











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
Knowledge of lexical co-occurrence and of lexical relation accounts for the extent to which the choice of a word in a text is stipulated by its surrounding words without taking into account syntactic and/or semantic reasons 39. Such knowledge is very important in many tasks of natural language processing: text analysis and generation, knowledge extraction, opinion mining, text summarization, question answering, machine translation, polarity identification, information retrieval, among others.
For instance, in the text generation task, one is interested in construction of not only grammatically correct utterances but also of those that sound natural. In order to achieve this, the system must know restrictions on usage of a particular word, that is, its combinability with other words in an utterance, or its collocational preferences.
Basically, word combinations can be divided into two big classes depending on word collocational choices. These two classes are free word combinations and restricted word combinations, also termed collocations.
Usually, collocations are defined as characteristic and frequently recurrent combinations 10,11 of (commonly) two linguistic elements which have a direct syntactic relationship 40 but whose co-occurrence in texts cannot be explained only by grammatical rules 7
One of the elements of a collocation is called a base or node and is autosemantic, that is, it can be interpreted even if it is not in the context of the collocation 13,14. The other element called collocator or collocate is semantically dependent on the base, has a more opaque meaning, and can only be interpreted with reference to the collocation, that is, it is synsemantic 14.
2. Strategies of Measuring Word Co-occurrence for Collocation Detection
In natural language processing research, there have been developed basically three strategies for automatic learning restrictions on word usage: statistical, rule-based, and hybrid strategies. Generally speaking, a computer system is expected to analyze a machine-readable text or a corpus defined as a collection of machine readable texts. The system must be able to extract combinations in which words are syntactically related and determine to what extent the appearance of one word in a phrase depends on the occurrence of another word or words. Such feature is called cohesion or association.
Within the statistical strategy, which is most common in language processing and lexical co-occurrence research, in order to calculate a measure of word association within collocations, a formal model of word co-occurrence should be designed or selected from the existing statistical models.
An important advantage of statistical models is that they use raw corpora where a selected language unit (word, type or lemma, phrase, sentence, document) is viewed as a data item. Statistical modeling is attractive since conclusions are derived out of data in a way that seems much more objective in comparison with linguistic interpretations and theories based on introspection and intuition of experts in linguistics. Moreover, statistical analysis in general is language- independent.
However, statistical methods work under certain assumptions, for instance, that data items “obey” certain well-studied distributions: normal, binomial, χ2, or other distributions. We do not know actually how real life linguistic data is distributed, but in any case, our mathematical constructs can be justified by the golden principle of pragmatics: it works therefore it is true. Another problem of statistical methods is that they require large corpora, otherwise estimations of frequencies and probabilities of word co-occurrences become imprecise and untrustworthy. Besides, if a collocation has a very low frequency of occurrence, it can hardly be detected.
In order to combat the above mentioned problems associated with the statistical methods, the rule-based strategy was put forward. Methods developed within this trend allow detecting low frequency phrases and do not rely on a very large collection of data.
On the other hand, rule-based techniques usually depend on language and lack flexibility. The latter characteristic harms the detection of those collocations which permit syntactic variation. Also, making hand-crafted rules is time consuming. Moreover, such rules have limited coverage and will hardly discover new collocations appearing in language.
In an effort to overcome the disadvantages of both strategies mentioned above and to take advantage of positive aspects of the same strategies, the hybrid methods have been proposed. Such methods use rules to extract candidate phrases and then apply statistical methods to improve the obtained results.
In this paper, we consider in detail the three strategies-statistical, rule-based, hybrid-on the task of detection of collocations. Reviewing each strategy, we describe various methods developed in state of the art works within the strategy, discuss their degree of effectiveness, and give examples.
3 Statistical Strategy to Measure Word Co-occurrence
Within the statistical methodology, candidate word combinations are identified based on calculation of a predetermined association measure in n-grams extracted from a corpus. Usually, n-grams are word combinations of a chosen syntactic pattern, e.g., adjective+noun or verb+preposition depending on the preferred structural type. In order to do this, the chosen corpus is lemmatized; words are tagged with their respective parts of speech (POS-tagged). Also, the corpus can be parsed. Evidently, this preprocessing is language-dependent. Another feature used for n-grams extraction is window size, typically from 1 to 5 words.
