











 texto en
texto en  Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
Generalidades del AFC
El análisis de frecuencia de crecientes (AFC) es una de las estimaciones básicas de la hidrología superficial, ya que permite la planeación, diseño y revisión de todas las obras hidráulicas requeridas por la sociedad, sean éstas de aprovechamiento, como los embalses; o de protección, como los diques, encauzamientos, presas de control, puentes, obras de drenaje urbano, etcétera. El AFC intenta definir la relación entre los gastos máximos de las crecientes anuales y su probabilidad de ser excedidos. Seleccionada tal probabilidad o riesgo para la creciente de diseño, su valor debe estimarse con la mayor precisión posible, ya que un error por defecto genera un aumento del riesgo adoptado y un error por exceso, origina un aumento del costo del proyecto (Botto, Ganora, Laio, & Claps, 2014).
El procedimiento más exacto para realizar un AFC consiste en representar el registro disponible de gastos máximos anuales por una función de distribución de probabilidades (FDP), y con base en tal modelo probabilístico realizar las inferencias buscadas o predicciones. Esta técnica puede conducir a estimaciones inexactas debido principalmente a los cuatro factores siguientes: (1) errores de medición en los datos; (2) amplitud finita del registro disponible; (3) presencia de mecanismos diferentes de generación de las crecientes, y (4) elección de la FDP (Merz & Blöschl, 2008).
Francés-García (1995) indica que históricamente la evolución de los AFC ha pasado por tres etapas: (I) búsqueda y ajuste de una mejor FDP a los gastos máximos anuales, hasta la década de 1960; (II) mejora de los métodos de estimación de los parámetros de ajuste de las FDP, durante el decenio de 1970, y (III) aumento en la exactitud de las estimaciones, desde la década de 1980, mediante el incremento de los registros de gastos máximos, a través del análisis regional y/o la incorporación de la información histórica de crecientes.
Una cuarta etapa evolutiva de los AFC inicia en el siglo XXI y se refiere al procesamiento de registros que no son estacionarios, debido a que presentan tendencias, y/o aumento o disminución de la variabilidad, como consecuencia de cambios físicos en las cuencas o del cambio climático (Khaliq, Ouarda, Ondo, Gachon, & Bobée, 2006; Katz, 2013; López-de-la-Cruz & Francés, 2014; Prosdocimi, Kjeldsen & Svensson, 2014; Campos-Aranda, 2018).
AFC con base en FDP mixtas
Desde la mitad del siglo pasado cobró interés la presencia de dos propiedades estadísticas observadas en los registros de gastos máximos anuales. La primera se llamó “efecto pata de perro” (dog leg effect), designada así por Potter (1958). Se observa al dibujar en el papel de probabilidad los datos y encontrar un cambio brusco de pendiente debido a la presencia de valores dispersos (outliers). La segunda propiedad se denominó “fenómeno de separación”, estudiada y documentada por Matalas, Slack y Wallis (1975), quienes dibujaron en las abscisas los valores promedio de los coeficientes de asimetría o de sesgo, y en las ordenadas sus respectivas desviaciones estándar de los registros sintéticos generados con las FDP más comunes. Al llevar a tal gráfica los puntos de los registros históricos disponibles de gastos máximos anuales en cada una de las 14 regiones hidrológicamente homogéneas de EUA se observó que las FDP quedaban por debajo de los puntos reales; esto indicaba que tales FDP no podían representar la variabilidad muestral que tienen las crecientes.
Detectadas por los hidrólogos las deficiencias citadas de las FDP utilizadas hacia el final de la década de 1970, se propuso su solución a través de los modelos probabilísticos mixtos, los cuales toman en cuenta los diferentes orígenes en las crecientes de un registro. Los modelos mixtos se aplican bajo dos enfoques diferentes: (a) crecientes independientes y separables, y (b) crecientes independientes que están mezcladas. El ejemplo clásico del primer enfoque es el modelo sugerido por Waylen y Woo (1982), aplicable cuando las crecientes originadas por fusión de la nieve y lluvia son plenamente identificables por su fecha de ocurrencia en el registro disponible de gastos máximos anuales. Las crecientes de fusión de nieve originan gastos bajos y ocurren en primavera-verano, y las de lluvia generan gastos mayores y suceden en el inverno de octubre a febrero. Para el segundo enfoque se han propuesto las mezclas de FDP, por ejemplo: (1) la denominada Gumbel doble, sugerida por González-Villarreal (1970); (2) la distribución Wakeby, propuesta por Houghton (1978), que intenta modelar la porción izquierda y derecha de manera separada; (3) el modelo TCEV, desarrollado por Rossi, Fiorentino y Versace (1984); y (4) la función Gumbel mixta aplicada recientemente por Molina-Aguilar, Gutiérrez-López y Aparicio-Mijares (2018). Rulfova, Buishand, Roth y Kysely (2016) propusieron la distribución TCGEV (two-component generalized extreme value) de dos componentes de valores extremos generalizados, como un modelo más flexible para el análisis de precipitaciones máximas anuales de seis horas de duración.
La distribución TCEV se describe con detalle en este artículo debido a que no ha sido aplicada en México de manera sistemática, ni bajo precepto, ni como una opción de los modelos probabilísticos sugeridos en registros de crecientes con poblaciones mezcladas.
Objetivo
En este trabajo se expone con detalle el origen teórico de la distribución TCEV (two-component extreme value) con cuatro parámetros de ajuste, que conduce a un modelo probabilístico adecuado a registros de crecientes anuales que proceden de dos mecanismos físicamente diferentes, pero que están mezclados. El método de ajuste de la distribución TCEV, por medio de máxima verosimilitud, se describe en sus dos versiones: (1) método numérico de sustituciones sucesivas y (2) método numérico de optimización. Se procesan, con ambos métodos, seis registros de crecientes tomados de la literatura especializada, los cuales varían de 31 a 72 datos, y tienen entre tres y seis valores dispersos. Enseguida, se contrastan seis predicciones de periodos de retorno de 10, 25, 50, 100, 500 y 1 000 años, cada una con seis valores procedentes del ajuste de las distribuciones TCEV, Log-Pearson tipo III, General de Valores Extremos, Logística Generalizada y Wakeby. Por último, se formulan las conclusiones de estudio.
