











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
En el campo de la atención médica, los servicios de análisis clínicos son fundamentales para el diagnóstico y tratamiento de pacientes. Al respecto, la flebotomía es el procedimiento médico que consiste en extraer sangre de un paciente para realizar pruebas de laboratorio, transfusiones de sangre o donaciones. La evaluación de una muestra de sangre de un paciente es un paso crítico en la atención médica [1]. Los laboratorios clínicos se rigen por diversos lineamientos sanitarios y estándares, de los cuales, la norma ISO 15189:2022 establece los requisitos de un sistema de gestión de la calidad en laboratorios clínicos, incluyendo lineamientos para procesos pre-examen, durante el examen y post-examen [2]. Algunos lineamientos incluyen el volumen de las muestras, tipo de tubo y sustancia preservativa a utilizar para asegurar que no existe faltante ni excedente de muestras colectadas [2], ya que cualquier desviación es crítica y debe ser corregida [3]. Además, el estándar requiere lineamientos para la identificación correcta de muestras para garantizar la seguridad del paciente, optimizar los procesos de laboratorio y entregar resultados de pruebas para el posterior diagnóstico y seguimiento de enfermedades.
Dentro de las tres fases del periodo analítico (preanalítica, analítica y postanalítica), es en las fases preanalítica y postanalítica donde son más propensas a errores que la fase analítica [4] [5] [6]. En la fase preanalítica destacan errores como solicitudes incorrectas, mala identificación del paciente o muestras, recolección de muestras inadecuada (volumen insuficiente), uso de contenedores incorrectos y fallos en el manejo, almacenamiento o transporte de la muestra [4]. En cuanto la etapa postanalítica, los errores incluyen validación incorrecta de datos, retrasos en la entrega de resultados críticos, errores en la entrada de datos y tiempos de respuesta excesivos[7] [8]. Estos errores potencialmente llevan al rechazo de muestras por parte del laboratorio. En la fase preanalítica, enfermería desempeña un papel crítico, al ser la responsable de la obtención de las muestras de sangre, mientras que en la fase postanalítica es el personal administrativo quien es el responsable de la recopilación y envío de resultados.
En las unidades médicas, el área de flebotomía es uno de los lugares con mayor cantidad de pacientes en un hospital [9], lo que implica grandes flujos de pacientes que pueden experimentar demoras por existencia de cuellos de botella. Al ser el servicio de obtención de muestras un proceso manual, éste conlleva la inspección visual de numerosos recipientes de muestras de sangre y es susceptible a errores humanos, lo que podría dar lugar a diagnósticos erróneos, retrasos en el tratamiento o atención deficiente al paciente. En este contexto, existe una creciente necesidad de sistemas apoyados en tecnologías que puedan ayudar a inspeccionar recipientes con muestras de sangre en laboratorios clínicos, incluyendo la reciente tendencia a la integración de la inteligencia artificial (IA) en el área de hematología [10] y química sanguínea mediante la automatización del análisis, la interpretación de datos, la segmentación precisa de imágenes para aislar células sanguíneas y el análisis de datos clínicos a nivel molecular y del paciente [11]. Sin embargo, persisten desafíos como la generalización de modelos, el desempeño en conjuntos de datos externos, la adopción de arquitecturas más actuales[11], la falta de interpretación, el volumen de datos, así como la confidencialidad de la información [12]. Existen además oportunidades de mejora en la inspección de muestras de sangre para la identificación de errores cuando la muestra de sangre recolectada de un paciente, se etiqueta incorrectamente con información de otro paciente, pudiendo ser difícil para el laboratorio reconocer este tipo de error [13].
En este sentido, mejorar la calidad y la eficiencia en los servicios de salud implica un reto recurrente al que se enfrenta el sector salud [14], por lo que en años recientes se ha incrementado la digitalización de los servicios de salud, conocida como Healthcare 4.0 [15], que involucra la implementación de variadas tecnologías y con fines distintos incluyendo deep learning (DL) [16], machine learning (ML) [17], big data [18], automatización [19], simulación [20], entre otras. Particularmente, herramientas de IA desempeñan un papel crucial en el campo médico, transformando la manera en que se diagnostican enfermedades, se realizan tratamientos y se gestionan los datos clínicos. Estas tecnologías han demostrado un potencial significativo para mejorar la precisión, la eficiencia y la atención médica en general. Algunas de las actividades clave para el sector médico donde se emplea IA son el análisis de grandes volúmenes de datos y el reconocimiento de patrones u objetos en imágenes médicas, como rayos X [21], tomografías computarizadas [22], resonancias magnéticas [23] y ultrasonidos [24]. DL es una subrama de la IA, la cual ha presenciado avances notables en los últimos años, ofreciendo oportunidades para el análisis de imágenes y las tareas de detección de objetos. Los modelos de DL se componen por múltiples capas que permiten aprender una secuencia en sus distintos niveles [25]. Al respecto, las redes neuronales convolucionales (CNN) procesan imágenes y otras formas de datos con estructura espacial, donde la clasificación se basa en regiones creando un cuadro delimitador alrededor de la región de interés, como la densidad, el color, etc. Los métodos estándares involucran algoritmos de una etapa [26] y dos etapas [27], siendo YOLO (You Only Look Once)[28] una familia de algoritmos de una sola etapa que ha mostrado ventajas incluyendo menor tiempo de entrenamiento [29] así como su eficiencia y precisión en la localización y clasificación simultánea de múltiples objetos en tiempo real en imágenes [28].
