











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1. Introducción
Una de las características más importantes de la distribución espacial de la actividad económica es su tendencia hacia la concentración (Albert, Mateu y Orts, 2007). Es decir, la localización de la actividad económica no es consecuencia de un accidente, sino más bien responde a diversos factores, como los ambientales, sociales y económicos, entre otros, que influyen para que la actividad económica se concentre en determinados espacios (Fujita y Thisse, 1996; Fujita y Krugman, 2004).
Existe una amplia evidencia empírica que muestra que las actividades económicas se encuentran distribuidas de manera desigual sobre el espacio, lo que implica que estas se aglomeren, en menor o mayor grado, en determinadas regiones y formen clusters (Venables, 2008). Principalmente con las aportaciones de Krugman (1991b) sobre la nueva geografía económica se resaltan los beneficios de dichas aglomeraciones. Ejemplos claros de las aglomeraciones espaciales en cuestión pueden ser las de empresas de alta tecnología en Silicon Valley en Estados Unidos; Bresnahan y Gambardella (2004) dan cuenta de ello. Para el caso mexicano, es la industria textil en Tijuana y Ciudad Juárez o la de productos químicos en Tampico y Campeche (Villarreal, Mack y Flores, 2017). Es decir, las empresas tienden a concentrarse en espacios que propicien ambientes idóneos para que puedan crecer y consolidarse, para lograrlo buscan estar cercanas a otras empresas, relativamente similares, para aprovechar una serie de beneficios como flujos de información y derrama de conocimientos, por mencionar algunos.
La literatura que aborda los factores que intervienen en las aglomeraciones espaciales es extensa, trabajos como el de Fujita, Krugman y Venables (1999), por ejemplo, dan cuenta de algunos factores que intervienen en la concentración de la actividad económica. Por el contrario, la literatura que trata sobre las formas de aglomeración o estructuras espaciales de la actividad económica es relativamente escasa, particularmente en América Latina, donde la mayoría de los estudios abordan el análisis espacial de las actividades económicas desde una perspectiva discreta, es decir, donde las unidades de estudio son polígonos con delimitaciones geopolíticas.
En este sentido, la presente investigación busca conocer la estructura espacial de la economía mexicana a través de analizar y caracterizar los patrones de localización de las manufacturas con la aplicación de algunos métodos basados en distancia que usan el análisis de patrones de puntos espaciales y que tratan el espacio como continuo. De manera específica, en esta investigación se hace uso de la función K de Ripley para conocer las aglomeraciones de las manufacturas mexicanas a diferentes rangos de distancia.
El análisis toma como punto de referencia el total de las manufacturas (TM), ya que de lo contrario, si se tomara como punto de referencia el CSR, las manufacturas presentarían aglomeraciones en todos los rangos de distancia debido a que el CSR asume que todos los puntos presentan una distribución aleatoria. De esta forma, si se toma como referencia el total de las manufacturas, los resultados indicarán si para cada sector manufacturero analizado su concentración espacial es igual, mayor o menor, que la concentración espacial del total de las manufacturas mexicanas.
Asimismo, con la aplicación de dichos métodos basados en distancia y que tratan el espacio como continuo se evita el problema de la escala geográfica o unidad administrativa de la que dependen los datos, una característica de los estudios de tercera generación (Duranton y Overman, 2005). De igual manera, nuestra investigación cumple con los cinco requerimientos que todo análisis de concentración espacial debe tener, que, de acuerdo con los autores antes señalados, son los siguientes: i) ser comparable a través de industrias, ii) tener control sobre la concentración general de las manufacturas, iii) tener control sobre la concentración industrial, iv) ser imparcial con respecto a la escala y a la agregación y v) dar un indicador de significancia a los resultados. Se enfatiza que para esta investigación se hace uso de coordenadas geográficas (longitud, latitud) para conocer la localización exacta de cada establecimiento, lo que favorece la precisión del análisis ya que no se toman en cuenta los límites administrativos y territoriales.
El trabajo se encuentra estructurado de la siguiente manera: después de la introducción, en la sección dos se hace una revisión de la literatura sobre los diferentes métodos utilizados en el análisis empírico de la estructura espacial de la actividad económica; en la tercera se describen los datos utilizados y las técnicas aplicadas; en la sección cuatro se analizan los resultados generados en el contexto de la economía mexicana y en la última se presentan las conclusiones.
2. Revisión de la literatura
Los estudios relativos a la aglomeración espacial de empresas son amplios y ricos en aplicaciones metodológicas y teóricas, desde finales del siglo XIX Marshall (1920) argumentaba sobre los beneficios de las aglomeraciones espaciales de pequeñas empresas con características similares en localidades particulares. Estos argumentos posteriormente fueron tomados por Krugman (1991a), quien mencionaba que un país puede ser diferenciado por un núcleo industrial y una periferia agrícola, y que las empresas tienden a aglomerarse en los espacios donde la demanda es más intensa.
De manera particular, Krugman afirma que las empresas tienden a concentrarse en determinados espacios geográficos, porque así aprovechan una serie de beneficios como mano de obra calificada, suministro de insumos, conocimiento t´ecnico, entre otros. También las empresas aglomeradas pueden aprovechar el personal calificado, cuando una de ellas pueda pasar por un mal momento esta misma demanda de mano de obra calificada provocará que otras empresas se aglomeren en ese mismo lugar o muy cercano a él para encontrar los beneficios antes descritos (Krugman, 1991b).
En este sentido, las nuevas empresas tienen como preferencia la vecindad con otras con similares características pues así aprovechan la experiencia en el mercado de esas empresas, lo que incentiva su competitividad. Existe un amplio contenido empírico que demuestra la importancia de las aglomeraciones espaciales para el establecimiento de nuevos negocios, lo demuestran algunos trabajos como como el de Stuart y Sorenson (2003) y Weterings y Marsili (2015). De igual manera, Porter (1998) argumentaba que la proximidad entre empresas les ayudaba para incrementar su productividad, ya que al estar cercanas aumentaban su competitividad, además de que aprovechaban la red de proveedores de las empresas que integran el cluster. Asimismo, los clusters no solo están integrados por empresas, sino por otras instituciones que sirven de apoyo a esas aglomeraciones espaciales, como universidades, centros de investigación e instituciones financieras, por mencionar algunas.