Otros métodos de ajuste y aplicaciones de la distribución TCEV
Francés (1998) amplió el método de máxima verosimilitud para el uso conjunto de información sistemática e histórica de crecientes. En cambio, Beran, Hosking y Arnell (1986) exponen tres ecuaciones para cuantificar los momentos de probabilidad pesada (MPP) e indican que tales expresiones deben resolverse de manera iterativa, por lo cual resultan más complicadas que el método de máxima verosimilitud. El procedimiento del método de los MPP ha sido expuesto por Singh (1998), así como el basado en el principio de máxima entropía, sugerido originalmente por Fiorentino, Arora y Singh (1987).
Por otra parte, Fiorentino, Versace y Rossi (1985) fueron los primeros en indicar que la distribución TCEV mostró un buen ajuste en registros de precipitación máxima diaria anual del sur de Italia, que fueron procesados como series de duración parcial o de magnitudes superiores a un valor umbral. Posteriormente, Cannarozzo, D’Asaro y Ferro (1995) aplicaron la distribución TCEV de manera regional en Sicilia, Italia, usando registros de lluvia y de crecientes. Ferro y Porto (2006) usan el modelo TCEV con el enfoque jerárquico regional en un AFC para Sicilia, Italia. Tal enfoque regional fue propuesto originalmente por Fiorentino, Gabriele, Rossi y Versace (1987). Boni, Parodi y Rudari (2006), así como Aronica y Candela (2007) emplean la distribución TCEV en los análisis regionales de lluvias que han descrito. Escalante-Sandoval y Reyes-Chávez (2004) realizan un análisis bivariado de crecientes, empleando como distribuciones marginales la TCEV.
Descripción de la teoría y datos
FDP de los modelos mixtos
Waylen y Woo (1982) llaman R a la variable aleatoria que representa a las crecientes anuales originadas por la precipitación, que son las más grandes, y S a las generadas por la fusión de la nieve, que son las básicas o menores; Xi es una nueva variable aleatoria que es el máximo de ambas; i es el año, y n es la amplitud del registro disponible. Como se acepta la hipótesis de que R y S son independientes, su FDP es igual al producto de ambas, y cada una se estima por separado con los n datos correspondientes tomados del registro. Entonces, la función de probabilidad de no excedencia de Xi es (Francés-García, 1995):
En el caso más simple, FR (x) y FS (x) son FDP Gumbel, con dos parámetros de ajuste, ubicación y escala, cada una. La aplicación de la distribución Gumbel doble de cinco parámetros de ajuste se ha resuelto de manera práctica a través de optimización numérica no restringida (Gómez, Aparicio, & Patiño, 2010); su FDP es (González-Villarreal, 1970):
En la ecuación anterior, p es la probabilidad de tener eventos ordinarios. En la distribución Wakeby (Houghton, 1978), la nueva variable aleatoria está definida por la suma, ya que la creciente máxima anual se produce por la combinación en el tiempo de los dos mecanismos generadores y entonces su FDP se expresa en forma explícita como:
La estimación de sus cinco parámetros de ajuste se ha resuelto por medio del método de los momentos L (Hosking & Wallis, 1997) y mediante optimización numérica restringida (Campos-Aranda, 2001). Por último, la distribución Gumbel mixta ha sido ajustada con base en algoritmos modernos de búsqueda (Molina-Aguilar et al., 2018); su FDP es similar a la >Ecuación (3), ésta es:
Génesis de la distribución TCEV
Proceso compuesto de Poisson
Rossi et al. (1984) establecieron que un principio teórico es necesario que respalde a una cierta FDP, para que pueda ser considerada y aceptada como un modelo de origen o fuente (parent distribution) de las crecientes de una cierta región geográfica. Debido a las limitaciones que tienen los registros disponibles de crecientes, además de sus particularidades estadísticas, la FDP por seleccionar debe contar con una estructura probabilística que simule la procedencia real de las crecientes de la zona bajo estudio.
Al respecto, Rossi et al. (1984) indican que la hipótesis básica de la teoría de valores extremos es muy restrictiva, al considerar que las crecientes anuales provienen del valor máximo de la una serie amplia de variables aleatorias independientes e idénticamente distribuidas (iid). Un planteamiento más flexible y de mayor similitud con la realidad física considera que las crecientes anuales (X) son el máximo de una secuencia de k números aleatorios con distribución de Poisson, que son variables aleatorias iid no negativas Zi , con i = 1, 2,..., k, las cuales son también independientes de k. Lo anterior equivale a modelar X como el máximo de un proceso compuesto de Poisson, cuya FDP es (Todorovic & Zelenhasic, 1970):
en donde λ = E[k] es el parámetro del proceso de Poisson. Si Z se adopta como una variable aleatoria exponencial, se tiene que:
siendo θ = E[Z]. Sustituyendo la Ecuación (7) en la Ecuación (6) se obtiene:
La expresión anterior se puede transformar en la FDP Gumbel o tipo I de valores extremos, haciendo su parámetro de ubicación ε igual a θ por el logaritmo natural de λ, obteniéndose:
siendo:
Y:
La Ecuación (8) tiene una discontinuidad en x = 0, que vale exp(-λ), es decir, exhibe una componente delta, mientras que la Ecuación (9) se extiende hacia los valores negativos de x. El valor de exp(-λ) es cercano a cero, excepto quizás en climas áridos por la ocurrencia de valores nulos (Rossi et al., 1984).
