











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
Con base en la literatura especializada resulta evidente que las herramientas estadísticas de series de tiempo se pueden emplear para la descripción, análisis y pronósticos de diversos problemas demográficos. En este sentido, por citar algunos casos, desde la década de los ochenta se han elaborado diversas investigaciones, como por ejemplo: Land y Cantor, 1983; Carter y Lee, 1986; Thompson et al., 1989; McNown y Rogers, 1992; Lee y Tuljapurkar, 1994; Bell, 1997; Keilman et al., 2002; McNown y Rajbhandary, 2003; Laporte y Fergusonb, 2003; Brücker et al., 2003; McNown y Ridao-Cano, 2005; Jeon y Shields, 2008; Girosi y King, 2008; Tuljapurkar et al., 2004; Hyndman y Booth, 2008; Alonso et al., 2008; Okita et al., 2009; Goldstein et al., 2009; Cornwell, 2009. Con esta perspectiva, es decir, al emplear series de tiempo en el contexto de proyecciones de población se advierte que se pueden asociar a las estimaciones puntuales futuras, intervalos de predicción con determinado nivel de confianza, donde se prioriza un apego a la objetividad derivada de los mismos datos, y, por otra parte, se considera que ésta resulta ser una visión complementaria con ciertas propuestas recientes, como la elaborada por King y Samir (2011).
Una de las mayores preocupaciones que sistemáticamente afectan a las instituciones generadoras de información, como el INEGI (Instituto Nacional de Estadística y Geografía) y el Conapo (Consejo Nacional de Población) en México y a los ministerios y consejos de población de otros países, así como a las instancias públicas y privadas que la utilizan, es lo tocante a las proyecciones o pronósticos de población. Universalmente se aspira a que éstos sean lo más confiables posible, para que con base en ellos se puedan sostener programas o planes cuyo diseño e implementación parten del supuesto de que se satisfagan determinados pronósticos oficiales y sean lo más precisos posible. Un pronóstico sin una apropiada precisión, por ejemplo en el sector público, es información que puede poner en JAQUE la viabilidad de algún programa social, ya sea en términos económicos o sociales, por decir lo menos.
Ante la eventual problemática que puede acarrear la baja capacidad predictiva de una proyección demográfica, en este trabajo se hace referencia a una alternativa cuyos elementos se han sugerido originalmente en el ámbito económico, pero que resultan eficientes en el ámbito demográfico. Así pues, el objetivo del presente trabajo es exponer el potencial que tiene la propuesta metodológica elaborada por Silva et al. (2011), donde se emplean series de tiempo multivariadas para pronósticos de población. Se particulariza en el caso de los resultados del Censo 2010 para la Zona Metropolitana de la Ciudad de México (ZMCM). Asimismo, y como hipótesis, se tiene que la herramienta metodológica representa una alternativa para, en concreto, enriquecer los mecanismos de proyecciones demográficas, y en general para realizar una mejor planeación en distintos órdenes, así como para propiciar un ambiente idóneo a considerar por parte de los tomadores de decisiones.
Metodología
Se sigue la propuesta metodológica de Silva et al. (2011) que se sustenta en el manejo de modelos de series de tiempo multivariados denominados VAR(p) (VAR, del inglés Vector Autoregressive). Para la implementación de la metodología se emplea el software estadístico EViews versión 5.0 en lo referente a la estimación y diagnóstico del modelo VAR(p), en tanto que se utiliza Matlab versión 7.0 para las desagregaciones y pronósticos multivariados. Cabe mencionar que en general, para este fin, se podrían utilizar algunos otros softwares, como SAS, STATA, R o RATS.