Las ventajas de las aglomeraciones espaciales aplican particularmente en el comportamiento espacial de las empresas alta tecnología, de acuerdo con la revisión de la literatura este tipo de empresas además de buscar proximidad con otras de similares características, buscan estar en espacios donde exista mano de obra calificada, centros de investigación, tecnologías de la información y otras infraestructuras que les permita innovar e incrementar su productividad. Dichos espacios suelen ser los principales centros urbanos, pues las áreas urbanas grandes o centros metropolitanos sirven como incubadoras de empresas debido a que brindan insumos necesarios que detonan la derrama de conocimientos (Schneider, Schulze-Bentrop, Paunescu, 2010; Malecki, 1979; Nijkamp, 1988; Frenkel, 2001). Por el contrario, las empresas de baja tecnología no necesariamente se concentrarían en los principales centros urbanos, ya que una empresa relacionada con la producción de madera o al envasado de mariscos, no se ubicaría forzosamente en espacios que albergaran centros de investigación o instituciones de educación superior. Existe una amplia evidencia empírica que señala las diferencias en la localización de las empresas por su grado de intensidad tecnológica (Barkley et al., 1988; Munier, 2006).
Por otro lado, existen estudios que demuestran que la productividad es mayor en los grandes centros urbanos porque los mercados laborales son más amplios, además de que la división del trabajo propicia que se generen economías de escala (Andersson, Quigley y Wilhelmsson, 2005). De este modo, se resalta que las zonas urbanas desempeñan un papel muy importante en la aglomeración espacial de empresas, pues es ahí donde existe la infraestructura necesaria para que se desarrollen (Frenkel, 2001).
2.1. Técnicas aplicadas al estudio de las aglomeraciones espaciales sobre un espacio discreto y continuo
Desde finales del siglo XIX se ha indagado sobre los factores que intervienen en las aglomeraciones espaciales de los diferentes sectores de la actividad económica, como ya se mencionó, a partir de Marshall (1920) se han expuesto teorías, métodos y técnicas aplicadas el estudio de la concentración espacial de empresas. Sin embargo, el campo de las aglomeraciones espaciales ha sido dominado por las técnicas que analizan el espacio como discreto, es decir, aquellos que se encuentran delimitados por fronteras geopolíticas como municipios, condados, estados u otro tipo de unidades territoriales.
Este tipo de investigaciones usan principalmente indicadores de concentración industrial como el LQ, el índice Ellison-Glaeser y otros índices que asumen que las unidades de análisis son independientes o aisladas de otros territorios (por ejemplo, Anselin, 1995; Ellison y Glaeser, 1997). Existe una amplia literatura en la cual aplican métodos que tratan al espacio como discreto aplicando los índices de concentración industrial antes mencionados (Vinay y Chakravorty, 2005; Vitali, Napoletano y Fagiolo, 2013; Sohn, 2014). Aun con dichas limitantes que presentan las técnicas aplicadas al espacio discreto, este tipo de estudios también presentan algunas ventajas, por ejemplo, la disponibilidad de información estadística sobre las unidades territoriales de estudio debido a que existe una gran cantidad de información disponible en los censos sobre las condiciones socioeconómicas de la población que habita en esas unidades territoriales, como características de la vivienda y salud, entre otras estadísticas. Otro de los puntos a favor de estos estudios es la amplitud de técnicas y la disponibilidad del software para realizar los análisis (por ejemplo, Anselin, Syabri y Kho, 2004).
Sin embargo, dichos análisis presentan diversos inconvenientes, principalmente que las variables utilizadas están condicionadas por las unidades territoriales de estudio, lo que podría ocasionar el llamado problema de la unidad de área modificable, concepto que hace referencia a que toda la unidad considerada presenta determinadas características de un fenómeno (Scholls y Brenner, 2012). Además, estos análisis suelen no tener en cuenta la distancia entre las unidades territoriales que se contemplan, como si estuvieran aisladas y fueran completamente independientes unas de otras. Para resolver los inconvenientes que se presentan, existen métodos basados en distancia, que tratan al espacio como continuo en donde las unidades de análisis suelen ser puntos, que pueden ser empresas, plantas, incidentes o cualquier otra unidad que requiera precisión en su localización, en forma de coordenadas geográficas. Estas unidades en forma de puntos suelen desplegarse sobre superficies euclidianas sin ningún tipo de delimitacion territorial o geopolítica (Ripley, 1976, 1977, por ejemplo).
Los métodos basados en distancia y que tratan al espacio como continuo mejoran los resultados que se generan con los métodos aplicados al espacio discreto, al ser análisis que se realizan con técnicas basadas en procesos de puntos (después de transformar los datos originales en patrones de puntos espaciales), lo que desaparece el problema de la unidad de escala o administrativa elegida. No obstante, esta clase de métodos se enfrentan a diversas dificultades entre las que destacan las siguientes:
a) La disponibilidad de la información estadística sobre los puntos a estudiar: a diferencia de los análisis que tratan al espacio como discreto, la información estadística sobre los puntos es escasa y muchas veces difícil de conseguir por criterios de confidencialidad, ya que al ser unidades localizadas con precisión, la información agregada es generalmente pobre, en comparación con las unidades territoriales que suelen tener una gran cantidad de estadísticas de la población que habita en ellas.
b) La localización exacta de los puntos: para este tipo de investigaciones se necesita la información sobre las coordenadas geográficas, para poder ubicar la localización exacta de las unidades de análisis. Asimismo, estas mismas coordenadas en ocasiones requieren transformación y manipulación para que los datos puedan estudiarse, lo que, en cierto, modo agregaría dificultad en el procesamiento de los mismos.
c) El empleo de las técnicas de estadística espacial: esta última presenta la dificultad de requerir el apoyo del software adecuado, que suele ser más complejo que el necesario para el tratamiento del espacio discreto. El software para realizar inferencias sobre la concentración de puntos se basa, principalmente, en la aplicación de las funciones K hechas con frecuencia en paquetes de lenguaje de programación R, de ahí su relativa complejidad (por ejemplo, Baddeley y Turner, 2005; Bivand et al., 2008).