Desarrollo del modelo mixto
Un enfoque posible para tomar en cuenta en los AFC la presencia de valores dispersos (outliers) y series de una asimetría elevada consiste en aceptar que el registro de crecientes proviene de dos mecanismos diferentes de generación: uno de ellos origina crecientes de baja magnitud, pero frecuentes, y el otro genera crecientes extraordinarias esporádicas. Entonces, asumiendo que existen dos secuencias de crecientes independientes de variables iid, Z1i , i = 1, 2,..., K1 y Z2j , j = 1, 2,…, K2, cada una definida por un proceso compuesto de Poisson con parámetros λ1 = E[K1] y λ2 = E[K2], respectivamente, con λ1 > λ2. El número total K = K1 + K2 de crecientes independientes en un año será también un proceso compuesto de Poisson con parámetro λ = λ1 + λ2, mientras que la magnitud Z de las crecientes anuales estará definida por la mezcla de FDP, es decir (Rossi et al., 1984):
en donde p = λ1/λ es la proporción de Z1 en la mezcla (crecientes básicas u ordinarias) y (1 - p) la de las crecientes extraordinarias con mucha mayor variabilidad. Sustituyendo la Ecuación (6) en la Ecuación (12) se obtiene:
Designando con X1 y X2 a los máximos anuales de Z1 y Z2 se tiene que:
Por último, si Z1 y Z2 son variables aleatorias exponenciales, como en la Ecuación (8), la Ecuación (14) se transforma en la distribución de valores extremos de dos componentes (TCEV):
Sus cuatro parámetros de ajuste caracterizan las crecientes básicas y las extraordinarias con el número medio de crecientes independientes por año (λ1 > 0, λ2 ≥ 0) y la amplitud media del gasto máximo anual (θ2 ≥ θ1 > 0). Fiorentino et al. (1985) destacan que la Ecuación (15) tiene una probabilidad finita cercana a cero, cuyo valor es exp(-λ), y que en ausencia de la componente de valores extraordinarios, la distribución TCEV se reduce a la distribución Gumbel. La función de densidad de probabilidad de X, según la ecuación anterior es:
en la cual:
Generalizando la Ecuación (11) y aplicándola a la Ecuación (15), se obtiene que el modelo TCEV equivale al producto de dos distribuciones Gumbel (Rossi et al., 1984; Metcalfe, 1997), ésta es:
En la ecuación anterior, ε1 y ε2 son los parámetros de ubicación y θ1 y θ2 los de escala de cada distribución Gumbel.
Probabilidad de valores dispersos
Beran et al. (1986) exponen y analizan diversos aspectos teóricos complementarios relativos a la distribución TCEV. Encuentran que al igual que la distribución Wakeby, el modelo TCEV tiene extremo derecho más denso que la mayoría de las FDP utilizadas en hidrología. También demuestran que la distribución TCEV es capaz de mostrar el fenómeno de separación al utilizar registros amplios de Inglaterra.
Beran et al. (1986) sugieren que la proporción de valores dispersos de un registro es de interés y puede ser utilizada para validar la aceptación de la distribución TCEV. Esta proporción denominada q es función de θ y λ, según las expresiones siguientes:
Beran et al. (1986) exponen una gráfica para estimar q, cuyas rectas varían de 0.01 a 0.90, con θ∙ln λ en las abscisas y θ en las ordenadas. También indican que en la Ecuación (21) la serie converge rápidamente para q < 0.90 y que cuando se empleó la distribución TCEV con 2 334 estaciones-año de 57 registros de Inglaterra se obtuvo un valor disperso por cada 33 datos máximos anuales; es decir, q = 3.03 %; en cambio, Rossi et al. (1984) encuentran en los ríos italianos un valor disperso por cada siete datos anuales, es decir, q = 14.3 %. Para estimar el valor de la función Gamma se puede emplear la aproximación de Stirling (Davis, 1972):
Ajuste por máxima verosimilitud
1. Método Numérico de Sustitución Sucesiva
Rossi et al. (1984) exponen el logaritmo natural de la función de máxima verosimilitud y lo designan por Lfmv ; su expresión es:
Igualando a cero las derivadas parciales de Lfmv con respecto a los cuatro parámetros de ajuste y realizando varias operaciones algebraicas, Rossi et al. (1984) obtienen las cuatro ecuaciones siguientes, las cuales se resuelven mediante una técnica numérica de sustitución sucesiva:
Para asegurar una convergencia rápida conviene iniciar con unos valores de λ y θ lo más aproximados posible. Para la búsqueda de los valores iniciales, primero se dibujan en el papel Gumbel-Powell (Chow, 1964) los datos del registro de crecientes, asignándoles una posición gráfica o probabilidad de no excedencia por medio de la fórmula de Weibull (Benson, 1962):
donde m es el número de orden del dato cuando éstos han sido ordenados de menor a mayor; n es el número de observaciones, crecientes o datos. Enseguida se identifica la serie básica y se representa por una línea recta o distribución Gumbel (Ecuación (9)), definiendo un punto F1, X1 en su inicio y otro hacia el final de los datos, que se designa F2, X2. Después se traza otra recta o modelo Gumbel con mayor pendiente para representar los valores extremos o crecientes extraordinarias, usando como punto inicial F2, X2, y definiendo un punto final en F3, X3 hacia el último de los datos. Estas tres parejas de valores son llevados a las fórmulas siguientes, que proceden de la Ecuación (9) (Campos-Aranda, 2002), para definir los valores iniciales λj y θj :
Con base en los valores iniciales, se aplican por primera vez la Ecuación (24) y Ecuación (25), y se evalúa la función logarítmica de máxima verosimilitud (Lfmv ), con la Ecuación (23), y con la Ecuación (15) y Ecuación (17) auxiliares. También se calcula el error estándar de ajuste con la Ecuación (33).
Enseguida, los nuevos valores de λj y θj se convierten en los iniciales y se vuelven a aplicar la Ecuación (24) y Ecuación (25). Si el valor de Lfmv disminuyó, se repite el proceso; si aumentó, se suspende la sustitución sucesiva. Este proceso se programó en lenguaje Basic y se llamó a tal código TCEVMV.
Al concluir el proceso, se tienen los valores óptimos de los parámetros de ajuste y con ellos se aplica de manera repetida la Ecuación (15) para obtener parejas de valores de x y FX (x), a fin de construir el modelo TCEV en el papel Gumbel-Powell, y obtener las predicciones buscadas asociadas con periodos de retorno (Tr) o intervalos promedio de recurrencia de 10, 25, 50, 100, 500 y 1 000 años. El Tr es el recíproco de la probabilidad de excedencia y entonces los Tr citados corresponden a probabilidades de no excedencia [FX (x)] de 0.90, 0.96, 0.98, 0.99, 0.998 y 0.999, respectivamente.
2. Método de maximización de la función objetivo
Metcalfe (1997) propuso maximizar el logaritmo de la función de máxima verosimilitud (Ecuación (23)), para el ajuste de la distribución TCEV; por ello, Campos-Aranda (2002) usó el valor negativo de tal expresión (Lfmv ), como función objetivo a minimizar por medio de un algoritmo numérico de múltiples variables no restringidas (Rosenbrock, 1960), a través del código disponible en Fortran (Kuester & Mize, 1973), el cual fue traducido al lenguaje Basic por facilidad de manejo de datos e impresiones (Campos-Aranda, 2003).
Las pruebas numéricas demostraron que el uso de la Ecuación (18) en la Ecuación (23) es más conveniente que la aplicación de la Ecuación (15) debido a una mayor estabilidad numérica y una convergencia más rápida hacia el mínimo buscado. Este algoritmo numérico se programó en lenguaje Basic y se designó a tal código TCEVROS.