After 𝑛-grams are extracted, the association strength between their constituents is computed according to some statistical metric. As we have mentioned previously, such metrics used in the process of extracting word combinations are termed word co-occurrence measures or association measures because they compute the degree of association between the components in a phrase.
In this section we consider the association measures used to detect two-word collocations, i.e., bigrams, which is a very common case. Besides, the association measures for bigrams can be extended to combinations of three or more words.
Pecina 25 gives a comprehensive list of 82 association measures used to detect two-word collocations. To calculate the association measures, it is common to take into account frequencies of occurrence of each word in a bigram xy (a sequence of two words, the word x and the word y), the frequency of the bigram, its immediate context, and its empirical context.
The words x and y are viewed as types or lexical items, i.e., words as they are encountered in a lexicon. Their realizations are various grammatical forms found in a text. Commonly, frequencies are estimated for types, and we view frequencies here in this manner. However, the theory termed lexical priming states that word associations are characteristic of different forms of lexical items, so a particular wordform may have its own collocations typical for it and not typical for another form of the same lexical item 16. Therefore, lexical priming aims at a more fine-grained classification of word associations which is its strong side. On the other hand, such approach increases the complexity of analysis, since lexical items may have a very big number of grammatical forms. Also, frequencies of each wordform may be not high enough and thus not sufficient for statistical tests to work accurately, as the total frequency of a type is distributed through the whole range of its numerous forms thus obtaining low frequencies for each form of the type.
Speaking about the context of a bigram xy, we mentioned above that in calculating association measures the immediate and empirical contexts are used 26. The immediate context of a bigram is word(s) immediately preceding or following the bigram. The empirical context of a word sequence is open class words occurring within a specified context window. Open class words include nouns, verbs, adjective, and adverbs.
Figure 1 gives an example of the immediate and empirical contexts of the Czech bigram černý trh (black market) from 25. In this example, the left immediate context includes one word, and the empirical context contains all words of the utterance where the given bigram is used taken without this bigram.

Fig. 1 Example of a left immediate context (top) and empirical context (bottom) of the collocation černý trh (black market)
In the formulas of association measures which we discuss in detail in what follows, the notation from the contingency table is used. The term contingency table was first used by Karl Pearson in 1904, and such table is a certain manner of considering the occurrence of two words symbolized as x and y.
The contingency table presented in Table 1 contains observed frequencies for a bigram 𝑥𝑦. In this table, the following notation is used: 𝑓 𝑥𝑦 is the frequency or the number of occurrences of the bigram 𝑥𝑦 in a corpus; 𝑥 stands for any word except x, 𝑦 stands for any word except y, ( stands for any word; N is a total number of bigrams in a corpus.
Table 1 Contingency table of co-occurrence frequencies of a bigram xy and its constituent words x and y
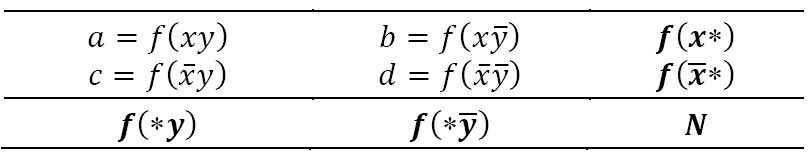
In fact, N can be interpreted differently depending on the task of the application being developed or on the objective of research, so generally speaking, N is the number of language units in the corpus chosen for consideration. Such language units can be tokens, types, n-grams of tokens or types, sentences, documents, etc. The choice of a language unit depends on the granularity of semantic analysis. In this article, we interpret N as the total number of bigrams in a corpus.
The bigrams are obtained following the paths in trees of syntactic dependencies or constituents resulting from parsing, so the words in a bigram are syntactically related. This procedure filters out irrelevant combinations of words which do not comprise a phrase with meaningful sematic interpretation.