Este estudio prueba la factibilidad de los algoritmos YOLO para la detección de características relevantes de tubos con muestras de sangre en un laboratorio clínico, centrándose en tres tareas principales: (1) verificar la presencia de identificación en cada recipiente, (2) verificar la presencia de sangre contenida en el recipiente y (3) detectar el adecuado recipiente para la prueba a realizar en función del color de la tapa. Al abordar estas tareas, se busca contribuir a mejorar la eficiencia y confiabilidad del análisis de muestras de sangre, lo que en última instancia mejora la atención al paciente y los flujos de trabajo de laboratorio.
Materiales y métodos
Con la finalidad de una evaluación integral de los modelos YOLO, se consideró las arquitecturas YOLOv5, YOLOv7 y YOLOv8 debido a características específicas que aportan cada uno en términos de precisión, velocidad y optimización respecto a sus predecesores. YOLOv5 es reconocido por su balance entre eficiencia y facilidad de implementación, facilitando así la inspección en tiempo real. YOLOv7 incluye mejoras en la velocidad y precisión en diferentes tipos de hardware. YOLOv8 incluye avances de arquitectura de red y procesamiento, resultando en mayor adaptabilidad y desempeño en escenarios complejos. Estas diferencias permitieron evaluar cada versión en la identificación precisa y rápida de seis clases de objetos, incluyendo: (i) etiqueta presente en tubos (label), (ii) tubo con llenado insuficiente (not_ok), (iii) tubo con llenado ok (good), (iv) tubo con tapa azul (blue_cap) que contienen citrato de sodio y se utilizan para pruebas de coagulación, (v) tubo con tapa morada (purple_cap) utilizadas en pruebas de hematología y (vi) tubo con tapa amarilla (yellow_cap) con anticoagulante para pruebas de química sanguínea. Se utilizó un conjunto de datos compuesto por 3000 imágenes, desglosadas en 2104 imágenes (70 %) para entrenamiento, 604 imágenes para validación (20 %) y 292 imágenes (10 %) para prueba y se realizó las anotaciones buscando un balance en las clases como se describe en la Tabla 1.
Tabla 1 Anotaciones por clase
| Descripción | Clases | Anotaciones |
|---|---|---|
| Detección de etiqueta presente en tubos | label | 2,378 |
| Tubo con llenado insuficiente | not_ok | 1,918 |
| Tubo con llenado ok | good | 2,580 |
| Tubo con tapa azul | blue_cap | 2,047 |
| Tubo con tapa morada | purple_cap | 1,998 |
| Tubo con tapa amarilla | yellow_cap | 1,725 |
El entrenamiento de los datos empleó el acelerador Tesla T4 incluido en la versión gratuita de Google Colab. Este acelerador, es una unidad de procesamiento gráfico (GPU) diseñada para tareas de alto rendimiento y cuenta con 40 núcleos, una frecuencia de 1.59 GHz y una capacidad de procesamiento de FP16 de 65 TFLOPS, lo cual, lo vuelve una herramienta versátil, potente y accesible. Por su parte, el etiquetado de las imágenes se realizó mediante la segmentación, empleando recuadros delimitadores “bounding boxes” en la herramienta Roboflow, la cual es una plataforma en línea para la clasificación de imágenes y la gestión de datos [30]. Las imágenes utilizadas presentan una resolución de 640x640 pixeles en formato JPG y se cuentan con acceso libre al conjunto de datos en la siguiente liga: https://doi.org/10.34740/kaggle/dsv/9616793. Los resultados se evaluaron como verdadero positivo (TP, true positive), es decir, el número de objetos detectados correctamente; verdadero negativo (TN, true negative), es decir, muestras que se rechazan correctamente de la clase; falso positivo (FP, false positive), es decir, el número de objetos detectados erróneamente; y falso negativo (FN, false negative), es decir, el número de objetos omitidos. Para evaluar las diferentes arquitecturas se utilizaron índices de desempeño como precisión (precision), sensibilidad (recall) y precisión media promedio (mAP). Precisión, precisión por clase (PRC) [31] o valor predictivo positivo (VPP) [32], mide la proporción de objetos correctamente detectados en relación con los objetos detectados [33]. La ecuación 1 muestra la fórmula utilizada en este estudio.
