











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
El pronóstico es un interés intrínseco a todas las disciplinas para planificación. El futuro es sinónimo de incertidumbre y el panorama se torna más complicado cuando se desea medirla. En los experimentos físicos o matemáticos, la precisión de las estimaciones es una de las exigencias de la calidad, es más, siempre se busca minimizar el error y en estos escenarios, bajo condiciones controladas, es común hablar de la precisión. No ocurre así en los casos en que se estudian los sistemas sociales, ya que no podemos contar con un escenario experimental definido como en el primer caso. Lo que es frecuente es recolectar información de las poblaciones para la construcción de indicadores de estado. Esta información está sujeta a errores de diversa naturaleza ya que no se trata de un sistema cerrado. ¿Es factible hablar de la precisión de los indicadores sociales? ¿Qué tanto podemos acercarnos a los datos reales de la población total? Desde el punto de la teoría estadística podemos acercarnos a la situación más probable y partiendo de ello si podemos hablar de la precisión de las estimaciones analizando los resultados de diferentes métodos de estimación, lo cual es el objetivo de esta investigación.
Recordemos que históricamente en matemáticas se están desarrollando nuevos métodos para cuantificar fenómenos y estimar resultados que se aproximen más a la realidad. Así lo describe claramente Bernoulli en su definición del arte de conjetura:
Definimos el arte de la conjetura, o arte estocástico, como el arte de evaluar lo más exactamente posible las probabilidades de las cosas, de modo que en nuestros juicios y acciones podamos siempre basarnos en lo que se ha encontrado que es lo mejor, lo más apropiado, lo más seguro, lo más aconsejado; este es el único objeto de la sabiduría del filósofo y la prudencia del gobernante (Stewart, 2007).
En este contexto, de búsqueda de mejores estimaciones, se realiza la presente investigación en un campo de interés a la sociedad y a los gobiernos para la planificación. Y aunque sea difícil realmente conocer el futuro y determinar que estimaciones están más cerca de la realidad, este nuevo paradigma nos motiva a considerar escenarios entre los cuales fluctúa el futuro.
Las proyecciones de población nos proveen de información que permite la planificación de los recursos y se utiliza para la evaluación de políticas públicas a través de la construcción de indicadores sociales. En demografía el método de proyección de población más utilizado es el método por componentes, sin embargo, recientemente nuevas metodologías provenientes de la probabilidad y estadística y de la ingeniería, toman importancia por capturar la dinámica compleja de los sistemas reales (Sevcikova, Raftery and Gerland, 2013). En 1965 Zadeh crea la teoría de los conjuntos difusos para modelar el pensamiento humano en el marco de la inteligencia artificial. Debido al potencial de esta teoría para el modelado de sistemas no lineales y considerando el carácter no lineal del comportamiento poblacional se propone utilizar los teoremas de series de tiempo difusas desarrollados por Song y Chissom (1991) para realizar proyecciones de población.
Los primeros estudios que utilizaron series de tiempo difusas para proyectar datos, desde la formulación teórica de conjuntos borrosos, se inician en los noventas. Así tenemos los desarrollos hechos por Song y Chisson en 1991 y 1993 para proyectar los estudiantes matriculados en la Universidad de Alabama. Luego Chen y Ching Hsu en 2004 proponen considerar el modelo de Song y Chissom para series de tiempo variantes en el tiempo y posteriormente comparar los resultados usando redes neuronales. Abbasov y Mamedova en 2003 aplican el método para proyectar la población total de Azerbaiyán y encuentran resultados que mejoran las estimaciones en comparación con métodos clásicos (Sasu, 2010). El objetivo del presente artículo es aplicar la metodología de series STD en proyecciones de población y evaluar sus resultados para el caso de la población total mexicana utilizando los datos históricos entre 1895 y 2010. Se trata de una nueva propuesta utilizando un método de proveniente de la inteligencia artificial.
Proyecciones de población
La inquietud de proyectar para conocer el futuro se presenta en todas las disciplinas. El ejemplo más conocido es la predicción del clima. En demografía, es muy importante realizar proyecciones de la población y su distribución a niveles desagregados, con el objetivo de planificar los recursos y servicios.
El método más utilizado en la proyección de población es el método por componentes (CEPAL, 2006) que considera la siguiente ecuación general:
Donde N t son los nacimientos en t, D t las defunciones, I t la inmigración y E t la emigración, las cuales balancean la “ecuación compensadora” para conocer la población en t + 1. Los cuatro componentes demográficos se representan por sus tasas de frecuencia anual (tasas específicas de fecundidad, tasa de mortalidad, tasa neta de migración) los cuales se proyectan bajo diferentes hipótesis de comportamiento (CEPAL, 2006: 29-33). Este método se utiliza de manera estándar y se adapta a diferentes contextos sociales sobre todo en los cuales la disponibilidad y calidad de la información puede ser deficiente. Sin embargo, cuando se hacen conteos de medio término de los censos de población, como en el caso de México, se encuentra que las proyecciones con las cuales se planificaron políticas públicas y se las evaluó, difieren de los datos que proporcionan los conteos, respecto lo cual se ajustan y se concilian los resultados (CONAPO, 2006).
México cuenta con una amplia experiencia en ejercicios de proyecciones de población ya que tiene de manera institucionalizada una recopilación constante de información a través de censos, conteos y encuestas, información disponible para la investigación y para política pública. Instituciones como el Instituto Nacional de Estadística y Geografía (INEGI) y Consejo Nacional de Población (CONAPO) desde el gobierno e instituciones de educación superior reconocidas como el Colegio de México (COLMEX), Facultad Latinoamericana de Ciencias Sociales (FLACSO) y la Universidad Nacional Autónoma de México (UNAM) realizan una amplia investigación en esta área.
Dentro los métodos más usados para las proyecciones de población se tienen los métodos tradicionales que están sujetos a varios supuestos demográficos como la constante y equilibrios que no son intrínsecos a los sistemas reales.1 El método por componentes principales descrito anteriormente forma parte de estos métodos tradicionales. La fortaleza de este método es su simplicidad y su lógica se asemeja a un sistema hidráulico, en el que se puede asumir la población total como la cantidad de agua en un tanque que se llena con los nacimientos y población migrante, se vacía con la emigración y las defunciones para contar con cierto nivel de población estimada, la cual se proyecta en el tiempo bajo supuestos del comportamiento de las tasas que regulan estos niveles.
Se han utilizado en el mundo con mayor frecuencia los métodos tradicionales para proyecciones de población que otros provenientes de las ciencias puras como la economía e ingeniería. Es desde 1969 que se vienen realizando ejercicios de proyecciones de población utilizando métodos estocásticos como los de Lee y Tuljapurkar (1997 y 1998). Este cambio implica una transformación conceptual de cómo se concibe la demografía para abrirse a nuevos paradigmas. La lógica matemática detrás del método por componentes es totalmente diferente a la perspectiva estocástica la cual incorpora conceptos de probabilidades. Los primeros intentos en México por incursionar en estas técnicas son los trabajos de Ordorica (1995) con la aplicación del filtro de Kalman para la estimación de la población mexicana a nivel nacional, posteriormente en 2004 aplico series de tiempo para la proyección del número total de defunciones del país. Entre otros trabajos relacionados se tiene el de Kesseli y Galindo (2007), González y Guerrero (2007), García Guerrero y Ordorica (2012) y García Guerrero (2014a, 2014).
