











 nova página do texto(beta)
nova página do texto(beta) Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink
Antecedentes
En artículos previos de la serie de Metodología de la investigación se abordó la manera de elegir una prueba estadística considerando el objetivo de la investigación, el tipo y distribución de las variables. Para determinar diferencia de medias en dos grupos no relacionados y variables cuantitativas de distribución normal se utiliza la prueba de t de Student, pero si lo que se quiere es predecir un desenlace dicotómico ajustando por distintas variables de confusión, la prueba estadística pertinente es el modelo de regresión logística múltiple. En este artículo abordaremos las pruebas estadísticas que permiten conocer la fuerza de asociación o relación entre dos variables cuantitativas u ordinales y cuyo resultado se expresa mediante el coeficiente de correlación. Si ambas variables se encuentran con distribución normal, calculamos la correlación de Pearson, si no se cumple este supuesto de normalidad o se trata de variables ordinales se debe calcular la correlación de Spearman1,2
Correlación de Pearson
El coeficiente de correlación de Pearson fue introducido por Galton en 1877 y desarrollado más adelante por Pearson. Es un indicador usado para describir cuantitativamente la fuerza y dirección de la relación entre dos variables cuantitativas de distribución normal y ayuda a determinar la tendencia de dos variables a ir juntas, a lo que también se denomina covarianza.
A continuación se muestra la fórmula para calcular el coeficiente de correlación de Pearson, la cual considera en el numerador la covarianza (suma de productos xy) y en el denominador, la raíz del producto de las sumas de cuadrados de ambas variables.
Ejemplo: para conocer la fuerza de asociación entre las variables del índice triglicéridos/glucosa y circunferencia abdominal, al ser variables cuantitativas de distribución normal la prueba estadística adecuada es la de correlación de Pearson.
Correlación de Spearman
La correlación de Spearman o también conocida como rho de Spearman es el análogo no paramétrico de la correlación de Pearson. Se utiliza para variables cuantitativas de libre distribución o con datos ordinales. La correlación de Spearman se basa en la sustitución del valor original de cada variable por sus rangos, tal como se puede observar en su fórmula. Para calcularla se requiere que se ordenen los valores de cada sujeto para cada variable X, Y, además de que se asigne un rango. Si existe una correlación fuerte, los rangos deben ser consistentes: bajos rangos de X se correlacionarán con bajos rangos de Y. 3
Donde:
∑d2 = sumatoria de la diferencia de rangos
n = número de pares (X, Y)
Ejemplo: si un investigador quiere determinar si existe correlación entre la saturación arterial de oxígeno y el estadio del pie diabético, la prueba estadística pertinente será la de correlación de Spearman.4
Interpretación y uso del coeficiente de correlación
El coeficiente de correlación se representa con una “r” y puede tomar valores que van entre −1 y + 1. Un resultado de 0 significa que no hay correlación, es decir, el comportamiento de una variable no se relaciona con el comportamiento de la otra variable. Una correlación perfecta implica un valor de −1 o + 1, lo cual indicaría que al conocer el valor de una variable sería posible determinarse el valor de la otra variable. Entre más cercano a 1 sea el coeficiente de correlación, mayor la fuerza de asociación (cuadro 1).
Cuadro 1 Interpretación del coeficiente de correlación
0 |
Sin correlación |
± 0.20 |
Correlación débil |
± 0.50 |
Correlación moderada |
± 0.80 |
Correlación buena |
Correlación perfecta |
Parámetros solo de referencia, no deben ser considerados como estrictos puntos corte. Estos valores son afectados por el tamaño de muestra.
Además de analizar el coeficiente de correlación también debemos considerar el signo de este, que nos permite conocer la dirección de la correlación.5 Un signo positivo implica que al aumentar la variable X también aumenta la variable Y, como ejemplo podemos encontrar que al aumentar la edad (X) aumenta la presión arterial (Y), mientras que un signo negativo implica que al aumentar la variable X disminuye la variable Y, tal como sucede con el índice tabáquico y el VEF1: al aumentar el índice tabáquico (X) disminuye el VEF1 (Y).
Las hipótesis que es posible plantearse mediante una correlación son las siguientes:
H0: r = 0, no existe correlación.
Ha: r ≠ 0, existe correlación y está puede ser positiva o negativa.
Diagrama de dispersión
Para examinar visualmente una correlación se utiliza un diagrama de dispersión, el cual nos permite conocer el comportamiento de ambas variables. Cada uno de los puntos representa la intersección de un par de observaciones (X, Y). Con un suficiente número de datos podemos crear un diagrama de dispersión para observar la fuerza y dirección de la relación.
En la figura 1 puede apreciarse una correlación perfecta positiva; en este tipo de correlación es posible inferir un valor de Y si conocemos el valor de X, dado que se modifican constantemente. Por ejemplo, si las variables edad y peso mostraran una correlación de + 1, con solo conocer el valor de edad podríamos determinar el peso de un niño. Sin embargo, es poco común encontrar este tipo de correlación, lo común es encontrar que las variables X y Y varían proporcionalmente y no siguen un patrón constante.
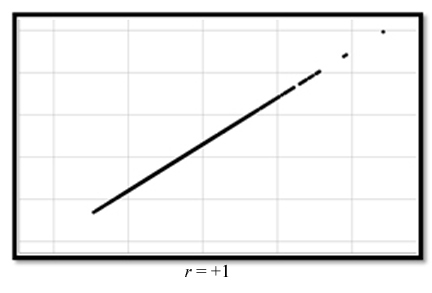
En la figura 2 se puede observar una correlación perfecta negativa. Es decir, al incrementar X disminuye el valor de Y, tal como podría ocurrir con las variables edad y masa muscular. Al aumentar la edad, disminuye la masa muscular.

