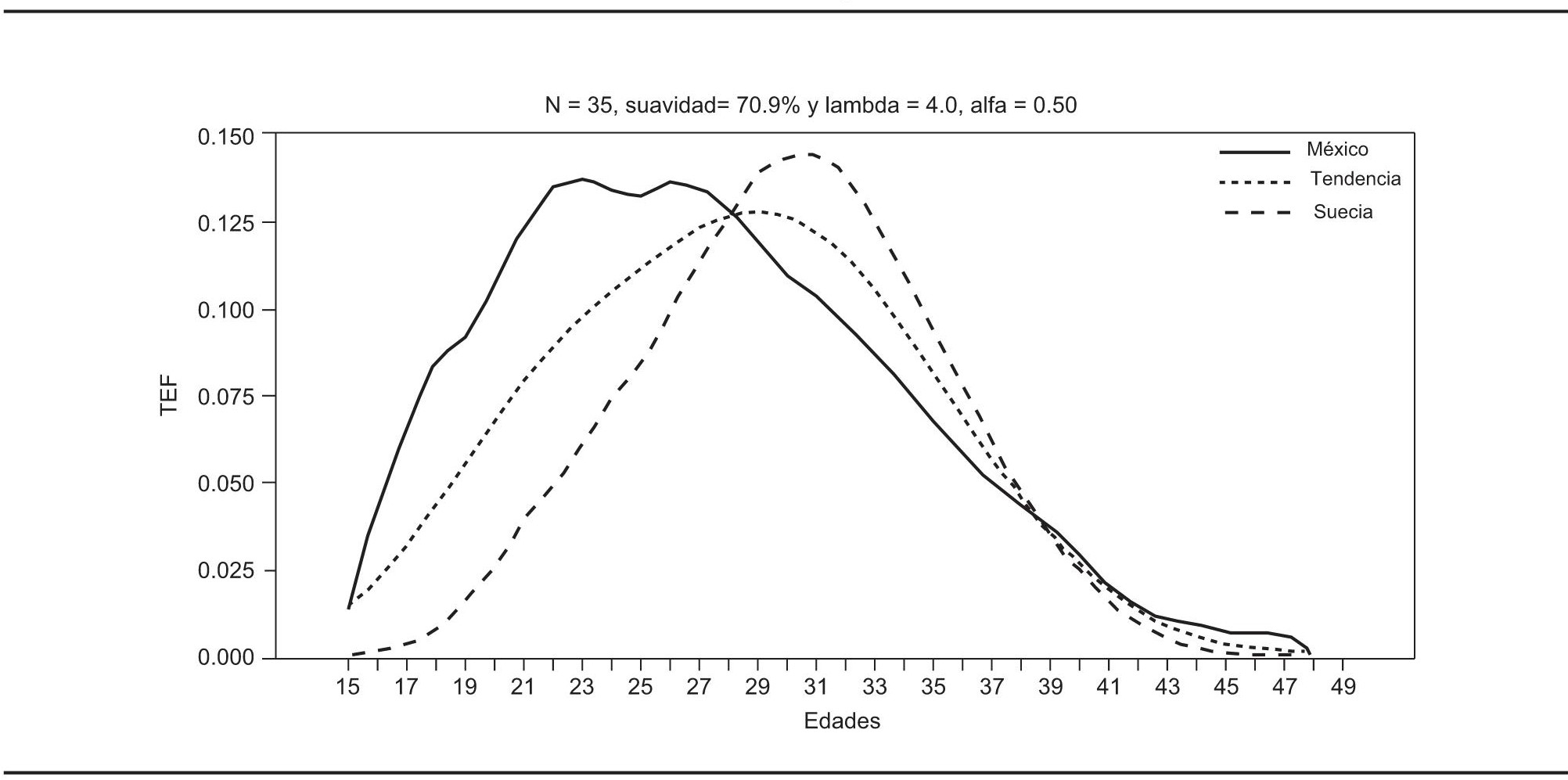
FUENTE: Cálculos propios con datos del Conapo, 2006 y <http://www.humanfertility.org>.
GRÁFICA 8. Tendencia estimada con las estructuras de fecundidad de México y Suecia
De esta manera se percibe la estructura a la que podría aspirar la fecundidad mexicana en cierto horizonte de décadas por definir, en relación con la estructura sueca. Es importante notar que la tendencia estimada busca apegarse a la estructura sueca sin alejarse por completo de la estructura mexicana. Debe ser claro que el horizonte asociado con la transición de una estructura a otra depende en gran medida de la agudeza y del conocimiento que el analista tenga sobre el tema. Nótese que la tasa específica de fecundidad en edad 15 es la misma entre la tendencia y la mexicana, y también se podría decir que la masa de la función de distribución de las probabilidades de fecundidad se redistribuye en un rango más amplio de edades. Desde luego esta estructura conllevaría nuevos retos en cuanto a las políticas de salud pública de los mexicanos, entre otras muchas implicaciones.
