











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1. Introducción
La llamada sociedad del conocimiento considera la apropiación crítica y selectiva de la información para el desarrollo del ser humano. La World Wide Web (WWW), por su naturaleza de reunión de información vinculada, se ha convertido en la principal fuente de información y desde su introducción en 1990 ha evolucionado para enriquecer la forma en que se organiza y se expone a los usuarios; que va desde un panorama de texto e hipertexto en sitios web planos hasta estándares de estructuración de metadatos e interoperabilidad de la llamada Web 3.0.
Esta masa de información que constituye la Web, en ocasiones se siente como "de una milla de ancho pero con una pulgada de profundidad" ¿Cómo poder construir una experiencia Web más integrada, consistente y profunda? 1. Es aquí donde se sitúa la semántica, como el proceso de comunicar la información con suficiente significado. Así es posible construir aplicaciones inteligentes que aporten un mayor conocimiento identificando en mayor profundidad los contenidos.
El ámbito académico no ha estado exento del impacto del crecimiento de la WWW. Encontrar información relevante para el aprendizaje, la ensenanza o la investigación en el volumen de recursos y publicaciones existentes se está convirtiendo en un reto importante para los estudiantes y científicos. Aunado a ello, compartir recursos, metadatos de los recursos y datos a través de la Web es un principio central en el contexto académico y de investigación. La colaboración científica por mucho tiempo ha luchado por reusar y compartir más ampliamente el conocimiento y los datos 2.
La educación, por su parte, ha sufrido importantes cambios propiciados por el desarrollo de las tecnologías que han modificado las formas de acceso y difusión de la información y los modos de comunicación entre los individuos, entre los individuos y las máquinas y entre las propias máquinas 3.
Los portales, plataformas y bases de datos de recursos académicos disponibles en la Web conforman una gran biblioteca dinámica y creciente; con múltiples y diversos puntos de consulta que imponen retos importantes en las tareas de búsqueda y recuperación de información relevante para un estudiante, docente o investigador.
En este sentido, resulta relevante el desarrollo de tecnologías que abonen en el descubrimiento de recursos de interés tomando en cuenta las necesidades de información y características del usuario.
En el presente documento se describen los resultados de la aplicación de un modelo que considera como insumos de un marco de trabajo de recuperación de información: recursos estructurados con el Protocolo para Cosecha de Metadatos de la Iniciativa de Archivos Abiertos (OAI-PMH), una representación ontológica y el contexto del usuario.
En un trabajo previo 4 se formularon las generalidades de un modelo preliminar que no había sido implementado, es decir que se encontraba en la fase de diseno. Posteriormente, con base en él, se desarrollaron los componentes de software, y acorde a los resultados obtenidos y problemas encontrados surge el enfoque mostrado en el presente trabajo. La implementación, resultados alcanzados, validación y retos enfrentados con este nuevo acercamiento son documentados a continuación.
2. Conceptos fundamentales
2.1. OAI-PMH
La variedad de recursos de información en la Web de utilidad para un alumno, académico, profesor o científico es muy amplia, abarca libros, artículos de revistas científicas, informes, actas de congreso, tesis, pre-prints, archivos de datos, entre otros. Todos ellos disponibles a través de portales especializados, repositorios y bases de datos que usan mecanismos de descripción y exposición de sus datos.
Para que este tipo de plataformas tengan la posibilidad de intercambiar información tienen que contar con reglas de comunicación y estándares de estructuración de datos. El protocolo de interoperabilidad OAI-PMH es uno de los más utilizados para este fin.
Según el Registro de Repositorios de Acceso Abierto 5 (ROAR, por sus siglas en inglés) existen poco más de 4,000 repositorios en el mundo que implementan el protocolo OAI-PMH. Para tener una mejor idea de la cantidad de archivos de contenido intelectual disponibles en Acceso Abierto se puede acceder al proveedor de servicio OAIster 6 que cosecha menos de la mitad de los repositorios registrados en ROAR y cuenta con más de 30 millones de registros disponibles a través de OAI-PMH.
El OAI-PMH surge con la Iniciativa de Archivos Abiertos, liberada en 1999, de la necesidad de convertir los archivos en interoperables y construir servicios de recuperación de información de diversos repositorios. Su naturaleza radica en la definición de una interfaz a través de la cual un repositorio expone públicamente en la web los metadatos de los objetos digitales que almacena.