La función K de Ripley y sus variantes han sido ampliamente utilizadas para determinar los grados de concentración de una determinada nube de puntos sobre un espacio continuo a diferentes rangos de distancia. En este sentido, existe una vasta literatura en donde se demuestra la utilidad de dichas técnicas para analizar los patrones espaciales de puntos (Arbia, 2001; Marcon y Puech, 2003, Duranton y Overman, 2005; Marcon, Puech, 2012 y Albert, Casanova y Orts, 2012).
En cuanto a los estudios sobre la economía de las aglomeraciones, Duranton y Overman (2005) mencionan que se puede dividir en tres generaciones. Los estudios de primera generación corresponden a aquellos en donde el espacio no se toma en consideración y las medidas de localización industrial, como el índice de Gini o índice Herfindahl, no hacen distinción si la concentración de actividad industrial se debe a algunas grandes empresas en un área determinada o a una gran cantidad de pequeñas empresas en esa misma área. Algunos estudios como el de Krugman (1991c) y Brülhart (2001) dan cuenta de ello.
Los estudios de segunda generación empiezan con la aplicación del índice de concentración industrial de Ellison and Glaeser (1997). A diferencia de los estudios de primera generación, los de segunda controlan el nivel de concentración industrial para las manufacturas, de este modo la aplicación del índice en cuestión permite comparar los niveles de concentración entre diferentes sectores industriales. Sin embargo, cuenta con la desventaja de tratar al espacio como discreto, con todas las limitaciones que se han explicado en los párrafos anteriores.
La tercera generación de estudios permite el tratamiento de los datos sobre un espacio como continuo, los resultados son independientes de posibles cambios en las unidades espaciales, igualmente permiten hacer comparaciones entre los diferentes sectores de la actividad económica y, también, se dispone de pruebas que permiten evaluar las significatividad estadística de los resultados. Esta clase de estudios tuvo como origen la función K elaborada por Ripley (1977), que posteriormente fue modificada para ser aplicada a diferentes campos de la ciencia como la silvicultura o ciencias forestales (Duncan, 1993; Goreaud y Pélissier, 1999), a la ciencia regional (Sweeney y Feser, 1998) y al análisis espacial de las actividades económicas (Marcon y Puech, 2003; Duranton y Overman, 2005; Albert, Casanova y Orts, 2012).
2.2. Algunas aplicaciones de la función K
La revisión de la literatura dio cuenta de la existencia de diversas aplicaciones de las funciones K para estudiar el comportamiento espacial de los diferentes sectores que componen la economía. Particularmente existe una amplia evidencia empírica en países desarrollados, como por ejemplo el trabajo de Arbia et al. (2012), donde se realiza un análisis para los sectores de alta tecnología en Milán. Los resultados indicaron que todos los sectores de alta tecnología presentan aglomeraciones a cortas distancias, mientras que a largas distancias los sectores tienden a dispersarse o a tener una distribución aleatoria.
Otro ejemplo es el de Billings y Johnson (2011) ellos también hacen un análisis de patrones de puntos espaciales, este en áreas urbanas aplicando técnicas de densidad Kernel. Por su parte, Austin et al. (2005) para Chicago y Buck et al. (2013) para Alemania, aplicaron las funciones K bivariadas para determinar aglomeraciones de establecimientos de comida rápida a diferentes rangos de distancia alrededor de las escuelas. Cutberth y Anderson (2002) utilizaron las mismas técnicas para conocer la organización de los usos de suelo en Canadá. Por último, Nakajima, Saito y Uesugi (2010) usan las variantes de las funciones K propuestas por Duranton y Overman (2005) y analizan la estructura espacial de la economía japonesa clasificando a las industrias por su grado de concentración a diferentes rangos de distancia.
De los trabajos mencionados se resalta la importancia que tiene el comportamiento organizacional en el espacio de los diferentes sectores que componen a la economía, esto mediante el análisis sobre un espacio continuo, lo que conlleva ciertas ventajas en comparación con los estudios que se realizan con unidades territoriales.
En la década de los ochenta, con trabajos como el de Barff (1987), ya empezaba la aplicación de dichos tipos de métodos para realizar análisis urbanos, en su caso para Canadá. Recientemente han ido en aumento los trabajos en donde se aplican las funciones K para explicar el comportamiento espacial de la economía, por ejemplo, Giuliani, Arbia y Espa (2014) aplican métodos basados en distancia para algunas zonas metropolitanas de Italia, y Casanova, Vicente y Albert (2017) lo hacen para explicar el comportamiento organizacional de la economía española.
Sin embargo, existen pocos estudios en el contexto de las economías emergentes que analicen la estructura espacial de la actividad económica con este tipo de métodos, de ahí el interés de nuestra investigación. Aunque ya se han realizado esfuerzos para analizar la estructura espacial de las empresas en el caso mexicano con las técnicas mencionadas, por ejemplo, Garrocho, Alvarez y Chávez (2012), la evidencia empírica no es suficiente. Por ello, uno de los aportes del presente estudio va en ese sentido. Se hace uso de una aplicación de la función K de Ripley para analizar la distribución espacial de las empresas manufactureras mexicanas a diferentes rangos de distancia. Se hace tomando como referencia la distribución espacial del total de las manufacturas (TM) mexicanas.