Recall, indica la proporción de objetos detectados correctamente en relación con todos los objetos presentes en el conjunto de datos [34], por lo tanto, recall es la precisión de las instancias predichas positivamente que describen cuántas se etiquetaron correctamente [35], lo que muestra el nivel de un modelo para predecir la clase positiva cuando la clase real es positiva [36]. En este estudio calculamos recall con la ecuación (2).
Precisión media promedio (mAP) mide en qué porcentaje el algoritmo predice el objeto correctamente de todas las clases individuales [37], siendo una métrica clave para evaluar los algoritmos de detección de objetos [38] y para la comparación entre modelos [39]. La ecuación 3 muestra la descripción matemática de mAP, donde APk representa la precisión promedio de las clases y n representa el número de clases [40].
En conjunto, estos métricos proporcionan una evaluación global del rendimiento del modelo y son ampliamente utilizados en la evaluación de algoritmos de detección de objetos ya que permiten comparar el desempeño del modelo en diferentes aspectos de la detección [41] [42]. El estudio también se enfoca en analizar el comportamiento de los modelos en distintas épocas de entrenamiento. Se seleccionaron las épocas 20, 50 y 100 como puntos de referencia para examinar la evolución de los modelos durante el proceso de entrenamiento y evaluar su capacidad de aprendizaje a lo largo del tiempo. Para complementar el resultado, se analizaron las matrices de confusión normalizadas y las gráficas de pérdidas para evaluar y visualizar el rendimiento de un modelo.
Equipo y Herramientas
El análisis se llevó a cabo en un equipo con un procesador AMD Ryzen 5 4650G con Radeon R7 Renoir, funcionando a una velocidad de 3.70 GHz, con 32 GB de RAM y sistema operativo Windows 11 de 64 bits. Además, se empleó una tarjeta gráfica NVIDIA GeForce GTX 1660 SUPER VENTUS XS OC con 6 GB de memoria dedicada para el procesamiento computacional. Para la captura de imágenes se utilizaron dos dispositivos: una cámara marca Salandens, modelo B0872YBHBV, con una resolución de 1080p, y la cámara de un teléfono móvil Huawei Nova Y9 SE, con una resolución de 108 MP. El entrenamiento de los modelos se realizó utilizando Google Colab en su versión gratuita, la cual ofrece acceso a una GPU T4 con 12.7 GB de RAM, 15 GB de memoria dedicada para la GPU, y un espacio en disco de 112.6 GB.
Resultados y discusión
El desempeño de los diferentes modelos de YOLO se muestra en la Tabla 2, siendo YOLOv8 la arquitectura que presentó la mayor precisión, 0.927, con 50 épocas mientras que YOLOv5, 0.924, con 100 épocas y YOLOv7, 0.917 con 100 épocas. Respecto a recall, YOLOv8 presentó los mayores valores, destacando 0.914 con 100 épocas. Al evaluar la capacidad del modelo para detectar imágenes de distintas clases, YOLOv8 presentó un valor de mAP de 0.941 y 0.940 con 100 y 50 épocas respectivamente. En términos de tiempo de entrenamiento, el modelo más rápido fue YOLOv5 con 20 épocas (15 min, 4 s), en contraparte, YOLOv7 con 100 épocas presentó la mayor duración (3 h, 27 min, 44 s).
Tabla 2 Resultados del rendimiento de los modelos de YOLOv5, YOLOv7 y YOLOv8.