El protocolo Z39.50 7 ya existía como un estándar que permitía la búsqueda federada a vários servidores de manera paralela. Sin embargo, se había presentado mucha dificultad para crear servicios de búsqueda federada de alta calidad a través de un gran número de servidores autónomos, por razones como: diferentes interpretaciones de las consultas, problemas de escalabilidad, dependencia de la disponibilidad de los servidores al momento de la consulta y rendimiento sujeto a la velocidad de respuesta del servidor más lento 8.
Es así, que el OAI-PMH se consolida como un estándar de la comunidad de archivos abiertos como resultado de las ventajas que ofrece en comparación con el Z39.50.
Este protocolo es un mecanismo de baja barrera para la interoperabilidad de repositorios 9. Define una interfaz que un servidor conectado a la red puede emplear para hacer disponible a aplicaciones externas los metadatos que describen objetos almacenados en ese servidor 8.
En el protocolo se especifican dos tipos de participantes, los proveedores de datos y los proveedores de servicio; los primeros, encargados de exponer públicamente los metadatos de su contenido y los segundos, a cargo de cosechar metadatos de los proveedores de datos para ofrecer interfaces de integración y búsqueda para el usuario final.
Hace uso de peticiones y respuestas HTTP para comunicarse entre un cosechador y un repositorio usando métodos GET o POST. Para la conformación de estas peticiones existe una URL base única que especifica el servidor y el puerto; y opcionalmente la ruta.
Dichas peticiones mejor conocidas como verbos son seis y se concatenan a la URL base. Los verbos se describen enseguida 10:
-GetRecord: regresa los metadatos de un registro individual.
-Identify: devuelve la información acerca del repositorio.
-ListRecords: es usado para cosechar los registros de un repositorio; argumentos adicionales permiten la cosecha selectiva basada en conjuntos o temporalidad.
-ListIdentifiers: es una forma abreviada de ListRecords que trae únicamente las cabeceras de los registros.
-ListMetadataFormats: regresa los formatos de metadatos disponibles en el repositorio.
-ListSets: recupera la estructura de conjuntos de un repositorio.
Las respuestas son serializadas en XML con los metadatos de Dublin Core (descritos posteriormente). El proceso de envío - recepción de peticiones y respuestas se controla a través del denominado proceso de cosecha de metadatos. Siendo un cosechador el programa que envía peticiones a un proveedor de datos y recibe como respuesta archivos XML con metadatos Dublin Core.
2.2. Dublin Core
La Iniciativa de Metadatos Dublin Core (DC) auspicia el desarrollo de estándares de interoperabilidad a diferentes niveles, entre los que se encuentra un conjunto de metadatos para descripciones simples y genéricas popularizado por ser parte de las especificaciones del protocolo OAI-PMH.
El llamado Dublin Core no calificado es el que originalmente se utiliza para describir recursos con OAI-PMH y contempla los siguientes 15 metadatos 10:
2.3. Sensibilidad al contexto
La característica de sensibilidad al contexto del usuario en servicios de recuperación de información se refiere a la capacidad de percibir información de su ambiente para otorgar resultados personalizados. Con ello es posible inferir situaciones no explicitadas y así manifestar un comportamiento inteligente.
Específicamente para el ámbito educativo muchas plataformas no toman en cuenta las diferentes necesidades del alumno y proveen la misma recuperación de información a todos los usuarios. Entonces, resulta pertinente como se menciona en 11 el uso de un modelo de estudiante para permitir la personalización efectiva de ambientes de aprendizaje.
2.4. Ontologías
Una ontología es una especificación explícita de una conceptualización 12.
Se considera conceptualización al modelado abstracto de algún fenómeno del mundo identificando sus conceptos relevantes. Es explícita dado que el tipo de conceptos usados y sus restricciones son definidos explícitamente. Es formal por el hecho de que debe ser legible para máquinas y es compartida ya que captura el conocimiento consensuado, es decir no es privativo de un individuo, sino aceptado por un grupo 12,13.
Las ontologías habilitan a una computadora para entender la información por sí misma 14.
Para la ciencia y la educación un insumo fundamental es la bibliografía así es que la representación ontológica de referencias bibliográficas ha sido objeto de diversos desarrollos. Entre ellos se encuentra FaBiO una ontología para registrar y publicar registros bibliográficos en la Web Semántica 15; CiTO, una ontología para citaciones bibliográficas 16; y BIRO, la ontología de referencias bibliográficas 17.