3. Datos
Los datos considerados para esta investigación provienen del Directorio estadístico nacional de unidades económicas (DENUE), recolectado por el Instituto Nacional de Estadística y Geografía (INEGI, 2012). La base de datos del DENUE, consiste en información georreferenciada de más de cuatro millones de empresas en todo el territorio nacional con sus respectivas coordenadas geográficas. Se realizó una depuración de la base de datos se deja para el análisis a las empresas que emplean a diez o más trabajadores, el criterio de la selección (habitual en la literatura especializada) obedece a que en la economía mexicana predominan las micro, pequeñas y medianas empresas, igualmente con esta restricción se facilitarían los cálculos, ya que analizar cuatro millones de establecimientos en forma de puntos, dificultaría y distorsionaría el análisis de resultados.
En este sentido, existen otras investigaciones con similares restricciones, Albert, Casanova y Orts (2012) también restringieron sus cálculos a empresas con más de diez trabajadores y Marcon y Puech (2003) hicieron un umbral de selección de empresas con más de 20 trabajadores para cálculos sobre la economía francesa, de igual forma, Arbia et al, (2012) realizaron restricciones similares. Para la investigación que nos ocupa se realizaron agrupaciones de manufacturas que resultaron en la clasificación de 21 sectores a tres dígitos basados en el SCIAN. La información de las manufacturas para analizar se puede observar en el Cuadro 1.
Cuadro 1 Información descriptiva sobre los sectores que componen las manufacturas mexicanas
| Código | Manufacturas | Empresas | Intensidad tecnológica |
|---|---|---|---|
| 311 | Industria alimentaria | 6 234 | BT |
| 312 | Industria de las bebidas y del tabaco | 1 170 | BT |
| 313 | Insumos textiles | 785 | BT |
| 314 | Productos textiles | 664 | BT |
| 315 | Prendas de vestir | 3 312 | BT |
| 316 | Productos de cuero | 2 102 | BT |
| 321 | Productos de madera | 960 | BT |
| 322 | Industria del papel | 943 | BT |
| 323 | Industria de la impresión | 2 150 | BT |
| 324 | Productos de petróleo | 238 | MAT |
| 325 | Industria química | 150 | MAT |
| 326 | Industria del plástico y del hule | 2 252 | MBT |
| 327 | Productos no metálicos | 1 641 | MBT |
| 331 | Metales básicos | 1 245 | MBT |
| 332 | Productos metálicos | 1 968 | MAT |
| 333 | Maquinaria y equipo | 917 | AT |
| 334 | Equipo de computo | 365 | MAT |
| 335 | Aparatos eléctricos | 716 | MAT |
| 336 | Equipo de transporte | 294 | AT |
| 337 | Fabricación de muebles | 1 944 | BT |
| 339 | Otras manufacturas | 1 372 | MBT |
Fuente: elaboración propia con datos de la DENUE 2012.
Como se comentó anteriormente, la base de datos proporciona la localización geográfica (longitud y latitud) de todas las empresas manufactureras mexicanas. Los puntos representan a las empresas que se distribuyen sobre un espacio bidimensional, los cuales se convierten en el patrón de puntos espacial de referencia.
El patrón de puntos espacial que se usa como referencia para determinar los distintos niveles de agrupación contiene un total de 31 422 puntos (empresas). Un ejemplo de las diferencias entre los distintos patrones de puntos espaciales que representan la localización de las empresas manufactureras mexicanas puede observarse en la Figura 1.

Fuente: elaboración propia.
Figura 1 Distribución espacial de empresas pertenecientes a diferentes sectores
La Figura muestra diversos mapas de la distribución espacial de algunos sectores de las manufacturas mexicanas, se puede observar que existen diferencias en la cantidad de empresas. El inciso a) sector 311 industria alimentaria cuenta con 6 234 empresas, que contrasta con el sector 325 industria química que tiene 150 empresas y se localiza en el inciso b). Igual contraste se puede apreciar entre el sector 336 equipo de transporte, inciso c), y sector 321 productos de madera, inciso d), con fuerte presencia en la parte central norte del país.
4. Método
Para conocer la estructura espacial de los sectores que componen las manufacturas mexicanas se utilizaron técnicas basadas en la función K de Ripley (Ripley, 1976). Se ha comentado que se trabajan con patrones de puntos espaciales (nubes de puntos en un espacio bidimensional) que representan las distribución espacial de las empresas, en consecuencia, cuando se habla de un punto se hace refiriéndose a una empresa.
Específicamente, la función K de Ripley, K (r) es un método basado en la distancia que mide la aglomeración de un patrón de puntos espacial contando el número medio de vecinos que presenta cada punto dentro de un círculo de radio (r) determinado, en un determinado espacio, la función K compara el valor observado a una cierta distancia con el valor esperado a esa misma distancia; dado un proceso de Poisson homogéneo, también conocido como complete spatial randomness (CSR), es decir, que todos los puntos tienen la misma probabilidad de ocurrir en cualquier parte del área de estudio, la función K puede describirse como (Dixon, 2002: 1):
La Figura 2 muestra cómo se construye la función K a partir del evento i, se crean áreas de influencia a diferentes rangos de distancia, posteriormente se cuentan los puntos que se encuentran a cada diferente distancia y se repite el mismo procedimiento para todos los puntos que se encuentran en el área de estudio. Después se obtiene el promedio de puntos para los diferentes rangos de distancia y se divide entre la densidad total de puntos.
