










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkAgrociencia
versión On-line ISSN 2521-9766versión impresa ISSN 1405-3195
Agrociencia vol.48 no.3 Texcoco abr./may. 2014
Matemáticas aplicadas, estadística y computación
Redes bayesianas aplicadas a un modelo CFD del entorno de un cultivo en invernadero
Bayesian networks applied in a CFD model of the crop in greenhouse
Guillermo de la Torre-Gea1,2*, Oscar Delfín-Santisteban1, Irineo Torres-Pacheco2, Genaro Soto-Zarazúa2, Ramón Guevara-González2, Enrique Rico-García2
1 CA Biosistemas. Universidad Tecnológica de Corregidora. Km 11.2 Carretera Santa Bárbara-Coroneo, Corregidora, Querétaro, México. * Autor responsable (gtorre@abanet.mx).
2 CA Ingeniería de Biosistemas. Universidad Autónoma de Querétaro. C.U. Cerro de las Campanas s/n, Colonia Las Campanas. 76010. Santiago de Querétaro, Querétaro, México
Recibido: agosto, 2013.
Aprobado: marzo, 2014.
Resumen
Los avances en sistemas y recursos informáticos permiten desarrollar modelos para simular el comportamiento de los fluidos en invernaderos. Sin embargo, la predicción de los gradientes de masa y energía, en los invernaderos con el cultivo y ventilación natural, es difícil por la naturaleza estocástica del viento y las relaciones de dependencia entre la temperatura, CO2 y humedad relativa. Existen técnicas heurísticas, como las Redes Bayesianas, que ayudan a conocer las relaciones entre las variables que no pueden determinarse con herramientas estadísticas. El objetivo del presente estudio fue determinar la temperatura, concentración de CO2 y humedad relativa con respecto a la altura del cultivo, en un invernadero con ventilación natural, mediante Redes Bayesianas aplicadas a un modelo de Dinámica de Fluidos Computacional. La Red Bayesiana permitió determinar los espacios del invernadero con condiciones ambientales adversas para el desarrollo del cultivo y los estados climáticos más probables, a partir de las relaciones entre las variables estudiadas.
Palabras clave: CFD, flujo de aire, invernadero, Solanum lycopersicum, ventilación natural.
Abstract
The advances in computer systems and resources make it possible to develop models to simulate the behavior of the fluids in greenhouses. However, the prediction of the gradients of mass and energy in the greenhouses with the crop and natural ventilation is difficult due to the stochastic nature of the wind and the relationships of dependence among temperature, CO2 and relative humidity. There are heuristic techniques, such as the Bayesian Networks, which help to know the relationships among the variables that cannot be determined with statistical tools. The objective of the present study was to determine temperature, CO2 concentration and relative humidity with respect to crop height, in a greenhouse with natural ventilation, by means of Bayesian Networks applied to a model of Computational Fluid Dynamic. The Bayesian Network made it possible to determine the spaces of the greenhouse with adverse environmental conditions for the crop development and the most probable climatic states, from the relationships among the variables studied.
Key words: CFD, air flow, greenhouse, Solanum lycopersicum, natural ventilation.
INTRODUCCIÓN
La Dinámica de Fluidos Computacional (CFD, por sus siglas en inglés) es una aplicación que, a partir de un balance de materia y energía en un volumen de control, permite obtener una solución numérica del comportamiento de fluidos. Esta técnica se usa para determinar las condiciones climáticas dentro de los invernaderos (Sase et al., 2006; Bournet y Boulard, 2010; De la Torre-Gea et al., 2011b), donde la ventilación influye principalmente en los gradientes de temperatura, humedad relativa y concentración de CO2 (Teitel et al., 2010) que afectan el desarrollo de los cultivos (Coelho et al., 2006).