Frequencies
In formulas, the contingency table cells are sometimes referred to as
In the contingency table, the following holds:
In some formulas of association measures, the concept of probability is used. The probability of finding a word x in a corpus
where
Also, in the formulas of some association measures, the context is represented by the following notation:
We remind the reader that some examples of the immediate and empirical context are given in Figure 1.
4 Typology of Statistical Association Measures
Evert 8 proposes a comprehensive classification of statistical association measures. They can be calculated using the UCS toolkit, software written in Perl of the same author (available at http://www.stefan-evert.de/Software.html). Evert defined the four approaches within the statistical strategy, and within each approach, a number of types of association measures. The classification is as follows:
Approach 1. The methods within the first approach measure the significance of association between the words 𝑥 and 𝑦 in a bigram xy. They quantify the amount of evidence that the observed bigram 𝑥𝑦 provides against a null hypotheses of independence of the words 𝑥 and 𝑦 in this bigram, i.e.,
-Likelihood measures which compute the probability of the observed contingency table (multinomial-likelihood, binomial-likelihood, Poisson-likelihood, the Poisson-Stirling approximation, and hypergeometric-likelihood);
-Exact statistical hypothesis tests which compute the significance of the observed data (binomial test, Poisson test, Fisher’s exact test);
-Asymptotic statistical hypothesis tests used to compute a test statistic (z-score, Yates’ continuity correction, t-score which compares the observed co-occurrence frequency 𝑓(𝑥𝑦) and the expected co-occurrence frequency
Approach 2. The methods within the second approach measure the degree of association of the words x and y in a bigram xy by estimating one of the coefficients of association strength from the observed data. This class includes measures of two types:
-Point estimates, usually, maximum-likelihood estimates (mutual information, odds ratio, relative risk, Liddell’s difference of proportions, minimum sensitivity, geometric mean coefficient, Dice coefficient or mutual expectation, Jaccard coefficient);
-Conservative estimates based on confidence intervals obtained from a hypothesis test (a confidence-interval estimate for mutual information).
Approach 3. The techniques within the third approach measure the association strength of the words x and y in a bigram xy or, in other words, the non-homogeneity of the observed contingency table compared to the contingency table of expected frequencies. These methods take advantage of the concepts of entropy, cross-entropy, and mutual information borrowed from the information theory (pointwise mutual information, local mutual information, average mutual information).
Approach 4. The methods in the fourth approach use various heuristics to evaluate the degree of association between the components of a bigram xy. Usually, such methods apply modified versions of measures from the other three approaches or combine such measures (co-occurrence frequency, variants of mutual information, random selection).
Now using the notation given previously, in the following sections we consider various association measures used for automatic detection of collocations in natural language texts. In each section we indicate the approach to which the considered association measures belong, so we grouped these measures by their types following the typology presented above.
We did not put the methods in the numeric order of the approaches, rather we ordered them using the criterion of complexity. First we describe some simple methods to estimate the association of words in a bigram xy, then we proceed to more complex formulas and techniques.
5 Simple Frequency-based Association Measures
In this section we discuss some simple measures, belonging to Approach 4, based on word frequency and probability used to detect collocations in a corpus.
In the simplest case, taking advantage of such property of collocations as recurrency (i.e., frequent usage in texts), we can count the number of occurrences of a bigram xy and estimate their joint probability P(xy):
If the bigram is used frequently, than it is probable that the two words are used together not by chance but comprise a collocation.
Also, to detect collocations, raw frequency of a bigram can be used instead of its probability. An example of this approach is the work of Shin and Nation 38 which presents most frequent collocations found by the authors in the spoken section of the British National Corpus (BNC). The article includes a list of 100 collocations ranked by their frequency in the BNC and in Table 2 we reproduce the upper part of this list which includes the most frequent word combinations.

The number of the bigram occurrences represented as the joint probability of two words occurring together
A drawback of using the joint probability
An example of the conditional probabilities approach is the works of Michelbacher, Evert, and
Schütze 20,21 where
The value of the conditional probability
6. Information-Theoretic Measures
The association measures in this section belong to Approach 3 and are based on such concepts as mutual information and entropy. These metrics measure the mutual dependency between two words x and y which are constituents of a bigram xy.