| Modelo | Épocas | Precisión | Sensibilidad | mAP | Tiempo |
|---|---|---|---|---|---|
| YOLOv5 | 20 | 0.909 | 0.897 | 0.919 | 15 min 4 s |
| 50 | 0.923 | 0.900 | 0.934 | 37 min 45 s | |
| 100 | 0.924 | 0.900 | 0.935 | 1 h 14 min 10 s | |
| YOLOv7 | 20 | 0.682 | 0.665 | 0.675 | 42 min 36 s |
| 50 | 0.903 | 0.852 | 0.856 | 1 h 44 min 24 s | |
| 100 | 0.917 | 0.878 | 0.906 | 3 h 27 min 44 s | |
| YOLOv8 | 20 | 0.922 | 0.907 | 0.933 | 34 min 19 s |
| 50 | 0.927 | 0.909 | 0.940 | 1 h 26 min 13 s | |
| 100 | 0.917 | 0.914 | 0.941 | 2 h 59 min 56 s |
En términos generales, YOLOv8 presenta un mayor desempeño, logrando una mayor precisión y mAP en todas las épocas analizadas. Su tiempo de entrenamiento, aunque mayor que YOLOv5, es más corto que YOLOv7, lo cual lo convierte en una opción eficiente en términos de rendimiento y costo computacional. YOLOv5, aunque no alcanza los niveles de YOLOv8, ofrece un desempeño consistente con una buena precisión y mAP, y tiempos de entrenamiento significativamente menores, haciéndolo atractivo en escenarios donde los recursos de tiempo y procesamiento son limitados. YOLOv7 comienza con un rendimiento inferior incluyendo precisión y mAP bajos con 20 épocas, pero mejora significativamente con más épocas de entrenamiento, aunque su tiempo de entrenamiento es considerablemente mayor que los otros dos modelos, lo cual podría ser un factor limitante dependiendo de la aplicación. la Figura 1 muestra ejemplos de detección de clases empleando YOLOv8.

Figura 1 (A) Ejemplo de detección de las clases “purple_cap” y “good”. (B) Demostración de la detección de las clases “yellow_cap” y “label”. (C) Representación de las clases “blue_cap” y “not_ok” empleando YOLOv8.
El desempeño de las tres arquitecturas por clase al utilizar 50 épocas se muestra en las Tablas 3-5. El resto de resultados con 20 y 100 épocas se agregó como material suplementario al artículo. Particularmente, la Tabla 3 muestra el desempeño de YOLOv5 con 50 épocas, destacando una precisión de hasta 0.980 para tapa morada “purple_cap” y una mínima de 0.876 para identificar tubos con tapa amarilla “yellow_cap”. Recall presenta valores de 0.978 hasta 0.85 para la detección de tubos con tapa morada “purple_cap” y tapa amarilla “yellow_cap” respectivamente. La clase con mayor mAP (0.99) es para tapa morada “purple_cap”, mientras que el menor valor fue 0.893 para la clase tapa amarilla “yellow_cap”.
Tabla 3 Resultados del rendimiento del modelo de YOLOv5 con 3000 imágenes entrenado con 50 épocas
| Clase | Precisión | Recall | mAP |
|---|---|---|---|
| blue_cap | 0.924 | 0.92 | 0.951 |
| good | 0.934 | 0.915 | 0.938 |
| label | 0.93 | 0.851 | 0.927 |
| not_ok | 0.896 | 0.886 | 0.903 |
| purple_cap | 0.98 | 0.978 | 0.99 |
| yellow_cap | 0.876 | 0.85 | 0.893 |
Tabla 4 Resultados del rendimiento del modelo de YOLOv7 con 3000 imágenes entrenado con 50 épocas
| Clase | Precisión | Recall | mAP |
|---|---|---|---|
| blue_cap | 0.906 | 0.914 | 0.877 |
| good | 0.901 | 0.860 | 0.87 |
| label | 0.944 | 0.708 | 0.826 |
| not_ok | 0.88 | 0.817 | 0.805 |
| purple_cap | 0.966 | 0.963 | 0.978 |
| yellow_cap | 0.821 | 0.847 | 0.782 |
Tabla 5 Resultados del rendimiento del modelo de YOLOv8 con 3000 imágenes entrenado con 50 épocas.
| Clase | Precisión | Recall | mAP |
|---|---|---|---|
| blue_cap | 0.923 | 0.914 | 0.955 |
| good | 0.933 | 0.921 | 0.942 |
| label | 0.944 | 0.901 | 0.952 |
| not_ok | 0.883 | 0.901 | 0.891 |
| purple_cap | 0.984 | 0.976 | 0.993 |
| yellow_cap | 0.895 | 0.840 | 0.908 |
Por su parte, la Tabla 4 muestra el desempeño de YOLOv7 con 50 épocas, logrando una precisión de hasta 0.966 para tapa morada “purple_cap” y una mínima de 0.821 para identificar tubos con tapa amarilla “yellow_cap”. Recall presentó valores de 0.963 hasta 0.708 para la detección de tubos con tapa morada “purple_cap” y tubos con etiqueta “label” respectivamente. La clase con el mayor mAP de 0.978 fue tapa morada “purple_cap”, mientras que el menor valor fue 0.782 para la clase que reporta los tubos con tapa amarilla “yellow_cap”.