En particular el trabajo de Guerrero (2014) realiza la proyección de la población total mexicana por sexo y edad aplicando el método de Lee-Carter (1992) y el de Hyndman y Booth (2008) (este segundo es una generalización del primero) con métodos estocásticos. El modelo de Lee-carter ampliamente usado para el pronóstico de población formalmente se resume al logaritmo natural de las tasas y forma parte de la clase de los métodos por factores (dos factores: intrínseco y otro constante). El método que forma parte de los modelos por factores, muy populares en la econometría contemporánea, también son emparentados por los Vectores Autoregresivos Cointegrados (Uribe, 2016). El autor logra estimar la población total mexicana a 2020 y 2050 y lo compara con un estudio anterior y con estimaciones oficiales del país. De acuerdo a Uribe (2016) la ventaja de estos modelos es que “toman en cuenta la estructura común de las tasas y se ajustan relativamente bien a las muestra de estudio” no obstante los intervalos de confianza obtenidos son muy amplios porque aparentemente se captura un gran componente aleatorio.
El mejor conocimiento del comportamiento de los indicadores demográficos, nos lleva a tener un mejor conocimiento de las proyecciones de población con lo cual es más probable predecir un futuro cercano a la realidad. Es seguro que no predeciremos de forma exacta el futuro,2 sin embargo, podemos mejorar nuestras estimaciones, reducir la incertidumbre y planificar por escenarios.
Alho et al. (2006) innovan en su trabajo de proyección de la población de 18 países europeos: “cuantifican la incertidumbre demográfica”. No solo estiman un número sino una distribución probabilística de la proyección con base a lo cual pueden hacer afirmaciones del tipo “El valor Y i tiene una probabilidad P i de ocurrir. Esta investigación utiliza el método “socalled scaled model for error” para cuantificar la incertidumbre relacionada a la proyección de población. El método de proyección estocástica tiene la ventaja de proyectar la población futura incluyendo un intervalo de proyección probabilística. Encuentran que a diferencia de los datos oficiales es probable que la población en general crezca y su descenso se retrase más tiempo debido a la alta esperanza de vida e incremento de la migración.
La importancia de la incertidumbre en proyecciones de población, fue considerada indirectamente por Welpthon en 1947. Fue el primero en desarrollar el método por componentes para las proyecciones de población y utilizó la función logística para representar el comportamiento de la fecundidad. Sin embargo sus modelos, ni los de ningún otro, pudieron predecir en su momento, el baby boom que hizo que las tasas de fecundidad que iban en descenso se dispararan. De esta manera hizo análisis exhaustivos de las tendencias de la fecundidad en varios países utilizando diversas fuentes y concluye: “A largo plazo, la tendencia de descenso de la fecundidad es una regla universal. Aunque raramente puede ocurrir que ascienda de forma relativa y corta” (Alho y Spencer, 2005). Lo improbable puede ocurrir (Taleb, 2007).
Concomitantemente, otra línea de investigación en el estudio de la precisión de las estimaciones demográficas en América latina surge en 2007 con los trabajos de Argote Cusi. Utilizando los datos de una encuesta en salud perteneciente a un país emergente, la autora, mediante el método de remuestreo genera la distribución estadística de la TGF lo cual le permite realizar un análisis de la precisión y la incertidumbre de una tasa. Como consecuencia de la aplicación de los algoritmos generados en diferentes muestras y en diferentes momentos en el tiempo, la investigación decanta en un análisis de sensibilidad de proyecciones de población a pequeños cambios de la TGF utilizando la distribución estadística generada de la TGF. La autora concluye: el mejor conocimiento del comportamiento de los indicadores demográficos nos lleva a tener un mejor conocimiento de las proyecciones de población con lo cual es más probable predecir un futuro cercano a la realidad. Es seguro que no predeciremos de forma exacta el futuro, sin embargo, podemos mejorar nuestras estimaciones, reducir la incertidumbre y planificar por escenarios (Argote, 2007).
En la presente investigación a diferencia de los anteriores, se aplica la teoría de los conjuntos difusos o Fuzzy Sets que provienen del área de la inteligencia artificial con el objetivo de modelar el conocimiento aproximado a través de métodos heurísticos altamente usados en la actualidad ante el desarrollo de la capacidad computacional. La lógica que está detrás de los modelos de inteligencia artificial es crear modelos que sean entendibles para el computador y trabajados por él mediante métodos recursivos hasta llevar a un punto de quiere que es el resultado buscado. Esta es una lógica diferente a los métodos vistos anteriormente la cual se explica con mayor detalle en el siguiente apartado.
Métodos de la inteligencia artificial: lógica difusa
La inteligencia artificial es una rama de ingeniería cuyo objetivo es simular la inteligencia humana a través de los computadores. Ello implica recrear los mecanismos adaptativos relacionados a la inteligencia en contextos complejos. Si bien esta tarea es difícil, el desarrollo computacional actual permite el desarrollo de investigaciones en esta área con interesantes hallazgos fundamentalmente en cuatro áreas: Redes Neuronales (RN), Computación Evolutiva (CE), inteligencia de enjambre (IE) y sistemas difusos (SD) (Fulcher, 2008; Zhi-xin, J., Hong-bin, Z. and An-min, X., 2009).
El fin último de estos métodos es la optimización en el proceso de encontrar el resultado; esto es rapidez de cálculo, precisión con el mínimo de recursos y esfuerzos. Estas son potencialidades de las técnicas ingenieriles de las que puede sacar provecho la demografía. Es así que Silverman, Bijack, Hilton, Cao y Noble (2013) en su artículo “Whem demography met social simulation: A tale of two Modeling Approaches” desarrolla una interesante propuesta desde donde se puede encontrar sinergias entre la demografía estadística con potencial para la observación de eventos y predicción y la simulación de sistemas sociales con potencial para modelar mecanismos individuales en busca de la explicación de comportamientos en lo que los autores denominan “scenario-based computational demography” (Silverman et al., 2013: 4).
¿Cuál es interés en estimar un resultado a partir de ciertos datos con un nivel de precisión óptimo? El fin último del uso de técnicas y metodologías de estimación y de cálculo de modelos y estadísticas a partir de un conjunto de datos es encontrar un resultado que cuente con la coherencia, la veracidad y la validez científica para la toma de decisiones. Todo este proceso de estimación a partir de datos es lo que hoy día se denomina la Ciencia de los Datos aunada a un contexto de grandes cantidades de información estructurada y no estructurada disponible en la actualidad (Argote y Parra, 2017; Zadeh, 1975).
En el caso de proyecciones de población, el razonamiento es el mismo, ¿porque nace el interés de estimar la población en un tiempo t en el futuro con el máximo nivel de precisión posible? La respuesta es: en apoyo a la toma de decisiones para planificación de los recursos. En este caso los datos provienen de encuestas, censos y conteos que por su alta cobertura los realizan instituciones de gobierno, aunque recientemente nuevas técnicas de recopilación de datos se vienen implementando a través de smartphones como los trabajos de Sim, Tark y Cho (sin fecha); Eagle y Pentland (2006); Dobra, Thomas, Williams y Dunbar (2013). Por otro lado el término de precisión en proyecciones de población aun no recibe la importancia merecida en América Latina como en otros países en los que se han desarrollado investigaciones en el tema por Stoto, 1979, Alho, 1985, Alho y Spencer, 1990 y 1991, entre otros.
