











 nova página do texto(beta)
nova página do texto(beta) Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink1 Introduction
With the increasing usage of social media like Twitter, there is an increasing opinion available on the social media. Mining such opinions has become a greater interest for the scientific and industrial community. In present times, sentiment analysis has found huge number of applications. For example, it can be used as a sub-module for systems like customer relationship management (CRM) and recommendation engines.
Sentiment analysis [3] is a branch of affective computing research [18] that aims to classify text (but sometimes also audio and video [21]) into positive, negative, and neutral. Sentiment analysis systems can be largely categorized as knowledge-based [5], statistics-based [16], and hybrid [4]. While most works approach tries solving sentiment analysis as a simple categorization problem, it is actually a ”suitcase” of research problem consisting of many NLP sub-problems to be solved, including named entity recognition [13], word polarity disambiguation [25], temporal tagging [27], personality recognition [14], sarcasm detection [20], and subjectivity detection.
Subjectivity detection, in particular, has become important in recent years, as the exponential growth of social media data is generating a greater and greater need for filtering out objective data (facts) from subjective data (opinions). Subjectivity detection can be more challenging than polarity detection (positive-versus-negative classification) but it has been under-investigated due to the assumption that most social data were considered subjective. This research gap comes as a surprise, given that the Web has transformed into a dynamic and evolving network enabling users to be the media themselves. Bearing in mind the current pace of these social data generation, filtering out neutral data is taking priority over processing opinionated data.
Subjectivity detection can be a useful tool for governmental agencies to find out which topics are particularly heated or controversial and, hence, act accordingly to prevent popular discontent. Similarly, businesses can use sentiment analysis in social communication for spam detection, troll filtering, social media monitoring, and business intelligence. On the other hand, the development and automated up-keeping of opinion gathering websites, can be undertaken by opinion mining techniques, in which opinions are continuously gathered in real time and from the Internet and include broader topics like national issues and not limited just to reviews of products.
Within such subjective topics, however, opinions can be expressed on multiple opinion targets. For this reason, aspect extraction [19] comes as an important subtask of sentiment analysis which consists of detecting aspects in opinionated text, i.e., in identifying the specific aspects of a product or service which the consumer is discussing about. For example: ”nuclear energy is good for the environment but safety is a great concern” is a subjective tweet about nuclear energy with ”environment” and ”safety” as two aspects.
This paper focuses on the application of subjectivity detection on tweets about nuclear energy. In addition to what has already been mentioned, there are three issues which this research aims to tackle, namely:
A lot of factual or non-opinionated information needs to be filtered out;
Opinions are most times on different aspects of the similar product or service rather than on the whole item;
Reviewers tend to praise aspects of the same product or service and criticize others.
Different strata of opinion mining have been proposed, each one having its own merits and demerits. In this paper, we apply an ensemble of deep learning and linguistics [6] to tackle the problem of subjectivity detection on tweets1. The subjectivity detection task ensures that factual information possessing neutral polarity is filtered out and only opinionated information is further passed on to the aspect extraction and polarity classifier. It enables the correct distribution of polarity among the different features of the opinion target (instead of having one unique, averaged polarity assigned to it).
The rest of this paper has been organized as follows: Section 2 reviews the related work; Section 3 explains the proposed architecture; Section 4 provides an evaluation of the architecture; finally, Section 5 illustrates the conclusion and future work.
2 Related Work
Subjective extraction yields comparable polarity results as full text classification [2] even after reducing the review data by 60%. Previous efforts used general subjectivity clues to produce training data from unannotated text [23]. Recently, in [15] the authors improved accuracy on subjectivity detection for Twitter data by using hand-crafted features and pre-computed word vectors. However, they considered two classifiers, the first for removing neutral sentences, and another to classify subjective sentences into ’positive’ or ’negative’. This approach cannot be applied to new languages and domains. In contrast, we consider deep convolutional neural network (CNNs) that can automatically learn features and hand-crafted features are only used to initialize the weights in the model.