La Tabla 5 muestra los resultados de cada clase utilizando YOLOv8 con 50 épocas, donde se observa una precisión máxima de 0.984 y mínima de 0.883 para identificar los tubos de sangre con tapa morada (“purple_cap”) y los tubos vacíos o que no contienen sangre (“not_ok”) respectivamente. Respecto a recall, el valor mayor es de 0.976 para la detección de tubos con tapa morada (“purple_cap”), mientras que 0.840 fue el valor menor para tubos con tapa amarilla (“yellow_cap”). La clase con mayor mAP de hasta 0.993 es la de tapa morada (“purple_cap”), mientras que el menor valor fue 0.891 para la clase que reporta los tubos que no contienen sangre (“not_ok”).
La Figura 2 muestra la matriz de confusión normalizada para YOLOv8 con 50 épocas donde cada fila representa los porcentajes de instancias reales de cada clase, mientras que las columnas muestran las predicciones del modelo. La diagonal normalizada muestra valores altos en la tasa de acierto, incluyendo “purple_cap” con 0.98, mientras “yellow_cap” muestra un valor de 0.91, siendo el menor.
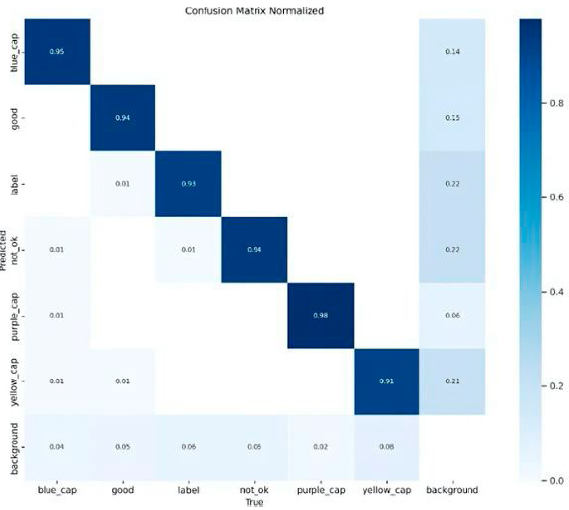
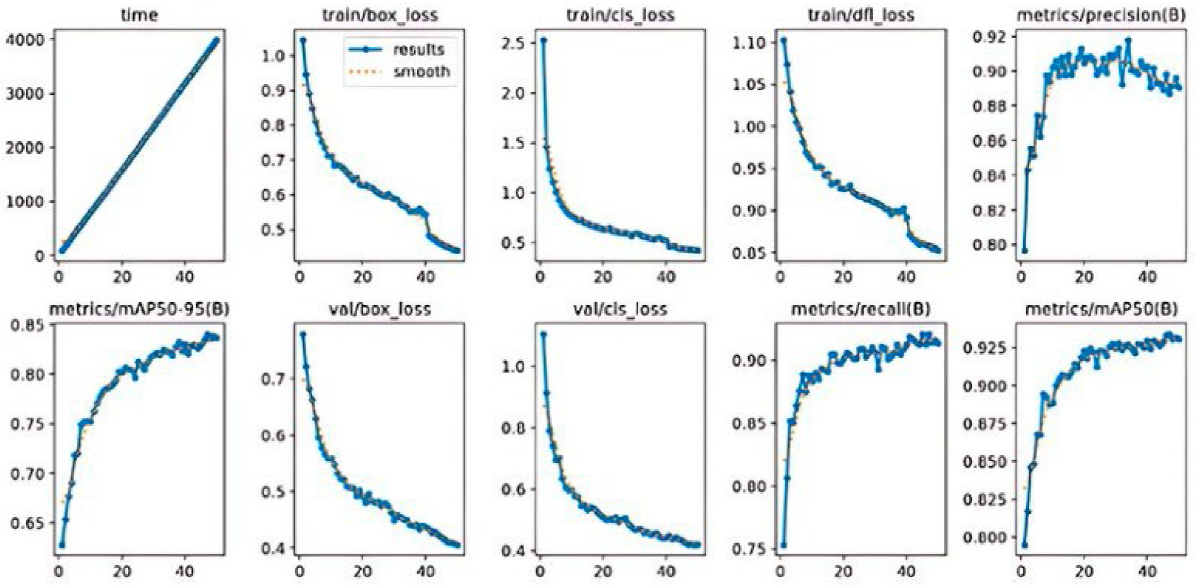
Por su parte, la Figura 3 muestra la gráfica de perdida para YOLOv8 con 50 épocas, destacando cómo la función de pérdida del modelo disminuye a lo largo del tiempo durante el entrenamiento. Una disminución continua en la pérdida indica que el modelo está aprendiendo correctamente a medida que avanza el entrenamiento. La estabilización de la curva o una disminución más lenta después de muchas épocas sugiere que el modelo ha alcanzado su punto de convergencia y que entrenar por más tiempo no mejoraría significativamente su desempeño. Si bien es cierto que extender el tiempo de entrenamiento puede resultar en mejoras marginales en precisión, es necesario considerar el costo computacional y la aplicación práctica para sistemas que trabajan en tiempo real. En conjunto, estas figuras reflejan un buen desempeño de YOLOv8, con una matriz de confusión que revela una alta precisión en la clasificación de los defectos, y una gráfica de pérdida que sugiere que el modelo se ha aprendido eficientemente a lo largo del proceso de entrenamiento.