Al realizar simulaciones mediante CFD del interior de los invernaderos es importante considerar que la altura del cultivo actúa sobre la velocidad del viento, pues ejerce una tensión mecánica o fuerza de arrastre, que a su vez modifica la temperatura y humedad relativa (Bournet y Boulard, 2010).
La estimación de gradientes de temperatura, humedad relativa y CO2 es difícil en términos de probabilidad porque estas variables están relacionadas intrínsecamente e influenciadas por la naturaleza estocástica del viento. Así, es necesario combinar técnicas de predicción, que permitan relacionar los conjuntos de datos generados por las aproximaciones numéricas. Las Redes Bayesianas (BNs por sus siglas en inglés) son técnicas numéricas de incertidumbre que usan la inferencia bayesiana como método heurístico, y pueden ayudar a describir las relaciones entre las variables que definen las condiciones del clima (De la Torre-Gea et al., 2011a). Con una BN es posible inferir las relaciones entre la temperatura, humedad relativa, concentración de CO2 y su interacción con el viento, a partir de un modelo de dinámica de fluidos computacional.
Según Lima y Lall (2010), las relaciones entre las variables climáticas se pueden estimar para evaluar sus tendencias con los datos climáticos empleando BNs. Tae-Wong et al. (2008) propusieron un modelo estocástico mediante datos de precipitación pluvial media anual que representa las dependencias temporales y espaciales de la ocurrencia de lluvia diaria. Un modelo basado en BNs y cadenas ocultas de Markov fue desarrollado por Wang et al. (2010), con el algoritmo K2 de máxima verosimilitud, y estimaron la probabilidad de lluvia con datos incompletos. El objetivo de este estudio fue determinar la distribución de la temperatura, concentración de CO2 y humedad relativa, en diferentes alturas de un cultivo de tomate (Solanum lycopersicum) en un invernadero con ventilación natural, mediante BNs aplicadas a un modelo CFD.
Teoría de las BNs
Las BNs son representaciones del conocimiento, desarrolladas en el campo de la inteligencia artificial, para el razonamiento aproximado (Correa et al., 2009). Una BN es un gráfico acíclico cuyos nodos corresponden a conceptos o variables, y cuyos enlaces definen las relaciones o funciones entre las variables (Reyes, 2010). Las variables se definen en un dominio discreto o cualitativo, y las relaciones funcionales describen las inferencias causales expresadas en términos de probabilidades condicionales (Ecuación 1).

Las BNs se pueden usar para identificar las relaciones entre las variables anteriormente indeterminadas o para describir y cuantificar estas relaciones, incluso con un conjunto de datos incompletos. Los algoritmos de solución de las BNs permiten calcular la distribución de probabilidad esperada de las variables de salida. El resultado de este cálculo es dependiente de la distribución de probabilidad de las variables de entrada. Las BNs pueden ser percibidas como una distribución de probabilidades conjunta de una colección de variables aleatorias discretas (Gámez et al., 2011).
La probabilidad a priori P (cj) es la probabilidad de que una muestra x. pertenezca a la clase CJ, definida sin información sobre sus valores característicos (Ecuación 2).

Las máquinas de aprendizaje, en la inteligencia artificial, están relacionadas estrechamente con la minería de datos, los métodos de clasificación o agrupamiento en estadística, el razonamiento inductivo y el reconocimiento de patrones. Los métodos estadísticos de aprendizaje automático se pueden aplicar al marco de la estadística bayesiana; sin embargo, la máquina de aprendizaje puede emplear una variedad de técnicas de clasificación para producir otros modelos de BNs (Garrote et al., 2007). El objetivo del aprendizaje mediante una BN es encontrar el arreglo que describa mejor a los datos observados. El número de estructuras posibles de grafos acíclicos directos para la búsqueda es exponencial al número de variables en el dominio, definido por la Ecuación 3:

El algoritmo K2 es el método más representativo entre las aproximaciones de "búsqueda y resultado". El algoritmo comienza asignando a cada variable sin padres. Luego agrega de manera incremental los padres a la variable actual que aumenta su puntuación en la estructura resultante. Cuando cualquier adición de una madre soltera no puede aumentar la cuenta, deja de agregar padres a la variable. Si se considera un valor conocido de antemano de alguna de las variables, el espacio de búsqueda bajo esta restricción es menor que el espacio de la estructura entera. Si el orden de las variables es desconocido, puede realizarse la búsqueda en los ordenamientos posibles (Hruschka et al., 2007).