Estimaciones de mortalidad infantil en México (1990-2020)
La tasa de mortalidad infantil tiene un gran impacto en el cálculo de la esperanza de vida al nacer y constituye un indicador del desarrollo social y económico de un país. Por ello las discrepancias que pudieran existir entre distintas fuentes sobre este indicador pueden conducir a diferentes perspectivas sobre la situación real en determinada nación. Así pues, se considera oportuno hacer una aplicación que combine dos fuentes de información respecto de la mortalidad infantil para el caso mexicano. En primer término se emplean las estimaciones de Aguirre (2009), y en segundo las que elaboró Conapo (2010). La longitud de las series es distinta en cada caso, por lo que la estimación de la tendencia con la metodología propuesta será tan larga como la serie de Conapo.
Una vez realizada la estimación de la tendencia con determinado porcentaje de suavidad, se contrastan los resultados con las cifras que reporta la Secretaría de Salud (SS). De esta manera, en principio se genera una estimación de la tendencia de la mortalidad infantil en México para el periodo 1990 a 2020. Como se ilustra en la gráfica 9, desde 1990 hasta 2005 las estimaciones que elaboró Conapo superan a las de Aguirre: la diferencia es más elevada al inicio y se reduce hacia 2005. Por otro lado, se observa que los datos de la Secretaria de Salud de 2000 a 2008 no presentan claramente una tendencia similar a la de las otras dos fuentes; de hecho parece que el valor de este indicador es relativamente constante durante el periodo de referencia.
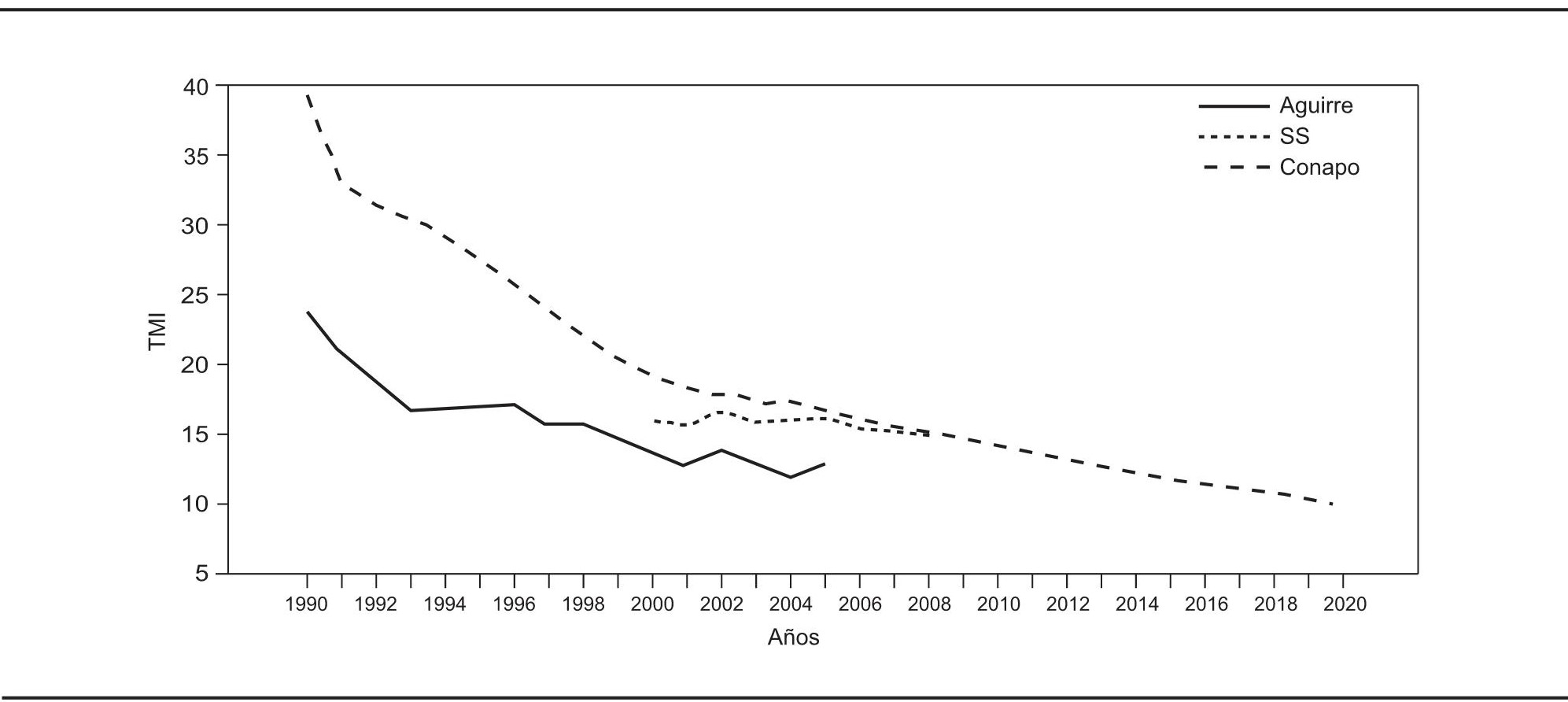
FUENTE:Aguirre, A. (2009), “La mortalidad infantil y la mortalidad materna en el siglo XXI”, Papeles de Población, núm. 15, pp. 75-99; Conapo (2010), Indicadores demográficos básicos, México, Consejo Nacional de Población, disponible en <http://www.conapo.gob.mx> (11 de agosto de 2010) y datos de la Secretaría de Salud, 2000-2008, disponible en <http://www.sinais.salud.gob.mx/mortalidad> (11 de agosto de 2010).