Para el arranque del algoritmo de Rosenbrock se definen unos valores iniciales de las variables a optimizar o parámetros de ajuste de la distribución TCEV; con base en la Ecuación (27), Ecuación (28), Ecuación (29), Ecuación (30) y Ecuación (31). Con tales valores iniciales (ε1, θ1, ε2 y θ2) se calcula la primera magnitud de la función objetivo (Ecuación (23), auxiliándose de la Ecuación (17)) y se comienza la búsqueda del mínimo por medio del algoritmo de Rosenbrock.
Al concluir el proceso, se definen las etapas y evaluaciones de la función objetivo (FO) y se obtienen los valores óptimos de los parámetros de ajuste, y con ellos se aplica de manera repetida la Ecuación (18) para obtener parejas de valores de x y FX (x), así como las predicciones, como se hizo en el método numérico de sustitución sucesiva.
Error estándar de ajuste
Con fines de comparación cuantitativa del ajuste logrado con la distribución TCEV y el método de máxima verosimilitud frente a otros modelos probabilísticos, se propuso estimar el llamado error estándar de ajuste (EEA), definido como (Kite, 1977):
siendo n el número total de datos; Qoi , el gasto máximo anual observado ordenado de menor a mayor; y Qci , el gasto máximo calculado con la distribución TCEV (Ecuación (15) o Ecuación (18)), para la misma probabilidad de no excedencia asignada al gasto observado mediante la fórmula de Weibull (Ecuación (26)). Por último, np es el número de parámetros de ajuste; en este caso, cuatro: λ1 o ε1; θ1, λ2 o ε2, θ2.
Como la Ecuación (15) y la Ecuación (18) no tienen solución inversa, el planteamiento fue utilizar el método numérico de bisección con tolerancia de error igual a 0.0001 entre la probabilidad calculada (Ecuación (26)) y la obtenida con la Ecuación (15) o con la Ecuación (18), utilizando valores límites inferior de 0.001 de Qoi y superior de tres veces Qoi . La evaluación del EEA se intentó al terminar el cálculo de los valores iniciales de los parámetros de ajuste (Ecuación (27), Ecuación (28), Ecuación (29), Ecuación (30), Ecuación (31) y Ecuación (32)). Algunas veces el método numérico de bisección no funcionó, por ejemplo, cuando la distribución TCEV no coincide con los datos; para tales casos se suprime el uso de la subrutina del EEA. El otro cálculo del EEA se realizó al terminar el método numérico de sustitución o el algoritmo de Rosenbrock, y por lo general concluyó de modo satisfactorio.
Registros de crecientes por procesar
Se procesaron seis series de gastos máximos anuales (m3/s) tomadas de la literatura especializada, las cuales se exponen en orden progresivo de amplitud (n) en la Tabla 1. Su procedencia es la siguiente: (1) tomado de Haan, Barfield y Hayes (1994) de la localidad llamada Beargrass Creek con 31 valores; (2) el registro de 37 valores de la estación Santa Cruz, lo han expuesto Molina-Aguilar et al. (2018); (3) Francés-García (1995) presentó el del río Turia en la estación E-25 con 41 datos; (4) el registro de 53 datos en la estación Huites procede de Campos-Aranda (1999); (5) Gómez et al. (2010) mostraron el registro de 58 datos en la estación La Cuña; por último, (6) Kite (1991) presentó los datos del río St. Mary con 72 datos.
Tabla 1 Gastos máximos anuales (m3/s) en los seis registros procesados de las estaciones hidrométricas: Beargrass Creek, Santa Cruz, E-25 río Turia, Huites, La Cuña y río St. Mary.
| Núm. | Registro número | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | ||||
| 1 | 51.3 | 2 142.0 | 139 | 2 085 | 1 530 | 784.0 | 595.2 | 565 | 824 |
| 2 | 22.4 | 1 023.4 | 90 | 2 531 | 8 000 | 736.8 | 110.2 | 294 | 292 |
| 3 | 23.8 | 837.6 | 63 | 14 376 | 5 496 | 510.0 | 523.9 | 303 | 345 |
| 4 | 49.6 | 1 161.2 | 2 300 | 2580 | 3 385 | 461.0 | 1 636.3 | 569 | 442 |
| 5 | 25.4 | 1 062.0 | 26 | 1 499 | 1 374 | 411.0 | 1 168.0 | 232 | 360 |
| 6 | 60.0 | 784.2 | 260 | 1 165 | 1 245 | 326.0 | 295.0 | 405 | 371 |
| 7 | 34.5 | 1 086.3 | 117 | 1 127 | 2 299 | 349.8 | 212.8 | 228 | 544 |
| 8 | 36.5 | 487.8 | 76 | 3 215 | 1 345 | 130.4 | 367.4 | 232 | 552 |
| 9 | 21.7 | 677.0 | 514 | 10 000 | 11 350 | 690.0 | 144.6 | 394 | 651 |
| 10 | 44.5 | 807.0 | 84 | 3 229 | 2 509 | 266.0 | 78.4 | 238 | 190 |
| 11 | 35.1 | 553.0 | 90 | 677 | 2 006 | 199.0 | 261.9 | 524 | 202 |
| 12 | 30.0 | 1 252.0 | 3 700 | 1 266 | 1 180 | 690.0 | 196.3 | 368 | 405 |
| 13 | 42.2 | 369.5 | 88 | 1 025 | - | 340.6 | 46.8 | 464 | 583 |
| 14 | 25.0 | 293.0 | 155 | 955 | - | 249.6 | 313.8 | 411 | 725 |
| 15 | 37.4 | 1 157.2 | 199 | 4 780 | - | 350.0 | 319.6 | 368 | 232 |
| 16 | 93.4 | 762.2 | 60 | 696 | - | 317.0 | 621.1 | 487 | 974 |
| 17 | 68.0 | 1074.0 | 58 | 593 | - | 732.6 | 824.5 | 394 | 456 |
| 18 | 27.6 | 1 280.0 | 79 | 3 010 | - | 265.1 | - | 337 | 289 |
| 19 | 26.0 | 1 002.0 | 150 | 1 908 | - | 743.6 | - | 385 | 348 |
| 20 | 111.0 | 3 680.0 | 918 | 15 000 | - | 463.9 | - | 351 | 564 |