En este contexto la teoría de conjuntos difusos se retoma de la Inteligencia Artificial como nuevo método de estimación de proyecciones de población bajo incertidumbre (Zadeh, 1965). El conjunto de datos utilizado es una serie histórica de la población total mexicana tomada de las instituciones oficiales que generan y trabajan con la información poblacional mexicana. Se realizan simulaciones del modelo de series de tiempo difusas para obtener las estimaciones de la población total mexicana a 2050 por decenios. Un proceso de analítica de los datos se refiere al análisis y comparación de los resultados que se presentan en los siguientes apartados.
Series de tiempo difusas
La complejidad del razonamiento puede ser construido a partir de conceptos simples como elementos, conjuntos, sus relaciones y su generalización considerando conjuntos infinitos. Es de esta manera que la teoría de conjuntos difusos, retoma los conceptos de los conjuntos y desarrolla la construcción de teoremas para modelar el comportamiento aproximado. Para los teóricos de la matemática basta con explorar los conceptos de sigma-algebra y sus propiedades, como se puede apreciar en el libro de Gut (2005), para tener una idea de este tipo de construcciones teóricas en la matemática.
La matemática de los conjuntos difusos trabaja con conjuntos que no tienen límites perfectamente definidos, es decir, la transición entre la pertenencia y no pertenencia de una variable a un conjunto es gradual. Estos conjuntos se caracterizan por las funciones de pertenencia, que dan flexibilidad a la modelación utilizando expresiones lingüísticas (Argote, 2016: 6).
Tales como alto, medio, bajo, etc., es decir, trabajar en escala de grises a diferencia de estados dicotómicos como blanco y negro. Consecuentemente a esta evolución en los métodos que permiten trabajar con información imprecisa a diferencia de los métodos tradicionales, la lógica difusa ha permitido trasladar sentencias sofisticadas del lenguaje natural a un formalismo matemático haciendo realidad su aplicación a fenómenos reales.
Características generales de los conjuntos difusos
Un conjunto difuso expresa el grado de pertenencia al conjunto que tiene cada uno de los elementos. El conjunto difuso A en X puede definirse como el conjunto de los pares ordenados.
Donde μA (x) es la función de pertenencia del conjunto.
La función de pertenencia asigna para cada elemento de X un grado de membrecía al conjunto A. El valor de esta función está en el intervalo entre 0 y 1, siendo 1 el valor para máxima pertenencia. Si el valor de esta función se restringiera solamente a 0 y 1, se tendría un conjunto clásico, o no-difuso. Esta función no es única. Las funciones utilizadas más frecuentemente son las de tipo trapezoidal, singleton, triangular (T), tipo S, exponencial, tipo Π (forma de campana).
El detalle de las características matemáticas de los conjuntos difusos se puede encontrar en Zadeh (1965), Rutkowska (2002), Jang et al. (1997), Nauk et al. (1997), Kosko (1992) y Martín del Brio y Sanz (2001), a continuación, se presenta algunas de ellas.
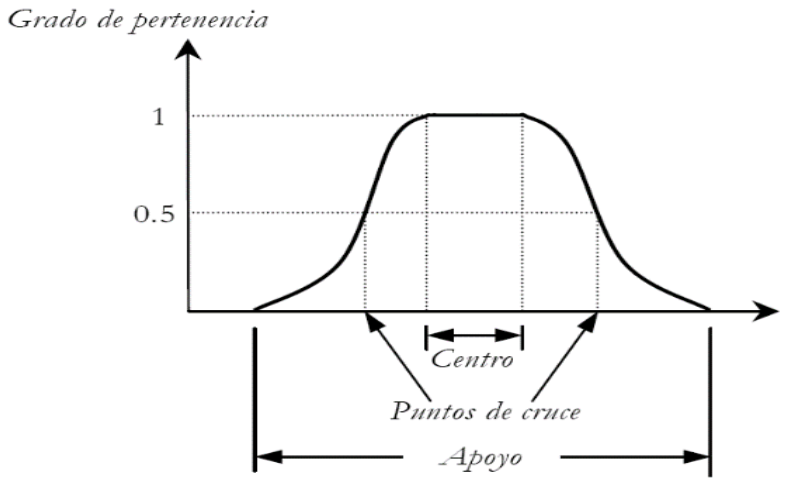
El apoyo en un conjunto difuso A es el conjunto de todos los puntos x para los cuales la función de pertenencia μA(x) > 0.
El centro en un conjunto difuso A es el conjunto de todos los puntos para los cuales la función de pertenencia μA(x) = 1.
Un conjunto difuso es normal si siempre existe un punto para el cual la función de pertenencia es 1, es decir el centro no está vacío. Los puntos de cruce son los puntos del conjunto difuso para los cuales μA(x) = 0.5 (véase Figura 1).
Definiciones y teoremas
Definición 1. Sea Y(t) є R1 donde t = 0,1,2, … una serie de tiempo. Si f i (t) es un conjunto difuso en Y(t) y F(t) = {f1(t), f2(t), …} entonces F(t) es una serie de tiempo difusa en Y(t).
Definición 2. Se supone que F(t) es un evento causado por F(t - 1) únicamente, es decir, F(t - 1) → F(t) la relación que está interviniendo se expresa:
Donde R(t, t - 1) es una relación difusa y se denomina modelo de primer orden de F(t).
Definición 3. Suponga que R(t, t - 1) es un modelo de primer orden de F(t). Si para cada t, R(t, t - 1) es independiente de t, entonces para todo t, R(t, t - 1) = R(t - 1, t, t - 2) entonces F(t) se denomina serie de tiempo difusa invariante en el tiempo.
Considerando las anteriores definiciones a continuación se presentan dos teoremas importantes:
Teorema 1. Sea F(t) una serie de tiempo difusa. Si para todo t, F(t) = F(t - 1) entonces F(t) es una serie de tiempo difusa invariante en el tiempo.
Teorema 2. Si F(t) es una serie de tiempo difusa, F(t) = F(t - 1) para todo t; y F(t) tiene elementos finitos f i (t) entonces:
Donde m > 0.
Este teorema implica que, en el caso de las series de tiempo difusas, es muy fácil y conveniente trabajar con un modelo de primer orden. Desde que se pueda definir rigurosamente infinitos conjuntos difusos en cualquier universo, ante cualquier punto sucesivo t 1 y t 2 se mantiene el mismo conjunto difuso, a partir de ello podemos obtener una serie de tiempo difusa invariante en el tiempo (Song y Chissom, 1991).
El uso de series de tiempo difusas como método de proyección
Los primeros en realizar la formulación matemática de las series de tiempo difusas fueron Song y Chissom en 1991 a partir de los desarrollos teóricos de conjuntos difusos realizado por Zadeh en 1965. Desde ese tiempo a la actualidad varios autores han explorado estas técnicas y realizado estimaciones más precisas sobre la proyección de la matrícula de estudiantes de la universidad de Alabama en Estados Unidos. Particularmente Chen y Hsu (2004) proponen una nueva metodología usando series de tiempo difusas con un modelo variante en el tiempo. Por otra parte, Son y Chissom (1993) continuaron sus investigaciones, no conformes por los resultados obtenidos de proyección, utilizaron redes neuronales para realizar el mismo ejercicio y encontraron resultados interesantes.
