










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkSalud Pública de México
versión impresa ISSN 0036-3634
Salud pública Méx vol.55 no.3 Cuernavaca may./jun. 2013
ARTÍCULO ESPECIAL
Análisis retrospectivo de la Encuesta Nacional de Adicciones 2008. Identificación y corrección de sesgo
Retrospective analysis of Mexican National Addictions Survey, 2008. Bias identification and correction
Martín Romero-Martínez, PhD; Martha María Téllez-Rojo Solís, D en C; América Andrea Sandoval-Zárate, Act; Juan Manuel Zurita-Luna, Act; Juan Pablo Gutiérrez-Reyes, PhD.
Centro de Investigación en Evaluación y Encuestas, Instituto Nacional de Salud Pública. Cuernavaca, Morelos, México
RESUMEN
OBJETIVO: Investigar la existencia de sesgo en la estimación de las prevalencias de consumo "alguna vez" en la vida de alcohol, tabaco y drogas ilegales e inhalables, para luego proponer una corrección al mismo, si existiera.
MATERIAL Y MÉTODOS: Se analizaron las Encuestas Nacionales de Adicciones (ENA) 2002, 2008 y 2011 para comparar estimaciones de parámetros poblacionales sobre el consumo "alguna vez" en la vida de tabaco, alcohol y drogas ilegales e inhalables. Se desarrollaron dos métodos para corregir el sesgo.
RESULTADOS: Las prevalencias nacionales estimadas de consumo "alguna vez" de alcohol y tabaco de la ENA 2008 no son plausibles. En contraste, no se encontró evidencia que apoyara un subregistro o sobrerregistro del consumo "alguna vez" de drogas ilegales e inhalables. Se obtuvieron nuevas estimaciones de las prevalencias de consumo "alguna vez" de alcohol y tabaco; las nuevas estimaciones resultaron ser plausibles al contrastarse con otras fuentes de información disponibles.
CONCLUSIONES: Los nuevos análisis sobre alcohol y tabaco que se realicen deberán usar los factores de expansión corregidos de la ENA 2008 para poder incorporar las nuevas estimaciones de consumo "alguna vez" de alcohol y tabaco obtenidas en este trabajo.
Palabras clave: encuestas epidemiológicas; adicciones; sesgo; México
ABSTRACT
OBJECTIVE: To determine the presence of bias on the estimation of the consumption sometime in life of alcohol, tobacco or illegal drugs and inhalable substances, and to propose a correction for this in the case it is present.
MATERIALS AND METHODS: Mexican National Addictions Surveys (NAS) 2002, 2008, and 2011 were analyzed to compare population estimations of consumption sometime in life of tobacco, alcohol or illegal drugs and inhalable substances. A couple of alternative approaches for bias correction were developed.
RESULTS: Estimated national prevalences of consumption sometime in life of alcohol and tobacco in the NAS 2008 are not plausible. There was no evidence of bias on the consumption sometime in life of illegal drugs and inhalable substances. New estimations for tobacco and alcohol consumption sometime in life were made, which resulted in plausible values when compared to other data available.
CONCLUSION: Future analyses regarding tobacco and alcohol using NAS 2008 data will have to rely on these newly generated data weights, that are able to reproduce the new (plausible) estimations.
Key words: health surveys; addictions; bias; Mexico
Las Encuestas Nacionales de Adicciones (ENA) en México han buscado generar evidencia que permita definir políticas y estrategias para afrontar el reto del consumo de sustancias adictivas. Realizadas desde 1988, estas herramientas han trazado los cambios en el consumo de alcohol, tabaco y drogas ilegales e inhalables en adolescentes y adultos mexicanos.1-5 Las drogas ilegales consideradas fueron: mariguana, cocaína, crack, alucinógenos, heroína, anfetaminas y otras drogas como Ketanina, GHB. Por otra parte, se aclara que en este texto el término "drogas ilegales" describe las drogas ilegales e inhalables.
Las ENA tienen como objetivo central estimar las prevalencias de consumo de drogas ilegales, alcohol y tabaco, a la vez que estudiar la cobertura de las estrategias preventivas y de los servicios de atención a la población consumidora de sustancias adictivas. Tienen retos importantes para asegurar que la información que generarán represente sin sesgo a la población sobre la que se busca generar inferencias.