| 21 | 32.6 | 861.0 | 90 | 1 396 | - | 1 474.9 | - | 518 | 479 |
| 22 | 24.7 | 888.8 | 133 | 1 620 | - | 323.0 | - | 365 | 303 |
| 23 | 20.2 | 1 166.4 | 25 | 2 702 | - | 160.4 | - | 515 | 603 |
| 24 | 41.1 | 950.0 | 150 | 1 319 | - | 763.8 | - | 280 | 514 |
| 25 | 20.0 | 7000.0 | 136 | 1 944 | - | 578.0 | - | 289 | 377 |
| 26 | 147.2 | 484.0 | 35 | 2 420 | - | 191.8 | - | 255 | 318 |
| 27 | 60.9 | 920.6 | 43 | 2 506 | - | 2 440.0 | - | 334 | 342 |
| 28 | 33.1 | 812.0 | 34 | 1 534 | - | 238.4 | - | 456 | 593 |
| 29 | 58.9 | 3 332.4 | 40 | 1 508 | - | 622.1 | - | 479 | 378 |
| 30 | 35.4 | 898.0 | 238 | 1 558 | - | 1 374.0 | - | 334 | 255 |
| 31 | 64.3 | 2 790.0 | 37 | 2 200 | - | 439.7 | - | 394 | 292 |
| 32 | - | 620.0 | 49 | 2 225 | - | 280.2 | - | 348 | - |
| 33 | - | 1 495.0 | 32 | 7 960 | - | 267.2 | - | 428 | - |
| 34 | - | 836.0 | 42 | 4 001 | - | 287.3 | - | 337 | - |
| 35 | - | 940.0 | 34 | 1 067 | - | 280.7 | - | 311 | - |
| 36 | - | 3 080.0 | 117 | 3 233 | - | 156.5 | - | 453 | - |
| 37 | - | 1 550.0 | 64 | 1 119 | - | 455.5 | - | 328 | - |
| 38 | - | - | 48 | 6 178 | - | 501.2 | - | 564 | - |
| 39 | - | - | 48 | 4 443 | - | 385.0 | - | 527 | - |
| 40 | - | - | 42 | 1 474 | - | 698.2 | - | 510 | - |
| 41 | - | - | 144 | 2 508 | - | 184.7 | - | 371 | - |
Para las tres estaciones de aforo de México se citan enseguida su clave, ubicación y periodo de registro: (1) Santa Cruz: 10040, río San Lorenzo de la Región Hidrológica No. 10 (Sinaloa), 1944-1980; (2) Huites: 10037, río Fuerte de la Región Hidrológica No. 10 (Sinaloa), 1941-1993; y (3) La Cuña: 12054, río Verde de la Región Hidrológica No. 12-3 (río Santiago), 1947-2004.
Verificación de la homogeneidad de los registros
Para que los resultados del AFC sean confiables, los datos a utilizar deben proceder de un proceso aleatorio estacionario, lo cual implica que no haya cambiado en el tiempo. Entonces los registros de crecientes deben estar integrados por datos independientes, que estén libres de componentes determinísticas, para que tal registro sea homogéneo.
A fin de comprobar lo anterior, se aplicaron siete pruebas estadísticas, una general, el Prueba de Von Neumann y seis específicas: dos de persistencia (Anderson y Sneyers), dos tendencia (Kendall y Spearman), una para el cambio en la media (Cramer) y la última para buscar inconsistencia en la dispersión (Bartlett). Estas pruebas se pueden consultar en WMO (1971), y Machiwal y Jha (2008). Todas las pruebas citadas se aplicaron con un nivel de significancia (α) del 5 % y seis de ellas indican que los registros seleccionados son homogéneos. La prueba de Bartlett detecta pérdida de homogeneidad por exceso de variabilidad debido a la presencia de los valores dispersos.
Como complemento se aplicó la prueba de Wald-Wolfowitz, no paramétrica, que ha sido utilizada por Bobée y Ashkar (1991), y por Rao y Hamed (2000) para probar independencia y estacionariedad en registros de gastos máximos anuales (xi ). Con base en esta prueba, también se aprobó la calidad estadística de los registros por procesar.
Resultados y su análisis
Ajustes según método numérico de sustitución
En la Tabla 2 y Tabla 3 se muestran los resultados del ajuste de la distribución TCEV a los seis registros procesados con base en la Ecuación (24) y Ecuación (25). Se observa que el número de iteraciones varió de 1 a 15 y que únicamente en el registro 3 del río Turia no se pudo evaluar el EEA inicial. La valoración de la calidad del ajuste logrado con este método será estimada durante el contraste de sus predicciones.
Tabla 2 Resultados del ajuste de la distribución TCEV según el método numérico de sustitución en las tres estaciones hidrométricas indicadas.
| Estación | Beargrass Creek | Santa Cruz | Río Turia |
|---|---|---|---|
| Datos en | Haan et al. (1994) | Molina-Aguilar et al. (2018) | Francés-García (1995) |
| Número de datos | 31 | 37 | 41 |
| Mínimo, máximo | 20.0, 147.2 | 293.0, 7 000.0 | 25.0, 3 700.0 |
| F1, X1 | 0.20, 24.0 | 0.022, 300.0 | 0.10, 35.0 |
| F2, X2 | 0.83, 62.0 | 0.830, 1600.0 | 0.90, 500.0 |
| F3, X3 | 0.97, 148.0 | 0.974, 7000.0 | 0.98, 1750.0 |
| (λ1)inicial | 6.282 | 7.662 | 2.904 |
| (θ1)inicial | 17.6 | 430.5 | 150.8 |
| (λ2)inicial | 0.688 | 0.333 | 0.204 |
| (θ2)inicial | 47.5 | 2 760.3 | 756.9 |
| FO(ln L)inicial | -139.490 | -293.149 | -278.073 |
| EEAinicial (m3/s) | 11.6 | 375.3 | - |
| Número de iteraciones: | 4 | 1 | 15 |
| (λ1)final | 12.120 | 6.558 | 5.030 |
| (θ1)final | 15.8 | 337.0 | 38.0 |
| (λ2)final | 0.784 | 0.238 | 0.138 |
| (θ2)final | 46.4 | 2180.2 | 1401.5 |
| FO(ln L)final | -137.440 | -290.976 | -243.446 |
| EEAfinal (m3/s) | 6.9 | 328.3 | 246.8 |
Tabla 3 Resultados del ajuste de la distribución TCEV según método numérico de sustitución en las tres estaciones hidrométricas indicadas.