En la figura 3 no es posible observar una relación lineal entre ambas variables. La variación observada entre una y otra es por efecto del azar. Esto ocurriría si quisiéramos mostrar la correlación entre consumo de chocolate al día y el coeficiente intelectual.

Significancia estadística del coeficiente de correlación
El coeficiente de correlación, así como otras pruebas estadísticas es dependiente del tamaño de muestra. Correlaciones de 0.20 pueden ser significativas con tamaños de muestras mayores, mientras que esta no será significativa si la muestra es pequeña, .6
Causalidad y correlación
Resulta necesario distinguir los conceptos de causalidad y correlación. La presencia de una correlación estadística entre dos variables no necesariamente implica causalidad, es necesario reflexionar acerca de algunas características que cuando se cumplen son sugerentes de una relación causal, como lo explicó sir Austin Bradford Hill varias décadas atrás. Por ejemplo, podríamos tener una correlación positiva y significativa entre las variables consumo de chocolate al día y el coeficiente intelectual, aún siendo significativa desde el punto de vista estadístico, no existe manera de explicar la plausibilidad biológica entre ambas variables.7,8
Coeficiente de determinación
Cuando exploramos una correlación lineal entre variables cuantitativas, parte de la variación de la variable Y puede ser debida a X. Sin embargo, en alguna proporción está variabilidad se deberá a otros factores o como efecto del azar. El coeficiente de determinación puede ser calculado para mostrarnos la proporción de variabilidad de la variable y que es atribuida a la relación lineal con X.
El coeficiente de determinación se obtiene elevando al cuadrado el valor del coeficiente de correlación (r2). El coeficiente de determinación podrá tomar valores entre 0 y 1. Valores cercanos a 1 implican que una gran proporción de la variabilidad de y es explicada por X. Al llevar a cabo una correlación entre masa muscular y consumo máximo de O2 en pacientes con insuficiencia cardiaca encontramos un coeficiente de correlación, r = 0.7 (p < 0.0001), el valor de R2 será de 0.49, es decir, 49 % del consumo máximo de O2 puede ser atribuido a la masa muscular.9
Ejemplo
