











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
Automatic summarization is a challenging task, as there are many issues such as redundancy, temporal handling, co-reference, sentence order, etc. that need particular attention when summarizing multiple documents, thereby, making this task complex [6].
A summary contains the main ideas of documents; in order to perform this task automatically, there are two different approaches: paraphrasing the main ideas of a document, or extracting sentences from the documents representing main ideas. This work focuses on this latter approach, called extractive summarization. The purpose of an algorithm for text summarization is to create a document formed by the most relevant information [4]; even for humans, this is a crucial step. There are several ways to determine which sentences are the most relevant in a set of documents.
Many algorithms to extract salient sentences from texts have been developed since the 1950s, when automatic text summarization arose. The first algorithm was based on topic representation, based on the idea that the more often a word repeats, the more likely it is to be important for identifying in the document [16]. This representation does not capture semantic and syntactic information; nevertheless, recent works with a similar approach have had a performance of 48% (recall) in a well-known dataset such as DUC (Document Understanding Conferences) 2002 [24]. Combining topic representation (word space models) with syntactic information such as Part Of Speech (POS) tagging helps to improve performance up to 55% (recall) [7].
In this work we propose using word embeddings combined with unsupervised clustering for the multi-document summarization task of DUC 2002. We aim to find evidence that semantic information is kept in word embeddings and this representation is subject to be grouped based on their similarity, so that main ideas can be identified in documents.
The following subsection describes related work to the task of document summarization, then in Section 2 we give some preliminaries related to this work. Our proposal is detailed in Section 3, Results are discussed in Section 4, and finally conclusions are drawn in Section 5.
1.1 Related Works
Word embedding is a distributed vector representation technique to capture information of a word. Each column of the vector represents a latent feature of the word and captures useful semantic properties [18]. This representation obtains good performance of 53% (recall) for the summarization task maximizing a submodular function defined by the sum of cosine similarities based on sentence embeddings [9] and 56% (recall) using an objective function defined by a cosine similarity based on document embeddings. This function is calculated based on the nearest neighbors distances on embedding distributions [10]. These works show that word embeddings are a useful representation to obtain the main ideas in the documents, but rely on the definition of an objetive function adjusted to a particular domain.
The main stages to obtain an extractive summary are three: representation, scoring, and selection. The representation contains the relevant features of the text; in the scoring stage each sentence obtains a weight using a similarity metric and finally, in the selection stage the summary length constraint is satisfied.
In the original DUC 2002 competition, ten algorithms were submitted for the extractive summarization task (200 words length). [23] used weighted sentence scoring based on lexical content. This method scores sentences with higher values when the sentence is different from the others.
Some other techniques are topic-based, such as Latent Semantic Allocation (LSA), a probabilistic method that extracts semantic structure in the text that uses the document context for extracts information about word relations. A higher number of common words among sentences indicate that the sentences are semantically related. Another technique called Singular Value Decomposition (SVD) is a linear algebra method which finds the interrelations between sentences and words using matrix representation.
Wang et al. proposed a Bayesian sentence-based topic model by using the term-document and the term-sentences matrices; each row represents a term and each column represents the document and the sentences, respectively. The goal of topic models is to infer words related to a topic and the topics discussed in a document. A higher value in each location indicates that the sentence or document is strongly related to that term [25].
The centroid-based method [20] is one of the most popular extractive summarization methods; it generates summaries using cluster centroids produced by topic detection, i.e. assesses the centrality of each sentence in a cluster and extracts the most important one.
A centroid is a set of words that are statistically important for the document cluster; therefore, the centroids are used to classify relevant documents and to identify salient sentences in a cluster. Each document is represented as a weighted vector of TFIDF and the centroid is calculated using the first document. As new documents are processed, the TF IDF values are compared with the centroid using cosine similarity, if the similarity is within a threshold, the new document is included in the cluster. The hypothesis of Radev et al. is that sentences containing words from the centroid are indicative of the topic of the cluster; the obtained results prove this hypothesis. However, the used word representation (TF IDF) does not fully capture the semantic information of the words [20]
Formulating the summarization task as an optimization problem defines objective functions to evaluate candidate summaries. Objective functions are defined as essential parameters that a summary must accomplish, for example, coverage of all the main ideas [7]. Methods based on optimization methods have achieved best performance tested on DUC 2002. In Table 1 a summary of the best results is shown. A disadvantage of establishing objective functions is that they are adjusted based on a particular document set or domain, and thus, they might not represent a general way of creating summaries. This is why in this work we explore different ways of creating summaries, based on unsupervised clustering.