Similarly, in [1] the authors predicted sentiment in finance tweets by cascading two classifiers for subjectivity and sentiment. In finance tweets, the position of the author (e.g., investor or company) is critical, hence they consider Bayes rule to cluster tweets in an unsupervised manner. In order to reduce the time complexity, they divided the training data into multiple subsets and then combine the features using a support vector machine (SVM). However, this can lead to loss of information, instead deep learning is a semi-supervised model where each hidden neuron is independent from others and, hence, can be trained in a parallel manner.
In deep neural networks, a word’s meaning is simply an indicator that aids to classify document like entities. Similar words appear consecutively when represented in a d dimensional vector-representation.
Vectorising makes it easier to cluster them on the basis of their similarities. The features include suffix, prefix, distance from verbs in the sentence, in order to know the corresponding position of verbs in semantic role labelling. However, there is a corresponding vector illustration in the training as a d dimensional space for each feature.
Recently, CNNs have become increasingly popular for subjectivity detection. In particular, [10] used recurrent CNNs. These show significant accuracy on datasets where the interdependency between sentences is high. In [6], authors extended the extreme learning machine (ELM) paradigm to a novel framework that exploits the features of both Bayesian networks and fuzzy recurrent neural networks to perform subjectivity detection.
The order of sentences preceding the one at hand, results in a sequence of sentences. However, due to overfitting of the model, hence in [6] the authors considered fusion of Spanish and English tweets using deep CNN. In this paper, we extend their work to multilingual and we train the model using reinforcement learning. We evaluate our method on tweets related to nuclear energy. Figure 1 depicts the ratio of subjective vs objective tweets collected from Twitter. It shows that Twitter is a potential source of data for opinion mining. This paper summarizes the significance and contributions of the research work as:
— We introduce a reinforced deep CNN (RDCNN) capable of classifying sentences as subjective (positive or negative) or objective (neutral) in multilingual datasets.
— We propose a new regularization for neural networks based on reinforcement learning.
— In order to validate the model we manually label 7,700 nuclear multilingual tweets into positive, neutral and negative classes.

3 Reinforced Deep Convolutional Neural Networks
In this section, we consider the use of reinforcement learning to regularize learning in a deep CNN. The resulting framework is referred to as a RDCNN. We begin with the description of reinforcement in a single layer neural network and then detail its integration into the complete framework.
3.1 Deep Reinforcement Learning
Point-wise probability reinforcements (PPR) are commonly used to robustify neural networks. Most robust neural network inference methods consists of assigning a weight to each instance in order to reduce the influence of outliers [7]. The reinforced maximum likelihood model maximizes :
 (1)
(1)
where y is the output class label, r is the vector or PPRs, α is a reinforcement meta-parameter, and Ω is a penalization function. A sparse L1 penalization function is obtained by :
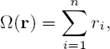 (2)
(2)
which shrinks PPRs towards zero with ri ≥ 0 L1-regularized PPRs are given by the closed-form expression:
 (3)
(3)
where  is the current estimate of the model parameters.
is the current estimate of the model parameters.
3.2 RDCNN Framework
The data pre-processing includes taking away top 50 stop-words and punctuation marks from the sentences. Subsequently, a POS tagger was used to determine the part-of-speech for each word in a sentence. Around 8,000 subjective clues were identified, which were compiled using both manual and automated procedures on both unannotated and annotated data. Each clue is comprised of word and its corresponding part-of-speech.
The subjective and objective sentences are taken from MPQA corpus. The count of each clue was computed in both the sentences. Here, the top 50 clue with maximum count in the subjective sentences were considered.
As described in Algorithm 1 line number 5-9, we compute the prior probability of each parent word set ai for child word xi called ”word-motif”. Sentences containing all words in a word-motif’ with high probability are selected. Lastly, the CNN is jointly pre-trained with both subjective and objective sentences that contain high probability ”word-motifs”.