MATERIALES Y MÉTODOS
Caracterización del flujo de aire y variables de estado
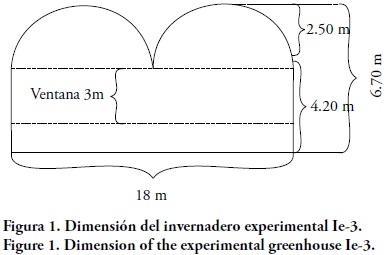
En el invernadero experimental Ie3 de la Universidad Autónoma de Querétaro, campus Amazcala, se realizaron muestreos entre el 21 y 25 de agosto de 2011, para determinar las condiciones iniciales del modelo CFD y entre el 15 y 22 de abril de 2012, para validar el modelo CFD. El invernadero Gótico tiene 432 m2, está dividido en dos naves, cada una de 9x24 m, con altura a la canaleta de 4.20 m y 6.70 m a la cumbrera (2.50 m de cumbrera), sin ventanas cenitales sólo laterales de tipo enrollable, de 3x9 m a la cara frontal y posterior y de 3x16 m a los costados (Figura 1). Su orientación fue de norte-sur, igual que los camellones del cultivo. Solanum lycopersicum se cultivó con densidad de 2.5 plantas m-2, anchura de los camellones del cultivo de 60 cm, altura de 2 m y pasillo de 1 m entre camellones.
Los datos incluyeron la temperatura, humedad relativa, concentración de CO2 y velocidad del viento. Las mediciones se realizaron a 1 y 3 m de altura sobre al suelo, cada 4 min, con un sensor tipo LM335 para la temperatura y humedad relativa y con un sensor modelo FYA600CO2H para la concentración de CO2. La velocidad y dirección del viento fueron medidas cada 2 s con anemómetros omnidireccionales, con intervalo entre 0 y 20 m s-1 y precisión de 0.03 m s-1.
Metodología para el desarrollo del modelo CFD
La metodología para desarrollar el modelo CFD fue propuesta por Rico-García (2008), en tres etapas:
1) Discretización del flujo continuo: las variables de campo se aproximaron a un número finito de valores en puntos llamados nodos.
2) Discretización de las ecuaciones de movimiento en función de los valores de los nodos.
3) Solución del sistema de ecuaciones algebraicas y obtención de los valores de las variables en todos los nodos.
Modelo CFD del espacio del cultivo
El desarrollo y simulación numérica del modelo CFD se realizó con el software ANSYS FLUENT V.14 e incluyó la temperatura, humedad relativa y concentración de CO2 (Figura 2 y Cuadro 1).
Análisis del modelo CFD mediante BNs
El análisis de las relaciones entre las variables se realizó con el software ELVIRA (versión 0.162) en las tres etapas sugeridas por Garrote (2007):
1) Pre-procesamiento: fue realizado mediante el algoritmo de imputación "por promedios" para completar las series de datos parciales. Este algoritmo reemplazó los valores faltantes o desconocidos por promedios, sin la necesidad de parámetros, los discretizó masivamente en diez intervalos con frecuencia similar.
2) Procesamiento: se realizó de acuerdo con lo propuesto por Wang et al. (2006), para determinar la estructura mejor de red bayesiana, con el algoritmo K2, número máximo de nodos padres igual a 3 y sin restricciones.