Los avances en esta línea de investigación se han realizado en dos ámbitos: en la metodología y en la aplicación en otras áreas. En el primer ámbito Song y Chissom mejoran sus modelos incluyendo series de tiempo variantes en el tiempo y redes neuronales (1993 y 1994); Chen y Hsu (2004) proponen una nueva metodología de división de intervalos que permite mejorar la estimación de la proyección de la matrícula de estudiantes de la universidad de Alabama en Estados Unidos.
En el segundo ámbito se encuentran antecedentes de la aplicación de series de tiempo difusas para la predicción de la temperatura (Chen y Hwang, 2000) y en demografía. En 2003 Abbasov y Mamedova lograron utilizar series de tiempo difusas para la proyección de la población de Azerbaiyán basada en los datos históricos entre 1980 y 2001. Utilizaron un modelo invariante en el tiempo y encontraron que como resultado la capacidad del modelo de proyectar el indicador requerido usando datos de entrada incompletos y poco precisos. El método permite proyectar la población solamente usando la serie histórica con resultados aceptables, mientras que con el método clásico se necesita información más específica y detallada como lo son las tasas de fecundidad, de mortalidad y de migración, parámetros necesarios para la proyección con el método por componentes.
Por otro lado, Sasu (2010) aplicó la metodología utilizada por Abbasov y Mamedova (2003) para la población de Rumania entre 1988-2009 y encontró resultados satisfactorios utilizando series de tiempo difusas. Se evidencian errores menores a 0.003 entre los datos observados y proyectados.
Este ejercicio nos brinda una nueva perspectiva de proyecciones de la población considerando solamente el dato previo. El método heurístico logra capturar la tendencia de comportamiento en el momento anterior y como resultado va obteniendo mejores resultados (resultados más precisos). A medida que se incrementa el número de años considerados del pasado para la proyección, la complejidad de cómputo aumenta. Es por ello que Abbasov y Mamedova (2003) solo consideran siete años atrás para el proceso. Es evidente que el modelo no permite proyectar los datos poblacionales a niveles más desagregados y no considera los procesos de reproducción o la estructura poblacional. En este sentido se abren líneas de investigación para considerar la estructura poblacional en el modelado con series de tiempo difusas.
Datos
Una de las fuentes oficiales más importante de México es el Instituto Nacional de Estadística y geografía (INEGI) que es la encargada de brindar datos a nivel nacional de la población y de otros grupos desagregados y en las diferentes temáticas de gobierno (salud, empleo, educación, etc.). En la página web del INEGI se pueden encontrar los datos de la población total mexicana desde 1895 hasta el 2010 año en el cual se realizó el último Censo Nacional de Población y Vivienda. Cabe aclarar que desde 1995 cada quinquenio México realiza un conteo de la población, es decir, que se disponen datos del conteo de 1995 y 2005. Sin embargo, para fines de la presente investigación se utilizan los datos decenales (véase Tabla 1).
Tabla 1: La dinámica de la población total mexicana, la variación y los valores de membrecía entre 1895 y 2010
| Año | Población total | Variación | Fusificación de las variaciones |
|---|---|---|---|
| 1895 | 12 491 573 | ||
| 1900 | 13 607 259 | 1 115 686 | A00 = (0.999/u1), (0.062/u2), (0.016/u3), (0.007/u4), (0.004/u5) |
| 1910 | 15 160 369 | 1 553 110 | A10 = (0.840/u1), (0.077/u2), (0.018/u3), (0.007/u4), (0.004/u5) |
| 1921 | 14 334 780 | -825 589 | A20 = (0.209/u1), (0.028/u2), (0.010/u3), (0.005/u4), (0.003/u5) |
| 1930 | 16 552 722 | 2 217 942 | A30 = (0.452/u1), (0.113/u2), (0.022/u3), (0.009/u4), (0.005/u5) |
| 1940 | 1 9653 552 | 3 100 830 | A40 = (0.203/u1), (0.216/u2), (0.029/u3), (0.010/u4), (0.005/u5) |
| 1950 | 25 791 017 | 6 137 465 | A50 = (0.038/u1), (0.4393/u2), (0.116/u3), (0.022/u4), (0.009/u5) |
| 1960 | 34 923 129 | 9 132 112 | A60 = (0.015/u1), (0.055/u2), (0.948/u3), (0.069/u4), (0.017/u5) |
| 1970 | 48 225 238 | 13 302 109 | A70 = (0.007/u1), (0.014/u2), (0.049/u3), (0.791/u4), (0.081/u5) |
| 1980 | 66 846 833 | 18 621 595 | A80 = (0.003/u1), (0.005/u2), (0.010/u3), (0.028/u4), (0.209/u5) |
| 1990 | 81 249 645 | 14 402 812 | A90 = (0.005/u1), (0.011/u2), (0.031/u3), (0.277/u4), (0.162/u5) |
| 2000 | 97 483 412 | 16 233 767 | A000 = (0.004/u1), (0.008/u2), (0.018/u3), (0.077/u4), (0.835/u5) |
| 2010 | 112 336 538 | 14 853 126 | A2010 = (0.005/u1), (0.010/u2), (0.027/u3), (0.190/u4), (0.231/u5) |
Fuente: cálculos propios con base a los datos de población total del INEGI de México.
Para el análisis comparativo de las estimaciones realizadas con otros métodos, se toman los resultados de proyecciones de población mexicana publicados en diferentes momentos en el tiempo por entidades oficiales como CONAPO, CELADE e INEGI tomando con base a los datos del Censo Nacional de Población y Vivienda (CNPV) 2000, Conteo de 2005 y CNPV 2010.
Método
Sea U el universo de discurso, U = {u1, u2, … , un} y sea A en el universo de discurso U definida de la siguiente manera:
Donde fA es la función de membresía de A, fA: U → [0,1], fA(ui), indica el grado de membresía de u i en el conjunto difuso A, fA(ui) є [0,1] y 1 ≤ i ≤ n.
Sea X(t) (t = …, 0,1,2, …) el universo de discurso y subconjunto de R, y sea el conjunto difuso f i (t) (i = 1,2, …) definido en X(t). Sea F(t) una colección de f i (t) (i = 1,2, …). Entonces F(t) es llamada serie de tiempo difusa de X(t) (t = …, 0,1,2, …).
Si F(t) es causado por F(t - 1), es decir F(t - 1) → F(t), entonces esta relación puede ser representada por F(t) = F(t - 1)°R(t, t - 1), donde el símbolo ‘°’ denota el operador compuesto Max-Min; R(t, t - 1) es una relación difusa entre F(t) y F(t - 1) y es llamado modelo de primer orden de F(t).
Sea F(t) una serie de tiempo difusa y sea R(t, t - 1) el modelo de primer orden de F(t). Si R(t, t - 1) = R(t - 1, t - 2) para cualquier t, entonces F(t) es llamada serie de tiempo difusa invariante en el tiempo. Si R(t, t - 1) es dependiente del tiempo, esto es, R(t, t - 1) puede ser diferente de R(t - 1, t - 2) para cualquier t, entonces F(t) es llamada serie de tiempo difusa variante en el tiempo.
Considerando las definiciones anteriores, el método de proyección se lleva a cabo a través de los siguientes pasos:
Paso 1: definir el universo de discurso, los conjuntos difusos y las variables lingüísticas.
Paso 2: particionar el universo de discurso en intervalos iguales.
Paso 3: determinar los valores de las variables lingüísticas representadas por los intervalos en que se dividió el universo de discurso.
Paso 4: fuzzificar los datos históricos (asignar grados de membrecía a los casos).