Desde el ámbito metodológico, el diseño de los instrumentos de captación de información, la selección de la muestra, la respuesta de la población, la aplicación de los instrumentos y la captación de las respuestas de los informantes son elementos que pueden afectar los resultados que se generan en una encuesta. Del lado de los informantes, las temáticas de las encuestas pueden inhibir la respuesta, causando subreporte de comportamientos que se perciben como socialmente no deseables, o bien, el sobrerreporte de los deseables. En lo particular, el estudio de las adicciones a través de una encuesta en hogares tiene el reto de obtener un reporte preciso del consumo de drogas ilegales, e incluso de alcohol y tabaco, pues su consumo en exceso no es socialmente deseable. Los retos mencionados hacen necesaria la revisión de las cifras que reportan las ENA, para asegurar que la evidencia que se entrega sea lo más cercana posible a la realidad.6
Un indicador para monitorear la validez de la información que se genera en encuestas sobre consumo de sustancias adictivas es la prevalencia1 de consumo "alguna vez en la vida en población de entre 12 y 65 años que habitan en viviendas particulares al momento de realizar la encuesta". Dicha prevalencia tiene la propiedad de que en poblaciones estáticas‡ debe incrementarse en el tiempo, ya que una vez que una persona ha consumido alguna sustancia, no pierde tal condición durante su vida. Por otra parte, en poblaciones no estáticas es posible que la prevalencia de consumo alguna vez disminuya, por ejemplo, cuando los inmigrantes son no consumidores y son más, en términos numéricos, a los nuevos casos de consumidores.
Al comparar las prevalencias estimadas de consumo "alguna vez" en personas de entre 12 y 65 años en las ENA 2002, 2008 y 2011, se observa un descenso significativo en el consumo de tabaco y alcohol entre 2002 y 2008 (después de considerar los intervalos de confianza), fenómeno que no se observa en el consumo de drogas ilegales (cuadro I).

El descenso de las prevalencias de consumo "alguna vez" de tabaco y alcohol entre 2002 y 2008 resulta inesperado por la razón expuesta, y lleva a suponer la existencia de un posible sesgo de la ENA 2008 en la estimación de consumo de alcohol y tabaco. En contraste, no se observa tal decremento en el consumo "alguna vez" de drogas ilegales.
El objetivo de este artículo es investigar la existencia de sesgo en las estimaciones de consumo de tabaco, alcohol y drogas ilegales en la ENA 2008 y proponer un mecanismo para tratar de corregirlo en caso de ser necesario.
Material y métodos
Se analizan las encuestas ENA 2002, 2008 y 2011 y ENSANUT 2012. El diseño metodológico de las encuestas se reporta en otros documentos.1-5,2 Pero, en síntesis, todas las encuestas analizadas son encuestas probabilísticas con muestreos polietápicos, estratificados y que tienen como universo de estudio a la población de entre 12 y 65 años en México. Las encuestas 2008 y 2011 cuentan con representatividad nacional y regional; adicionalmente, la ENA 2008 y la ENSANUT 2010 tienen representatividad estatal. El número de cuestionarios completos de las ENA fue 16 249 individuos en 2011, 51 227 en 2008 y 11 225 en 2002; por otra parte, la ENSANUT tuvo 56 911 cuestionarios completos de personas de 12 a 65 años. Las preguntas de las encuestas de adicciones usadas para captar el consumo "alguna vez" son básicamente las mismas: a) ¿ha fumado tabaco alguna vez en la vida aunque sea una sola fumada?; b) ¿ha consumido alguna vez cualquier bebida que contenga alcohol?; c) ¿me podría decir si ha tomado, usado, probado (inicie con la primer droga)? Por otra parte, la ENSANUT 2012 usa las preguntas: a) ¿has fumado por lo menos 100 cigarrillos (5 cajetillas) de tabaco durante toda tu vida?; b) ¿qué edad tenías la primera vez que tomaste una bebida alcohólica en tu vida? En la ENSANUT 2012 no se pregunta por consumo de drogas y en las opciones de respuesta se incluye "nunca he tomado" y "nunca he fumado". Se incluyó la ENSANUT 2012 en el análisis porque, además de que ésta y la ENA 2011 son muy cercanas en el tiempo, ambas tuvieron estimaciones que fueron razonablemente cercanas, a pesar de que las preguntas no son exactamente iguales. La ENSANUT 2012 estimó las prevalencias de consumo "alguna vez" (tabaco= 48.1%, alcohol= 70.9%), mientras que las estimaciones nacionales de la ENA 2011 fueron (tabaco= 47.0%, alcohol= 75.0%).
En las ENA 2002, 2008 y 2011, se recolectó la información utilizando como instrumento la entrevista cara a cara, en las dos últimas se capturaron las respuestas en computadoras.
Razonamiento de Occam
El procedimiento que se sigue para argumentar la existencia de sesgos será el razonamiento de Occam:7 cuando dos teorías compiten por explicar un hecho y las dos teorías hacen las mismas predicciones, entonces la teoría más simple es la mejor; esto es, la explicación de los hechos no debe ser más complicada de lo necesario. Por ejemplo, si los estimadores de tres encuestas (A, B, C) son  y el intervalo de confianza de la encuesta B no se intersecta con los intervalos de confianza de las encuestas A y C, se pueden plantear dos hipótesis. La primera, diría que el parámetro vale 1 y que ocurrió algo extraordinario en la encuesta B, y la segunda diría que el parámetro vale 4 y ocurrió algo extraordinario en A y C. Luego, dado que la segunda hipótesis es más compleja porque supone dos eventos extraordinarios, se favorece a la primera.
y el intervalo de confianza de la encuesta B no se intersecta con los intervalos de confianza de las encuestas A y C, se pueden plantear dos hipótesis. La primera, diría que el parámetro vale 1 y que ocurrió algo extraordinario en la encuesta B, y la segunda diría que el parámetro vale 4 y ocurrió algo extraordinario en A y C. Luego, dado que la segunda hipótesis es más compleja porque supone dos eventos extraordinarios, se favorece a la primera.