Supongamos que el objetivo de un estudio es determinar si existe relación entre índice de masa corporal y porcentaje de grasa corporal por densitometría ósea. Nuestra hipótesis nula es que no existe relación y por lo tanto r = 0 y no existe correlación. La hipótesis alterna es que existe relación entre estas variables y que la asociación es positiva y por lo tanto r es distinto a 0.
A continuación, se muestran los pasos para la determinación de la correlación:
Determinar el tipo de distribución de las variables.
Al calcular las pruebas de normalidad encontramos que ambas variables tienen libre distribución, ya que la prueba de hipótesis de normalidad Kolmogorov-Smirnov muestra un valor de p < 0.05, por tanto, asumimos que nuestras variables tienen libre distribución (figura 4).
En virtud de que las variables de estudio tienen libre distribución, calcularemos la rho de Spearman.
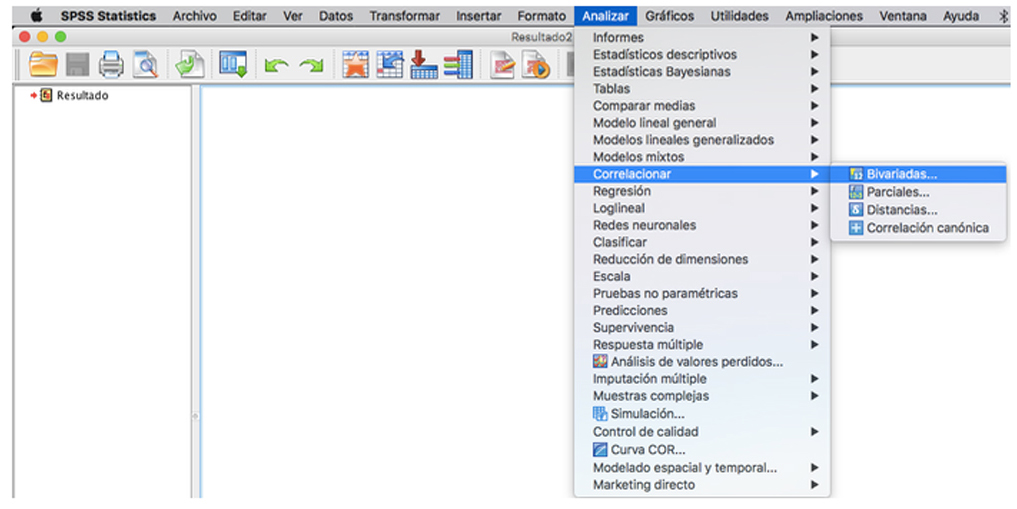
En SPSS seleccionamos la opción de analizar y correlaciones bivariadas (figura 5).
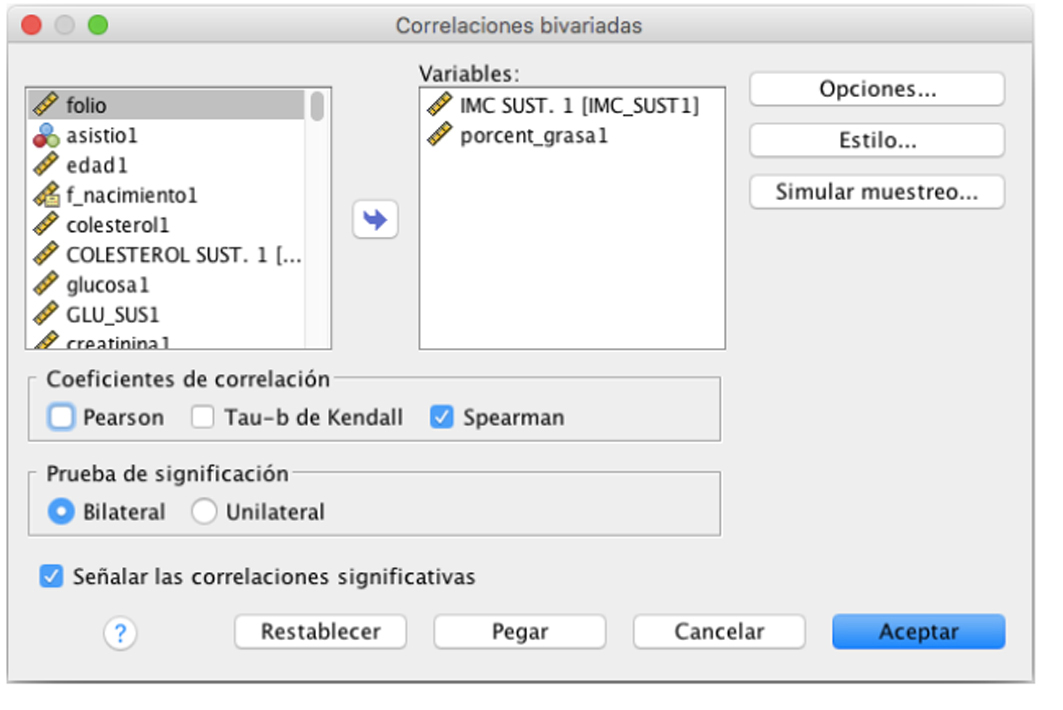
Dado que nuestras variables presentan libre distribución, seleccionamos la opción de correlación de Spearman (figura 6).
Al analizar los resultados de la correlación, encontramos un coeficiente de correlación de 0.69, con un valor de p < 0.001. Estos resultados nos muestran que la fuerza de asociación entre estas variables es de moderada a buena, se observa una correlación significativa, es decir que no es atribuible al azar. Al aumentar el índice de masa corporal se incrementa el porcentaje de grasa corporal (figura 7).
Para realizar el diagrama de dispersión, se elige la opción de cuadro de diálogos antiguos y elegirá diagrama de dispersión (figura 8).
La figura 9 nos muestra el diagrama de dispersión para las variables índice de masa corporal y porcentaje de grasa corporal, con una correlación positiva.

Figura 4 Resultado de la prueba de normalidad para índice de masa corporal (IMC) y porcentaje de grasa.



Otros usos
El empleo de los coeficientes de correlación es también útil para evaluar la relación entre las distintas variables independientes o covariables que planean ser introducidas en un modelo multivariado. De esa manera puede observarse si la correlación entre las variables independientes es alta (colinealidad) y evitar incluirlas juntas en un mismo modelo.