Estas y cinco ontologías más: PRO, la ontología de roles de publicación; PSO, la ontología de estado de la publicación; PWO, la ontología del flujo de trabajo de publicación; C4O, la ontología de caracterización del contexto y conteo de citación; y DoCo, la ontología de componentes del documento conforman el conjunto SPAR (Semantic Publishing and Referencing Ontologies) compuesto de módulos para crear metadatos RDF comprehensivos para todos los aspectos de la publicación y referencia semántica 18.
Por su parte, la Ontología Bibliográfica BIBO provee los conceptos y propiedades principales para describir citaciones y referencias bibliográficas 19.
En cuanto a Dublin Core se refiere, la DCMI también ha elaborado una ontología para describir el conjunto de términos para identificar objetos digitales 20.
Por otro lado se encuentra también FOAF, un proyecto devoto de vincular personas e información usando la Web 21. El espacio de nombres FOAF http://xmlns.com/foaf/0.1/ es usado para representar datos acerca de personas tales como, nombres, fechas de nacimiento y especialmente a la gente con la que se relacionan. Es particularmente útil para representar datos de redes sociales.
2.5. Marco de trabajo Jena
Jena, proyecto de código abierto iniciado por los Laboratorios HP en el 2000, es un marco de trabajo Java para la construcción de aplicaciones de la Web Semántica, provee bibliotecas Java para el desarrollo de código que maneje RDF, RDFS, RDFa, OWL y SPARQL alineado con las recomendaciones de la W3C 22.
Incluye un motor de inferencia basado en reglas para desempenar razonamiento basado en ontologías OWL y RDFS y una variedad de estrategias de almacenamiento para tripletas RDF en memoria o en disco.
La API ontológica de Jena provee una interfaz de programación consistente para el desarrollo de aplicaciones ontológicas, independiente del lenguaje. Fue seleccionado para la implementación de este enfoque dada su solidez y robustez para el desarrollo de aplicaciones de la Web Semántica.
3. Descripción de la propuesta
El alcance del enfoque propuesto se restringe al uso de recursos estructurados bajo el protocolo OAI-PMH, es decir, los datos estructurados en otros formatos o bajo otros protocolos no son considerados en este modelo.
La parte central constituye un motor de recuperación de información sobre ese conjunto de datos.
3.1. Metodologia
En la Figura 1 se puede observar el diagrama de flujo del proceso llevado para la implementación de la propuesta.

Se aprecia que la información requerida de entrada desde uma interfaz de usuario corresponde a la consulta así como la información contextual del usuario.
Dicha información ingresa al motor de recuperación donde circula por un razonador basado en reglas que procesa la consulta sobre una base de datos de tripletas haciendo uso del API de ontologías de Jena.
El proceso de consulta es en tiempo real sobre datos colectados previamente en un procesamiento por lotes, dando como resultado un conjunto de inferencias correspondientes a recursos de información.
Los pasos seguidos y componentes de software desarrollados se detallan en los apartados siguientes.
3.2. Cosecha de metadatos OAI-PMH
Se desarrolló una aplicación Java que realiza peticiones HTTP a los proveedores de datos haciendo uso del verbo ListRecords del OAI-PMH. Con ello, se obtienen archivos en formato XML con los datos descritos en el conjunto simple de metadatos de Dublin Core. Dentro de estos archivos XML se encuentran registros (<record>). El número de registros por archivo depende de la configuración de cada repositorio cosechado y estos pueden variar desde 1 hasta n.
3.3. Transformación a RDF
Muchas instituciones dan acceso a sus repositorios de metadatos a través de OAI-PMH pero no hacen que sus recursos sean accesibles a través de URIs desreferenciables, cosa que provoca restricciones de significado y hace que quede restringido el acceso a los metadatos 23. Por esta razón, es necesario hacer uso de un convertidor a RDF con la intención de transformar los metadatos contenidos en un repositorio OAI-PMH a RDF.
Se han desarrollado diversos proyectos que permiten explotar datos estructurados y dotarlos de características propias de aplicaciones semánticas, como lo es OAI2LOD Server un desarrollo para exponer metadatos OAI-PMH como Linked Data 24. Dentro de este tipo de proyectos wrapper también se puede encontrar D2R 25.