Análisis temporal
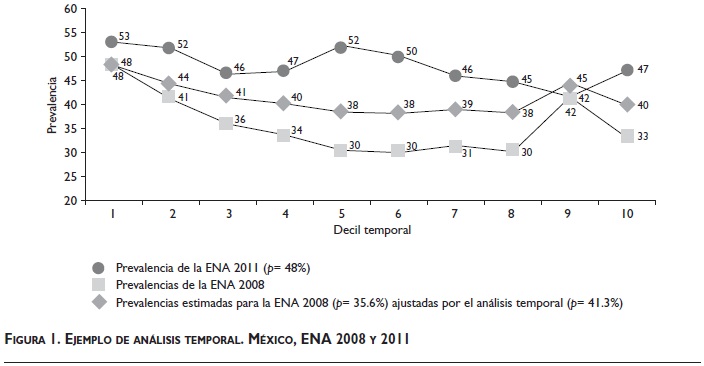
Se usan dos procedimientos para tratar de corregir el sesgo. El primero se denomina análisis temporal, el cual analiza las prevalencias en p cuantiles temporales (prevalencias temporales); los cuantiles temporales son p grupos de cuestionarios tales que: a) los cuestionarios de cada cuantil temporal son contiguos en el tiempo; y b) cada cuantil temporal expande a un pésimo del total de la población. El análisis temporal consiste en igualar la variabilidad de las prevalencias temporales estatales estimadas por la ENA 2008 con la variabilidad de las prevalencias temporales regionales estimadas por la encuesta de 2011. La idea del procedimiento es que si hubiera un descenso en las prevalencias a través del tiempo, el descenso observado en 2011 debería replicarse en las estimaciones corregidas de la ENA 2008. Para ello, se estima a la prevalencia estatal en el quintil temporal t, P(t), por P*(t) = P(1) - Rv( P(1)- P(t) ), donde P*(t) es la prevalencia estatal ajustada en el quintil temporal t y Rv es tal que el mínimo t{ P*(t)/P*(1) } es igual al mínimo t{ Q(t)/Q(1) } donde Q(t) es la prevalencia regional en el quintil t de la ENA 2011. El valor de Rv se determinó para cada estado y sustancia (alcohol, tabaco). Finalmente, la prevalencia estatal corregida se obtiene al ponderar los valores P*(t). La figura 1 muestra un ejemplo de aplicación del análisis temporal para ajustar la prevalencia nacional de "consumo alguna vez" de tabaco usando deciles (figura 1).
Análisis basado en el modelo de regresión
El segundo procedimiento que trata de corregir el sesgo se deriva de un modelo de regresión. Se ejemplifica con un caso en que la población es estática y en que el porcentaje de personas que consumen por primera vez alguna sustancia adictiva es constante en el tiempo, esto es pt= p0 + tδa, donde pt es la prevalencia de consumo "alguna vez" a tiempo t, po es la prevalencia a tiempo 0 y δa es el porcentaje de incremento de consumidores "alguna vez" por unidad de tiempo; entonces, se ajusta el modelo pt= po + tδa, + e, donde e representa la variabilidad no explicada por pt= p0 + tδa. Desafortunadamente, las prevalencias pt, po son observadas con error porque son estimadas mediante encuestas, entonces, pt= po + tδa + e, puede ser complementada con las ecuaciones  , donde u y v representan respectivamente, los errores de estimación en los tiempos 0 y t; así, el modelo final es el modelo de regresión:
, donde u y v representan respectivamente, los errores de estimación en los tiempos 0 y t; así, el modelo final es el modelo de regresión:  .
.
Una vez derivado el modelo de regresión (1), en seguida se describe cómo fue usado para estimar las prevalencias estatales de consumo "alguna vez" em 2008. Primero, δa fue estimado por  , donde
, donde  es el tiempo transcurrido entre el levantamiento de las ENA 2002 y 2011. Luego, se obtuvieron estimaciones estatales usando:
es el tiempo transcurrido entre el levantamiento de las ENA 2002 y 2011. Luego, se obtuvieron estimaciones estatales usando:

donde  se eligió como un promedio de la estimación de las prevalencias estatales de consumo "alguna vez" de la ENA 2011 y la ENSANUT 2012:
se eligió como un promedio de la estimación de las prevalencias estatales de consumo "alguna vez" de la ENA 2011 y la ENSANUT 2012:

Donde  son respectivamente las prevalencias estatales estimadas por la ENA 2011 y la ENSANUT 2012 para el estado i; de modo similar n 2011(i) y n2012(i) son el número de entrevistas completas; además,
son respectivamente las prevalencias estatales estimadas por la ENA 2011 y la ENSANUT 2012 para el estado i; de modo similar n 2011(i) y n2012(i) son el número de entrevistas completas; además,  es el cociente entre las estimaciones nacionales de estas dos encuestas. El valor de K se usó para descontar cualquier diferencia sistemática que hubiera; por ejemplo: los cuestionarios o un incremento del consumo. se eligió como un promedio de las estimaciones de la ENA 2011 y ENSANUT 2012 por dos razones: el tamaño de muestra de la segunda se determinó para hacer inferencias en el ámbito estatal y para obtener estimaciones con el mayor número de casos.