Table 1 Comparison of recall metrics for summaries
| Work | Method | ROUGE-1 | ROUGE-2 | F-score | Dataset |
|---|---|---|---|---|---|
| Halteren (2002) | Scoring based on lexical content | 0.2000 | — | 0.2100 | DUC 2002 |
| Radev et al. (2004a) | Centroid-cluster | 0.4538 | 0.1918 | — | Extracted by CDIR |
| Wang et al. (2009) | Position, semantic, LSA-NMF | 0.4881 | 0.2457 | — | DUC 2002 |
| John et al. (2017) | Optimization | 0.5532 | 0.2586 | 0.5419 | DUC 2002 |
2 Preliminaries
In this section, details on the task in general (Section 2.1) are presented. Then we discuss some text preprocessing techniques (Section 2.2), and evaluation methods (Section 2.3). The word embeddings used in this work are described in Section 2.4, along with the used similarity measures (Section 2.5).
2.1 The Summarization Task
The main goal of a summary is to encompass the main ideas in a document reducing the original document size. If all sentences in a text document were of equal importance, producing a summary would not be very effective, as any reduction in the size of a document would carry a proportional decrease in its informativeness. However, identifying the most relevant segments in the documents is the main challenge in summarization.
This task produces a transformation of source documents through content condensation by selecting and generalizing on important information [8]. Also, algorithms created for solving this task have a relevant application given the exponential growth of textual information online, and the need to find the main ideas of documents in a shorter time.
Research on the summarization task started to attract the attention of the scientific community in the late fifties when there was a particular interest in the automation of summarization for the production of abstracts of technical documentation [16].
2.1.1 Summarization Types
There are several distinctions in summarization, some are described below:
Source type: single-document, where a summary of a single document is produced; whereas in multi-document a summary of many documents on the same topic or the same event is built.
Output produced: extractive, which is a summary containing passages selected from the source document (usually sentences); and abstractive, where the information from the source document has been analyzed and transformed using paraphrasing, reorganizing, modifying and merging information for condensation.
Language: mono-lingual, where the language of the source document is the same for the summary; multi-lingual, which accepts two or more languages from a source document; and cross-lingual, which translates the summary to other than the original language.
Audience-oriented: generic, in this output it is assumed that anyone may end up reading the summary; and query-oriented that provides a summary that is relevant to a specific user query.
This work focuses on a multi-document, extractive, mono-lingual (English) and generic summary.
2.2 Text Preprocessing Techniques
Some of the most used techniques are:
-
— Word and sentence tokenization: Tokenization is the process of separating the text into words, phrases, symbols, or other meaningful elements called tokens. This process is considered easy compared to other tasks in natural language. However, automatically extracted text may contain inaccurately compounded tokens, spelling errors and unexpected characters that can be propagated into later phases causing problems. Therefore, tokenization is an important step and in some cases needs to be customized to the data in question.
In all modern languages that are based on Latin, Cyrillic, or Greek classical languages, such as English, word tokens are delimited by a blank space. In these languages, also called segmented languages, token boundary identification is not a complex task, an algorithm which replaces white spaces with word boundaries and inserts a white space when a word is followed by a punctuation mark will produce a reasonable performance. Nonetheless, a period is an ambiguous punctuation mark indicating a full-stop, a part of abbreviation or both. Regular expressions can resolve these ambiguities defining different string search patterns [22]. In this work Python libraries have been used for tokenization1
-
— Stop words removal: The stop words are common and non-informative words that are often filtered, such as articles, prepositions, pronouns, etc. The removal of stop words have been done using methods based on Zipf's law [26], these methods indicate a distribution of words for any corpus and established an upper and lower cut-off frequency, being stop words the ones that are not between the cut-off.
Analyzing a dataset shows the most frequent words are document type dependent. A definitive stop words list does not exist, therefore the list used in this work is a general one2 and contains 153 items.