| Estación | Huites | La Cuña | St. Mary’s River |
|---|---|---|---|
| Datos en | Campos-Aranda (1999) | Gómez et al. (2010) | Kite (1991) |
| Número de datos | 53 | 58 | 72 |
| Mínimo, máximo | 593.0, 15 000.0 | 46.8, 2 440.0 | 190.0, 974.0 |
| F1, X1 | 0.10, 1 000.0 | 0.018, 50.0 | 0.05, 220.0 |
| F2, X2 | 0.80, 3 500.0 | 0.905, 860.0 | 0.95, 660.0 |
| F3, X3 | 0.98, 16 700.0 | 0.984, 2 475.0 | 0.99, 1 040.0 |
| (λ1)inicial | 5.857 | 5.047 | 22.894 |
| (θ 1)inicial | 1 071.1 | 219.2 | 108.2 |
| (λ2)inicial | 0.422 | 0.263 | 0.870 |
| (θ 2)inicial | 5 495.4 | 886.0 | 233.1 |
| FO(ln L)inicial | -473.167 | -412.894 | -452.755 |
| EEAinicial (m3/s) | 790.1 | 116.4 | 33.9 |
| No. iteraciones: | 5 | 5 | 1 |
| (λ1)final | 6.450 | 4.945 | 21.770 |
| (θ 1)final | 655.4 | 160.9 | 100.1 |
| (λ2)final | 0.358 | 0.253 | 0.706 |
| (θ 2)final | 5088.6 | 734.5 | 181.1 |
| FO(ln L)final | -466.344 | -408.736 | -452.673 |
| EEAfinal (m3/s) | 478.7 | 83.1 | 30.3 |
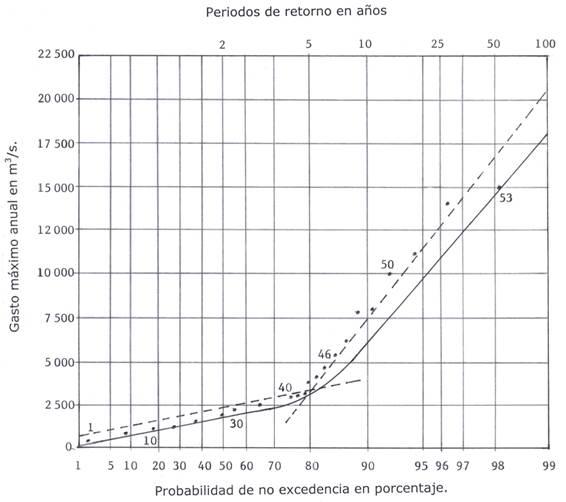
En la Figura 1 se tienen dibujados, en el papel de probabilidad Gumbel-Powell, los datos del registro en la estación Huites, en intervalos de cinco valores del 1 al 40, y de ahí en delante de 1 en 1. Con líneas punteadas se muestran las rectas que representan a las dos poblaciones y con línea continua la distribución TCEV calculada con el método numérico de sustitución sucesiva. Se observa que el modelo TCEV sigue de manera aproximada a las crecientes básicas hasta la número 42, pero se aparta de las extraordinarias desde la número 43 y coincide con la última, que es el dato 53.
Ajustes según método numérico de optimización
En los registros de Santa Cruz y La Cuña, los valores iniciales definidos por los puntos F1, X1 a F3, X3 no permitieron el arranque del algoritmo de Rosenbrock y, por ello, se modificaron ligeramente, como se muestra en la Tabla 4 y Tabla 5, de resultados del ajuste de la función TCEV a los seis registros procesados. Se observa que algunas veces este método mejoró el ajuste (menores Lfmv y EEA), como en el primero y el último de los registros procesados, y en otras ocasiones no superó los resultados del método numérico de sustitución, como fue el caso de los registros del río Turia y de Huites. Por lo anterior, se recomienda que de manera normal se apliquen ambos métodos de ajuste por máxima verosimilitud.
Tabla 4 Resultados del ajuste de la distribución TCEV según el método numérico de optimización en las tres estaciones hidrométricas indicadas.
| Estación | Beargrass Creek | Santa Cruz | Est. 25 Río Turia |
|---|---|---|---|
| F1, X1 | 0.20, 24.0 | 0.10, 550.0 | 0.10, 35.0 |
| F2, X2 | 0.83, 62.0 | 0.78, 1 300.0 | 0.90, 500.0 |
| F3, X3 | 0.97, 148.0 | 0.95, 3 830 | 0.98, 1 750.0 |
| (ε 1)inicial | 32.387 | 830.945 | 160.738 |
| (θ 1)inicial | 17.624 | 336.852 | 150.759 |
| (ε 2)inicial | -17.785 | -932.923 | -1 203.201 |
| (θ 2)inicial | 47.848 | 1 603.572 | 756.855 |
| FO(ln L)inicial | -139.490 | -291.499 | -278.073 |
| EEAinicial (m3/s) | 11.6 | 432.9 | - |
| Número de etapas | 6 | 8 | 17 |
| Número de evaluaciones | 72 | 118 | 232 |
| (ε1)final | 27.918 | 729.148 | 60.849 |
| (θ1)final | 8.133 | 277.394 | 36.710 |
| (ε2)final | -19.230 | -1 274.057 | -1 913.153 |
| (θ2)final | 43.013 | 1 719.063 | 1 133.334 |
| FO(ln L)final | -134.291 | -289.773 | -243.634 |
| EEAfinal (m3/s) | 5.9 | 397.9 | 267.0 |
Tabla 5 Resultados del ajuste de la distribución TCEV según método numérico de optimización en las tres estaciones hidrométricas indicadas.