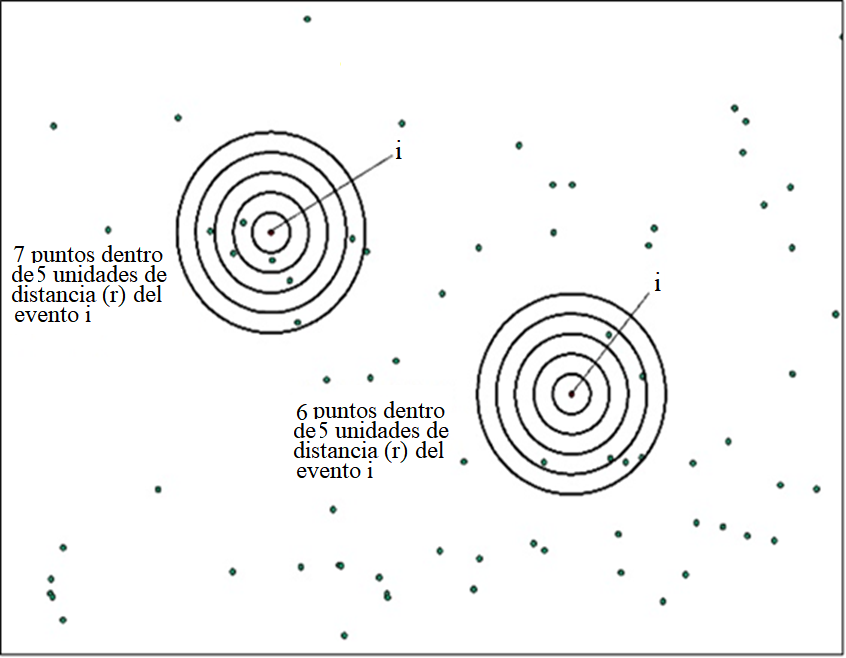
Fuente: elaboración propia con base en Gatrell et al. (1996: 263).
Figura 2 Construcción de la función K de Ripley
Para un determinado patrón de puntos espacial representado sobre un área A, la función K puede denotarse de la siguiente manera:
Donde d ij es la distancia entre los puntos i y j, I (x) es la función del indicador, N es el número total de puntos observados en el área de estudio, λ = N/A representa la densidad, A representa el área en donde se llevará a cabo el análisis de los puntos y w ij es el factor de ponderación para la corrección de los efectos frontera. El indicador I (d ij ), toma un valor de 1 si la distancia entre el punto i y el punto j es menor o igual que r, o 0 si es mayor.
Si se sustituye λ la función K (r) puede ser representada como:
La función K (r) anterior se interpreta como el promedio del número de vecinos en un radio (r), divido por la densidad del área de estudio completa.
En lo referente a la forma del área de estudio, en los análisis iniciales se utilizaba (algunos actuales la continúan haciendo) una forma cuadrada o rectangular, pero en esta investigación se ha construido una superficie poligonal que se adapta mucho mejor a la superficie del territorio mexicano y permite obtener resultados más precisos.
Para continuar con el análisis de los patrones de localización espacial de las manufacturas mexicanas se determina la hipótesis nula que se usa para clasificarlos. Como punto de partida se podría usar la hipótesis de aleatoriedad espacial completa (CSR), es decir, usar como referencia una distribución espacial en donde los puntos puedan ocurrir en cualquier lugar del área de estudio. Para hacer los contrastes de aleatoriedad espacial completa se utliza la función M CSR (r), que se define como la diferencia entre el valor de la K observada o empírica del patrón de puntos real de cada sector y el valor de la K teórica, esto se puede expresar de la forma siguiente:
Si el valor de la K observada, K (r), es más alto que el valor de la K teórica, πr 2 , indicaría concentración en el patrón de puntos para la distancia considerada, mientras que valores de K (r) inferiores a πr 2 indicarían dispersión, por último, si K (r) es igual πr 2 significaría que el patrón de puntos está distribuido de manera independiente. La diferencia entre la función K y la función M se puede observar en los dos casos de la Figura 3.

En ellos se pueden ver dos tipos de distribuciones de una determinada cantidad de puntos, en ambos casos son 50 puntos, una distribución está dada de forma independiente y la otra tiene una marcada tendencia a la aglomeración.
Por otro lado, la Gráfica 1 muestra la función K y la función M correspondiente a la distribución independiente de la Figura 3. De lado izquierdo se pueden observar dos líneas, la línea continua negra representa la K observada, en tanto que la línea discontinua representa la K teórica que, en este caso, es el punto de referencia (CSR) que toma el valor de πr 2 . Se puede observar que las dos líneas presentan una forma muy similar sin importar a las distancias que se encuentren, es decir, que toma el valor K (r) ≈ πr 2 .

De lado derecho de la Gráfica 1 se encuentra la función M de la distribución independiente de la Figura 3, en ella se puede observar que esa distribución independiente de puntos genera una curva plana con valores cercanos a 0.
Por otra parte, en la Gráfica 2 están las funciones K para la distribución aglomerada de la Figura 3 y, de igual manera, se presentan figuras correspondientes a la función K (lado izquierdo) y a la función M (lado derecho).

La Gráfica 2, por un lado, muestra las funciones K teórica (línea discontinua) y observada (línea continua); se puede notar que la K observada es mayor que la K teórica en todas las distancias (r), es decir, K (r) > πr 2 . Por otro lado, en la función M se puede observar el resultado de forma directa, es decir, K (r) − πr 2 ; asimismo, se puede observar la distancia en donde el patrón de puntos alcanza su máxima concentración. De igual manera la curva M CSR muestra información sobre las formas de aglomeración de los sectores que componen las manufacturas mexicanas, y es esta función la que se utilizará en primera instancia como punto de referencia.
Sin embargo, considerar que todas las empresas se distribuyen de forma aleatoria e independiente respecto una de la otra no parece un supuesto adecuado, ya que la actividad económica no se distribuye de manera homogénea, sino que tiende a aglomerarse en determinados espacios. Por ejemplo, las empresas no suelen localizarse sobre los ríos, montañas o lagos (first nature), sino que tienden a situarse en espacios idóneos para su crecimiento, por ejemplo, en las ciudades o cercanas a ellas. Por lo tanto, tomar la curva CSR como referencia no parece la opción más adecuada.
De manera alternativa, en esta investigación, se propone un escenario en el cual se minimicen los inconvenientes antes señalados, en donde se pueda comparar la aglomeración de cada sector con la aglomeración del total de las manufacturas, en otras palabras, se tomará como referencia la distribución espacial del total de las manufacturas. Con este fin se propone la función:
En este escenario, M T M (r) es la diferencia entre el valor K de cada sector y el valor K del total de las manufacturas para un radio r, en este caso la hipótesis nula será que la distribución espacial de las empresas de un sector manufacturero es la misma que la que se obtendría al sacar una muestra aleatoria de su mismo tamaño del conjunto formado por el total de las manufacturas, en otras palabras, se presenta una aleatoriedad espacial condicionada, tanto por la concentración industrial como por la aglomeración del conjunto de manufacturas. En este sentido, la concentración o dispersión estará dada por el valor que tome la K observada respecto a la K del conjunto de manufacturas, es decir, la concentración/dispersión de los sectores en relación con el total de las manufacturas.