Donde Amn es el conjunto difuso que corresponde a las variaciones entre los años (1895, 2010), C es una constante que en nuestro caso es 0.000001, U es el universo de discurso conformado por las variaciones que se muestran en la Tabla 1 y ui m es el punto medio del correspondiente intervalo u i. Los conjuntos difusos se definen en el conjunto universo U.
Paso 5: Elegir el parámetro w donde w > 1, calcular la matriz R w (t, t - 1) y proyectar la población de la siguiente forma:
Donde F(t) es el dato proyectado de la población en el año t, F(t - 1), es la población fuzzificada del año t - 1, y
Donde w es llamado “modelo base” que considera el número de años antes del tiempo t, “×” es el producto cartesiano y T es el operador transpuesto.
Paso 6: desfusificar la población proyectada. Es necesario transformar la respuesta en una forma que no sea difusa, en este caso se utiliza el método del centroide de área (Jang et al., 1997):
Donde μt (ui) el valor calculado de la función de membresía para el año proyectado t y ui m es el valor medio del intervalo.
Paso 7: El error estimado de las proyecciones de población acorde a la presente metodología se calculó a través de la siguiente fórmula:
Donde V t obs es la variación de la población en el año t; Vt proy es la variación de la población proyectada en el año t; Nt obs es la población total observada en el año t, 1985 ≤ t ≤ 2010.
Resultados
La diferencia entre el año t y el año anterior nos da la variación entre [t - 1, t]. La columna “variación” de la Tabla 1 que se constituye en el universo de discurso U. Sea el valor mínimo de variación de la población entre [t - 1, t] = -825.89 y el máximo valor 18 621 595 tenemos un intervalo en el cual fluctúan las variaciones de la población total a lo largo de 100 años. Acorde a la metodología U = [V min - D 1, V max - D 2], donde D 1 = 2.411 y D 2 = 2.405, de tal manera que el universo de discurso es U = [-828 000, 18 624 000].
El universo de discurso es dividido en intervalos iguales. En el presente caso es dividido en cinco intervalos iguales: u1 = (-828 000, 3 062 400), u2 = (3 062 400, 6 952 800), u3 = (6 952 800, 10 843 200), u4 = (10 843 200, 14 733 600), u5 = (14 733 600, 18 624 000). Se presentan los puntos medios de los intervalos para la estimación del menor error promedio: u1 m = 1 117 200, u2 m = 5 007 600, u3 m = 8 898 000, u4 m = 12 788 400, u5 m = 16 678 800.
En la Tabla 1 se presentan los conjuntos difusos correspondientes a cada año. Estos conjuntos son estimados con base a la variación en la población total registrada con respeto al año anterior y la función de membrecía definida en la ecuación (6) de la sección de metodología.
La variable lingüística: “variación en la población total” adopta los valores lingüísticos que se observan en la Tabla 2.
Tabla 2: Modelo de proyección de la población mexicana: La variable lingüística
| Conjuntos difusos | Variable lingüística |
|---|---|
| A1: Bajo nivel de crecimiento poblacional (BNCP) | BNCP, (1 114 000;4 615 800), A1 |
| A2: Poco cambio en el crecimiento poblacional (PNCP) | PNCP, (4 615 800;8 117 600), A2 |
| A3: Moderado crecimiento poblacional (MNCP) | MNCP, (8 117 600;11 619 400), A3 |
| A4: Normal crecimiento poblacional (NNCP) | NNCP, (11 619 400;15 121 200), A4 |
| A5: Alto nivel de crecimiento poblacional (ANCP) | ANCP, (15 121 200;18 623 000), A5 |
Fuente: elaboración propia.
Si el valor de la variable U en la función de membresía toma el valor medio de los intervalos, el conjunto difuso A i = (i = 1, …, 5) se representa en la Figura 2.
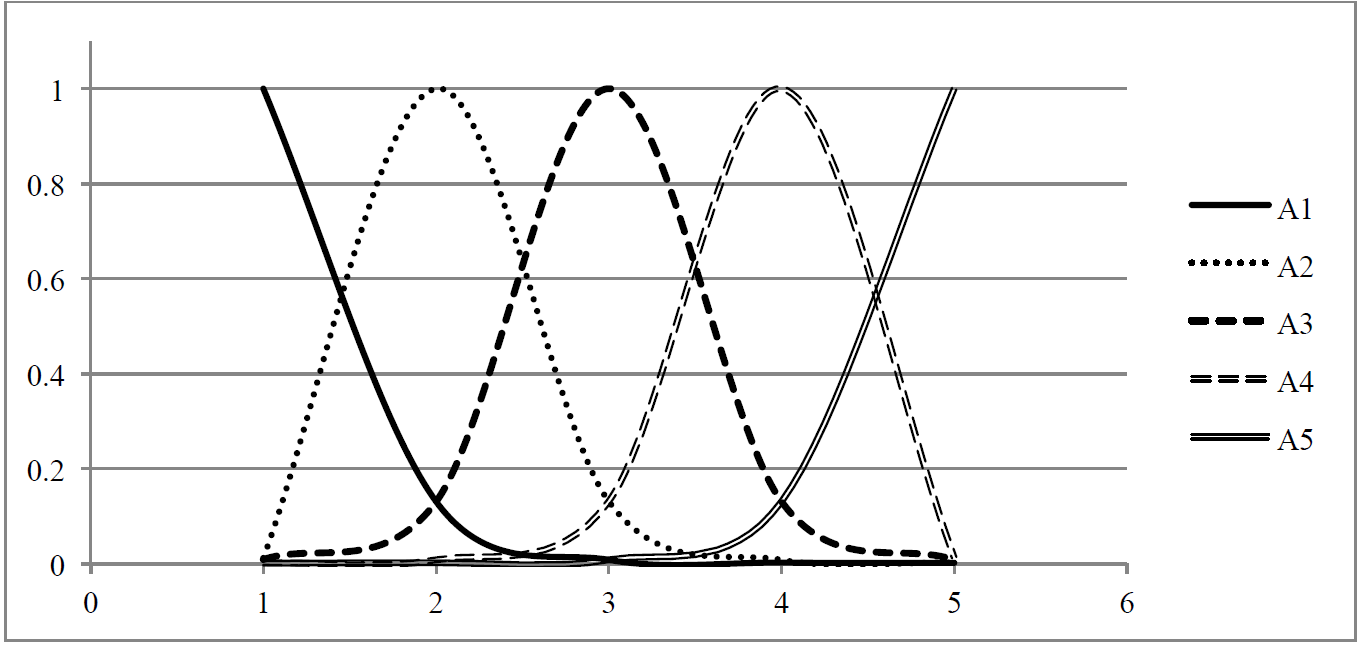
Fuente: cálculos propios.
Figura 2: Funciones de membrecía de la variable lingüística “variación de la población total”
Una vez obtenida la matriz de valores fusificados se procede a aplicar el paso 5 en las ecuaciones (7) y (8) para tener como resultado la matriz F(t) de 1×n. Esta matriz se defusifica a través de la ecuación (9) para obtener el valor proyectado. En la Tabla 3 se puede observar los valores proyectados en etapa retrospectiva, es decir, estimados para la serie de datos del pasado hasta el presente. Se encuentra un error promedio de 0.484 por ciento.