La lógica de utilizar series de tiempo multivariadas emerge de la concepción de cómo está compuesta la ZMCM. Esta zona se concibe como un conjunto de municipios y delegaciones que a su vez constituyen anillos; a saber, es una ciudad central y tres anillos (en el cuadro 1 se explica cómo fueron consideradas dichas unidades geográficas). Aún cuando se podrían estimar cuatro modelos independientes, con o sin la perspectiva de series de tiempo, para las unidades geográficas referidas, al tener evidencia de que existe dependencia temporal entre las series (lo cual se puede verificar de manera formal mediante las denominadas pruebas de cointegración), resultaría un desperdicio el no aprovechar toda la información disponible. Con esto se considera justificable el uso de la perspectiva multivariada.
CUADRO 1 Composición de la ZMCM

Fuente: Definición de la ZMCM adoptada con base en la propuesta del INEGI.
Debe notarse que para la desagregación no se cuenta con datos específicos censales de 1940 a 2000 relativos a la ciudad central y los anillos, sino que sus series se deben ir reconstruyendo a partir de los respectivos datos de municipios y delegaciones (a pesar de que en algunos casos no existen como tales en las primeras décadas que se consideran en el análisis) (véase el cuadro 2). Lo mismo ocurre en cuanto a las estadísticas vitales, las cuales se aproximan por medio de porcentajes. A continuación se citan, de manera general, los cuatro pasos principales de la metodología.
CUADRO 2 Censos de población (1940-2010) y conteos (1995-2005) por anillos concéntricos

Nota: Los datos de 2005 corresponden a datos con estimación elaborados por el INEGI.
n.d. = Dato no disponible.
Fuente: Recopilación propia en los censos respectivos (INEGI, 1940-2010) y en los conteos (INEGI, 1995 y 2005).
Paso 1. Previo
Se realiza la recolección de datos provenientes de los censos de población desde 1940 hasta 2000, de los conteos de 1995 y 2005, e información anual de estadísticas vitales (nacimientos y muertes) de 1941 a 2000. Siguiendo un algoritmo de naturaleza demográfica (véase el anexo) se generan series anuales de tasas acumulativas de crecimiento demográfico PGR 1 (Population Growth Rate), tomando como momento inicial el año de 1940 y estimando el crecimiento en referencia con dicho año y cada uno de los años restantes para cada unidad geográfica. Éstas son las llamadas series preliminares.
Paso 2. Desagregación
Se define un vector de variables no observables de tamaño 4 (k) (número de
unidades geográficas consideradas)
Una forma sencilla de interpretar la expresión ENT#091;1ENT#093; es afirmar que las series desagregadas finales (estimadas) son iguales a las series preliminares más un factor de ajuste (o corrección), el cual está vinculado con las restricciones por satisfacer, es decir, con los datos censales. Se remite al lector al artículo de Guerrero y Nieto (1999) para mayores detalles sobre el método y las definiciones empleadas.
Con la desagregación se transita de un número pequeño de observaciones a otro mucho más elevado. O sea, de siete observaciones (datos censales de 1940, 1950, …, 2000) a un total de 60 observaciones (1941, 1942, …, 1999, 2000), y además esta cantidad de datos se genera para cada una de las unidades geográficas definidas. El tipo de desagregación que se realiza se puede entender como una interpolación, con la propiedad de que se garantizan optimalidad y propiedades deseables en términos de estimación. También es importante destacar que las series preliminares no deben tener como meta el alcanzar los niveles de las observaciones censales, sino que en todo caso son ellas las que proporcionan la estructura a las series desagregadas finales. Estas últimas sí que deben satisfacer las restricciones expuestas en el segundo sumando de la ecuación ENT#091;1ENT#093;. A manera de validación de la metodología para la desagregación se verifica que los datos del Conteo 1995 caigan respectivamente dentro de los intervalos de estimación a un nivel de 95% de confianza.