| Estación | Huites | La Cuña | St. Mary’s River |
|---|---|---|---|
| F1, X1 | 0.10, 1 000.0 | 0.05, 80.0 | 0.01, 185.0 |
| F2, X2 | 0.80, 3 500.0 | 0.88, 750.0 | 0.90, 580.0 |
| F3, X3 | 0.98, 16 700.0 | 0.97, 1 850.0 | 0.99, 1 010.0 |
| (ε 1)inicial | 1 893.361 | 313.058 | 344.690 |
| (θ 1)inicial | 1 071.135 | 212.414 | 104.565 |
| (ε 2)inicial | -4742.809 | -827.543 | 168.192 |
| (θ 2)inicial | 5 495.425 | 766.904 | 182.996 |
| FO(ln L)inicial | -473.167 | -411.328 | -455.004 |
| EEAinicial(m3/s) | 790.1 | 93.9 | 50.4 |
| Número de etapas | 12 | 6 | 8 |
| Número de evaluaciones | 184 | 127 | 98 |
| (ε 1)final | 1 445.455 | 280.490 | 315.582 |
| (θ 1)final | 639.558 | 162.207 | 96.423 |
| (ε 2)final | -6 417.104 | -1 157.494 | 165.375 |
| (θ 2)final | 5 969.293 | 852.125 | 145.344 |
| FO(ln L)final | -466.337 | -408.863 | -451.528 |
| EEAfinal (m3/s) | 540.6 | 54.4 | 22.5 |
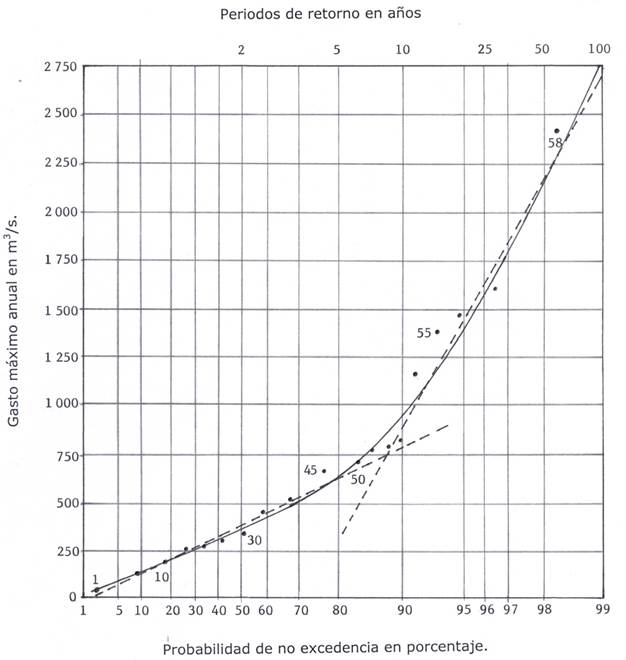
En la Figura 2 se tienen dibujados, en el papel de probabilidad Gumbel-Powell, los datos del registro en la estación La Cuña en intervalos de cinco valores del 1 al 50, y de ahí en delante de 1 en 1. Con líneas punteadas se muestran las rectas que representan a las dos poblaciones y con línea continua la distribución TCEV calculada con el método de maximización de la función objetivo. Se observa que el modelo TCEV representa de forma excelente a todas las crecientes.
Contrastes de las predicciones de la distribución TCEV
Un primer contraste se realizó entre las predicciones obtenidas con cada uno de los dos métodos de ajuste de la distribución TCEV aplicados. Se deduce que ambos métodos conducen a predicciones similares en todos los registros, destacando el último por su similitud y el de la estación Huites por sus diferencias. Lo anterior ratifica la sugerencia de ajustar el modelo TCEV con ambos métodos expuestos.
El segundo contraste de predicciones se llevó a cabo utilizando las tres distribuciones cuya aplicación ha sido sugerida bajo precepto. La Log-Pearson tipo III (LP3) en EUA; la General de Valores Extremos (GVE) en Inglaterra, de 1975 a 2000; y la Logística Generalizada (LOG), que actualmente se aplica en Inglaterra (Shaw, Beven, Chappell, & Lamb, 2011). Además, se aplicó la distribución Wakeby (Houghton, 1978), que ha demostrado gran versatilidad y habilidad descriptiva, al ser una función mixta.
La distribución LP3 se ajustó con el método de momentos en el dominio logarítmico (WRC, 1977) y en dominio real (Bobée, 1975), adoptando la de menor EEA; en cambio, las funciones GVE, LOG y Wakeby se aplicaron con el método de los momentos L (Stedinger, Vogel & Foufoula-Georgiou, 1993; Hosking & Wallis, 1997; Campos-Aranda, 2018). En la Tabla 6 se exponen las predicciones estimadas con cada uno de los cuatro modelos probabilísticos citados.
Tabla 6 Predicciones de los periodos de retorno indicados, obtenidas con cinco distribuciones de probabilidad, en los seis registros procesados.
|
Estación(*) FDP (**) |
EEA (m3/s) |
Periodos de retorno, en años | |||||
|---|---|---|---|---|---|---|---|
| 10 | 25 | 50 | 100 | 500 | 1 000 | ||
| Beargrass Creek (nvd = 3; q = 9.7 %) | |||||||
| TCEV (ns) | 6.9 | 102 | 139 | 171 | 203 | 277 | 309 |
| TCEV (no) | 5.9 | 78 | 118 | 149 | 179 | 248 | 278 |
| LP3 (dl) | 3.4 | 77 | 111 | 143 | 184 | 320 | 404 |
| GVE (mL) | 7.7 | 76 | 107 | 138 | 177 | 313 | 398 |
| LOG (mL) | 4.9 | 74 | 105 | 136 | 178 | 334 | 440 |
| WAK (mL) | 7.2 | 79 | 110 | 138 | 170 | 266 | 319 |
| Santa Cruz (nvd = 6; q = 16.2 %) | |||||||
| TCEV (ns) | 328.3 | 2 080 | 3 845 | 5 375 | 6 898 | 10 417 | 11 929 |
| TCEV (no) | 397.9 | 2 620 | 4 225 | 5 435 | 6 635 | 9 408 | 10 600 |
| LP3 (mdl) | 255.6 | 2 510 | 3 943 | 5 445 | 7 440 | 14 947 | 20 026 |
| GVE (mL) | 499.8 | 2 348 | 3 677 | 5 127 | 7 133 | 15 296 | 21 234 |
| LOG (mL) | 340.5 | 2 290 | 3 571 | 5 003 | 7 033 | 15 694 | 22 265 |
| WAK (mL) | 502.2 | 2 348 | 3 725 | 5 205 | 7 213 | 15 084 | 20 616 |
| Est. 25, río Turia (nvd = 4; q = 9.8 %) | |||||||
| TCEV (ns) | 246.8 | 381 | 1 708 | 2 693 | 3 671 | 5 932 | 6 905 |
| TCEV (no) | 267.0 | 638 | 1 712 | 2 510 | 3 300 | 5 129 | 5 915 |
| LP3 (mdl) | 207.0 | 408 | 1 093 | 2 323 | 4 975 | 30 201 | 66 688 |
| GVE (mL) | 441.0 | 453 | 958 | 1 666 | 2 883 | 10 223 | 17 612 |
| LOG (mL) | 416.9 | 355 | 750 | 1 307 | 2 269 | 8 144 | 14 119 |
| WAK (mL) | 501.0 | 369 | 793 | 1 385 | 2 395 | 8 404 | 14 381 |
| Huites (nvd = 6; q = 11.3 %) | |||||||
| TCEV (ns) | 478.7 | 6 240 | 11 050 | 14 630 | 18 200 | 26 387 | 29 916 |
| TCEV (no) | 540.6 | 7 025 | 12 680 | 16 870 | 21 045 | 30 675 | 34 814 |
| LP3 (mdl) | 949.9 | 6 290 | 10 492 | 15 061 | 21 303 | 45 851 | 63 053 |