GRÁFICA 9. Tasas de mortalidad infantil en México con tres fuentes distintas
Para esta aplicación se eligieron como datos iniciales los de la serie de estimaciones de Aguirre, que incluye una cantidad de datos menor que la de Conapo. Se propuso entonces una suavidad de 75% y, como se observa en la gráfica 10, se genera una tendencia cuya curvatura es acorde con las previsiones que elaboró dicho especialista. Como valor agregado se obtienen estimaciones subsecuentes, o vistos de otra forma, pronósticos de la tasa de mortalidad infantil desde 2006 hasta 2020. Nótese que esto ocurre como consecuencia de la extensión de la serie de Conapo y del uso del Filtro de Kalman.
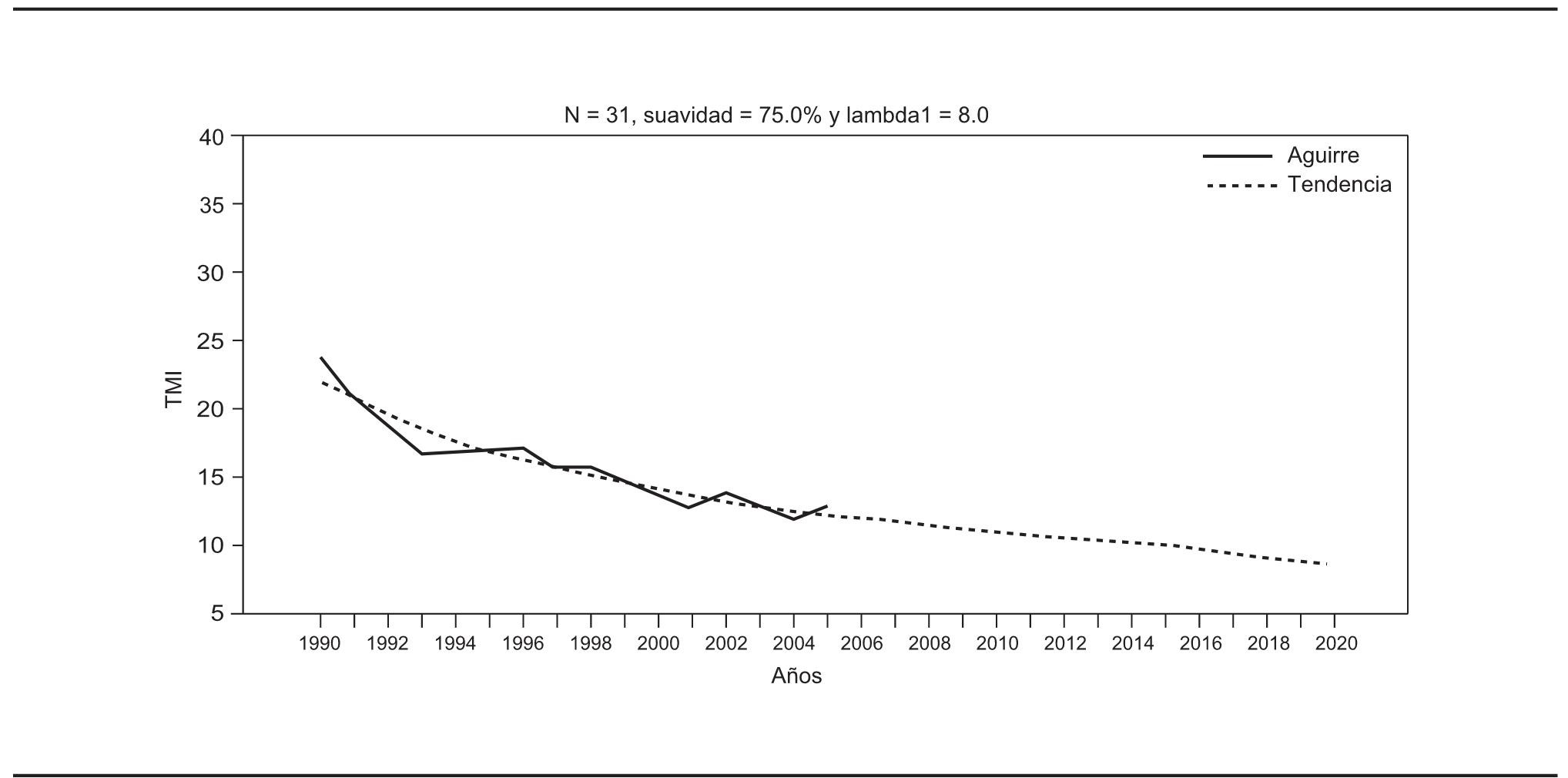
FUENTE: Cálculos propios con datos de Aguirre, 2009.