Paso 3. Pronósticos multivariados
Para los pronósticos multivariados se define el vector
donde Π (B) es una matriz polinomial de orden p finita en el operador retraso B tal que
Por otra parte, se hacen dos modificaciones sobre los intervalos de confianza de los pronósticos multivariados: los ajustes por ser generados a partir de procesos estimados y la adherencia de los errores heredados de la desagregación. Para este último punto se consideran matrices de covarianza de los residuales correspondientes así como los datos respectivos de las dos últimas décadas, es decir, de 1980 a 2000, para incluirlas dentro del horizonte de pronóstico de 2001 a 2020. La eficiencia de los pronósticos multivariados se respalda tomando en cuenta los datos del Conteo 2005 y verificando que estas observaciones caigan respectivamente dentro de los intervalos de predicción a un nivel de 95% de confianza.

Paso 4.Verificación del potencial de la técnica
Un elemento teórico adicional considerado por Silva et al. (2011) lo constituyen las llamadas pruebas de compatibilidad, cuyo objetivo esencial es señalar qué tan acordes o no son los valores futuros propuestos con base en el comportamiento de las series poblacionales observadas. La propuesta de este estadístico fue planteada por Guerrero y Peña (2000, 2003), y de manera general viene dado por
donde
En el cuadro 3 se presenta una síntesis de los pasos comprendidos para la aplicación de la metodología con la finalidad de que el lector los pueda seguir y dimensionar globalmente.

Resultados para pronósticos de 2010
Una vez expuesta brevemente la metodología de Silva et al. (2011) se valora qué tan eficiente resulta ésta en cuanto a su capacidad predictiva con base en los datos censales del año 2010, es decir, se procede a conocer qué potencial tiene la propuesta metodológica. El insumo para esta tarea es el conjunto de resultados de volúmenes de población que se han alcanzado en la ZMCM y que provienen de los resultados del levantamiento del Censo de Población y Vivienda 2010 a cargo del INEGI, algo relativamente análogo a lo que se realizó con datos de los conteos 1995 y 2005 respectivamente.
Con base en los resultados del Censo se calcularon las PGR correspondientes para los crecimientos (o eventuales decrementos) de la ciudad central y los anillos concéntricos (se utiliza la fórmula VII del anexo). Durante la elaboración de Silva et al. (2011), desde la perspectiva estadística se tenía la certeza de que los intervalos de predicción iban a contener los niveles de población para 2010 y que para los conteos subsecuentes (si es que los hubiera) sería necesario actualizar los pronósticos dotándolos de mayor información. Sin embargo, por tratarse de una manera distinta de hacer las proyecciones poblacionales, con la mirada demográfica existía un sano grado de escepticismo ante la verificación del potencial de la propuesta de los pronósticos multivariados.
En la práctica resulta inverosímil que los pronósticos puntuales de cualquier fenómeno donde se susciten de manera intrínseca efectos aleatorios generados por diversas causas, cualquiera que sea el método con el que se elaboren, tengan un error nulo o una precisión absoluta. Por esta razón, resulta recomendable acompañarlos con sus respectivos intervalos de predicción. Más aún, si todo intervalo de predicción es capaz de contener los datos que se desea pronosticar, entonces se puede evidenciar que se tiene capacidad predictiva, y en eso radica justamente el potencial de la técnica aquí propuesta.
Para un juicio objetivo y orientador acerca de la viabilidad del cumplimiento de metas futuras en diversos contextos, adicionalmente a los intervalos de predicción, resultan útiles las pruebas de compatibilidad. Una pregunta natural que se puede formular es en torno a la relación que pudiera existir entre los intervalos de predicción y las pruebas de compatibilidad. De manera empírica, por medio de diversas simulaciones elaboradas por los autores, se ha observado que las regiones donde se satisface la compatibilidad contienen a los intervalos de predicción. Por lo tanto, en el marco de los denominados pronósticos restringidos multivariados, una buena manera de fijar metas futuras por alcanzar es emplear todo el conjunto de puntos contenido en los intervalos de predicción.