Adicionalmente, el desempeño de YOLOv8 con 100 épocas se resume en la Tabla 6, destacando una precisión de hasta 0.970 para tapa morada (“purple_cap”) y una mínima de 0.892 para identificar tubos vacíos o que no contienen sangre (“not_ok”). Recall presenta valores de 0.976 hasta 0.877 para la detección de tubos con tapa morada (“purple_cap”) y tapa amarilla (“yellow_cap”) respectivamente. La clase con mayor mAP (0.993) es para tapa morada (“purple_cap”), mientras que el menor valor fue 0.898 para la clase que reporta los tubos que no contienen sangre (“not_ok”). En resumen, YOLOv8 presenta desempeño similar tanto en 50 y 100 épocas.
Tabla 6 Resultados del rendimiento del modelo de YOLOv8 con 3000 imágenes entrenado con 100 épocas.
| Clase | Precisión | Recall | mAP |
|---|---|---|---|
| blue_cap | 0.901 | 0.895 | 0.953 |
| good | 0.928 | 0.928 | 0.943 |
| label | 0.928 | 0.915 | 0.947 |
| not_ok | 0.892 | 0.892 | 0.898 |
| purple_cap | 0.970 | 0.976 | 0.993 |
| yellow_cap | 0.881 | 0.877 | 0.916 |
Implicaciones para laboratorios clínicos
Los laboratorios clínicos tienen un rol significativo al proveer de información para la toma de decisiones de los profesionales de salud. No obstante, existe un grado de falibilidad en pruebas o dispositivo de laboratorio, por lo que la ocurrencia de errores es factible en las diferentes fases de una prueba de laboratorio (preanalítica, analítica y postanalítica) [43]. Este estudio aborda la evaluación de diferentes modelos de DL para identificar objetos en imágenes de tubos con muestras de sangre de un laboratorio clínico como un medio para asistir al profesional de salud en la inspección de riesgos en la etapa preanalítica. Respecto a precisión, este métrico fluctúa entre 0 y 1, donde valores cercanos a 1 indican una alta tasa de detección de clases de manera correcta [33], siendo YOLOv8 la arquitectura que presentó el mayor valor, 0.927, con 50 épocas. Respecto a recall, es decir, la capacidad del modelo de identificar todas las clases en la imagen [44] [45] [46], el modelo YOLOv8 presentó los mayores valores, destacando 0.914 con 100 épocas. Al evaluar la capacidad del modelo para detectar imágenes de distintas clases [47], YOLOv8 presentó un valor de mAP de 0.941 y 0.940 con 100 y 50 épocas respectivamente, demostrando un equilibrio entre la precisión y recall en todas las clases durante la validación [45]. Estos resultados indican que el modelo YOLOv8 presentó un mejor desempeño general, seguido por YOLOv5 y YOLOv7.
Estos resultados presentan a los algoritmos de DL como una herramienta factible para asistir al técnico flebotomista en la inspección de características importantes que pueden ser omitidas por la naturaleza repetitiva del proceso y dependiente del factor humano, incluyendo omitir etiqueta de identificación, extraer cantidad no adecuada de sangre, utilizar tubo incorrecto (con o sin preservativo o anticoagulante), entre otros. Particularmente, la identificación errónea del paciente [6] y el consecuente problema para comunicar resultados, afectan a la prestación de servicios de diagnóstico, siendo reconocidos como objetivos para la mejora de la calidad en este sector [4]. Estos errores pueden provocar la retoma de muestra, retraso del análisis, alteración o contaminación de la sangre, teniendo un impacto en el diagnóstico y salud de los pacientes, así como en la calidad y eficiencia del proceso. Aunque se tiende a responsabilizar al personal de atención médica por los errores, en realidad la mayoría de estos problemas surgen debido a la falta de procesos seguros y bien estructurados [5]. A pesar de su importancia, existe poca información sobre el nivel de precisión al realizar actividades de inspección en el sector salud, particularmente en laboratorios clínicos. En sectores industriales, la tasa de errores al realizar inspección visual varía por múltiples factores [48], con tasas entre 20 % y 30 % de manera general [8], mientras que en el sector de construcción va de 19 % a 48 % [49] y de 17.8 % a 29.8 % en sector metalmecánica [50].