GRÁFICA 10. Tendencia inicial con datos de Aguirre
Al intercambiar una parte del porcentaje de suavidad inicial de 75% por estructura, se obtiene una suavidad final de 70.6%, como se presenta en la gráfica 11. Por otra parte, se decidió brindar la misma credibilidad a ambas fuentes de información, es decir, se eligió α = 0.50. Con estos parámetros se genera una tendencia que cubre el periodo de 1990 a 2020, donde se aprecia un cruce entre la tendencia estimada y las proyecciones de Conapo de 2014 y 2015. Asimismo, las cifras que reporta la Secretaria de Salud muestran una dinámica distinta de la tendencia estimada a partir de las fuentes iniciales, aunque también se produce un cruce en el año 2001.
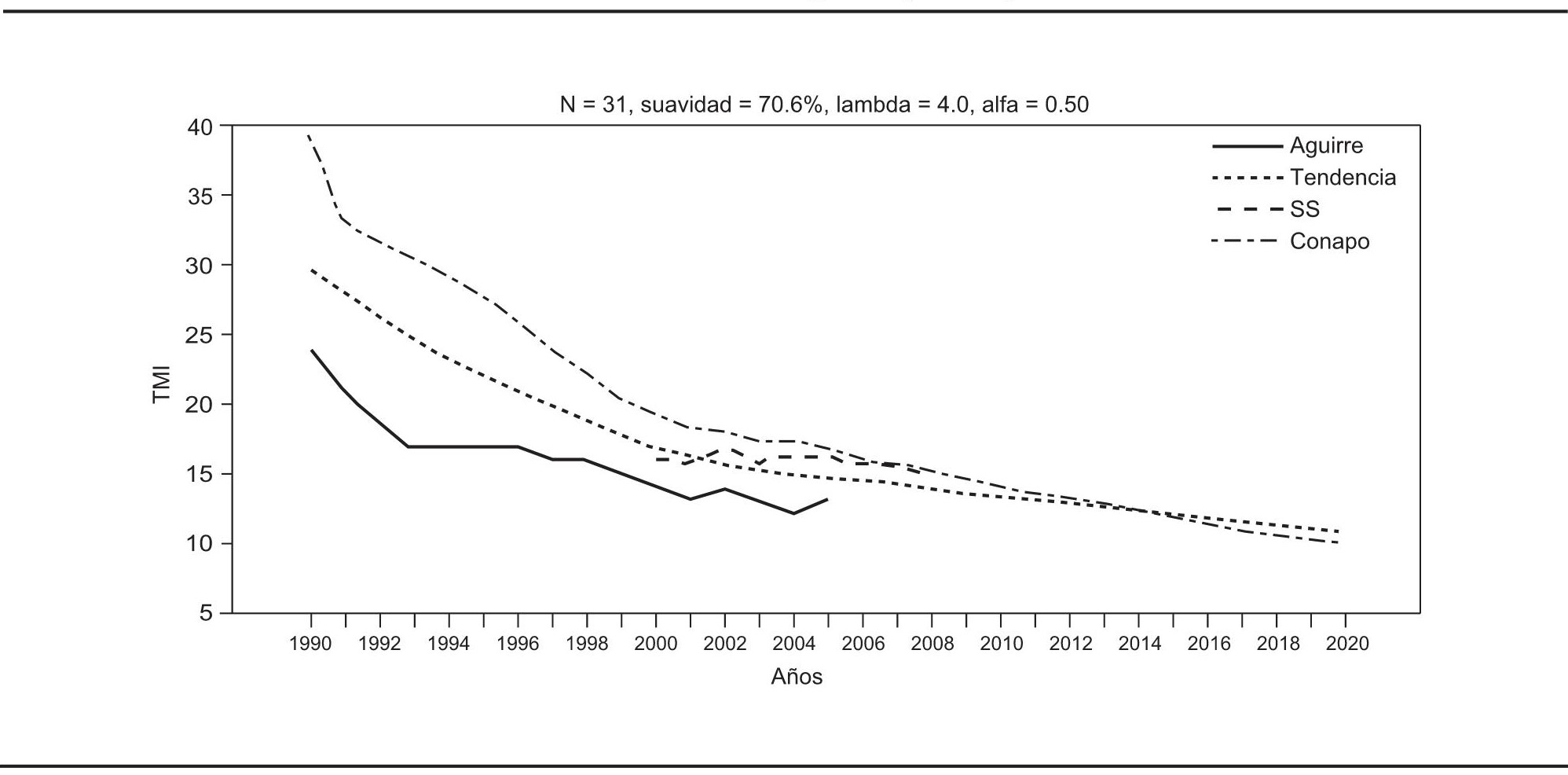
FUENTE: Cálculos propios con datos de Aguirre, 2009 y Conapo, 2010.