Conforme a las ideas básicas anteriores se ha optado por buscar la pertenencia de las PGR observadas del Censo 2010 en los intervalos de predicción con los distintos niveles de confianza que generalmente se emplean: 90, 95 y 99% (los resultados se muestran en el cuadro 4). En resumen, considerando tanto los intervalos de predicción como los resultados de las pruebas de compatibilidad se lograron los siguientes hallazgos para cada una de las unidades geográficas:
CUADRO 4 PGR observadas vs. intervalos de predicción

LI: límite inferior del intervalo de predicción; LS: límite superior del intervalo de predicción. Se marca con * el intervalo donde el valor observado pertenece al intervalo de predicción.
Fuente: Cálculos propios.
a) Ciudad central. En ningún caso el valor observado de la PGR cae dentro de los intervalos de predicción. Se piensa que esto se explica en gran medida debido a los resultados de la política del Bando 2, que se impuso en 2000 con la idea de incentivar el repoblamiento y así aprovechar la infraestructura urbana ahí existente (véase Delgadillo, 2009; Paquete y Yescas, 2009). De hecho la PGR Observada es incompatible con la dinámica de la serie porque el valor del estadístico es de 20.57 y es significativo al 1%; se rompe con la dinámica de la tendencia que presentaba esta serie. Otra perspectiva de este mismo resultado sería que la política agresiva de repoblamiento en el Distrito Federal tuvo éxito, sin embargo haría falta precisar si eso era lo que se esperaba para 2010, tanto para los planificadores como para los tomadores de decisiones, o más bien fue algo circunstancial cuyas consecuencias no se han previsto en lo tocante a su sustentabilidad, ya sea en el corto, mediano o largo plazos.
b) Primer anillo. El valor de la PGR es 3.47, que cae casi dentro del intervalo de predicción de 90%; asimismo resulta estar contenida en los dos últimos intervalos de predicción. En este caso el estadístico de compatibilidad fue de 2.68 y no es significativo al 1%; también se aprecia que con base en el dato censal hubo un incremento poblacional más alto que la resultante a partir de la estimación puntual obtenida.
c) Segundo anillo. La PGR observada fue de 3.90 y está contenida en todos los intervalos de predicción; de hecho, es la única de todas las unidades geográficas que posee esta característica. Su estadístico de compatibilidad fue de 2.83 y es no significativo al 1%. A diferencia de los otros dos anillos, el dato censal es menor que la estimación puntual generada.
d) Tercer anillo. Su PGR es 2.86 y se alcanza a cubrir hasta el intervalo de predicción de 99%, en tanto que su estadístico de compatibilidad parcial fue de 5.22 y es no significativo también al 1%. Al igual que en el caso del primer anillo, el dato censal es más alto que la estimación puntual obtenida.
Con base en la gráfica 2 y con los estadísticos de compatibilidad parcial y total, los resultados del Censo 2010 serían compatibles si no hubiera tenido efecto alguno la política de repoblamiento impuesta en la ciudad central; es decir, los datos censales de 2010 son compatibles con la dinámica de crecimiento poblacional de la ZMCM exclusivamente en los anillos. En términos cualitativos se puede afirmar que el ritmo de crecimiento es menos pronunciado para el segundo anillo y más pronunciado de lo previsto para las demás unidades geográficas. Para subsecuentes pronósticos convendría tomar los datos observados de 2010 y así hacer los ajustes respectivos.