es el cociente entre las estimaciones nacionales de estas dos encuestas. El valor de K se usó para descontar cualquier diferencia sistemática que hubiera; por ejemplo: los cuestionarios o un incremento del consumo. se eligió como un promedio de las estimaciones de la ENA 2011 y ENSANUT 2012 por dos razones: el tamaño de muestra de la segunda se determinó para hacer inferencias en el ámbito estatal y para obtener estimaciones con el mayor número de casos.
Evaluación de estimaciones
Para motivar el criterio de evaluación se considera una situación similar. Sean tres ciudades A, B y C las cuales se encuentran en ese orden sobre un camino. En el caso en que la estimación inicial de la distancia de A a C es 1; luego, si se sabe que B se encuentra entre A y C, entonces, resulta natural esperar que la distancia estimada de A a B sea menor que 1. En el caso que se expone aquí, bajo el supuesto de que las prevalencias de consumo "alguna vez" no debieran decrecer con el tiempo, las estimaciones que tratan de corregir el sesgo de 2008 deberían no ser mayores que las prevalencias estatales estimadas por la ENA 2011, y no menores que las prevalencias estimadas por la de 2002. Las estimaciones que no satisfacen el criterio descrito se denominan estimaciones inesperadas.
Construcción de ponderadores
Después de obtener las estimaciones estatales, ya sea por el análisis temporal o por el modelo de regresión, se construyó un nuevo conjunto de ponderadores que permite replicar, a partir de la base de datos de la ENA 2008, las nuevas estimaciones de las prevalencias de "consumo alguna vez"8 para alcohol y tabaco. Las estimaciones de consumo alguna vez de drogas ilegales no cambian con los nuevos ponderadores.
Resultados
Probabilidades condicionales de consumo de alcohol
Las encuestas de adicciones primero preguntan por el consumo de tabaco y luego por el consumo de alcohol. Entonces, se analizará la estabilidad de la estimación de la probabilidad de consumo de alcohol condicionado en el no consumo de tabaco.
P=Probabilidad (Sí se consumió alguna vez alcohol | No se consumió alguna vez tabaco).
La figura 2 muestra que el consumo de alcohol es estimado de manera similar en las ENA 2002 y 2011. Entonces pueden plantearse dos hipótesis: a) el valor de p es cercano al estimado por ambas encuestas y ocurrió algo extraordinario (se observó un valor alejado de su media supuesta) en 2008, o b) el valor de p es cercano al estimado por la ENA 2008 y ocurrió algo extraordinario en 2002 y 2011. Se considera la segunda hipótesis como la más compleja porque implica dos eventos extraordinarios asociados a cambios opuestos en las estimaciones, primero decrece el consumo entre 2002 y 2008 y luego crece entre 2008 y 2011 en la misma magnitud que decreció. Entonces, siguiendo el razonamiento de Occam, la figura 2 aporta evidencia de que en la ENA 2008 ocurrió algo extraordinario y que el valor de p es cercano al estimado por las de 2002 y 2011.

Análisis de cohortes de consumidores de alcohol, tabaco y drogas ilegales e inhalables
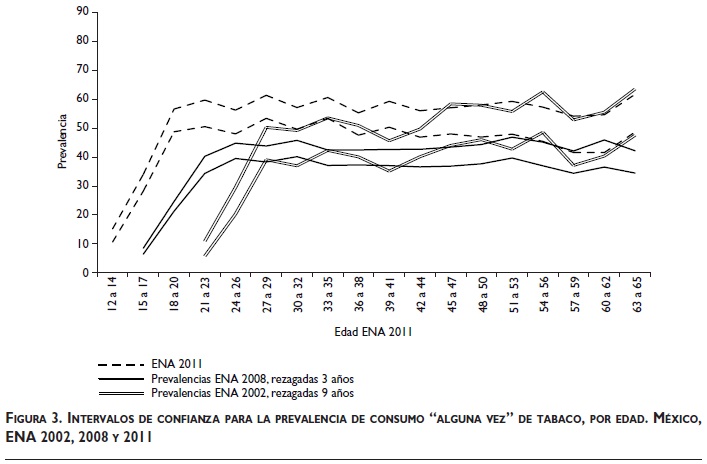
El análisis de cohortes compara las prevalencias de consumo "alguna vez" para grupos poblacionales definidos por su fecha de nacimiento;9 esto es, las cohortes que se analizarán serán conjuntos de individuos que nacieron en un mismo periodo de tiempo. La figura 3 compara los intervalos de 95% de confianza (IC95%) para la prevalencia de consumo "alguna vez" de tabaco para personas: con edad x en 2011, con edad x-3 en 2008 y con edad x-9 en 2002. Por ejemplo, si x="21 a 23", en la gráfica 1, se deduce que el IC95% de la prevalencia de consumo "alguna vez" de tabaco en personas con edad "21 a 23" no se intersecta con el IC95% de la prevalencia de ese mismo grupo de personas cuando tenían edad x-3 = "17 a 20" en 2008. En virtud de que el análisis de cohortes compara las prevalencias de consumo "alguna vez" para grupos poblacionales definidos por su fecha de nacimiento, también es de esperarse que la prevalencia de dicho consumo aumente con el tiempo;3 esto es, tales prevalencias de consumo en 2002 deberían ser menores a las de 2008, y éstas, a su vez, deberían ser menores a las prevalencias de consumo "alguna vez" en 2011.