-
— Stemming: This method is used to reduce words to a common form by removing their longest ending handling spelling exceptions. Two main principles are used in the construction of a stemming algorithm: iteration and longest-match. Iteration is based on the fact that suffixes are attached to stems in a certain order, no more than one match is allowed within a single order-class; and the longest-match principle states that within any given class of endings, the longest ending should be removed.
2.3 Summary Evaluation
There are two quality evaluation methods for the summarization task: extrinsic and intrinsic. Extrinsic methods are based on the performance of a specific task (question-answering, comprehension, etc.) while intrinsic measures are based on norm set (fluency, coverage, similarity to an annotator summary, etc.).
Both quality evaluation methods can be performed by a human or a machine. The automatic evaluation lacks the linguistic skills and emotional perspective that a human has, but is popular because the evaluation process is quick, even when the summaries are large, and provides a consistent way of comparing the various summarization algorithms [3].
2.3.1 Recall-Oriented Understudy for Gisting Evaluation (ROUGE)
The University of Southern California's Information Sciences Institute (ISI) developed the recall-based metric called ROUGE-N defined by Equation 1 [15].
where N is the number of n-grams, GSS is a set formed by the gold-standard summaries s,
In 2004, the ROUGE package was created including additional recall-based metrics, such as ROUGE-L, ROUGE-W, ROUGE-S, etc. and their precision and F-score metrics4. This package has a maximum reference count, i.e. if the word is repeated it only counts the number of times it is repeated in the gold-standard summary.
ROUGE metrics were evaluated to measure their correlation with human evaluations; for the multi-document summarization task, ROUGE-1 and ROUGE-2 showed high Pearson's correlation (90%) [14]. These two metrics are used in this work.
2.3.2 Document Understanding Conferences
In 2000, to foster progress in summarization, and as a part of an evaluation campaign organized by the Defense Advanced Research Projects Administration (DARPA) and the National Institute of Standards and Technology (NIST), the Document Understanding Conferences (DUC) were created5. In these challenges, different summarization tasks were developed by NIST and data for training and testing was distributed to participants.
In the dataset of DUC 2002 for the multi-document extractive summarization task (200 words length) 60 collections (document sets) with two gold-standard summaries each were distributed, but due to reasons beyond our knowledge, one document collection (d088) received no gold-standard summaries and two collections (d076 and d098) received only one; therefore, only 57 collections have the two gold-standard summaries. In this work, the dataset of DUC 2002 with 57 collections was used [23].
2.4 Word Embeddings
The term word embedding was originally coined by [1]. They trained a neural network to predict the next word given previous words in order to obtain a feature vector associated with each word; similar words are expected to have similar feature vectors. However, [2] were the first to demonstrate the power of pre-trained word embeddings and establish word embeddings as a highly effective tool when used in natural language processing tasks. Moreover, in [18] word embeddings were brought to the fore through the creation of word2Vec and a tool-kit enabling the training and use of pre-trained embeddings.
Word2Vec is an efficient method for learning high-quality vector representations of words from large amounts of text data using neural networks. There are two models for computing embeddings: the bag-of-words and skip-gram models. Bag-of-words model predicts the probability of a word given a context, while the skip-gram model predicts the context given a word [17].
Word embeddings result from applying unsupervised learning, therefore they do not require annotated datasets. Rather, they can be derived from already available unannotated corpora.
2.4.1 Paragraph Embeddings
With the success of word embeddings, new algorithms called paragraph embeddings were developed. These paragraph embeddings, based on word embeddings, are an unsupervised learning algorithm that learns vector representations for variable length pieces of texts such as sentences and documents. As in word embeddings, there are two models: memory model and bag-of-words. Memory model predicts a paragraph identification given a number of context words, while the bag of words model ignores context words and forces the model to predict words randomly sampled from the paragraph in the output layer [12].
A software framework implementing these techniques was created [21] and the method was named doc2Vec6. In [11] they performed an empirical evaluation of doc2Vec on two tasks: duplicate question detection in a web forum and semantic textual similarity between two sentences, finding that doc2Vec in bag-of-words model performs better than the memory model. In this work, the final hyper-parameters and model of the previous work have been used7.