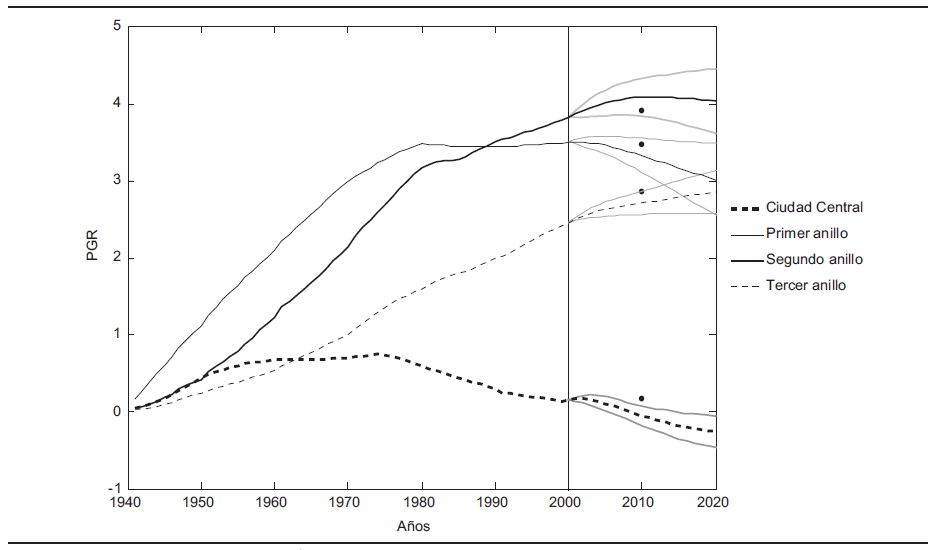
Nota: Intervalos de predicción de 95%. Los puntos de colores respectivos son los datos del Censo 2010.
Fuente: Cálculos propios.
GRÁFICA 2 Pronósticos irrestrictos para la ZMCM, 2001-2020
De acuerdo con la gráfica 2, se pueden distinguir aproximadamente las denominadas etapas del metropolitanismo (véase Sobrino, 2007): i) concentración (la tasa de crecimiento demográfico de la ciudad central supera a la de la periferia); ii) desconcentración (la periferia alcanza un mayor ritmo de crecimiento poblacional respecto a la ciudad central); iii) despoblamiento (la ciudad central inicia un saldo neto migratorio negativo y prosigue hasta el decrecimiento absoluto de su población), y iv) repoblamiento (la ciudad central retoma su crecimiento demográfico). En un trabajo de investigación futuro convendría entonces, a partir de los datos censales de 2010, hacer un estudio acerca de la movilidad de la población de la ZMCM en relación con el lugar de residencia en retrospectiva.
Conclusiones
Se utilizan métodos estadísticos de series de tiempo multivariadas con el propósito de explicar que esta perspectiva resulta apropiada para los pronósticos de población. Así pues, el enfoque estadístico expuesto puede ser útil y adecuado para propiciar un panorama idóneo para la toma de decisiones, más allá de que el conjunto de herramientas estadísticas que lo conforman haya sido originalmente propuesto en el ámbito económico.
Para subsecuentes pronósticos y conforme a la presente propuesta, sería oportuna la actualización de los pronósticos sobre las mismas series demográficas con datos censales de 2010. Asimismo se considera que se podría utilizar la herramienta para hacer propuestas de planes de crecimiento demográfico donde se utilicen nuevamente las llamadas pruebas de compatibilidad. Por otra parte, se está ante la disyuntiva de deducir qué es más eficiente: a) aplicar la desagregación hasta 2010, o b) usar pronósticos restringidos para satisfacer la meta (datos observados) de 2010, para pronosticar posteriormente en ambos casos.
Una implementación de la propuesta de Silva et al. (2011) para todos los estados del país podría resultar extremadamente costosa en términos de tiempo, presupuesto y esfuerzo. Sin embargo sería más factible y provechoso en términos estratégicos replicar la aplicación de la metodología en las zonas metropolitanas del país. La idea sería en principio establecer las unidades geográficas que las definen y luego seguir los pasos subsecuentes, dado que se tiene una alta concentración demográfica en ellas y que existe una alta generación de riqueza (PIB) en las mismas.
Finalmente es digno de mencionar que con horizontes de pronósticos más pequeños, por ejemplo cinco años, los resultados suelen ser más satisfactorios en el caso univariado; sin embargo en el caso multivariado, como el ejemplo de la ZMCM, los resultados sugieren que se puede tener eficiencia predictiva en al menos el doble de tiempo. Esto a manera de orientación y con base en diversas pruebas que realizamos los autores, más allá de un resultado teórico formalmente demostrado.