Para este trabajo se probó un desarrollo enmarcado en los llamados RDFizers, software de conversión a RDF llamado OAI2RDF como un componente en la arquitectura 26. La herramienta realiza esta tarea con una transformación lógica que se hace a través de hojas XSLT que se invocan una vez que los datos han sido entregados.
Sin embargo, se optó por desarrollar una aplicación de software para realizar esta tarea dado que esto permitía una mejor integración del proceso de cosecha con el resto de la implementación.
Esta aplicación se encarga de leer los metadatos de los archivos XML obtenidos de la cosecha OAI-PMH utilizando el API SaxBuilder que permite recuperar los registros convirtiéndolos en objetos. Enseguida se muestra un ejemplo de registro contenido en un XML de entrada.

Posteriormente, se creó un modelo en Jena a partir de listas de los objetos recuperados y se definió un esquema compatible con el estándar Dublin Core para generar un archivo RDF/XML.
Los datos del autor son enriquecidos para agregar relaciones de coautoría y más datos acerca del autor. Estos metadatos pueden extenderse en tanto los conjuntos de datos usados como fuente contengan información sobre los autores y son expresados con FOAF, de la siguiente forma:

Un ejemplo de salida es el que se muestra a continuación.

3.4. Modelo Ontológico y validación
El componente ontológico integra dos ontologías una de ellas Dublin Core, dado que los recursos que alimentan la base de conocimiento están estructurados con metadatos DC al estar bajo el estándar OAI-PMH.
El estándar Dublin Core original incluía el nivel simple y el calificado, el primero compuesto de 15 elementos y el cual se utiliza para descripción de recursos con OAI-PMH bajo el espacio de nombres http://purl.org/dc/elements/L1/. Sin embargo, para este trabajo se utiliza el espacio de nombres http://purl.org/dc/terms, la razón radica en que a partir del ano 2012 la DCMI (Dublin Core Metadata Initiative) incorpora los dos niveles en este espacio de nombres.
La segunda ontología es FOAF. La intención del uso de FOAF en este proyecto es explorar su adaptación para tratar la información sobre los autores de los artículos, libros y otros recursos académicos. Aunado a esto, se pueden incluso expresar sus relaciones sociales basadas en coautoría para poder determinar recursos relacionados.
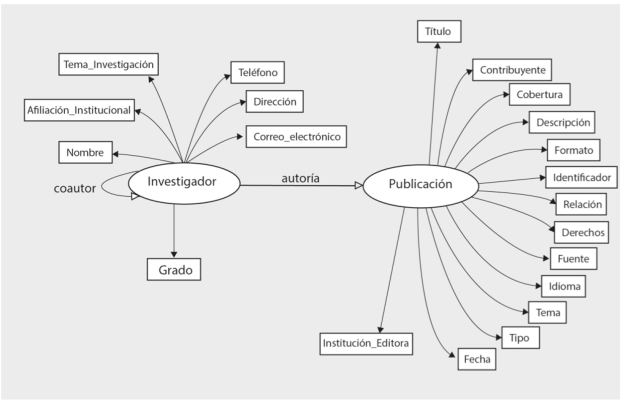
De este modo es posible modelar las propiedades de un recurso con su autor como en la Figura 2; donde por ejemplo, un investigador es un autor de una publicación (dc:creator) pero a la vez es una persona (foaf:person) con propiedades individuales. Asimismo están representadas por un lado la relación de autoría entre una publicación y un investigador; y la de coautoría de un investigador con otro u otros con los que escribe en conjunto una publicación (Figura 3).
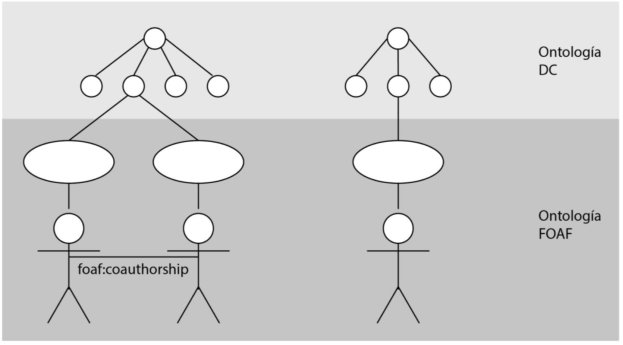
Por otro lado, es importante recordar que las ontologías son desarrolladas a diferentes niveles de abstracción por personas distintas y para diversos propósitos. El conocimiento representado por las ontologías se dispersa debido a la existencia de muchas ontologías representando los mismos conceptos, es así, que se vuelve difícil analizar, estudiar y usar el conocimiento propagado a través de múltiples ontologías si se estudian individualmente 27.