2.5 Similarity Measure
Measuring similarity between vectors is related to measuring the distance between them, the smaller the distance the larger the similarity.
Finding similarity between words is a fundamental part of finding the sentence, paragraph and document similarities. Words can be similar in two ways: lexically and semantically. Words are similar lexically if they have a similar character sequence. Words are similar semantically if they are used in the same context [5].
Word and paragraph embeddings are a representation that contains lexical and semantic information in vector form, therefore to measuring their similarity vector distance has to be computed.
Cosine similarity measures the distance between two vectors using an inner product that measures the angle between them, as shown in Equation 2:
Euclidean distance is the square root of the sum of squared differences between corresponding elements of the two vectors, also called L2-distance, as shown in Equation 3:
where N is the dimension of each vector and i and j are the two vectors.
3 Proposal
The proposed method for the multi-document summarization task consists of three stages: (a) pre-process the dataset DUC 2002 in order to eliminate non-content words (Section 3.1) (b) select a word representation for this dataset to capture semantic and syntactic information and obtain sentence vectors (Section 3.2); and (c) implement a method to obtain the main ideas of the documents and select the relevant ones (Section 3.3). The sentences with main ideas will form the summary; this is the general approach to generate a summary, as described in Section 2.1. In Figure 1 a general diagram of the proposal is shown.
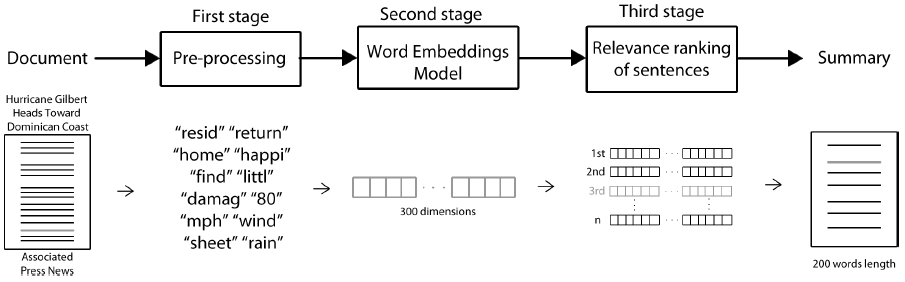
3.1 Pre-processing Stage
In the first stage sentence tokenization and word tokenization of each sentence are implemented using Python libraries based on regular expressions and named entities recognition8.
The DUC 2002 dataset has 547 documents D grouped in 57 document sets T with two gold-standard summaries each.
In this work, each set is tokenized in sentences and each sentence is tokenized in words; then the stop words have been removed using a list of non-informative words for the English language9 and stemming of each word in a sentence has been done, based on Porter's stemming10, this is shown in Figure 2.

3.2 Embeddings Model
In the second stage, the word embedding model doc2Vec is used11. The model is a trained Artificial Neural Network (ANN) whose input is a set of tokenized words-which can be extracted from a sentence, a document, or a set of documents-and its output is a vector of 300 dimensions, called, from now on, simply embedding, i.e., an embedding is a vector representation of the sentence, document, or set of documents.
An example of the embedding model used in this work is shown in Figure 3, where the input is a sentence of the DUC dataset and the output is an embedding. The final hyper-parameters and model described in [11] have been used.

In order to find the sentence that has been transformed to a vector, let
This function keeps an index to map a vector to the sentence that originated it (one to one function) in order to build the summary with the corresponding sentence from specific embeddings.