GRÁFICA 11. Tendencia estimada con las fuentes de información de Aguirre y Conapo combinadas
Hacia una mortalidad típica de la cuarta etapa de la transición demográfica
Para elaborar proyecciones de población desde una perspectiva demográfica el método más empleado es el de Componentes, según se mencionó en la tercera sección. Con este método, de manera resumida, se proyectan las variables demográficas de mortalidad, fecundidad y migración, y se generan escenarios sobre lo que se espera en el futuro con base en el conocimiento y la experiencia del analista. Dentro de la tarea predictiva de la variable de mortalidad existen varias alternativas, como son: el uso de tablas límite de mortalidad, la suposición de determinado comportamiento de mortalidad dentro de un contexto ubicado en la última parte de la transición demográfica, etcétera. Es en este espacio donde también se tiene oportunidad de aplicar la propuesta metodológica de manera natural.
En este ejemplo se presenta una estimación de estructura con suavidad de mortalidad mediante una tendencia generada para la experiencia mexicana de 2010 (MXH10) y la japonesa de 2008 (JPH08), en el supuesto de que en cierto horizonte de “H” décadas se presentará tal comportamiento. Para hacer la aplicación se usan las tasas específicas de mortalidad por sexo que elaboró Conapo (2010) y para Japón las de la base de datos de <http://www.mortality.org>. En otras palabras, se estima la tendencia de manera que el escenario actual mexicano aspire al escenario de Japón. Cabe advertir que se tienen resultados análogos tanto de estructura como de suavidad al hacer la aplicación con datos del sexo femenino o bien para el total de la población.
Conviene destacar algunos detalles de la gráfica 12, por ejemplo que la serie de Japón llega hasta los 110 años, mientras que la mexicana se queda en 100 (pese a ello la metodología es aplicable); además, en ambas experiencias de mortalidad se presenta el comportamiento típico de las distintas etapas de la vida, como se ha propuesto en la literatura (Thiele, 1871; Heligman y Pollard, 1980), y también se observa que en casi todo el rango de las series la mortalidad japonesa es inferior hasta el entorno de los 85 años de edad, desde donde la mexicana se vuelve más baja. En este sentido se debe tomar en cuenta que lo que se considera como experiencia mexicana son estimaciones, no datos observados, por lo cual también se explica la suavidad de la serie mexicana frente a la japonesa (sin que se haya aplicado el método aquí propuesto a los datos nacionales). Por último, la serie japonesa a partir de los 85 años presenta una ligera curvatura, semejante a las respectivas experiencias de mortalidad que se observan en algunos países altamente desarrollados y que se han documentado ampliamente en la literatura demográfica (véase Ham, 2005).