6.1 Mutual Information (MI)
MI is a well-known information-theoretic notion used to judge about dependence of two random variables. Its application as an association measure for collocation extraction was suggested by Church and Hanks 6. MI is an estimation of how much one word x tells about the other word 𝑦 and it is computed according to the formula
where the probabilities are calculated using data from the contingency table (see Table 1). We remind the reader that P(xy) is the joint probability of x and y co-occurrence:
and P(x) and P(y) are individual, or marginal, probabilities of x and y, respectively:
As it is seen from the formula for MI, the collocation hypothesis is expressed as the probability P(xy) actually observed in a corpus, and the null hypothesis suggests that x and 𝑦 are independent, i.e. constitute a free word combination, therefore, the probability of co-occurrence P(xy) has the property
If MI = 0, the null hypothesis is proved, if
Strictly speaking, the metric we have just considered is pointwise mutual information. But in the NLP literature it is referred to as simply mutual information according to the tradition started in 6, since we are interested not in mutual information of two random variables over their distribution, but rather in mutual information between two particular points.
Pecina and Schlesinger compared the effectiveness of 82 association measures given in their article 26 and demonstrated experimentally that pointwise mutual information works as the best association measure to identify collocations. However, this metric becomes problematic when data is sparse; it is also not accurate for low-frequency word combinations.
Two versions of mutual information are also applied to estimate the association strength of the words x and y in a bigram xy, these are average mutual information calculated according to the formula
and local mutual information for a given bigram 𝑥𝑦 which is estimated as follows:
In these formulas
6.2 Evaluation
Upon obtaining a list of collocation candidates, evaluation of the list must be done to check what candidate phrases are true collocations.
Evaluation can be manual or automatic. Results are presented in terms of conventional precision and recall. Given a finite set of word combinations, precision P is the number of word combinations correctly identified as collocations by the method under evaluation compared to all word combinations identified as collocations by the method; recall R is the same number of correctly identified collocations compared to all collocations in the dataset:
Manual evaluation is fulfilled using three methods. The retrieved list of candidates is ordered and the first n-best candidates (with highest values of association measure applied in the extraction process) can be
-. checked by a native speaker who has sufficient training in linguistics or by a professional lexicographer;
-. compared against a dictionary, however, the evaluation results will depend on quality and coverage of the dictionary;
-. evaluated using a hand-made gold standard (a list of collocations manually identified in a corpus).
Although manual evaluation is very accurate, it suffers certain limitations. If collocation candidates are evaluated by human experts, they may have disagreements on the status of some expressions. This is due to a lack of formality in the definitions of collocations as well as to the nature of this linguistic phenomenon since there are no clear-cut boundaries among various types of collocations and between collocations and free word combinations.
On the other hand, when evaluation is performed against a dictionary, the scope of work is restricted by the inventory of phrases in the selected dictionary. However, when collocations are extracted from very large corpora, the list of candidates is much bigger than the expressions found in the dictionary, therefore, a good portion of true collocations might be lost in the evaluation process.
Concerning a hand-made golden standard, the limit is time and financial resources because manual work is always costly in both senses. A very serious limitation of manual evaluation is the impossibility to estimate recall for very large lists of collocations candidates. It may seem that the problem can be solved with the data size reduction (to 50-200 samples), but association measures do not work well on small datasets.
To overcome the drawbacks of manual evaluation, automatic evaluation methods have been proposed. A well-known and widely used method was developed by Evert and Krenn (9). Instead of manually annotating only a small (in the sense of automatic language processing) number of n-best collocation candidates, Evert and Krenn suggested to compute precision and recall for several n-best samples of an arbitrary size comparing them against a golden standard of about 100 collocations (true positives, TPs). Then, in this case, precision is the proportion of TPs in the n-best list, and recall is the proportion of TPs in the base data that are also contained in the n-best list, the base data being an unordered list of all extracted collocation candidates.
7 Likelihood Measures
The association measures in this section belong to the first approach.