3) Post-procesamiento: se realizó un análisis para obtener la estructura topológica de la red, la cual representó las dependencias causales entre variables. Después de obtener la red de aprendizaje paramétrico se calcularon las probabilidades condicionales en las variables que mostraron relación o dependencia.
Del modelo CFD se tomó una muestra de 33,610 registros en un plano transversal, a una distancia de 8.8 m de la entrada (1/3 de la longitud del invernadero), con datos de temperatura, concentración de CO2, humedad relativa, altura y ubicación del cultivo con respecto a la anchura del invernadero. Con ellos se desarrolló una BN, discretizando los datos en 10 intervalos para cada variable, entre 26 °C y 37 °C, 200 y 400 mg CO2 m-3, 10% y 90% de humedad relativa, 0 y 22 m de la longitud del invernadero, 0 y 18 m de anchura del invernadero y 0.2 y 2.00 m de altura del cultivo.
RESULTADOS Y DISCUSIÓN
Los valores de humedad relativa y concentración de CO2 obtenidos con los sensores disminuyeron con el aumento de la temperatura y existieron gradientes en el espacio del cultivo, encima de él y entre los camellones. Los gradientes fueron mayores en el cultivo debido al efecto del estancamiento del viento (Cuadro 2). Estos resultados coinciden con los obtenidos por Teitel et al. (2010), por lo cual se usaron para configurar el modelo CFD.
La validación del modelo CFD consistió en verificar la exactitud de los resultados obtenidos y se realizó a través de un conjunto de datos diferente al de las mediciones obtenidas para definir las condiciones iniciales y de frontera del modelo desarrollado. Una prueba de significancia se aplicó mediante análisis de regresión lineal, de las relaciones entre humedad y CO2 con respecto a la temperatura, en condiciones climáticas similares (Figura 3).
La regresión lineal mostró que la concentración de CO2 y humedad relativa en el modelo CFD son similares con el conjunto de datos medidos, con 5 % de diferencia en la ordenada al origen en la ecuación de la humedad relativa, y 39 mg m-3 en la ecuación de la concentración de CO2. Las pendientes de las ecuaciones en ambos casos indican que la aproximación por el modelo CFD es aceptable.
Las distribuciones de CO2, humedad relativa y temperatura fueron heterogéneas, ya que los camellones formaron una barrera que evitó el flujo libre del viento, lo que aumentó la turbulencia (Cuadro 3, Figura 4). Esto concuerda con los resultados obtenidos por Majdoubi et al. (2009). La temperatura máxima se detectó en la parte del cultivo más cercana al suelo. Lo anterior es resultado del efecto de la radiación solar y el estancamiento del aire por el cultivo, que a la vez provoca concentraciones bajas de CO2 y humedad relativa alta.

BN para el análisis del modelo CFD
Una BN se obtuvo con el software ELVIRA (Figura 5) aplicando el algoritmo K2 al conjunto de datos calculados con el modelo CFD, y mostró las dependencias entre las variables estudiadas, la altura del cultivo y su ubicación en el invernadero. La anchura del invernadero es el nodo que más influyó en las variables que definen el clima dentro del invernadero, debido a que establece la velocidad y dirección del viento.
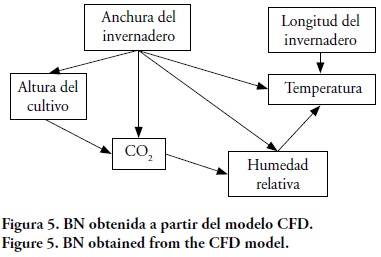
La altura del cultivo afectó inversamente la concentración de CO2, pues en el modelo CFD se consideraron las ecuaciones del Cuadro 2 en la geometría de la Figura 2A para simular los efectos del cultivo en la fotosíntesis. La humedad relativa fue influenciada por el viento y la turbulencia, y se relacionó inversamente con la temperatura. La relación entre la temperatura y la longitud del invernadero indicó el efecto de la radiación solar sobre la cubierta del invernadero. La temperatura fue la variable más susceptible ya que presentó un número mayor de dependencias que estuvieron relacionadas mayormente con las dimensiones del invernadero. Debido a que no se localizaron otros estudios sobre modelos de BNs aplicados a condiciones climáticas del interior de invernaderos, no se hicieron comparaciones.