Tabla 3: Resultados de población total mexicana obtenidos para la etapa retrospectiva
| Año | Observado | Proyectado | ||||
|---|---|---|---|---|---|---|
| Población total | Variación observada | Población total | Variación proyectada | AVGE | Error promedio | |
| 1940 | 19 653 552 | |||||
| 1950 | 25 791 017 | 6 137 465 | 24 988 466 | |||
| 1960 | 34 923 129 | 9 132 112 | 32 992 219 | 8 003 753 | 0.032 | |
| 1970 | 48 225 238 | 13 302 109 | 44 848 417 | 11 856 198 | 0.030 | |
| 1980 | 66 846 833 | 18 621 595 | 61 531 883 | 16 683 466 | 0.029 | |
| 1990 | 81 249 645 | 14 402 812 | 82 648 390 | 21 116 507 | -0.083 | 0.002204859 |
| 2000 | 97 483 412 | 16 233 767 | 95 223 174 | 12 574 784 | 0.038 | |
| 2010 | 112 336 538 | 14 853 126 | 113 778 984 | 18 555 810 | -0.033 | |
Fuente: cálculos propios.
Acorde con la Figura 3, la curva proyectada se acerca a los datos observados en el corte 1950 y 2010. Para la proyección de la población a futuro, que se considera desde el último censo en 2010 a 2050, se aplica nuevamente la metodología considerando la matriz de valores fusificados de las variaciones Rw(t), o modelo de primer orden, para dar los resultados de la etapa prospectiva que se muestran en la columna “proyección 2014” de la Tabla 4, y resultados de otras de fuentes oficiales.
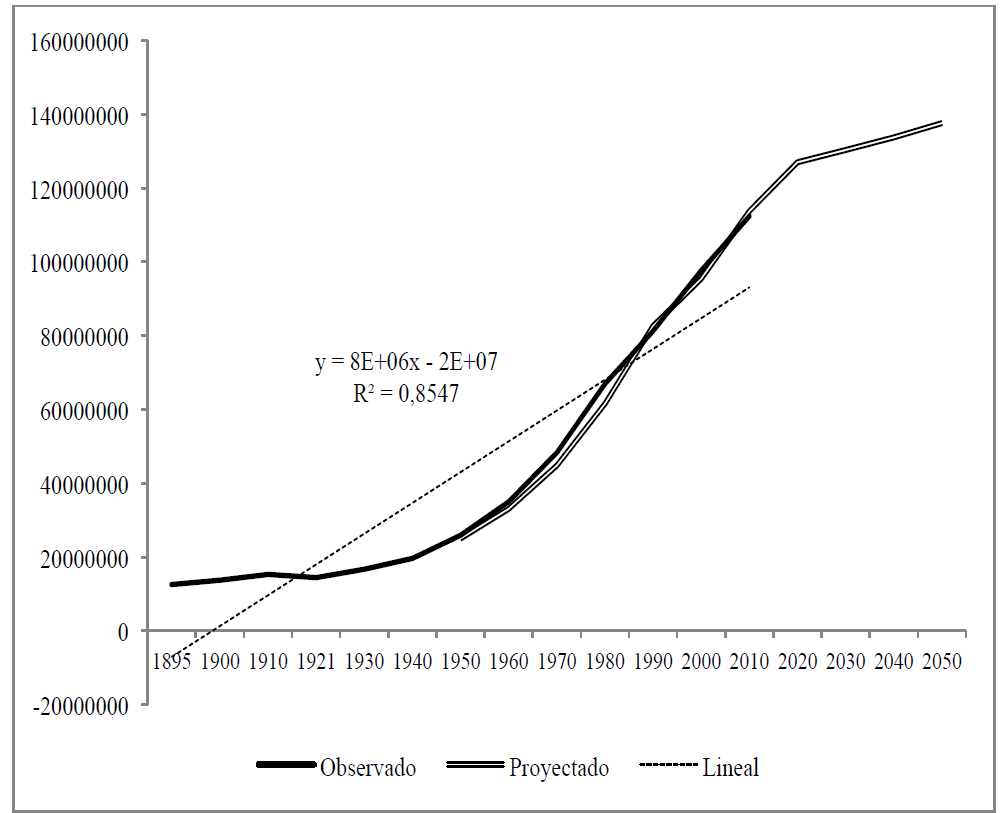
Tabla 4: Comparación de resultados de proyección de la población total mexicana
| Etapa | Año | Observado censos y conteos INEGI 2010 |
Proyección 2000-2050 versión 1998 (1) |
Proyección con base al CNPV 2000 (2) |
Proyección con base al CONTEO 2005 (3) |
Proyección CEPAL 2009 (4) |
Proyección con base al CNPV 2010 (5) |
Proyección 2016 lógica difusa |
|---|---|---|---|---|---|---|---|---|
| Retrospectiva | 1895 | 12 700 294 | NA | NA | NA | NA | NA | NA |
| 1900 | 13 607 259 | NA | NA | NA | NA | NA | NA | |
| 1910 | 15 160 369 | NA | NA | NA | NA | NA | NA | |
| 1921 | 14 334 780 | NA | NA | NA | NA | NA | NA | |
| 1930 | 16 552 722 | NA | NA | NA | NA | NA | NA | |
| 1940 | 19 653 552 | NA | NA | NA | NA | NA | NA | |
| 1950 | 25 791 017 | NA | NA | NA | 27 741 000 | NA | 23 100 276 | |
| 1960 | 34 923 129 | NA | NA | NA | 37 877 000 | NA | 32 297 019 | |
| 1970 | 48 225 238 | NA | NA | NA | 52 029 000 | NA | 44 466 262 | |
| 1980 | 66 846 833 | NA | NA | NA | 69 321 000 | NA | 61 376 766 | |
| 1990 | 81 249 645 | NA | NA | NA | 83 906 000 | 86 313 924 | 82 608 385 | |
| 2000 | 97 483 412 | 99 600 000 | 100 569 263 | NA | 98 957 000 | 100 246 535 | 94 830 105 | |
| 2010 | 112 336 538 | 112 200 000 | 111 613 906 | 108 396 211 | 110 675 000 | 113 462 004 | 113 778 984 | |
| Prospectiva | 2020 | NA | 122 100 000 | 120 639 160 | 115 762 289 | 120 099 000 | 126 441 718 | 126 968 922 |
| 2030 | NA | 128 900 000 | 127 205 586 | 120 928 075 | 127 516 000 | 136 955 288 | 130 260 380 | |
| 2040 | NA | 132 200 000 | 130 200 000 | 122 936 136 | 132 145 000 | 145 020 862 | 133 696 704 | |
| 2050 | NA | 131 600 000 | 129 592 522 | 121 855 703 | 133 341 000 | 150 622 767 | 137 632 144 |
(1) Proyecciones de población de México 2000-2050 con base a los datos disponible en 1998.
(2) Proyecciones de población de México 2000-2050 con base a los datos del Censo de 2000.
(3) Proyecciones de Población de México con base al Conteo 2005.
(4) Proyecciones de Población, Latino América y el Caribe, 2009. Observatorio Demográfico, año 4, núm. 7.
(5) Proyecciones de población de México 2010-2050 con base a los datos del Censo de 2010.
NA no aplica.
Fuente: elaboración propia.