Las figuras 3 y 4 sugieren que en las cohortes poblacionales la prevalencia de consumo "alguna vez" de alcohol y tabaco decreció entre 2002 y 2008 para luego volver a crecer entre 2008 y 2012, ya que los IC95% de las ENA 2002 y 2008 no se intersectan y las estimaciones por grupo de edad en la de 2011 son mayores a las estimaciones de 2008. Entonces, se pueden plantear dos hipótesis: a) no ocurrió algún evento extraordinario en la muestra pero sí en la población de 2008, pues se observa  aunque θ2008< θ2002< θ2011, o b) ocurrió algo extraordinario en la encuesta de 2008 porque se observa aunque θ2008< θ2002< θ2011. En este caso, la hipótesis más complicada es la hipótesis primera, pues supone que entre 2002 y 2008 la prevalencia de consumo "alguna vez" de alcohol y tabaco decreció, para luego aumentar entre 2008 y 2011.
aunque θ2008< θ2002< θ2011, o b) ocurrió algo extraordinario en la encuesta de 2008 porque se observa aunque θ2008< θ2002< θ2011. En este caso, la hipótesis más complicada es la hipótesis primera, pues supone que entre 2002 y 2008 la prevalencia de consumo "alguna vez" de alcohol y tabaco decreció, para luego aumentar entre 2008 y 2011.
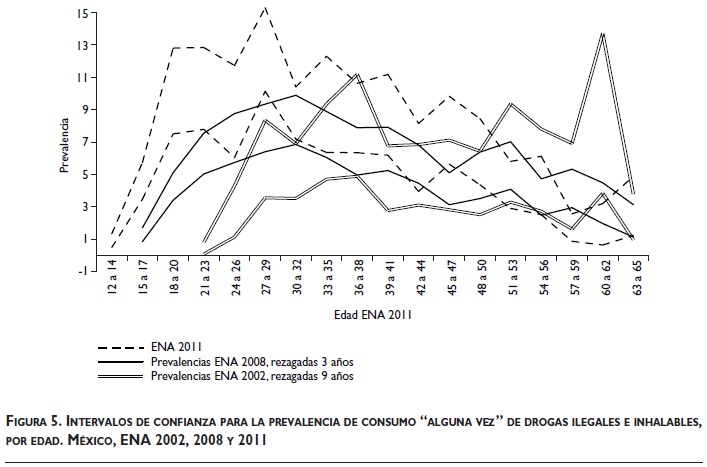
Adicionalmente, puede argumentarse que los incrementos casi uniformes para personas con edad de 30 años o más son poco verosímiles, pues en general (como lo muestran las figuras 3 y 4, para las ENA 2002 y 2008), el incremento en consumo "alguna vez" es marginal para las personas con edad de 40 años o más.
Entonces, las figuras 3 y 4 aportan evidencia de que existe un sesgo en la estimación del consumo "alguna vez" de alcohol y tabaco en la ENA 2008. En contraste, la figura 5 aporta evidencia de que no hubo sesgo en la estimación del consumo "alguna vez" de drogas ilegales e inhalables.
Resultados del análisis temporal
Se calculó el índice RV definido como el cociente entre la prevalencia temporal mínima y la prevalencia en el primer cuantil temporal.

Por ejemplo, si las prevalencias temporales son (0.5, 0.4, 0.3, 0.2, 0.4), el valor de RV es 0.2/0.5= 0.4. RV mide el descenso de las prevalencias de consumo "alguna vez" durante el levantamiento con respecto a las prevalencias estimadas al inicio del desarrollo de la encuesta; valores menores de RV indican mayores descensos en las prevalencias temporales. RV se definió para cuantificar los patrones observados en la figura 1, donde las prevalencias de consumo más altas se observan al inicio del levantamiento. En los cuadros II y III se presentan los valores de RV en las ENA 2008 y 2011 para subpoblaciones definidas por sexo y edad.