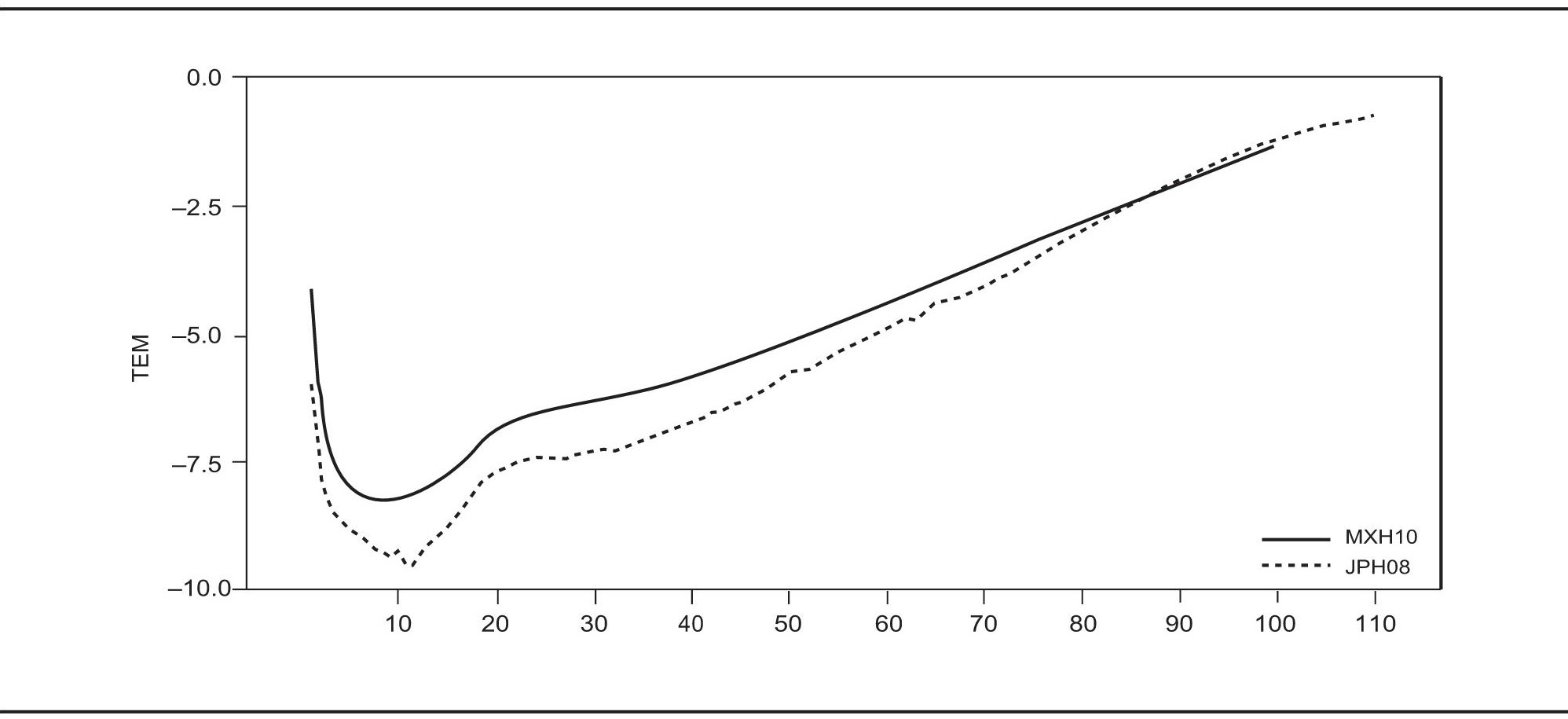
FUENTE:Conapo (2010), Indicadores demográficos básicos, México, Consejo Nacional de Población, disponible en <http://www.conapo.gob.mx> (11 de agosto de 2010), y para Japón disponible en la base de datos <http://www.mortality.org> (11 de agosto de 2010).
GRÁFICA 12. Tasas específicas de mortalidad masculina para México en 2010 y Japón en 2008
No se requiere una suavidad alta para estimar la tendencia de la serie mexicana, y con 65% de suavidad se obtienen resultados satisfactorios (véase la gráfica 13). Por medio de la aplicación de la metodología, la tendencia llega hasta los 110 años de edad, límite de edad máximo de la serie japonesa, y la estimación para niños menores de un año queda ligeramente baja.
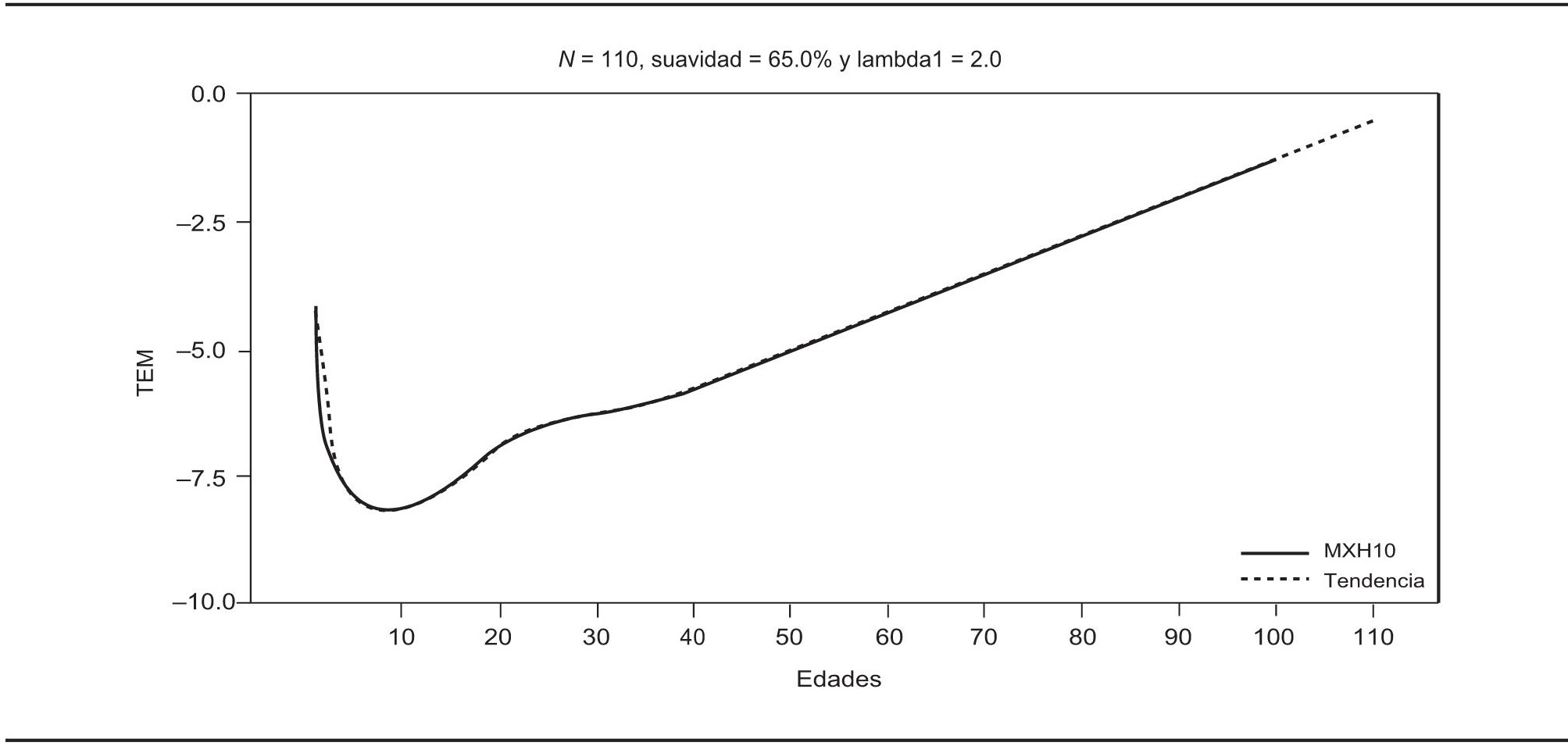
FUENTE: Cálculos propios y Conapo, 2010.
GRÁFICA 13. Tendencia inicial para las tasas específicas de mortalidad masculina en México
Posteriormente, al asignar la misma credibilidad a ambas fuentes de información, es decir, al usar α = 0.50, se intercambia la suavidad por la estructura y la suavidad se reduce aproximadamente a 60%, con lo cual se obtiene la tendencia que muestra la gráfica 14.
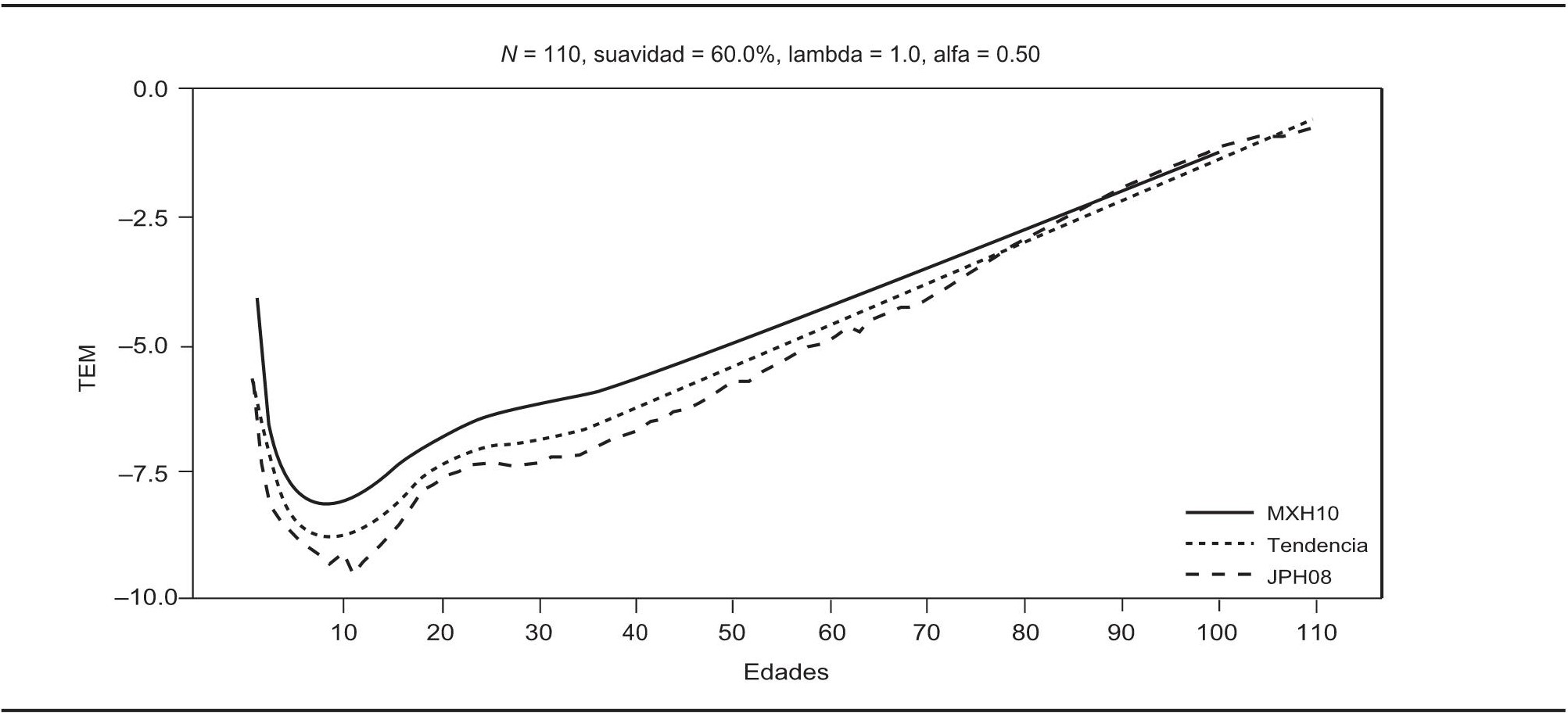
FUENTE: Cálculos propios con datos de Conapo, 2010 y <http://www.mortality.org>.
GRÁFICA 14. Tendencia estimada con fuentes de información mexicana y japonesa