La técnica para combinar en una sola ontología el conocimiento representado en varias ontologías es la unión o merge. Con este Ontologia DC procedimiento se busca obtener una definición para expresar el conocimiento obtenido de las fuentes de información descritas, que favorezca su validación y análisis.
Con la ayuda de la herramienta Protégé 28 y su función de Refactor > Merge Ontologies se realizó la fusión de las dos ontologías de entrada.
Esta integración automática no resuelve las inconsistencias generadas después del proceso. Por ello, la ontología de salida fue sujeta a un refinamiento posterior siguiendo los pasos del algoritmo de merging propuesto en 27.
La jerarquía de clases de la ontología resultante se muestra en la Figura 4 con un total de 39 propiedades.
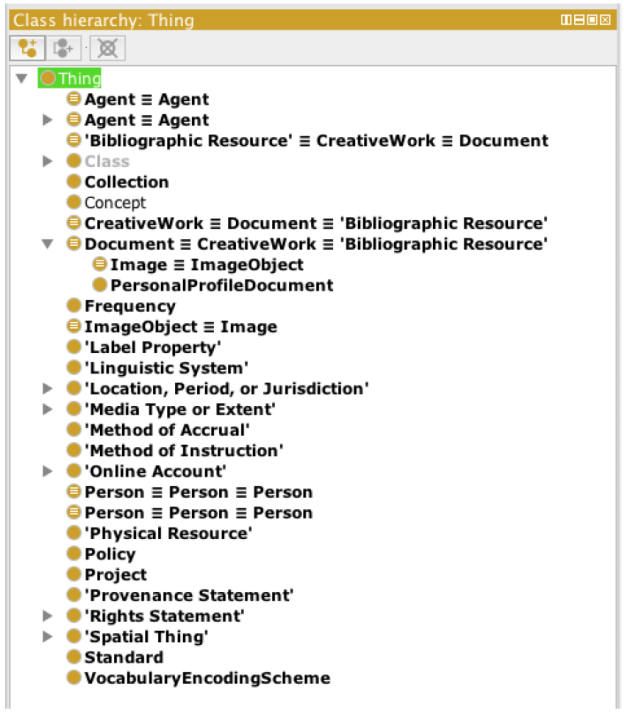
Como parte del refinamiento se identificaron equivalencias, por ejemplo con la clase BibliographicResource de DC de la cual se hizo explícita su equivalencia a Document de FOAF que a su vez ya era equivalente a CreativeWork (Figura 5).

De la misma forma, también se establecieron otras equivalencias, entre ellas el caso de Creator (http://purl.org/dc/terms/creator) de Dublin Core com Maker (http://xmlns.com/foaf/0.1/maker) de FOAF.
3.5. Almacenamiento
El modelo contempla TDB del marco de trabajo de Jena. TDB es un componente para el almacenamiento y consulta RDF, soporta el rango completo de APIs de Jena y puede ser usado como un almacén de alto rendimiento para tripletas RDF.
3.6. Motor de recuperación de información
El motor de recuperación de información es una aplicación desarrollada en Jena haciendo uso de sus API de ontologías, razonamiento y almacenamiento. La arquitectura de sus componentes se muestra en la Figura 6.
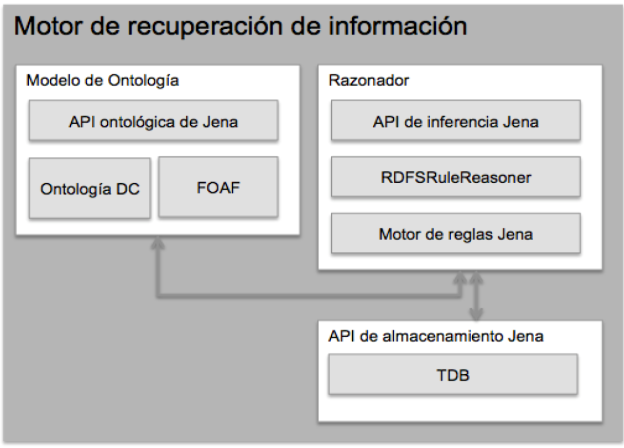
El subsistema de inferencia está disenado para derivar un conjunto de enunciados a partir de la base de datos de hechos proveniente de los procesos de cosecha y transformación de recursos OAI-PMH, la información de contexto del usuario e información ontológica.