Para establecer la significancia en las distribuciones espaciales de las manufacturas, tanto para M CSR como para M T M , se realizaron 200 simulaciones Monte Carlo para generar K teóricas que se pudieran comparar con las K observadas, lo anterior para generar intervalos de confianza de 95 por ciento. Para el caso de M CSR se hicieron simulaciones de patrones espaciales Poisson, en las que los puntos puedan ser localizados aleatoriamente en el área de estudio. En cuanto a M T M se realizan las mismas simulaciones pero, en esta ocasión, la localización de los puntos está restringida a la distribución del total de las manufacturas.
El software utilizado para llevar a cabo los cálculos fue Spatstat de la librería R, mismo que comprende cuatro métodos para corregir los efectos frontera: border, isotropic, Ripley y translate. Para esta investigación se utilizó el método border (reduce simple estimator) ya que presenta la ventaja de ser rápido para los cálculos y que es aplicable al polígono que se ha construido para analizar los patrones de puntos espaciales. Igualmente es apropiado para muestras de tres mil puntos o más pero menos de 100 mil, lo que es, en particular, adecuado para la muestra que se ha utilizado para este análisis ya que el punto de referencia es de poco más de 30 mil puntos.
5. Análisis de resultados
La Gráfica 3 contiene los patrones de localización de algunos sectores manufactureros en diferentes rangos de distancia. Se puede observar que en los cuatro sectores considerados existen patrones de aglomeración a prácticamente todas las distancias; asimismo, se puede advertir como este patrón de aglomeración de dichos sectores presentan, al menos, dos picos de concentración pronunciados, por ejemplo, el sector 311 industria alimentaria muestra un pico de concentración a los 329 kilómetros y otro a 550 kilómetros, situación similar al sector 325 industria química donde son evidentes dos picos de concentración.

Al observar la distribución de estos sectores en la Figura 1 se puede deducir que esa distribución influye en la forma de sus patrones de aglomeración por distancia. Específicamente, en la Figura 1 se puede observar la distribución del sector 325 industria química que hace contraste respecto al sector 311 industria alimentaria.
Asimismo, el sector 325 industria química presenta una distribución contrastante en diversos puntos del espacio, se observa que los puntos se concentran mayoritariamente en el centro y sur del país, con poca presencia en el norte, de ahí su patrón de aglomeración espacial a diferentes rangos de distancia en la Gráfica 3. La misma interpretación puede aplicarse al sector 336 equipo de transporte y 321 productos de madera.
En comparación con el estudio realizado en España por Albert, Casanova y Orts (2012), los patrones de localización espacial de los sectores que componen las manufacturas españolas presentan aglomeración a todos los rangos de distancia cuando el punto de referencia es M CSR . Asimismo, estos patrones parecen ser relativamente más estables que los encontrados en México, ya que como se puede observar en la Gráfica 3 y en las gráficas de los anexos, los patrones de las manufacturas mexicanas no parecen tener aglomeraciones continuas en su escala, en el sentido de que la mayoría de ellos presentan al menos dos picos de concentración a diferentes rangos de distancia. En particular, los sectores 336 equipo de transporte y 321 productos de madera no presentan aglomeraciones continuas ya que tienen diversos picos de aglomeración.
Para el caso de Japón, Nakajima, Saito y Uesugi (2010), el sector alimenticio presenta una dispersión a todos los rangos de distancia, mientras que los productos de metal presenta una aglomeración a cortas distancias y tiende a dispersarse a largas, situación similar para el caso de México cuando el punto de referencia es el total de las manufacturas (TM), como se podrá ver en la Gráfica 4. En este sentido, es importante destacar que la morfología territorial de cada país podría tener influencia en la estructura espacial de su economía.

Para el caso específico del territorio mexicano, este presenta una superficie territorial más grande en comparación con otros países (particularmente los europeos, donde los territorios suelen ser de menor tamaño) y las localizaciones de clusters espaciales de empresas se encuentran más lejanas unas de las otras. Por ejemplo, se pueden encontrar empresas del sector 311 industria alimentaria a lo largo y ancho del territorio mexicano (Figura 1), tanto en la frontera norte como en la frontera sur o en las costas el pacífico como en las costas del golfo, con distancias de cientos de kilómetros entre las empresas del mismo sector. De este modo es de esperarse que la morfología y la superficie territorial de cada país pueda tener implicaciones en la estructura espacial de su actividad económica.
Es importante señalar que los patrones de aglomeración de la Gráfica 3 fueron obtenidos mediante la aplicación de la función MCSR , lo que implica que el punto de referencia sea la distribución espacial aleatoria de todos los puntos, no tomándose en cuenta la heterogeneidad del espacio, de ahí que prácticamente todos los sectores presenten aglomeración en sus patrones de localización a diferentes rangos de distancia. El Anexo 1*** contiene los patrones de aglomeración para el resto de los sectores que componen las manufacturas mexicanas, tanto de la función M CSR como la función M T M .
Por otro lado, en la Gráfica 4 se tienen los patrones de aglomeración espacial de los mismos sectores como resultado de la aplicación de la función M T M . Se pueden observar las diferencias de los patrones de localización entre las Gráficas 3 y 4. Los patrones de localización de la Gráfica 4 tienen como punto de referencia la distribución espacial del total de las manufacturas (M T M ), por los que sus patrones de localización cambian de manera considerable en comparación al punto de referencia M CSR .