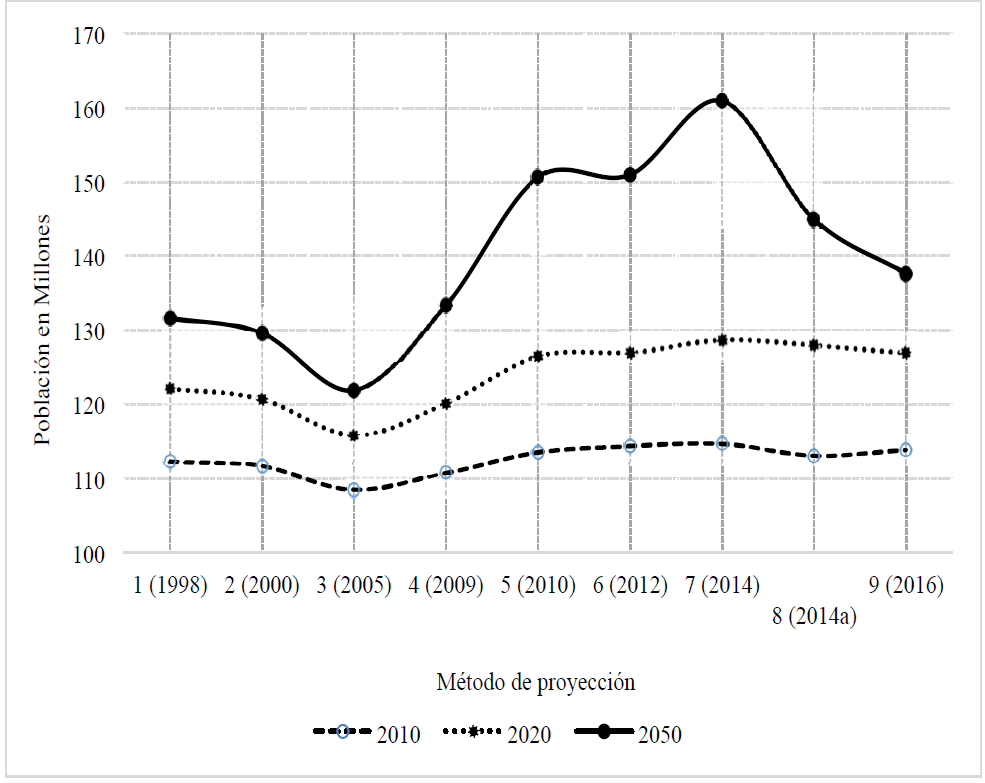
La Figura 4 muestra la variabilidad de diferentes estimaciones de proyecciones de población total mexicana, conformando así un escenario para el análisis de la precisión del estimador. El resultado de las estimaciones de población total mexicana con series de tiempo difusas, aparentemente se constituyen en un promedio entre las estimaciones de otras fuentes, por lo tanto, el resultado es coherente.
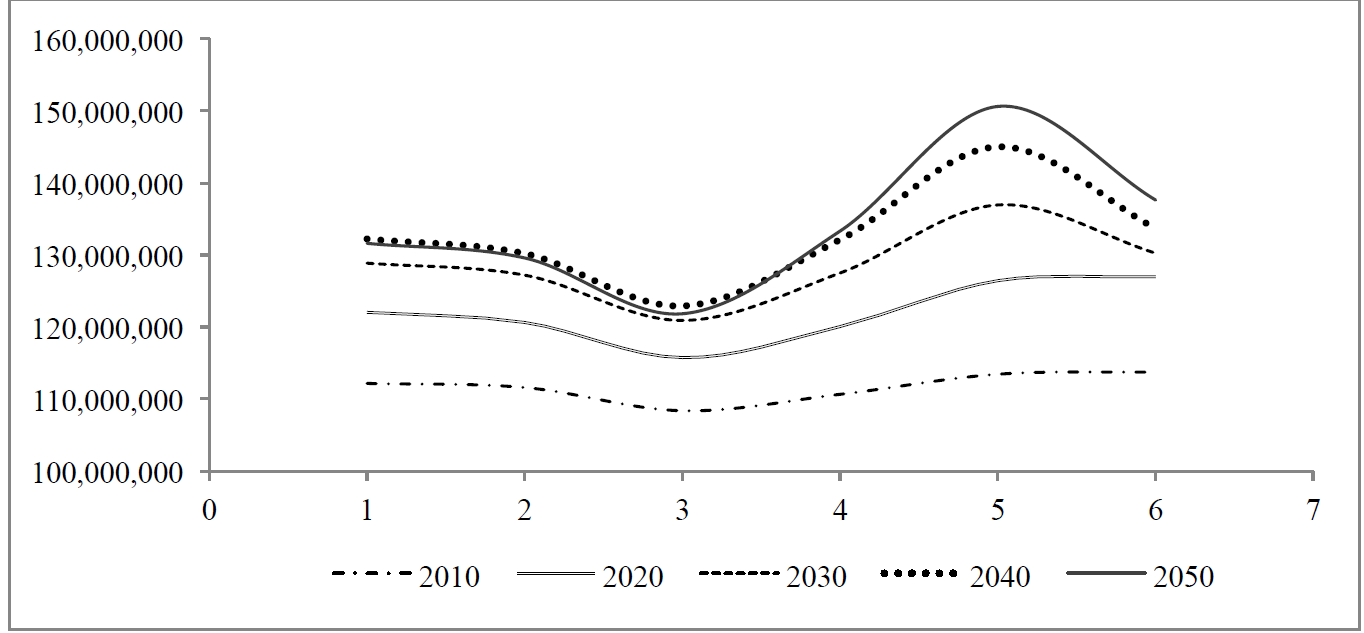
Eje X: Diferentes ejercicios de proyecciones de población
(1) Proyecciones de población de México 2000-2050 con base a los datos disponible en 1998; (2) Proyecciones de población de México 2000-2050 con base a los datos del Censo de 2000; (3) Proyecciones de población de México con base al Conteo 2005; (4) Proyecciones de Población, Latino América y el Caribe, 2009. Observatorio Demográfico, Año 4, nro. 7; (5) Proyecciones de población de México 2010-2050 con base a los datos del Censo de 2010; (6) Proyecciones de población de México 2010-2050 estimada con series de tiempo difusas.
Fuente: elaboración propia.
Figura 4: Diferentes Versiones de la población mexicana proyectada a 2050
La variabilidad de las estimaciones oficiales comparada con nuestros resultados es sorprendente. Se podría decir que los resultados aplicando series de tiempo difusas promedian las tendencias de las diferentes estimaciones. En la Figura 4 de puede observar por ejemplo que para el escenario más lejano, que es el año 2050, en 1998 se estimó que la población mexicana llegaría a un poco más de 130 millones de habitantes; con el censo de 2000 la proyección bajó un poco; con el conteo de 2005 la estimación varia dramáticamente hasta un poco más de 120 millones lo cual hace una diferencia, con las estimaciones anteriores, de 10 millones de habitantes aproximadamente. Los resultados del estudio demográfico de América Latina por la CEPAL, en 2009, muestran una estimación más alta cerca de 130 millones. Posteriormente con el censo de 2010 el valor se dispara a 150 millones de habitantes estimados para 2050 (por el método por componentes). Con el método de series de tiempo difusas, que es la propuesta de la presente investigación, la estimación de la proyección para el año 2050 es un poco más baja de 140 millones de habitantes, que es el punto medio entre 150 y 130, intervalo en el que ha estado variando las estimaciones.