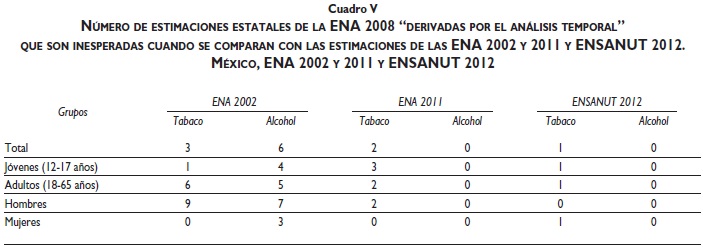
Los cuadros II y III muestran que la variabilidad de las prevalencias temporales fue mayor en la ENA 2008 que en la 2011 porque el cociente RV (ENA 2008) / RV (ENA 2011) es menor que uno en todos los grupos de edad, hombres y mujeres. Por otra parte, al graficar las prevalencias temporales usadas para calcular los cuadros II y III se observan patrones similares al observado en la figura 1: la primer prevalencia temporal, p(1), es similar para las ENA 2008 y la 2011, luego, se observa un descenso mayor de las prevalencias temporales para la de 2008. Entonces, dado que RV (ENA 2008) / RV (ENA 2011) es menor que uno en todos los grupos de edad, hombres y mujeres, y considerando que el análisis de las probabilidades condicionales y el análisis de cohortes sugirieron que algo extraordinario ocurrió en la ENA 2008, entonces se decidió obtener nuevas estimaciones de las prevalencias de consumo "alguna vez" de alcohol y tabaco usando el análisis de las prevalencias temporales. Las nuevas estimaciones nacionales de prevalencia de dicho consumo resultaron ser: alcohol= 61.3%, tabaco= 40.5%. Adicionalmente, se contabilizó el número de estimaciones estatales "inesperadas" de acuerdo con el criterio de validación descrito en la sección de métodos (cuadro V), y con el fin de evaluar la mejora de las estimaciones estatales, el cuadro IV presenta las estimaciones estatales ENA 2008 que resultan inesperadas.
Resultados del modelo de regresión
Se estimó el modelo de regresión descrito en (1), las tasas de crecimiento anual que se obtuvieron fueron las del cuadro VI.
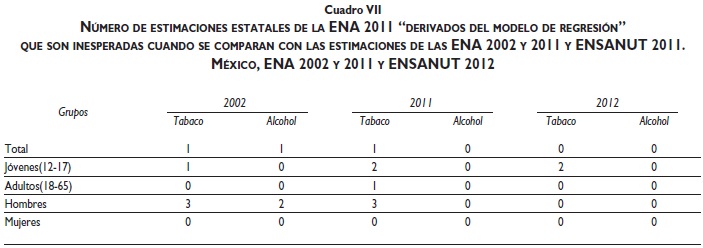
Se obtuvieron nuevas estimaciones nacionales de prevalencia de consumo "alguna vez" (alcohol=68.5%, tabaco = 45.5%) y también se contabilizó el número de estimaciones estatales inesperadas (cuadro VII).
Comparación de resultados
El mayor número de estimaciones inesperadas (suma de valores en el cuadro IV) ocurre para las estimaciones obtenidas por la ENA 2008 (110 inconsistencias). Por otra parte, el ajuste de las estimaciones de esta encuesta mediante el análisis temporal reduce de modo significativo el número de estimaciones inesperadas (el número total de inconsistencias va de 110 a 57). Finalmente, las estimaciones de la ENA 2008 derivadas del modelo de regresión son las estimaciones con el menor número de estimaciones inesperadas (17 en total). No obstante, este resultado es en todo caso esperado, porque el modelo de regresión supone que las prevalencias de consumo "alguna vez" se incrementan en el tiempo, supuesto que no es necesario en el análisis temporal.
Discusión
Al contrastar la ENA 2008 con dos fuentes de información independientes, ENA 2002 y 2011, surgió evidencia que sugiere que la de 2008 subestimó el consumo "alguna vez" de tabaco y alcohol. Entonces, la primera conclusión que se obtiene es que en ésta existe sesgo en las estimaciones de dicho consumo; afirmar la hipótesis alternativa de que no tiene este sesgo obligaría a encontrar dos explicaciones diferentes para justificar las discrepancias observadas en la ENA 2008 con las fuentes de información mencionadas.4 Luego, aplicando el principio de Occam, se concluye que la hipótesis más verosímil es la existencia de un sesgo en la estimación de consumo "alguna vez" de alcohol y tabaco en los resultados de 2008. En contraste, no se encontró evidencia que apoyara un subregistro del consumo "alguna vez" de drogas ilegales.