Una vez estimada la tendencia se puede advertir cómo podría sería la mortalidad mexicana en el horizonte futuro prefijado por el analista. En esencia, la estimación resultante es una mezcla entre ambas estructuras y con curvatura en edades jóvenes. Sin embargo el efecto de mezcla no va más allá de los 85 años, y si se quisiera lograr ese efecto se tendría que asignar otro valor al parámetro α (pero se considera que México dista mucho de alcanzar una estructura de tal naturaleza).
Conclusiones
La metodología que se describe en este trabajo puede utilizarse para estimar tendencias de datos demográficos que tengan en cuenta la fidelidad a los datos, así como la suavidad que se desea y la estructura proveniente de alguna teoría, o bien, que se le pueda considerar como una meta que se aspire alcanzar en algún horizonte futuro. El control que el analista puede tener sobre estas características de la tendencia, de acuerdo con sus intereses y su conocimiento del fenómeno, hacen que los resultados sean comparables en distintos análisis. Debido a su facilidad de implementación en paquetes del tipo Matlab o R o RATS (en particular se utilizó RATS y los programas están disponibles a solicitud del interesado), es factible que el método sea utilizado por analistas con poca experiencia o con deficiente formación demográfica, por lo que ése es un punto a cuidar en la práctica, porque los resultados que se obtengan dependerán fuertemente de los insumos que se usen, es decir, de los datos originales y de la teoría o meta propuesta. Además debe tenerse en mente que es el analista quien decide cuál de las dos perspectivas de la metodología debe utilizarse en cada caso.