En la Gráfica 4 se observan diferentes patrones, por ejemplo, el sector 311 industria alimentaria presenta aglomeración a todos los rangos de distancia cuando se aplica MCSR como punto de referencia, pero cuando es M T M , esos patrones tienden a ser mayoritariamente dispersos, caso contrario para el sector 325 industria química, donde sus patrones de localizaci´on tienden a concentrarse a largas distancias cuando es M T M el punto de referencia, aunque hasta los 446 km presente una tendencia a la distribución independiente. Para el caso de 336 equipo de transporte y 321 productos de madera, esos patrones son dispersos a diversos rangos de distancia. Igual que en Nakajima, Saito y Uesugi (2010) y Albert, Casanova y Orts (2012), algunos sectores se aglomeran a algunas distancias y se dispersan en otras.
Por otro lado, el Cuadro 2 muestra los patrones de aglomeración para el resto de los sectores, en el se pueden observar las distancias a las que se concentran/dispersan los sectores manufactureros.
Cuadro 2 Patrones de aglomeración/dispersión de las manufacturas mexicanas MT M
| Sectores | Concentración significativa (km) | Dispersión significativa (km) | Valor M T M | Distancia (r) | Intensidad tecnológica* | Tipo de cluster | |
|---|---|---|---|---|---|---|---|
| 311 | industria alimentaria | 432-460 | 0-412 | -1.88 | 350 km | BT | 2 |
| 312 | industria de las bebidas y del tabaco | - | 0-560 | -4.5 | 529 km | BT | 2 |
| 313 | insumos textiles | 0-480 | 580-635 | -4.79 | 580 km | BT | 3 |
| 314 | productos textiles | - | 0-426/501-549 | -5.09 | 329 km | BT | 2 |
| 315 | prendas de vestir | 0-450 | 481-643 | 5.86 | 295 km | BT | 3 |
| 316 | productos de cuero | 0-550 | 556-570 | 9.58 | 426 km | BT | 1 |
| 321 | productos de madera | - | 0-618 | -5.14 | 329 km | BT | 2 |
| 322 | industria del papel | 0-364/474-557 | - | 9.51 | 543 km | BT | 1 |
| 323 | industria de la impresión | 0-302 | 350-474/632-646 | -3.5 | 460 km | BT | 3 |
| 324 | productos de petróleo | - | - | - | - | MBT | 0 |
| 325 | industria química | 446-501 | - | 9.13 | 473 km | MBT | 4 |
| 326 | industria del plástico y del hule | 0-419/529-536 | 453-481 | 3.7 | 343 km | MBT | 3 |
| 327 | productos no metálicos | 426-453 | 0-364 | -9.18 | 275 km | MBT | 2 |
| 331 | metales básicos | 27-151/419-502/ | - | 9.14 | 557 km | MBT | 3 |
| 522-543 | |||||||
| 332 | productos metálicos | 0-102 | 185-405 | -6.7 | 343 km | MAT | 3 |
| 333 | maquinaria y equipo | 0-102/425-473 | - | 1.99 | 418 km | AT | 1 |
| 334 | equipo de cómputo | 0-21 | 82-569 | -7.26 | 534 km | MAT | 3 |
| 335 | aparatos eléctricos | 0-137 | 549-569 | -3.28 | 556 km | MAT | 3 |
| 336 | equipo de transporte | - | 102-404 | -4.08 | 322 km | AT | 2 |
| 337 | fabricación de muebles | 0-158 | 220-447/474- | -3.66 | 522 km | BT | 3 |
| 550 | |||||||
| 339 | otras manufacturas | 0-137 | 233-549 | -3.55 | 370 km | MBT | 3 |
Nota: *Clasificación de acuerdo con la OECD. BT= baja tecnología, MBT= media baja tecnología, AT= alta tecnología, MAT= media alta tecnología.
Fuente: elaboración propia.
El cuadro tiene siete columnas, la dos y la tres muestran las distancias a las que los sectores de manufacturas se aglomeran o dispersan, por ejemplo, se puede observar que los sectores 312 industria de las bebidas y del tabaco, 314 productos textiles, 321 productos de madera y 336 equipo de transporte no presentan concentraciones significativas a ninguna distancia cuando el punto de referencia es M T M , por lo que estos sectores se dispersan a diferentes rangos de distancia. Por otro lado, los sectores 322 industria del papel, 325 industria química, 331 metales básicos y 333 maquinaria y equipo no muestran dispersión significativa a ningún rango de distancia, por lo que estos sectores presentan una tendencia a la concentración.
Igualmente, en las mismas columnas se pueden observar que no existen patrones de localización continuos en la escala, ya que muchos de ellos se aglomeran a unas distancias, se dispersan en otras o toman una distribución independiente en algunas distancias. Esto puede ser comprobado en la distribución del sector 325 industria del plástico y hule, el cual presenta aglomeración de los 0 hasta los 419 km, después tiene una distribución independiente y en seguida se dispersa desde los 453 a los 481 km para que, posteriormente, se vuelva a aglomerar desde los 529 a los 536 km. Esta lectura se puede aplicar a los demás sectores.
Por otro lado, la columna cuatro, muestra el valor M T M para cada sector, los valores negativos indican que el sector presenta su pico máximo en la dispersión, por el contrario, valores positivos señalan que el sector presenta su máximo pico en la concentración. De este modo la columna cinco ofrece la distancia a la que cada sector alcanza su pico de concentración/dispersión, por ejemplo, el sector que alcanza su máxima concentración a distancias más largas es el 331 metales básicos, al alcanzar su pico a los 557 km, por el contrario el sector que alcanza su máxima concentración a distancias más cortas es el 315 prendas de vestir, que lo hace a los 295 km. En cambio, el sector que presenta su máxima dispersión a distancias más largas es el 315 insumos textiles, el cual tiene su pico máximo de dispersión a los 580 km, mientras que el sector que tiene su máxima dispersión a distancias más cortas es el 327 productos no metálicos, al alcanzar su pico de dispersión a los 275 km.