Las causas del sesgo pueden ser diversas, sin embargo, al considerarse que el instrumento de recolección de información se ha mantenido relativamente constante, que el marco de muestreo es de referencia nacional, que se ha documentado la tasa de respuesta y que los sistemas de digitación de datos fueron revisados, la incertidumbre mayor recae en la aplicación de los cuestionarios. Incertidumbre que puede explicarse porque al analizar las diferencias operativas de la supervisión de la aplicación de los instrumentos, se encontró que el esquema de supervisión de la ENA 2011 abarcó hasta cuatro niveles: la supervisión directa del equipo de campo, la supervisión centralizada e independiente al equipo de campo, una supervisión por parte del equipo conceptual y finalmente el seguimiento en línea de forma diaria de indicadores de consumo. En contraste, en la ENA 2008 sólo existieron dos niveles de supervisión y no se contó con el sistema de seguimiento en línea, aunque se monitorearon de modo sistemático las estimaciones de consumo de drogas ilegales.
La corrección del sesgo de un estimador es un problemaestadístico donde se tiene evidencia de que el valor esperado de un estimador  es diferente del parámetro a estimar; esto es, E≠ θ; entonces la tarea de tratar de corregir el sesgo se reduce a proponer un nuevo estimador . Luego, no hay un solo camino a seguir, sino tantos caminos como hipótesis de trabajo sustentables se puedan proponer. En este caso, se han propuesto dos caminos, que han llevado a asumir dos hipótesis.
es diferente del parámetro a estimar; esto es, E≠ θ; entonces la tarea de tratar de corregir el sesgo se reduce a proponer un nuevo estimador . Luego, no hay un solo camino a seguir, sino tantos caminos como hipótesis de trabajo sustentables se puedan proponer. En este caso, se han propuesto dos caminos, que han llevado a asumir dos hipótesis.
La hipótesis del análisis temporal es que la variabilidad (medida por Rv) de las prevalencias estimadas para los cuantiles temporales de la ENA 2008 debió ser similar a la variabilidad de la de 2011; supuesto que no se puede sustentar de forma general porque la variabilidad de las prevalencias temporales depende del orden en que se programa el trabajo de campo. Pero, dadas las enormes diferencias en variabilidad entre ambas encuestas, aun el cumplimiento parcial de este supuesto propicia que las estimaciones derivadas del análisis temporal sean mayores a las estimaciones de la ENA 2008; hecho que lleva a obtener menos estimaciones estatales inesperadas que las obtenidas a partir de estos resultados de 2008.
En contraste, las hipótesis del modelo de regresión son que: a) las estimaciones de las encuestas ENA 2002 y 2011 y ENSANUT 2012 no tienen un sesgo sistemático, y b) el modelo de regresión es una buena aproximación a la manera en que evolucionaron en el tiempo las prevalencias de consumo "alguna vez". En este caso, siempre se puede argumentar que el modelo de regresión puede considerarse una buena primera aproximación, pero no se presentó evidencia de cuán buena es la aproximación; también, se puede argumentar que la ENA 2011 y la ENSANUT 2012 no tienen sesgos sistemáticos, pues tabulados presentados en un reporte más extenso de este trabajo así lo sugieren.
Respecto a cuál de las dos estimaciones debería usarse, la respuesta no es fácil ya que cualquier opción que se elija (análisis temporal, modelo de regresión) va a depender de supuestos que se deberán asumir. Pero se decidió usar las estimaciones derivadas del modelo temporal debido a tres razones: primero, las estimaciones derivadas del análisis temporal dependen únicamente de la ENA 2008, de la cual sólo se requiere una hipótesis sobre la variabilidad de las prevalencias temporales; segundo, se reduce de modo significativo el número de estimaciones inesperadas (de 110 a 57), y tercero, las estimaciones del modelo de regresión quedan fuertemente condicionadas por los resultados de las ENA 2002 y 2011, condición contraria al espíritu con el que se realizó la de 2008, pues lo que busca una encuesta es justamente identificar la situación del momento en que se realiza; entonces, al utilizar la mínima información (con el análisis temporal) se busca generar estimaciones que dependan del mínimo de hipótesis.
La corrección del sesgo en las prevalencias de consumo "alguna vez" genera también correcciones en otros parámetros, como se argumenta enseguida. Con el fin de mantener una conversación lógica con el entrevistado, primero se pregunta por el consumo "alguna vez", para luego hacer las preguntas sobre consumo reciente y frecuencia de consumo. Así, θA si es la proporción de personas que han consumido "alguna vez" alcohol y θU|A representa la proporción de personas que reportan haber consumido alcohol en el último año después de haber respondido que han consumido alcohol "alguna vez", entonces la proporción de personas que han consumido alcohol "alguna vez" puede ser estimada por θAθU|A, en consecuencia la existencia o corrección de sesgo en la estimación de θA tiene efectos inmediatos en la estimación de θAθU|A y en cualquier otra pregunta de las secciones de alcohol. Desafortunadamente, las correcciones que se propusieron para el sesgo de θA no pueden corregir los sesgos que hubiera en θU|A. En consecuencia, si hubiera sesgos en las prevalencias condicionales, (θU|A) deberán hacerse análisis adicionales.