3.3 Relevance Ranking of the Sentences
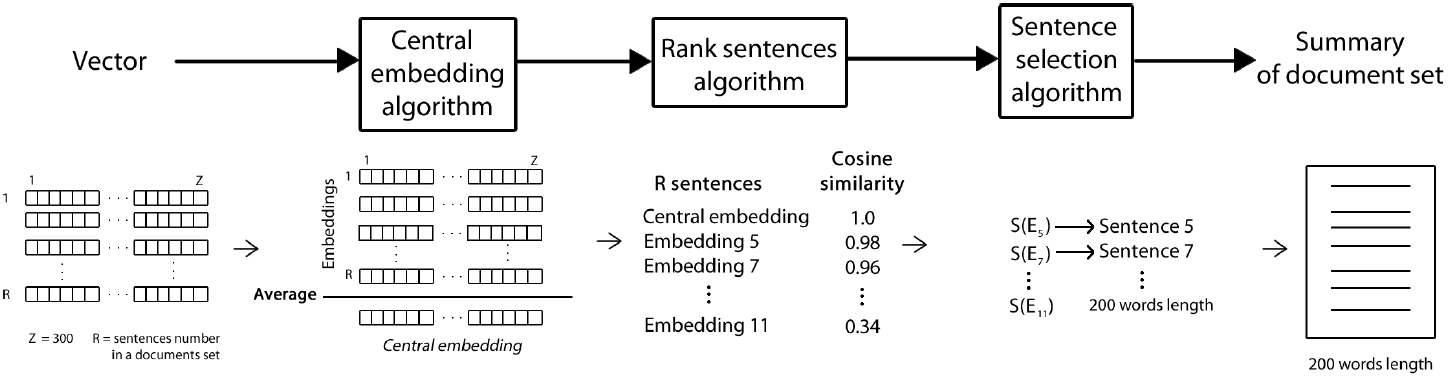
In the last stage, once the embeddings for each sentence in the DUC dataset are obtained, we propose to calculate a central vector that contains the document main ideas, using the average of the sentence embeddings.
For this approach, we consider that each column of the sentence embedding represents a document subject and a higher value indicates the important subjects. Consequently, the average of the sentence embeddings in a set should represent the subjects in the set and higher value columns indicate the important subjects in the set; we call this average central embedding (CE) and consider that it represents the main idea of the document set.
The distance between each paragraph embedding and the central embedding in each column is short if both match in most columns; this means that the sentence embedding contains the same subjects than the main idea (central embedding) of the document set, and thus it is a relevant embedding that must be included in the summary; an example of this is shown in Figure 6.
In this toy example, four vectors with four columns each are shown. The average of each column is calculated, this vector is the central embedding and the cosine similarity with each sentence embedding is shown with the aim to show that the last sentence embedding has a higher similarity because the distance in each column is shorter than the other sentence embeddings.
Recalling that word embedding model input, shown in Figure 3, could be a word, a sentence, a paragraph, a document or text of any length. We propose three different forms of computing the central embedding: (a) using the sentence embeddings (CE-S), as in Figure 6; (b) using the document embeddings (CE-D), instead of using the sentence embeddings in Figure 6 (i.e., the input in Figure 3 is a document); and (c) the central embedding is the document set embedding (CE-Set), this means that the input in Figure 3 is a document set. In Figure 4 these variants are illustrated. Algorithm 1 shows the pseudo-code for computing these three variants.

Fig. 4 Different ways of computing average vectors: (a) CE computed using the sentences (CE-S); (b) CE computed using the documents (CE-D) and; (c) CE using the document set (CE-Set). |S| is the number of sentences in each set, and |D| is the number of documents in each set

Once the central embedding is obtained, the cosine similarity between each sentence embedding and the calculated central embedding is calculated, giving ranked sentence embeddings related to a sentence using Equation 4. The top ranked sentences will form the summary. This process is depicted in Figure 5 and detailed in Algorithm 2. The central embedding CE can be CE-S, CE-D or CE-Set, as previously calculated.


4 Results
For the evaluation of the summaries in each experiment presented in Section 3, two measures have been used: ROUGE-1, ROUGE-2, and F-score because they have a high correlation with human evaluation of summaries [13].
Recalling that each document set contains two gold-standard summaries of 200 words length, we present the results comparing each gold-standard summary separately, and using both as an average result.
Three different forms of computing the central embedding were proposed: (a) using the sentences (CE-S), (b) using the documents (CE-D) and (c) using the document set (CE-Set). In Tables 2, 3 and 4 ROUGE-1, ROUGE-2 and F-score for the experiments are shown.