7.1 Log-Likelihood Ratio
The alternative terms for this measure found in literature are G-test and maximum likelihood statistical significant test. Log-likelihood ratio is computed with the formula
Similar to the formula of average mutual information given in the previous subsection,
where 𝑑𝑎𝑡𝑎𝐼𝑡𝑒𝑚 is either x, y,
Another option is to determine the squared log likelihood ratio according to the following formula:
7.2 Multinomial Likelihood
This measure termed multinomial likelihood (ML) estimates the probability of the observed contingency table point hypothesis assuming the multinomial sampling distribution:
ML =
7.3 Hypergeometric Likelihood
Another version is the hypergeometric likelihood (HL) computed under the general null hypothesis of independence
where
7.4 Binomial Likelihood
Under the assumption of the binomial distribution, we can compute the total probability of all contingency tables for
7.5 Poisson Likelihood
If we replace the binomial distribution with the Poisson distribution, this will increase the computational efficiency and will provide results with a higher accuracy. In this case, the corresponding association measure is called Poisson likelihood (PL) and is calculated as follows:
7.6 Poisson-Stirling Approximation
This is another association measure calculated under the assumption of the Poisson distribution. If we take the negative logarithm of the Poisson likelihood and approximate the factorial
8 Exact Statistical Hypothesis Tests
The association measures belonging to Approach 1 and estimated using the concept of likelihood as in the previous sections may suffer from very small values of probabilities which may be obtained in some cases. However, one can provide evidence concerning the independent occurrence of the words x and y in a bigram xy using what is called exact or strict hypothesis tests. These tests evaluate the probability of the null hypothesis
For the binomial distribution, the following metric is used:
For the Poisson distribution, the following metric is used:
Another exact test can be developed using the hypergeometric likelihood function, this gives what is called the Fisher’s exact test:
where
9. Asymptotic Statistical Hypothesis Tests
The methods in this group belong to Approach 1, they operate under the assumption of the normal distribution. The asymptotic theory is also called the large sample theory, and of course, natural language corpora are very large samples of linguistic data. Different from statistic tests of other groups which work on a finite data sample of size N, the asymptotic tests assume that that the sample size grows infinitely and estimate test statistics for
9.1 z-score
This is the simplest test statistic in this group of association measures. It is a simplification of computing the binomial measure approximating the discrete binomial distribution with the continuous normal distribution. Figure 2 borrowed from 8 shows how this approximation works.
The z-score is computed with the formula
9.2 Yates’ Continuity Correction
The Yate’s function is applied to the normal approximation to the binomial distribution. This correction is made to adjust observed frequencies towards the expected frequencies thus obtaining the corrected frequencies
Figure 3 shows that Yates’ continuity correction is a closer approximation to the binomial distribution, compare it with the Figure 2.


9.3 𝐭-score
This metric, also called the Student’s t-test, compares the observed co-occurrence frequency
This test estimates whether the means of two groups of data are statistically different. Applying it to measuring the association of words in a bigram xy, one thus compares the observed and expected frequencies. The above formula corresponding to the t-test measure is a ratio. The numerator is the difference between the observed and expected frequencies, and the denominator includes a measure of the variability of the observed frequency. The t-test requires the normal approximation and assumes that the mean and variance of the distribution are independent.
9.4 Pearson’s χ2 Test
The standard test for the independence of the rows and the columns in the contingency table is Pearson’s test. It is a two-sided association measure computed according to the formula
Another version of this test is based on the null hypothesis of homogeneity and is estimated according to the following formula:
9.5 Dunning’s Log-Likelihood
This test is a likelihood ratio test, and its metric LD is computed according to the formula
where
As it can be seen from the formula, this test compares the likelihood of two hypotheses about the words in a bigram 𝑥𝑦, the first hypothesis is
In order to estimate the statistical significance of the calculated metric, it is multiplied by -2, and then one has to consult the χ2 table at the degree of freedom equal to one.
10 Coefficients of Association Strength
The methods in this section belong to Approach 2. The techniques within this approach measure the degree of association between the words x and y in a bigram xy by estimating one of the coefficients of association strength from the observed data.