En las aplicaciones aquí mostradas, así como en otras realizadas con la metodología propuesta, se ha observado que el método produce mejores resultados en tanto mayor sea la desagregación de los indicadores demográficos. Es de resaltar el hecho de que la metodología puede aplicarse sin dificultad alguna, aunque la longitud de las series que se combinen no sea la misma o incluso si se presenta la situación de datos faltantes; esto se debe al uso del Filtro de Kalman con suavizamiento, que en los casos mencionados (longitud distinta de las series o datos faltantes) se aplica automáticamente por el procedimiento sin realizar en realidad el suavizamiento, sino sólo el filtrado. Es posible extender la propuesta metodológica para incorporar más fuentes de información, sin embargo ello representa una nueva línea de investigación en la cual los autores están trabajando actualmente. De igual manera, una línea futura de investigación la constituye una extensión del método a casos en que sea necesario aplicar diferentes suavidades o estructuras por rangos de edades de la población. Finalmente se evidencia, de acuerdo con el criterio de los autores, que la herramienta metodológica propuesta representa una herramienta alternativa más para desarrollar diferentes estudios cuantitativos relacionados con distintos fenómenos demográficos, en el sentido de complementar o potenciar lo hasta ahora existente en la literatura especializada. En concreto, un problema demográfico que se podría resolver con el empleo de la presente propuesta es el de la llamada “conciliación demográfica”. Adicionalmente, y si así se deseara, se podría calcular la varianza de la estimación de acuerdo con la expresión [15].