Table 2 Recall for CE-S experiment
| Gold-standard summary set | ROUGE-1 | ROUGE-2 | F-score |
|---|---|---|---|
| A | 0.3808 | 0.1087 | 0.3740 |
| B | 0.3671 | 0.0932 | 0.3605 |
| A and B | 0.3740 | 0.1010 | 0.3673 |
Table 3 Recall for CE-D experiment
| Gold-standard summary set | ROUGE-1 | ROUGE-2 | F-score |
|---|---|---|---|
| A | 0.4371 | 0.1906 | 0.4495 |
| B | 0.4336 | 0.1873 | 0.4454 |
| A and B | 0.4353 | 0.1889 | 0.4474 |
Table 4 Recall for CE-Set experiment
| Gold-standard summary set | ROUGE-1 | ROUGE-2 | F-score |
|---|---|---|---|
| A | 0.4233 | 0.1791 | 0.4365 |
| B | 0.4119 | 0.1633 | 0.4239 |
| A and B | 0.4176 | 0.1712 | 0.4302 |
Our calculated embeddings for the DUC 2002 dataset, as well as the different Central Embeddings are available online12
4.1 Case Study of a Document Set
The main hypothesis of this proposal is that a central embedding should contain the main idea of a document and therefore, the sentence embeddings close to this central embedding contain important ideas because of their similarity. We will examine a particular document set, composed of 6 documents

Fig. 7 Gold standard summaries from DUC 2002 (document set d061j) (a) legend; (b) Gold Standard A and; (c) Gold Standard B
Generated summaries of our system on this set of documents are shown in Figure 8. The first strategy (CE-S) includes several sentences (7, 10, 11, 12) that are not clearly identified under the three previously mentioned main subjects; few sentences are included on the damage report.

The second strategy (CE-D, Figure 8(b)) gives the best balance on the three subjects mentioned.
The third strategy (CE-Set, Figure 8(c)) lacks information on the route description. Although more descriptive sentences are obtained with the CE-S experiment, the best performance was obtained in the CE-D experiment because in CE-S the sentence descriptions are not related with route and origin of the hurricane.
The effect of locating the central embedding with different strategies can be observed in Figure 9. These plots were created using the Radviz library13, which allows to project the 300-dimension embeddings into a 2D plot for visualization purposes. Circle markers indicate the document set sentences; triangle markers indicate the selected sentences; square markers indicate the location of the central embedding; cross markers indicate the central embeddings for the A gold standard, while star markers indicate the central embeddings for the B gold standard.

Fig. 9 Visualization of the different forms of computing central embeddings for the d061j document set: (a) CE calculated using the sentences (CE-S); (b) CE calculated using the documents (CE-D) and; (c) CE using the document set (CE-Set)
In Figure 9(a) the central embedding is located in the center of the selected sentences and very close to gold-standard central embeddings, but the sentences are short and do not contain relevant topics; this summary only selects one sentence from each gold-standard. In Figure 9(b) the central embedding seems far from the gold-standard central embeddings but contains more information from damage reports; it has two sentences in common with the gold-standard summaries.
In Figure 9(c) the central embedding is far from the gold-standard central embeddings, but is close to the central embedding of the previous experiment containing sentences with the damage report. It has five sentences in common with the previous experiment and two sentences in common with the gold-standard summaries.
5 Conclusions
In this paper we addressed the multi-document summarization task using a word embedding model that represents sentences as vectors which contain syntactic and semantic information.
Different variants to calculate central embeddings have been described. Specifically, three different ways of calculating averages were proposed: (1) using the sentences, (2) using the documents and (3) using the document set. Their foundations rely on the centroid-based method, which indicates that sentences containing words from the centroid are more indicative of the document topic. We found that using the documents for calculating the averages yielded better results when evaluated on the DUC 2002 corpus.
Our method obtains similar performance to LSA methods with the advantages that sentence embeddings do not have the course of dimensionality of the matrices and are independent of the document type and language. This implies that sentence embeddings obtain semantic information useful for summaries and the results could be improved if different main ideas can be found in sentence groups, for example, sentences with a predominant description of the origin and route of the hurricane.
The advantages of this method are: it does not need any linguistic resource, it is easy to implement and has a similar performance to the state of the art. Also, our method is unsupervised, thus it can be adapted to other summarization corpora and language without the need of adjusting parameters, or estimating optimization goals.
In future work, we plan to evaluate the results with clustering algorithms in order to obtain different groups of main ideas in order to capture the balance of topics observed in gold-standard summaries. Also, testing our method on different corpora to evaluate its performance is left as future work.