En la evaluación de la calidad en la atención médica existen varias herramientas, incluyendo los indicadores de calidad (QIs), los cuales proporcionan medidas objetivas basadas en evidencia para evaluar diferentes aspectos críticos del cuidado de manera consistente [51]. Al respecto, la clasificación de errores en laboratorio según su gravedad, es crucial para identificar áreas prioritarias de mejora en la calidad [4], por lo que, el entendimiento de los QIs permite a los laboratorios clínicos identificar las acciones correctivas y mejoras más adecuadas para la resolución de problemas [52]. Los indicadores han sido agrupados en seis etapas del proceso de pruebas de laboratorio: i) orden de la prueba, ii) identificación del paciente y recolección de la muestra, iii) identificación, preparación y transporte de la muestra, iv) análisis, v) informe de resultados, así como vi) interpretación de resultados y acciones posteriores [53]. A pesar de que la implementación sistemática los QIs en laboratorios puede ser efectiva para reducir los errores, mejorar la seguridad del paciente y cumplir con los requisitos de la norma ISO 15189, en la práctica existen dificultades para mantener la recolección de datos de manera estandarizada y sistemática, así como para fomentar un continuo interés, compromiso y dedicación en todo el personal [52]. Al respecto, los resultados de este estudio contribuyen a brindar información sobre la factibilidad detectar desviaciones y evaluar indicadores correspondientes a las primeras etapas (i, ii e iii), con posibilidad de expansión al resto. En este sentido se ha sugerido que los laboratorios deben crear un mapa de proceso que describa todos los pasos del proceso de prueba desde la orden del médico hasta la entrega del resultado [6].
Las herramientas de IA como DL han apoyado en el diagnóstico médico permitiendo reducir el tiempo para iniciar un tratamiento [54], mediante la detección y clasificación del cáncer [55], diagnósticos mediante electrocardiogramas [56], detección de glaucoma [57] o la clasificación de tumores cerebrales [58], lo que permite reducir el tiempo para iniciar un tratamiento [54]. Particularmente, diferentes versiones de YOLO han sido evaluados en contextos variados como el farmacéutico para la detección de defectos en blíster alcanzando una precisión de 0.974 [59], para detectar equipo médico de protección personal logrando un mAP de 97.2 % [60], o para detectar máscaras y tubos de ventilación en pacientes logrando una exactitud (accuracy) de 93 % [61]. Sin embargo, la evidencia es escasa sobre estudios que aborden DL para la evaluación y análisis de actividades de inspección visual en sector salud y particularmente en laboratorios clínicos. El presente estudio contribuye en la discusión sobre el uso de DL como apoyo al técnico flebotomista en la etapa preanalítica. En este sentido, estudios previos han identificado que el uso de IA puede facilitar la colaboración entre especialistas de la salud [62], permitiendo una mejor la utilización de servicios con el fin de optimizar los recursos [63]. Al respecto, es crucial involucrar al equipo del sector de la salud y centrarse en fortalecer las capacidades locales y adaptar la tecnología disponible a las necesidades específicas de los países latinoamericanos [64]. En la región, la IA se encuentra en fase inicial y muchas áreas carecen de la infraestructura necesaria [65]. Sin embargo, tecnologías como la IA tienen el potencial de mejorar el acceso a servicios, reducir consultas innecesarias, brindar comodidad a los usuarios, reducir la carga de trabajo, disminuir costos [66] o incluso disminuir las readmisiones no planificadas [67], lo cual, tiene un efecto directo a la calidad de atención al paciente [68].
Inspección visual y aprendizaje profundo (DL)
Con respecto al desempeño de actividades de inspección visual en laboratorios clínicos, existe poca información sobre el grado de precisión o exactitud de los profesionales de salud. En comparación con actividades de inspección en sectores industriales, comúnmente la inspección visual humana es superada por algoritmos de DL [69] [70], aunque existen excepciones mostrando resultados mixtos o comparables [71] [72] o incluso un rendimiento inferior de los modelos en comparación con los inspectores humanos [73]. El presente estudio destaca una brecha entre la inspección totalmente automatizada y la necesidad continua de participación humana, principalmente en actividades críticas como las asociadas a la salud. En algunos escenarios, los algoritmos comienzan la inspección y los inspectores humanos intervienen en el caso de elementos inciertos o que caen por debajo de un umbral establecido [74] [75]. De esta manera, los modelos de DL tienen el potencial de ayudar de manera consistente a los procesos de inspección al minimizar la participación humana y aliviar la fatiga física y mental. La utilización de algoritmos para detectar objetos empleando redes neuronales convolucionales, como YOLO, ofrece la posibilidad de realizar esta tarea de manera automatizada y eficiente. Adicionalmente, las herramientas de DL presentan la capacidad de identificar objetos que pudieran no ser evidentes a simple vista u omitidos debido a condiciones humanas de error. Considerando que hasta dos tercios de decisiones de los profesionales de salud son basadas en resultados de pruebas de laboratorio [76], DL representa un soporte para los profesionales de la salud y en última instancia, un apoyo para mejorar de la calidad de la atención médica.