10.1 Odds Ratio
Odds ratio is the ratio of two probabilities, that is, the probability that a given event occurs and the probability that this event does not occur. This ratio is calculated as
The odds ratio is sometimes called the cross-product ratio because the numerator is based on multiplying the value in cell
10.2 Relative Risk
This measure estimates the strength of association of the words x and y in a bigram xy according to the formula
where
Relative risk is also called risk ratio because, in medical terms, it is the ratio of the risk of having a disease if exposed to it divided by the risk of having a disease being unexposed to it.
This ratio of probabilities can also be used in measuring the relation between the probability of a bigram xy being a collocation versus the probability of this bigram to be a free word combination.
10.3 Liddell’s Difference of Proportions
This measure (LDP) is the maximum likelihood estimation for the difference of proportions and is calculated according to the formula
This metric has been applied to text statistics in 19, where one can find a detailed discussion of its advantages compared to the conditional exact test without randomization.
10.4 Minimum Sensitivity
Minimum sensitivity (MS) is an effective measure of association of the words x and y in a bigram xy and has been used successfully in the collocation extraction task. This metric is calculated according to the formula
In fact, what this measure does is comparing two conditional probabilities
However, 12 suggests that MS has not to be trusted without a proper consideration in spite of its good performance. The reason is that the value of this metric does not specify what association is taken into account, i.e., the association between x and 𝑦 or the association between y and x. The author gives an example of the collocation because of and states that if the value MS = 0.2 is obtained, this number does not reveal whether the 0.2 is
10.5 Geometric Mean Coefficient
This association measure is calculated according to the formula
Or
The geometric mean is similar to the arithmetic mean, however, they are different in the operation over which the average value is calculated. The arithmetic mean is applied when several numbers are added together to produce a total value. The arithmetic mean estimates the value that each of the summed quantities must have to produce the same total. That is, if all the summands had the same value, what this value would be to give the same total. Analogously, the geometric mean is applied to multiplication of several factors, and it estimates the value that each of the factors must have (the same value for all the factors) to produce the same value of the product.
Applied to the contingency table (see Table 1), the geometric mean is equal to the square root of the heuristic MI2 measure defined by the following formula:
Therefore, the geometric mean increases the influence of the co-occurrence frequency in the numerator and avoids the overestimation for low-frequency bigrams.
10.6 Dice Coefficient
This association measure (D) is calculated according to the formula
This coefficient is one of the most common association measures used to detect collocations; moreover, its performance happens to be higher than the performance of other association measures.
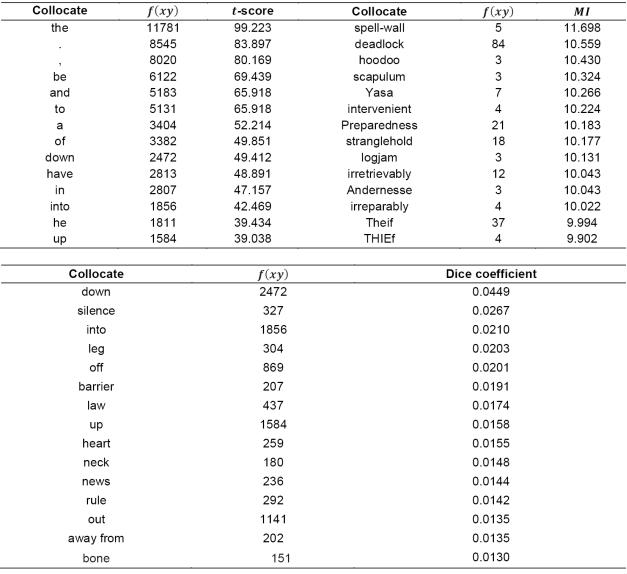
For example, Rychlý 37 experimented with various association measures including t-score, MI, MI3 (defined as
The experiments showed that Dice coefficient outperformed the other association measures. Besides, collocations detected with Dice coefficient were relevant for a collocation dictionary. To show this, in Table 3 we reproduce the results of applying three measures, namely, t-score, MI, and Dice coefficient, to extract collocations of break in 37.