A partir de 33 610 registros obtenidos del modelo CFD, se determinaron los valores de temperatura, concentración de CO2 y humedad relativa a diferentes alturas del cultivo, y a partir de sus inferencias se calcularon sus probabilidades de ocurrencia mediante el software ELVIRA (Cuadros 4 y 5).


Las diferencias entre los cuadros 3 y 4 se deben a que en el Cuadro 3 se consideraron valores promedio de todo el interior del invernadero, mientras que para el segundo conjunto los valores fueron calculados a partir de la BN (Figura 5), aplicada a una muestra del invernadero.
El manejo de los valores altura del cultivo, longitud y anchura del invernadero, permitieron identificar que la parte del cultivo más cercana al suelo requiere mayor ventilación para su desarrollo, porque es donde se presentó un estancamiento del aire. Así mismo, los valores de anchura permitieron definir que el viento no alcanza a disipar las altas temperaturas al extremo derecho del invernadero.
La concentración de CO2 al interior del invernadero es menor que la del ambiente exterior, debido tanto al proceso de fotosíntesis como al calentamiento. Una posible solución a este problema es incrementar las entradas de aire mediante ventanas cenitales, que permitan ventilar la parte central, aumentando los niveles de CO2 y disminuyendo la temperatura.
La humedad relativa alta puede causar problemas al cultivo en la parte cercana al suelo, lo cual se puede corregir incrementando la altura de la base del cultivo mediante la poda de sus ramas inferiores, de esta manera el viento podrá circular evitando el estancamiento.
Los resultados mostraron (Cuadro 5) los estados de ocurrencia más probables, con base a las relaciones de la variables estudiadas, donde las mayores probabilidades están definidas por distribuciones de probabilidad con menor variabilidad, según Gámez et al.(2011); así, la concentración de CO2 y la humedad relativa fueron las variables con menor dispersión. Además, la longitud del invernadero presentó la misma probabilidad para todas las alturas del cultivo, ya que fue referido al mismo valor del Cuadro 4 (8.8 m), el cual definió la línea transversal de la cual fueron tomados los registros del modelo CFD.
Relaciones inversamente proporcionales fueron observadas entre la concentración de CO2 y la altura del cultivo, como se muestra en la Figura 6, lo cual concuerda con el estudio reportado por Teitel (2010).
CONCLUSIONES
Un modelo de CFD permite determinar las relaciones entre la temperatura, humedad relativa y concentración de CO2 con respecto al viento y altura del cultivo mediante una BN. La anchura del invernadero es la variable con efecto mayor en el clima, pues define la ventilación interior. La temperatura es la más influenciada por las otras variables, por lo que puede ser modificada de varias maneras. El cálculo de la inferencia en la BN permite establecer el estado más probable de las variables estudiadas y determina los espacios del invernadero que presentan condiciones críticas para el desarrollo del cultivo. Esas condiciones se presentan próximas al suelo y en la zona central del invernadero, e incluyen temperaturas y humedad relativa altas. Es necesario aumentar la ventilación mediante ventanas cenitales y aumentar la distancia entre el suelo y el cultivo mediante poda. La ventaja de usar una BN para analizar un modelo CFD es incluir la incertidumbre mediante el cálculo de las inferencias y cuantificación del grado de dependencia o independencia entre las variables estudiadas.