Al incorporar los resultados de otras investigaciones como los de CONAPO (2012) y Guerrero (2014) en el análisis comparativo de las estimaciones de proyección de población total mexicana de 2010, 2020 y 2050 se tienen hallazgos interesantes (véase Tabla 5). La proyección de la población para 2010 en los diferentes momentos y con diferentes técnicas tiene un comportamiento similar alrededor de los 113 millones de habitantes. Para el año 2020 se tiene una curva similar a la de 2010 con un mínimo en el conteo de 2005, con valores superiores posterior al CNPV 2010. En el caso de las estimaciones a 2050, hasta 2009 las estimaciones siguen la misma tendencia que para 2010 y 2020, pero se observa un quiebre, ya que la curva presenta una protuberancia reflejando las estimaciones de CONAPO a 2012 y los resultados de Guerrero (2014) con el método de Lee-Carter. Se espera que a mayor lejanía de tiempo de pronóstico una mayor exogeneidad afecte los resultados, pero la estimación con series de tiempo difusas parece no verse afectada con el mismo fenómeno, ya que la estimación puntual no dista demasiado de las estimaciones anteriores a 2009, es decir se encuentra en un rango coherente (véase Figura 5).
Tabla 5: Cuadro comparativo de la población mexicana proyectada a 2020 y 2050
| Ejercicios de proyección | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1998 (1) | 2000 (2) | 2005 (3) | 2009 (4) | 2010 (5) | 2012 (6) | 2014 (7) | 2014a (8) | 2016 (9) | |
| Año | Proyección 2000-2050 versión 1998 |
Proyección con base al CNPV 2000 |
Proyección con base al CONTEO 2005 |
Proyección CEPAL 2009 |
Proyección con base al CNPV 2010 |
CONAPO 2012 |
Guerrero (2014) Hyndman y Booth |
Guerrero (2014a) Lee- Carter |
Proyección 2016 lógica difusa |
| 2010 | 112 200 000 | 11 1613 906 | 108 396 211 | 110 675 000 | 113 462 004.2 | 114 300 000 | 114 600 000 | 113 000 000 | 113 778 984.3 |
| 2020 | 122 100 000 | 120 639 160 | 115 762 289 | 120 099 000 | 126 441 718.2 | 127 000 000 | 128 700 000 | 128 000 000 | 126 968 922.0 |
| 2050 | 131 600 000 | 129 592 522 | 121 855 703 | 133 341 000 | 150 622 767.3 | 151 000 000 | 161 000 000 | 145 000 000 | 137 632 144.5 |
(1) Proyecciones de población de México 2000-2050 con base a los datos disponible en 1998.
(2) Proyecciones de población de México 2000-2050 con base a los datos del Censo de 2000.
(3) Proyecciones de Población de México con base al Conteo 2005.
(4) Proyecciones de Población, Latino América y el Caribe, 2009. Observatorio Demográfico, Año 4, núm. 7.
(5) Proyecciones de población de México 2010-2050 con base a los datos del Censo de 2010.
(6) Proyecciones de la población de México, 2010-2050. Documento Metodológico CONAPO, 2012
(7) Pronostico estocástico de la población mexicana utilizando modelos de datos funcionales, 2014.
(8) Proyecciones y políticas de población en México, García Guerrero (2014a).
(9) Proyección de la población mexicana con Fuzzy sets (2016).
Fuente: elaboración propia.
Fuente: elaboración propia.
Figura 5: Comparación de diferentes estimaciones de proyección de la población total mexicana con base datos oficiales de censos y conteos
Un aspecto a destacar de la estimación con lógica difusa es que proyecta las unidades de miles y las decenas, característica que da cuenta de la precisión de la estimación. En la Tabla 5 se puede observar que las estimaciones que mantienen esta característica son las basadas en los censos nacionales y el conteo, el resto presenta un redondeo a este nivel cuando el conteo de la población difícilmente cae en números redondeados.
Discusión
El método es robusto y permite modelar el comportamiento no lineal del crecimiento poblacional. El error promedio entre el dato observado y proyectado, en la etapa retrospectiva, es bajo (0.048 por ciento). La Figura 3 nos muestra que la curva proyectada se ajusta y sigue la tendencia histórica de los datos.
Los resultados de proyección de la etapa retrospectiva (historia) de los diferentes años estimados por el INEGI desde 1998 a 2005, resultan muy importantes para la aplicación del método. En este sentido una de las ventajas del método es el uso de pocos datos a la vez que al considerar los grados de membresía se modela lo difuso del comportamiento poblacional, aunque no considera la estructura poblacional.
El modelado con series de tiempo difusas permite considerar la incertidumbre al incorporar el concepto de membrecía, “que tanto pertenece un dato a determinado conjunto de la variable lingüística”. Estos conjuntos borrosos nos permiten considerar resultados alternativos o grados de pertenencia como ocurre en los sistemas reales. Por ejemplo, una tasa de variación en la población respecto al año anterior de tres por ciento se puede considerar baja, mediana, alta, etc.
Otro concepto importante en el modelado con STD es la memoria del pasado. Al considerar en el modelo con series de tiempo difusas los datos anteriores, t - n, donde n, varía de acuerdo a las necesidades y disponibilidad de información de la investigación, se considera el comportamiento del pasado para estimar el futuro.
El análisis comparativo permite validar la coherencia del método. En demografía una de las formas de validar las estimaciones realizadas es a través de las comparación con los resultados de otras instituciones o autores que han realizado estimaciones con diferentes métodos y esta es una buena práctica que añade riqueza a la investigación. En este sentido se evidencia que los resultados obtenidos por STD son coherentes y se mantienen dentro un rango cercano a las otras estimaciones, lo cual se constituye en una ventaja con relación al método Lee-Carter, que como lo indica Uribe (2017) al absorber mayor exogeneidad por el número de variables que maneja el modelo obtiene intervalos de confianza muy amplios.
La disponibilidad de otras estimaciones de proyecciones de la población total mexicana por instituciones oficiales y otras investigaciones que utilizas métodos estocásticos para el caso mexicano brinda una gran riqueza al análisis. Si esta información no existiera no se podría efectuar un proceso de validación exhaustivo como en el presente caso que dispuso de ocho estimaciones, de ocho puntos de comparación. Este hecho permitió realizar un análisis de la precisión de las estimaciones y generar un escenario, sin un modelo o simulación adicional.
De acuerdo a lo anterior, el método de proyección de la población mexicana utilizando STD prueba ser robusto y coherente con las estimaciones oficiales y otros métodos estocásticos aplicados al caso mexicano. Se propone una nueva ruta de investigación que aplique el método a los grupos de edad para así contar con información a niveles desagregados como lo demandan los tomadores de decisión de los diferentes niveles del gobierno.
Finalmente, existen diferentes métodos de estimación y utilizarlos es parte del arte de la conjetura. Las proyecciones de población se realizan con métodos demográficos, econométricos, estocásticos y la presente propuesta con técnicas de la inteligencia artificial como la lógica difusa. El método por componentes tradicionalmente aplicado es muy práctico pero aún mantiene supuestos rígidos. Los métodos estocásticos revelan menor rigidez en los supuestos e incorporan conceptos probabilísticos que son una ventaja en el modelado de sistemas sociales, aunque utilizan muchos parámetros en algunos casos. Así también, los métodos provenientes de la inteligencia artificial que incorporan los conceptos de probabilidad, optimización, simulación y precisión ofrecen una nueva perspectiva sobre proyecciones de población que resulta interesante de considerar en apoyo a la toma de decisiones de políticas de población.