El motor de inferencia de Jena es usado para derivar enunciados RDF adicionales de la base TDB. Con fines experimentales para este desarrollo se usó el razonador OWL incluido, una implementación basada en reglas de OWL/Lite.
Cabe destacar que la inferencia se realiza sobre las coincidencias en los valores de las tripletas. Un caso, por ejemplo, es la temática que aborda un recurso de información que en Dublin Core es modelado con dc:subject, es así que los registros que tienen el mismo valor en ese atributo tienen una asociación. El modelo no contempla, en este momento, encontrar dichas coincidencias en diferentes idiomas.
La interfaz de usuario debe proveer información de contexto expresado en un perfil del sujeto que lanza la consulta y que constituye un conjunto de características para representar circunstancias personales, profesionales, sociales o de espacio-tiempo como fecha y lugar en que se emite la consulta.
Dado que la información tratada en este trabajo es de corte académico - científico es pertinente aplicar el modelo para estudiantes.
Para este fin, se retomó el modelo de representación de estudiantes basado en ontologías para sistemas de tutoría inteligente de aprendizaje a distancia propuesto en 29. Dicho modelo permite representar a un estudiante con cuatro clases:
- Student, representa cualquier estudiante.
- StudentCourseInformation, comprende información relevante al proceso educativo como módulos del programa que cursa, escuela, tareas, exámenes, entre otros.
- StudentCurrentActivity, se refiere al detalle de la actividad académica del ano en curso.
- StudentPersonalInformation, es la información estática y permanente del estudiante.
3.7. Procesamiento de la información
3.7.1. Procesamiento en tiempo real
El proceso de consulta basada en un conjunto de parámetros que ingresan a un motor de inferencia para devolver un resultado, se realiza en tiempo real y comienza una vez que se recibe la información de entrada y concluye con el envío de resultados de salida. Es así, como este motor de recuperación de información utiliza los datos recolectados por el programa de cosecha que han sido transformados, enriquecidos y almacenados de manera centralizada con anterioridad.
3.7.2. Procesamiento por lotes
La naturaleza del funcionamiento del protocolo OAI-PMH obliga a recolectar los datos de los repositorios en procesos por lotes y en segundo plano por las siguientes razones:
a) El tiempo de cosecha de metadatos depende de los tiempos de respuesta de los repositorios individuales. Asimismo, el tiempo total de recolección de metadatos está sujeto al modo de operación del cosechador ya sea secuencial o paralelo para todos los repositorios que se deseen cosechar. Así, para el primer modo será la suma total de los tiempos de respuesta de todos los repositorios y para el modo paralelo dependerá del número de repositorios que estén siendo cosechados de manera simultánea y el tiempo de respuesta más lento de cada hilo de procesamiento.
b) La disponibilidad de los repositorios en el momento de los procesos de recolección de metadatos puede impedir que un repositorio sea localizado. Así, en un procesamiento por lotes, es posible realizar intentos de reconexión con el repositorio sin impactar el tiempo final.
4. Resultados
Con fines experimentales y de validación del modelo propuesto fueron elegidos dos repositorios que implementan OAI-PMH. Cabe resaltar que la única condición para que un repositorio sea compatible con este modelo es que implementen dicho protocolo. Los repositorios usados fueron: Redalyc.org, el portal de la Red de Revistas Científicas de América Latina, el Caribe, Espana y Portugal 30 y el repositorio institucional de la Universidad Roskilde llamado RUDAR (Roskilde University Digital Archive) de Dinamarca 31.
A continuación se describen los resultados obtenidos de seguir la metodología:
-
El proceso de cosecha de metadatos OAI-PMH recolectó de Redalyc.org 17,328 archivos XML conteniendo cada uno de ellos un máximo de 20 registros, que hicieron un total de 346,557 artículos científicos. La cosecha con RUDAR recuperet 121 archivos con un máximo de 100 registros cada uno, haciendo un total de 12,011 recursos entre artículos, tesis y más documentos (Tabla 1).
Los archivos XML fueron transformados a RDF/XML resultando en total 17,449 archivos.
Esos archivos resultantes fueron sujetos a la validación utilizando la ontología combinada.