La columna seis ofrece los diferentes niveles de intensidad tecnológica para cada sector, se pueden observar diferentes grados que, de acuerdo con la Organization for Economic Cooperation and Development, OECD (2011), son cuatro. Estos niveles de intensidad tecnológica parecen no tener un patr´on claro relacionado con su localización espacial, ya que en el cuadro se pueden encontrar sectores de baja tecnología (BJ) y alta tecnología (AT) que no presentan aglomeración, como el sector 314 productos textiles y el 336 equipo de transporte.
La última columna contiene el tipo de cluster que forma la distribución espacial a diferentes rangos de distancia de cada sector, es decir, el número indica la caracterización de esa localización espacial. De acuerdo con Albert, Casanova y Orts (2012) son cinco: tipo 0, aquellas empresas que no presentan aglomeración/dispersión significativa a ningún rango de distancia en comparación con el total de las manufacturas; el tipo 1 son sectores que muestran una fuerte tendencia a concentrarse en comparación con el total de las manufacturas; tipo 2, sectores que presentan una dispersión respecto al total de las manufacturas; el tipo 3 son empresas que están relativamente concentradas a cortas distancias y dispersas a largas distancias; por último el tipo 4, que son aquellos patrones en los que las empresas relativamente se dispersan a cortas distancias y se aglomeran a largas distancias, esto en comparación con el total de las manufacturas.
En este sentido, solo el sector 324 productos de petróleo presenta un cluster tipo 0, es decir, aquellas empresas que no presentan una concentración ni dispersión significativa en ningún rango de distancia, esto es, el sector presenta una distribución aleatoria o independiente. Del mismo modo, el sector 325 industria química se clasifica como un cluster tipo 4 o empresas que presentan una dispersión a cortas distancias, en tanto que a largas distancias tiende a aglomerarse. Los demás sectores presentan diferentes tipos de clusters, y dentro de ellos el cluster tipo 3 es el que más se presenta en los patrones espaciales de las manufacturas.
6. Conclusiones
Este estudio analiza los patrones de localización de las manufacturas mexicanas por sectores con métodos basados en la distancia. Se investigaron las concentraciones/dispersiones de las manufacturas tomando al espacio como un continuo, al mismo tiempo, debido al uso de coordenadas geográficas, se buscó ser precisos en la determinación de las localizaciones de las empresas.
Bajo este método, se obtuvieron diversos patrones de localización para los diferentes sectores que componen las manufacturas mexicanas. En un primer escenario se tomó como punto de referencia la curva MCSR , la cual atribuye que todas las empresas se distribuyen de forma aleatoria o independiente, por lo que es de esperarse que, prácticamente, se generen patrones de aglomeración a diferentes rangos de distancia.
Posteriormente, en un segundo escenario, se usó M T M , que toma en consideración la heterogeneidad espacial de la actividad económica, es decir, este punto de referencia nos permitió aislar espacios en los que las empresas difícilmente se establecerían (first nature) como ríos, desiertos y otros espacios en donde la actividad econ´omica es nula. Para dicho punto de referencia se utilizó la distribución espacial del total de las manufacturas. De esta manera, se pudo comparar cada sector de manufacturas con respecto a la localización del conjunto de las mismas, con sus respectivas pruebas de significancia obtenidas por 200 simulaciones Monte Carlo.
La aplicación de los dos puntos de referencia arrojaron resultados diferentes, con M CSR prácticamente todos los sectores presentan aglomeración espacial a todas las distancias, en tanto que con M T M los patrones de localización cambiaron considerablemente, ya que algunos sectores presentaban aglomeración a ciertas distancias y dispersión en otras; además de que algunos sectores alcanzaron su máximo valor M T M en su dispersión, mientras que otros lograron su pico en la aglomeración.
Igualmente, con la aplicación M T M como punto de referencia, se encontraron algunos sectores que no presentaban concentración significativa a cualquier rango de distancia (311 industria alimentaria, 314 productos textiles, 321 productos de madera y 336 equipo de transporte), en tanto que otros no tuvieron dispersiones significativas (322 industria del papel, 325 industria química, 331 metales básicos y 333 maquinaria y equipo).
Por otro lado, con la aplicación de M CSR como punto de referencia, se evidenció que los patrones espaciales de empresas presentan una distribución bimodal, con grandes picos de concentración a diferentes distancias, es decir, no cuentan con aglomeraciones continuas en la escala.
En este sentido, habría que tomar en cuenta la morfología, la superficie territorial y la geografía física de cada país, ya que podría incidir en la estructura espacial de su actividad económica debido a que las actividades humanas suelen concentrarse en espacios que propicien su desarrollo, esto en relación con lo que comentan Fujita y Krugman (2004) sobre las economías de aglomeración.
Por ejemplo, la estructura espacial de la economía en algunos países de Africa del norte puede manifestarse en aglomeraciones/dispersiones diferentes a las que se manifiesten en algunos países de Europa; ya que en los primeros las actividades económicas suelen concentrarse, principalmente, en el norte, debido a que su territorio está compuesto mayoritariamente por desierto (por ejemplo, Libia).
El presente estudio puede generar nuevas líneas de aplicación en el campo de la economía espacial, ya que ofrece una distribución más exacta de las empresas que conforman las manufacturas al tomar la heterogeneidad espacial de la actividad económica. Asimismo, es importante señalar que la aplicación de estos métodos basados en distancia, se realizaron sobre el espacio de una economía emergente y en un contexto socioeconómico diferente al de los países desarrollados, en donde se realizan en su mayoría dicho tipo de análisis. De este modo, se abre la posibilidad de encontrar nuevos elementos de análisis para futuros estudios en el campo de las aglomeraciones espaciales que toman al espacio como continuo.
Por último, esta investigación deja abierta algunas preguntas que pudieran ser contestadas con la elaboración de otros estudios: ¿la actividad económica se aglomera/dispersa de igual manera en una región, ciudad o zona metropolitana que en otra? ¿existen diferencias en los patrones de localización de los diferentes sectores que componen la economía entre regiones del país? Estas y otras preguntas pueden ser respondidas con la aplicación de métodos basados en la distancia, para dejar evidencia empírica y entender la economía mexicana desde otra perspectiva.