LITERATURA CITADA
Bournet, P. E., and T. Boulard. 2010. Effect of ventilator configuration on the distributed climate of greenhouses: A review of experimental and CFD studies. Comput. Electron. Agr. 74: 195-217. [ Links ]
Coelho, M., F. Baptista, F. Cruz, V., and J. L. Garcia. 2006. Comparison of four natural ventilation systems in a Mediterranean greenhouse. Acta Horticulturae 719: 157-171. [ Links ]
Correa M., C. Bielza, J. Paimes-Teixeira, and J. R. Alique. 2009. Comparison of Bayesian networks and artificial neural networks for quality detection in a machining process. Expert Syst. Appl. 36: 7270-7279. [ Links ]
De la Torre-Gea, G., G. M. Soto-Zarazúa, R. Guevara-González, and E. Rico-García. 2011a. Bayesian Networks for defining relationships among climate factors. Int. J. Phys. Sci. 6: 4412-4418. [ Links ]
De la Torre-Gea, G., G. M. Soto-Zarazúa, I. López-Crúz, I. Torres-Pacheco, and E. Rico-García. 2011b. Computational fluid dynamics in greenhouses: A review. Afr. J. Biotechnol. 10: 17651-17662. [ Links ]
Gámez, J. A., J. L. Mateo, and J. M. Puerta. 2011. Learning Bayesian networks by hill climbing: efficient methods based on progressive restriction of the neighborhood. Data Min. Knowl. Disc. 22: 106-148. [ Links ]
Garrote, L., M. Molina, and L. Mediero. 2007. Probabilistic Forecasts Using Bayesian Networks Calibrated with Deterministic Rainfall-Runoff Models. In: Vasiliev E. F., P. H. J. M. van Gelder, E. J. Plate, and M. V. Bolgov (eds.), Extreme Hydrological Events: New Concepts for Security, Springer, pp: 173-183. [ Links ]
Hruschka, E., E. Hruschka, and N. F. F. Ebecken. 2007. Bayesian networks for imputation in classification Problems. J. Intell. Inform. Syst. 29: 231-252. [ Links ]
Majdoubi, H., T. Boulard, H. Fatnassi, and L. Bouirden. 2009. Airflow and microclimate patterns in a one-hectare canary type greenhouse: an experimental and CFD assisted study. Agr. For. Meteorol. 149: 1050-1062. [ Links ]
Reyes, P. 2010. Bayesian networks for setting genetic algorithm parameters used in problems of geometric constraint satisfaction. Intell. Artif. 45: 5-8. [ Links ]
Rico-García, E., I. López-Cruz, G. Herrera, G. M. Soto-Zarazúa, and M. R. Castañeda. 2008. Effect of the yemperature on a greenhouse natural ventilation under hot conditions: Computational fluid dynamics simulations. J. Appl. Sci. 8:4543-4551. [ Links ]
Sase, S. 2006. Air movement and climate uniformity in ventilated greenhouses. Acta Horticulturae 719: 313-324. [ Links ]
Teitel, M., M. Atias, and M. Barak. 2010. Gradients of temperature, humidity and CO2 along a fan-ventilated greenhouse. Biosyst. Eng. 106: 16 6-174. [ Links ]
Tae-Wong, K., A. Hosung, C. H. Gunhui, and Y. Chulsang. 2008. Stochastic multi-site generation of daily rainfall occurrence in south Florida. Stoch. Environ. Res. Risk Assess. 22: 705-717. [ Links ]
Wang, H. R., Y. LeTian, X. XinYi, F. QiLei, J. Yan, L. Qiong, and T. Qi. 2010. Bayesian networks precipitation model based on hidden Markov analysis and its application. Sci. China Technol. Sci. 53: 539-547. [ Links ]
Wang, S., X. Li, and H. Tang. 2006. Learning Bayesian Networks dtructure with continous variables. In: Li X., O. R. Zaiane, and Z. Li (eds). Advanced Data Mining and Applications. Second International Conference, ADMA2006, Xi'an, China, Proceedings. Lecture Notes in Computer Science, Heidelberg: Springer-Verlang. pp: 448-456. [ Links ]