10.7 Jaccard Coefficient
The Jaccard coefficient (J) is monotonically related to the Dice coefficient and measures similarity in asymmetric information on binary and non-binary variables. It is commonly applied to measure similarity of two sets of data and is calculated as a ratio of the cardinality of the sets’ intersection divided by the cardinality of the sets’ union. It is also frequently used as a measure of association between two terms in information retrieval.
To estimate the relation between the words x and 𝑦 in a bigram xy, the Jaccard coefficient is defined by the following formula:
where the values of
The Jaccard coefficient as well as the Dice coefficient are often called normalized matching coefficients because the way to assess the similarity of two terms is to count the total number of each combination in a contingency table as presented in Table 1. Jaccard is similar to the cosine coefficient (cos) defined by the following formula:
where the values of
10.8 Confidence-Interval Estimate for Mutual Information
Point estimates of association between words in a phrase operate well for words which have sufficiently high frequency, however, these metrics are not reliable when words or word combinations have few occurrences in a corpus. This fact results in a low performance of point estimates, for example, of mutual information, as shown in 9. This issue can be resolved by using interval estimates from exact hypothesis tests which correct for random variation and evade overestimation.
The confidence-interval estimate for mutual information (MIconf) is defined as
11 Rule-Based and Hybrid Strategies to Measure Word Co-occurrence
Statistical methodology requires large collections of data, otherwise estimations of frequencies and probabilities of word co-occurrences become imprecise and untrustworthy.
However, the Zipf’s Law asserts that the frequency of a word in a corpus is inversely proportional to its rank in the frequency table. Therefore, a great deal of words (from 40% to 60% of large corpora, according to 18) are hapax legomena, i.e., they are used only once in a corpus.
Low-frequency phenomenon also extends to collocations. Baldwin and Villavicencio 1 indicate that two-thirds of verb-particle constructions occur at most three times in the overall corpus.
An example of the rule-based method can be found in 17. The authors use candidate selection rules for key phrase extraction from scientific articles. Key phrases are simplex noun or noun phrases that represent the key ideas of the document. Examples of rules are presented in Table 4.

On the other hand, rule-based techniques usually depend on language and lack flexibility. The latter characteristic harms the extraction of collocations which permit syntactic variation.
Also, making hand-crafted rules is time consuming. Moreover, such rules have limited coverage and will hardly discover new restricted word combinations appearing in language.
To combat these disadvantages, hybrid methods have been proposed. The latter use rules to extract candidate restricted constructions and apply statistical methods to improve the obtained results.
For example, in 15, machine learning is used together with simple patterns to identify functional expressions in Japanese. Their experiments show that the hybrid method doubles the coverage of previous approaches to resolving this issue, at the same time preserving high values of precision.
12 Conclusions
In this article we presented a detailed survey of word co-occurrence measures used in natural language processing. Such measures are called association measures and they are applied to determine the degree of word cohesiveness in phrases. If the value of such measure is high in a given word combination, the latter is called collocation. Collocations are different from free word combinations, in which the degree of cohesiveness is low. It is important in natural language processing to determine which word combination is a collocation since they must be treated in a way different from phrases in which words combine freely.
We described the association measures grouping them in classes depending on approaches and mathematical models used to formalize word co-occurrence. The three approaches were presented: statistical, rule-based, and hybrid approaches. Most association measures belong to the statistical approach in which there are many types distinguished: frequency-based measures, information-theoretic measures, likelihood measures, statistical hypothesis tests (exact and asymptotic), and coefficients of association strength. The measures are described indicating their formulas, basic principles of their definition, their advantages and disadvantages.
In the last decade, the area of NLP has changed racially with the progress of deep learning. There is a number of directions to improve the co-occurrence measure for collocation detection, such as the use of concepts and common sense knowledge 27,32,35,36, as well as sentiment and emotion information in the text 29,33. In addition word2vec-like techniques can be used to improve the co-occurrence measure for collocation spotting. Word2vec is a vector-space language model learned using deep learning, which has shown good performance on text 2-4 and multimedia 28,30,31 analysis. Co-occurrence methods can be useful for personality detection34 and textual entailment-based techniques 22-24.