We first construct a minimal deep CNN with visible layer of L × d nodes, where length of the sentence is given by L and d is number of features for each word; first hidden convolution layer of k-gram neurons, second hidden logistic layer of nh neurons and nd output neurons.
The nh features expressed at logistic layer after training form the new low-dimensional input data of T samples.
Next, we construct a recurrent neural network (RNN) with nh input nodes and nr hidden neurons with time-delays. The nr features expressed at the hidden neurons after training form the new output data of T samples.
Each test sample is used to generate nh features from deep CNN and nr features from RNN and finally classified using RNN. Lastly, we regularize the negative log-likelihood probability of the output layer in deep CNN as described by Eq.(1) resulting in a RDCNN.
We calculated the change in visible layer reconstruction error Δ∊ on the training samples in order to ascertain the number of hidden layers in the deep CNN and the RNN. At each visible node the Δ∊ is the root mean square error between reconstructed sample and the input training sample.
If a significant change in error was noticed as shown in Algorithm 1 then a new hidden layer was added. The reconstruction error is recomputed and the each layer’s weights are learned. The above procedure is iteratively recomputed until no further significant change in classification precision error with the addition of hidden layers occurs. For each hidden layer, optimal number of hidden neurons are determined based on significant principal components in the training data.
Each neuron in the final output layer corresponds to a particular class. In order to sample features with high frequency we use contrastive divergence approach. It samples them in the upper layers, which results in the formation of the phrases at the neurons in the first layer. The bigger sentences are generated at the neurons in the second hidden layer and so on. The algorithm is iterated until no significant change in the weights at the lth layer were found. Lastly, we train the model using labelled multilingual tweets.
4 Evaluation
This phase includes data collection from Twitter, data pre-processing, and testing it on the model.
4.1 Data Collection
The dataset consists of tweets crawled from Twitter streaming API 2. In order to collect tweets relevant to nuclear energy, we carefully chose a list of keywords from Twitter. The crawling started with a single basic keyword # nuclearenergy and it resulted in about 2000 tweets over a period of two days. The collected tweets were parsed and the “hashtags” were collected from each tweet.
The hashtags were sorted in terms of frequency. A hashtag was counted only once even if it appeared twice in the tweet. It thereby prevented not giving weightage to a keyword just on the basis of frequency even if it appeared multiple times in one tweet. For example, in the tweet, “ The # nuclearenergy is the # greenenergy and will help cut carbon emissions. # nuclearenergy # nuclear”, The tag ” # nuclearenergy” occurs twice but our model counts it only once, thereby not giving irrelevant weightage to the hashtag.
Bearing this in mind, 219 hashtags were collected with frequencies ranging from 1100 to 10. The cut-off of the hashtag frequency was set to 800, which resulted in 1200 tweets. Then the keywords not related to nuclear energy were manually removed, for example some tweets included # nuclearenergy with # trump, whereas # trump was not an apt keyword for our dataset.
After removing the irrelevant keywords there were 20 keywords left. Then, the rest of the keywords were given input to the Twitter API. The output of Twitter were stored and analyzed manually to come up with a list of keywords best suited for nuclear energy task. Table 1 is the list of final keywords for the nuclear energy:

It was observed that using ”# ” restricted the output tweets with #, whereas some people do not enter ”# ” tags , thereby losing a major part of opinionated posts. The final set of keywords were then given to Twitter’s streaming API to get tweets. It collected 30,000 tweets for both the topics over a course of 2 months.
4.2 Data Preprocessing
The data preprocessing phase followed the following rule in order to remove unnecessary tweets:
removes usernames (starting with @),
urls (eg., https://www.Twitter.com),
Removal of the stop words and punctuation marks,
Removal of microtext (including emoticons, interjections, and slang).