Retos Prácticos
Algunos retos identificados incluyen aspectos técnicos para la implementación de sistemas de inspección en laboratorio clínico basados en IA, incluyendo la dependencia al volumen y calidad de conjuntos de datos para su rendimiento [77]. Cuando no se dispone de grandes conjuntos de datos, es necesario realizar un entrenamiento previo [78] o transferencia de aprendizaje [79] como alternativas para trabajar con conjunto de datos pequeños. Otro aspecto y tal vez más relevante es el factor humano, donde la transición de inspección tradicionalmente realizada por un profesional de la salud, a una inspección asistida por tecnología puede representar un reto, principalmente por desconocimiento, falta de infraestructura, resistencia al cambio, entre otros. Adicionalmente, un reto futuro en contextos de laboratorios clínicos es el uso de más arquitecturas de DL, incluyendo modelos de dos etapas como redes neuronales convolucionales basadas en regiones (R-CNN), Fast R-CNN [80], Faster R-CNN [81] y Mask R-CNN [82], que, aunque requieren conjuntos de datos más grandes, pueden aportar una comparativa integral.
Limitaciones
El estudio no está exento de limitaciones, incluyendo el tamaño del conjunto de datos, que puede considerarse pequeño, por lo que un trabajo futuro incluye su ampliación. El estudio consideró una variabilidad limitada en las condiciones del entorno de las imágenes incluyendo la iluminación y los tipos de tubos, por lo que se proyecta ampliar estas características. Adicionalmente, la incorporación de más y diferentes fondos de imagen (background) podrá ayudar a mejorar aún más el desempeño de las arquitecturas evaluadas para detectar objetos con diferentes fondos. Un aspecto importante es el desequilibrio de clases, el cual en este estudio no es un problema crítico, ya que el rango de anotaciones va desde 1,725 a 2,580, como se mostró en Tabla 1, sin embargo, un trabajo futuro será balancear las anotaciones de clase, aumentar el número de imágenes con respecto a las clases a identificar, así como implementar data augmentation para el incremento de imágenes. finalmente, las clases referentes a volumen de sangre, solo consideraron presencia o ausencia de sangre en el tubo, por lo que el siguiente paso será entrenar al modelo en diferentes niveles o cantidades presentes en el tubo.
Conclusiones
El presente estudio abordó el uso de tecnología asociada a inteligencia artificial como lo es deep learning, en la detección de características relevantes al realizar inspecciones en el área de flebotomía de un laboratorio clínico público. Los resultados indican que los modelos YOLO y particularmente YOLOv8 mostraron un buen desempeño en identificar adecuadamente las clases analizadas. Si bien no se cuenta con información sobre el nivel de precisión del personal de salud al realizar actividades de inspección en laboratorios clínicos, estos valores rondan entre 85 y 90 % en otros sectores, por lo que los resultados de este estudio son alentadores y sugieren que los modelos de DL son capaces de detectar características relevantes en la fase preanalítica con una precisión superior. Además, estos resultados abren posibilidades de desarrollo para sistemas de inspección que asistan a los profesionales de salud y complementen la función de inspección que realizan. El estudio brinda información valiosa para futuras investigaciones, incluyendo la inspección de más variables críticas en laboratorios clínicos, la realización de análisis más detallados, así como optimizaciones específicas para cada arquitectura, teniendo en cuenta las necesidades y requisitos específicos del laboratorio clínico. Dada la escasa literatura sobre aplicaciones específicas de DL en el llenado e identificación de muestras de sangre en laboratorios clínicos, los hallazgos respaldan el potencial de estas herramientas para asistir a los profesionales de salud en actividades de inspección visual y con ello contribuir a la mejora de los servicios de salud.
Declaración ética
El presente trabajo no involucró la participación de seres humanos ni animales. Por lo tanto, no se requirió el consentimiento informado de personas. El protocolo de investigación fue debidamente registrado ante el Instituto de Servicios de Salud Pública del Estado de Baja California.
Contribución de los autores
I. F.-A. conceptualización, curación de datos, análisis formal y escritura de manuscrito original; J. A.-D. conceptualización, análisis formal, escritura de manuscrito original y revisión final; Y. B.-L. investigación, metodología, administración de proyecto y validación; J. L.-R. curación de datos, software, validación y revisión final; M. M. S.-Q. investigación, visualización y administración de proyecto; D. T. conceptualización, análisis formal, supervisión, escritura de manuscrito original y revisión final.