Posteriormente, la información pasó al almacén en forma de tripletas, las cuales ascendieron a un total de 7,147,338.
Para ejemplificar la consulta se usó como entrada el perfil del siguiente alumno:


El objetivo es recuperar recursos académicos relevantes para el curso de "Sociologia".
Un recurso recuperado, entre otros, fue el correspondiente a un artículo científico titulado "Hacia una ontologia social del aprendizaje", escrito por "Jean Lave" y "Martin Packer" publicado en espanol en la revista "Revista de Estúdios Sociales" editada en la "Universidad de Los Andes" de Colombia en "2011" y cuya temática es "Sociologia". El resultado fue recuperado dada la coincidencia exacta con la temática (dc:subject) del artículo que es "Sociologia".
Otro recurso resultante corresponde a una tesis titulada "Education for Active Non-violence" de la autoria de "Uski, Juha Janne Olavi" publicado el "2008-01-17" y que trata de diversos temas, es decir cuenta con varios dc:subject, uno de ellos tiene como valor el texto: "Lave" que coincide con el atributo foaf:surname de la autora del artículo encontrado previamente. Es decir, esta tesis tiene como temática cuestiones relacionadas con la autora. Y aunque no contiene explicitamente la temática de "Sociologia" fue recuperada dada la relación derivada.
Las relaciones entre los recursos se muestran en el grafo de la figura 7, por motivos de visualización no se incluyeron todos los datos de cada recurso en el grafo.

En resumen, los hechos obtenidos de los metadatos OAI-PMH cosechados son, entre otros:
- El artículo "Hacia una ontologia social del aprendizaje" tiene una temática de "Sociologia" así que es relevante para el estudiante.
- El artículo "Hacia una ontologia social del aprendizaje" fue escrito en coautoria por "Jean Lave" y "Martin Packer".
- "Lave" es un tema (dc:subject) de la tesis de "Uski, Juha Janne Olavi".
Hecho derivado:
- La tesis de "Uski, Juha Janne Olavi" es relevante para el estudiante, ya que trata sobre una temática relacionada con una autora de un artículo que es relevante para el estudiante.
Así, es posible descubrir recursos relevantes para un usuario tomando en consideración la información de contexto a través de un perfil de usuario así como las relaciones obtenidas entre los recursos de información.
5. Trabajos relacionados
Respecto a proyectos cuyo objetivo gira en torno a la recuperación y descubrimiento de información se encuentra Sindice, el índice de la Web Semántica 32, es un proyecto patrocinado por el Digital Enterprise Research Institute (DERI) que provee un motor de búsqueda semántico de recursos marcados con RDF, microformatos, microdatos, RDFa, entre otros, indexados de la Web para exponerlos a través de una API para desarrolladores.
Freebase, una colección abierta de datos estructurados y plataforma para accederlos y manipularlos a través de una API que ha notificado su adición al proyecto Wikidata 33.
Por otro lado, hay trabajos en el campo del descubrimiento de recursos y recomendación como 34 o para ambientes de aprendizaje personales como 35 y sobre la información de Linked Data.
Todos estos proyectos si bien se enmarcan en la línea de motores semánticos no están especializados para recursos estructurados con OAI-PMH de ahí la diferencia con el modelo aquí presentado.
6. Conclusiones y trabajo futuro
El descubrimiento de recursos de información es un problema derivado del acelerado crecimiento de la Web que dificulta cada vez más la localización de información para un usuario; en lo correspondiente al ámbito educativo y de investigación es un reto importante para los estudiantes y científicos.
El enfoque presentado propone una metodología y un motor de recuperación de información basado en ontologías tomando en consideración la información de contexto a través de un perfil de usuario así como las relaciones obtenidas entre los recursos de información. Tal acercamiento permite descubrir recursos de interés personalizados a través de inferencia.
Este modelo podría extenderse para aprovechar las fuentes de información de Linked Data como insumo además de contenidos OAI-PMH, sin embargo, habría que plantear mecanismos de filtrado y selección de información académica o científica.
Adicionalmente, la propuesta puede ser enriquecida con el uso de vocabularios controlados como en 36 y/o el uso de ontologías multilingües como la desarrollada en 37 para recuperar información en diversos idiomas. Y es posible probar otros motores de inferencia como Pellet, Racer o FaCT para un completo razonamiento OWL DL.