The above mentioned rules resulted in 12,719 tweets against 30,000 collected tweets, for nuclear energy, which suggests that most of the tweets contained urls, usernames, stopwords, and microtext. This huge dropout in the number of tweets also depicts the importance of a microtext analysis module.
4.3 Microtext
By dropping microtext, a major part of opinionated posts may have been lost since it became one of the most widespread communication forms among users due to its casual writing style and colloquial tone [11]. For instance, it is possible to recognize the sentiment of a tweet through features like retweets (since users frequently retransmit messages they strongly agree with) and hashtags (which can have affect keywords and assembly tweets that often agree with each other) [9]. As follows, the intrinsic noisy nature of this user-generated content (UGC) poses difficult challenges to sentiment analysis applications [8]. Some of the microtext key features of micortexts are as follows:
Yet, the challenge arises when, instead of removing microtext, we try to automatically rectify and reinstate them with the correct in-vocabulary (IV) words [12, 17].
4.4 Parameters
In order to determine the accuracy of the sentences we employed 10-fold cross validation using the trained CNN classifier. The learned features are visualised by only using 6-grams in the test set. The 6-grams demonstrated the highest activation when convolved with learned kernels.
The root mean square error (rmse) method was employed to calculate the difference between the predicted 6-gram kernel vectors and the prior word-vectors for each 6-gram learned. The 6-gram learned was using co-occurrence data. We find that 32% of the tweets are objective and 68% of the tweets are subjective.
4.5 Nuclear Energy
Some neurons in the first layer learn neutral and some learn subjective features. We have illustrated the 6-gram features for nuclear energy as learned by two neurons in Table 2. Next, in order to assess the quality of prediction, we manually labeled 7, 700 tweets out of 12, 719 tweets as Subjective (neutral) and Objective (positive or negative).
We first consider a model trained on 10,000 MPQA English corpus [6] and tested it on all the nuclear tweets. For the second model we report 10-fold cross-validation (CV) on multilingual labeled nuclear tweets in English, French, Spanish, German, Malay and Indonesian. We use pre-trained word-vectors for different languages ( available at Facebook Research 3).
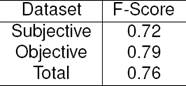
Table 3 and Table 4 shows the F-measure for our model trained on MPQA English corpus and manually labelled multilingual tweets. It can be seen that the F-measure is around 76% for both classes showing that the proposed model works well on Tweets with different languages. Though the model shows low F-score for MPQA dataset which is around 50%.

5 Conclusion and Future Work
The exponential growth of social data has led to a new challenge: subjectivity detection. Subjectivity detection is a complex NLP task that consists of distinguishing subjective data (opinions) from objective data (facts). This paper, proposes a new model with reinforcement learning. The testing phase included Twitter streaming API tweets about nuclear energy.
The data preprocessing phase removed the major part of noise in the collected data, emphasizing the importance of data preprocessing in social media. By filtering out objective data, we found out that 68% of total tweets about nuclear energy were subjective which also shows that Twitter is a consistent source for mining public opinions.
The percentage of neutral tweets is due to the following possible reasons as seen in Figure 1:
No nuclear disaster occurred during the data crawling phase. As, public tends to share updates (opinions) more often during a disaster, as could be seen during Fukushima disaster.
Many social media users shared media content (e.g., news) related to nuclear energy unlike other topics (e.g., political issues).
The results show a great significance in detection of subjective and objective tweets about “nuclear energy” and, hence, open new avenues in aiding government agencies for decision making in terms of management, planning and logistics related to nuclear power plants. Besides subjectivity detection, sentiment analysis requires handling many other NLP subtasks such as aspect extraction, sarcasm detection, anaphora resolution, and microtext analysis. Future work will involve the development and application of all such subtasks to further improve the accuracy of the proposed analysis. We will also go one step further by applying polarity detection on the collected subjective data, to finally infer whether the public opinion about nuclear energy is positive or negative at any given time.