Finalmente, para el análisis de la ENA 2008, el resultado final de este artículo implica que deberá usarse el nuevo conjunto de ponderadores cuando se necesite obtener estimaciones sobre el consumo de alcohol y tabaco.
Agradecimientos
Los autores reconocen las invaluables aportaciones de los doctores María Elena Medina Mora, Mauricio Hernández Ávila, Eduardo Lazcano Ponce, Luz Myriam Reynales Shigematsu y del Lic. Jorge Villatoro Velázquez, quienes contribuyeron en las discusiones que permitieron la identificación del sesgo y la corrección del mismo, además de proponer algunos de los análisis realizados en el artículo. Asimismo, se agradecen los comentarios emitidos por el doctor Ignacio Méndez, por los maestros Edmundo Berumen y Roy Campos, quienes revisaron una versión preliminar del abordaje metodológico seguido para este documento.
Referencias
1. Consejo Nacional Contra las Adicciones, Instituto Nacional de Psiquiatría Ramón de la Fuente Muñiz, Dirección General de Epidemiología, Instituto Nacional de Estadística Geografía e Informática. Encuesta nacional de adicciones 2002. Aguascalientes, Ags.: INEGI, 2004. [ Links ]
2. Consejo Nacional Contra las Adicciones, Instituto Nacional de Psiquiatría Ramón de la Fuente Muñiz, Instituto Nacional de Salud Pública, Secretaría de Salud, Fundación Gonzalo Río Arronte. Encuesta nacional de adicciones 2008. Cuernavaca, México: INSP, 2009 [ Links ]
3. Villatoro-Velázquez JA, Medina-Mora ME, Fleiz-Bautista C, Téllez-Rojo MM, Mendoza-Alvarado LR, Romero-Martínez M et al. Encuesta nacional de adicciones 2011. Reporte de drogas. México: INPRFM, 2012. [ Links ]
4. Reynales-Shigematsu LM, Guerrero-López CM, Lazcano-Ponce E, Villatoro-Velázquez JA, Medina-Mora ME, Fleiz-Bautista C et al. Secretaría de Salud. Encuesta nacional de adicciones 2011. Reporte de tabaco. México: INPRFM, 2012. [ Links ]
5. Medina-Mora ME, Villatoro-Velázquez JA, Fleiz-Bautista C, Téllez-Rojo MM, Mendoza-Alvarado LR, Romero-Martínez M et al. Encuesta nacional de adicciones 2011. Reporte de alcohol. México: INPRFM, 2012. [ Links ]
6. Groves RM. Survey errors and surveys costs. Hoboken, New Jersey: Wiley, 1989. [ Links ]
7. Jeffreys WH, Berger JO. Sharpening Ockham razor on a Bayes strop. West Lafayette, EUA: Purdue University, agosto de 1991, 13 pp. Reporte técnico 91-44C. [ Links ]
8. Deming WE, Stephan FF. On a least squares adjustment of a sampled frequency table when the expected marginal totals are known. Annals of Mathematical Statistics 1940;11(4):427-444. [ Links ]
9. Glenn ND. Cohort analysis. Thousand Oaks, California: SAGE, 2005. [ Links ]
 Autor de correspondencia:
Autor de correspondencia:
Dr. Juan Pablo Gutiérrez Reyes
Instituto Nacional de Salud Pública
Centro de Investigación en Evaluación y Encuestas
Av. Universidad 655, col. Santa María Ahuacatitlán
62100 Cuernavaca, Morelos, México
Correo electrónico: jpgutier@insp.mx
Fecha de recibido: 17 de abril de 2013
Fecha de aceptado: 30 de abril de 2013
‡ Se entiende como aquella sin migración, nacimientos, fallecimientos o exclusiones por edad.
1 Se define como el cociente entre el total de habitantes de 12 a 65 años y el número de habitantes 12 a 65 años que han consumido alguna vez en la vida alcohol, tabaco, o drogas ilegales.
2 Romero-Martínez M, Shamah-Levy T, Franco-Núñez A, Villalpando S, Cuevas-Nasu, Rivera-Dommarco J, Gutiérrez JP. Encuesta nacional de salud y nutrición 2012. Diseño y cobertura. Salud Publica Mex 2012. En prensa.
3 Aunque es posible que en un año no existan nuevos casos de consumidores, en el caso de alcohol y tabaco en el ámbito nacional, la no adición de nuevos consumidores en un año es un evento no verosímil.
4 Por ejemplo, se tendría que suponer conjuntamente que: a) es plausible que las prevalencias de consumo alguna vez decrezcan mientras las ventas de cerveza aumentan; b) que las estimaciones de sesgo obtenidas de la encuesta de supervisión son equivocadas; c) que la prevalencia de consumo "alguna vez" se mantuvo constante en el periodo 1998-2002, luego decreció significativamente entre 2002 y 2008 y finalmente aumentó entre 2008 y 2011.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}