| GVE (mL) | 1007.1 | 5 948 | 9 614 | 13 600 | 19 091 | 41 299 | 57 363 |
| LOG (mL) | 984.2 | 5 786 | 9 322 | 13 263 | 18 830 | 42 460 | 60 302 |
| WAK (mL) | 893.1 | 6 303 | 10 070 | 13 834 | 18 626 | 35 412 | 46 091 |
| La Cuña (nvd = 5; q = 8.6 %) | |||||||
| TCEV (ns) | 83.1 | 847 | 1 359 | 1 858 | 2 369 | 3 554 | 4 064 |
| TCEV (no) | 54.4 | 926 | 1 575 | 2 168 | 2 762 | 4 137 | 4 729 |
| LP3 (mdr) | 74.8 | 991 | 1 389 | 1 719 | 2 078 | 3 025 | 3 486 |
| GVE (mL) | 97.1 | 941 | 1 373 | 1 784 | 2 290 | 3 964 | 4 979 |
| LOG (mL) | 61.1 | 913 | 1 338 | 1 764 | 2 313 | 4 304 | 5 614 |
| WAK (mL) | 95.2 | 958 | 1 400 | 1 799 | 2 265 | 3 668 | 4 446 |
| St. Mary’s River (nvd = 4; q = 5.6 %) | |||||||
| TCEV (ns) | 30.3 | 568 | 680 | 769 | 862 | 1 099 | 1 211 |
| TCEV (no) | 22.3 | 595 | 707 | 795 | 888 | 1 122 | 1 233 |
| LP3 (mdl) | 16.8 | 600 | 712 | 797 | 883 | 1 093 | 1 188 |
| GVE (mL) | 22.1 | 603 | 713 | 796 | 881 | 1 079 | 1 167 |
| LOG (mL) | 15.5 | 589 | 706 | 807 | 919 | 1 240 | 1 410 |
| WAK (mL) | 23.3 | 605 | 715 | 794 | 868 | 1 025 | 1 087 |
*nvd = número de valores dispersos.
n = número de datos del registro.
q = (nvd/n)∙100.
** Método de ajuste:
ns = numérico de sustitución.
no = numérico de optimización.
mdl = momentos en el dominio logarítmico.
mdr = momentos en el dominio real.
mL = momentos L.
En términos generales, las distribuciones LP3, GVE, LOG y WAK conducen a predicciones mayores en todos los registros procesados en los periodos de retorno (Tr) de 500 y 1 000 años. Adoptando el criterio de selección del menor EEA, en los tres primeros registros la función LP3 sería la opción a tomar, pero ello conduce a predicciones elevadas en los Tr de 500 y 1 000 años. Lo anterior es notable en el río Turia y en Santa Cruz, y podría ser aceptable en el registro 1. Lo contrario ocurre en los registros de Huites y de La Cuña, en los cuales la mejor opción es la distribución TCEV, en el primero a través del método numérico de sustitución y en el segundo con el de optimización (ver Figura 1 y Figura 2). Por último, en el registro de St. Mary’s River, la distribución con el menor EEA es la Logística Generalizada, cuyas predicciones son las más grandes, pero del mismo orden de magnitud que las obtenidas con los otros modelos probabilísticos.
Conviene destacar que las predicciones de la distribución TCEV en la estación Huites (Figura 1), prácticamente coinciden con las obtenidas con el enfoque global por Campos-Aranda (1999).
Otra apreciación que se detecta en la Tabla 5 es la siguiente: cuando el porcentaje de valores dispersos (q) es cercano al 10 % o lo excede; las distribuciones que se aplican bajo precepto y la Wakeby pueden conducir a predicciones muy elevadas en los Tr superiores a los 100 años, sobre todo si tales valores dispersos son muy grandes comparados con las crecientes ordinarias, como en el caso de los registros del río Turia, Huites y Santa Cruz. En tales registros, el modelo TCEV es una opción que siempre hay que emplear, pues su origen teórico justifica su aplicación en muestras de crecientes que proceden de dos mecanismos físicos diferentes de formación, pero que están mezcladas y por ello muestran valores dispersos (outliers).
Conclusiones
Primera: la distribución TCEV constituye una opción muy importante para modelar crecientes cuando el registro disponible consiste de eventos asociados con dos procesos hidrometeorológicos diferentes; es decir, cuando existen gastos que se apartan bastante de la tendencia general de los datos, al dibujarlos en el papel Gumbel-Powell.
Segunda: de acuerdo con los resultados de la Tabla 2, Tabla 3, Tabla 4 y Tabla 5, el ajuste de la distribución TCEV mediante el método de máxima verosimilitud, según el proceso numérico de sustitución sucesiva y de optimización mediante el algoritmo de Rosenbrock, son procedimientos simples que por lo general convergen y se complementan, ya que unas veces el primero aporta mejores resultados (menores Lfmv y EEA) y otras el segundo.
Tercera: el contrate de las predicciones con seis periodos de retorno de la distribución TCEV (mostrado en la Tabla 6) permite observar que sus dos métodos de ajuste por máxima verosimilitud conducen a predicciones similares en todos los registros. Lo anterior ratifica la sugerencia de ajustar el modelo TCEV con ambos procesos expuestos.
Cuarta: las predicciones de las distribuciones que se aplican bajo precepto (LP3, GVE, y LOG) y del modelo probabilístico Wakeby pueden servir para ratificar o acotar las estimaciones obtenidas con la función TCEV, y ayudar en la selección de las crecientes de diseño, al tomar en cuenta la génesis de las crecientes, el EEA y las capacidades predictivas de cada distribución.

