











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
The agglutination is a widespread phenomenon in the Tunisian Dialect (TD). This reason reveals the importance of this linguistic phenomenon and makes its treatment a necessity. The construction of morphological grammars by relying on a set of finite transducers solves the treatment of agglutination and facilitates lexical analysis. Furthermore, finite transducers provide flexibility for maintenance and reuse.
In addition, the treatment of agglutination via a morphological analyzer allows the recognition of TD words and their different parts. Besides, this morphological analyzer can be integrated in many applications such as automatic annotation of TD corpus, POS-Tagging, TD speech synthesis and automatic translation from TD to Modern Standard Arabic (MSA) and vice versa.
The processing of TD raises other issues, such as the lack of standard spelling because it is never taught in educational institutions. In addition, there are dialectal differences from one city to another. This diversity creates the appearance of non-existent letters in MSA and the existence of words of different origins: French, Maltese, Turkish, etc.
Moreover, the lack of linguistic resources in language platforms like NooJ for TD exacerbates the problems of building robust tools and applications. In this paper, our principal objective is to build morphological grammars based on finite transducers that allow the processing of agglutination in TD.
In order to achieve this goal, we carry out a linguistic study on the phenomenon of agglutination. Subsequently, we need to implement a set of linguistic resources using the NooJ linguistic platform. The present paper is divided into six sections.
In the second section, we present related work dealing with the morphological analyzer for the Arabic dialects and MSA. In the third section, we exhibit our in-depth linguistic study. In the fourth section, we explain our linguistic resources related to the phenomenon of agglutination by explaining the designed dictionary and grammars.
In the fifth section, we experiment and evaluate our constructed grammars and dictionary. Finally, our paper ends with a conclusion and some perspectives.
2 Related Work
The agglutination treatment is done by the construction of morphological analyzers. In what follows, we introduce some works dedicated to MSA and Arabic dialects. Numerous works deal morphologically with MSA such as the Buckwalter Arabic Morphological Analyzer (BAMA) [1], the Standard Arabic Morphological Analyzer (SAMA) [9], the morpho-syntactic analyzer Alkhalil [8], the tool for morphological analysis and disambiguation MADAMIRA [10] and the Arabic morpho-syntactic analyzer using the NooJ linguistic platform [4, 7].
On the one hand, other works consider the approach that treats Arabic dialects using tools designed for MSA. The work of [12] which leans on SAMA and BAMA analyzers to recognize the prefixes and suffixes of the Egyptian dialect. Besides, the authors [5] have developed an Algerian morphological analyzer based on the BAMA and Al-Khalil.
Moreover, the Analyzer for Dialectal Arabic Morphology (ADAM) [13] allows the morphological processing of three dialects (Egyptian, Levantine and Iraqi). These three dialects have many similar morphological characteristics such the negation verbs, propositions and indirect object complements.
On the other hand, other works have chosen another approach that works directly on the dialect. Among these works, the authors [11] have created an a Moroccan dialect electronic dictionary (MDED) in order to develop a Moroccan morphological analyzer.
Besides, the authors [2] have proposed a machine learning method to extract Egyptian morphological lexicons from morphologically annotated corpora, such as inflection classes and associated lemmas.
Concerning TD, the authors [3] are interested in the creation of a morphological analyzer using the Morphological Analyzer and GEnerator for Arabic Dialects (MAGEAD).
This analyzer only processes verbs. The authors [6] have suggested a TD morphological analyzer using aebWordNet, Tunisian lexical dictionary and twenty two predicate rules. This created system does not deal with the standardized TD.
In addition, the authors [15, 16] have sought to create a morphological analyzer processing TD using the NooJ linguistic platform. In fact, the second approach generally gives better morphological analyzers than the first approach in terms of quality because it requires handwritten rules. Thus, this paper is based on [15, 16].
3 Linguistic Study on Agglutination Phenomenon
TD is an agglutinative dialect. Indeed, the agglutination is the association of several grammatical categories in the same word. An agglutinated word has either proclitics, or enclitics, or both. The proclitics are located before the inflected or canonic form and the enclitics are after. In the following, we list the forms of agglutination at the level of verbs, nouns and particles.
3.1 Agglutinated Verbs
The verb is the most complicated grammatical category in terms of agglutination because it has multiple patterns. Regarding the proclitics of a verb, there is the conjunction (CONJ) which is frequently  ‘wa’ (and), the adverb of interrogation (INTERR)
‘wa’ (and), the adverb of interrogation (INTERR)  ‘ch’ (what) and the adverb (ADV)
‘ch’ (what) and the adverb (ADV)  ‘maa’.
‘maa’.
For example, the word  ‘wachmakharraj’ (and what does it take out) gathers all proclitics. Like proclitics, enclitics are found in TD verb. There are several types of enclitics: the adverb of interrogation which concerns yes/no questions (INTERR)
‘wachmakharraj’ (and what does it take out) gathers all proclitics. Like proclitics, enclitics are found in TD verb. There are several types of enclitics: the adverb of interrogation which concerns yes/no questions (INTERR)  ‘chii’, the adverb of negation (NEG)
‘chii’, the adverb of negation (NEG)  ‘ch’ (not), direct object complements (DOC) and indirect object complements (IOC) as shown in Table 1.
‘ch’ (not), direct object complements (DOC) and indirect object complements (IOC) as shown in Table 1.
Table 1 IOC and DOC in Tunisian Dialect
| Persons | DOC | IOC |
| 1st singular person |
 ‘nii’ (me) ‘nii’ (me) |
 ‘lii’ (to me) ‘lii’ (to me) |
| 1st plural person |
 ‘naa’ (us) ‘naa’ (us) |
 ‘lnaa’ (to us) ‘lnaa’ (to us) |
| 2nd singular person |
 ‘k’ (you) ‘k’ (you) |
 ‘lik’ (to you) ‘lik’ (to you) |
| 2nd plural person |
 ‘kum’ (you) ‘kum’ (you) |
 ‘lkum’ (to you) ‘lkum’ (to you) |
| 3rd masculine singular person |
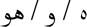 ‘huu’ (him/it) ‘huu’ (him/it) |
 ‘luu’ (to him/it) ‘luu’ (to him/it) |
| 3rd feminine singular person |
 ‘haa’ (her) ‘haa’ (her) |
 ‘lhaa’ (to her) ‘lhaa’ (to her) |
| 3rd plural person |
 ‘hum’ (them) ‘hum’ (them) |
 ‘lhum’ (to them) ‘lhum’ (to them) |
Indeed, negation and interrogation adverbs cannot be together in the same verb. The TD verb structure is defined by the regular expression 1:
For example, the word  ‘wmaawarrawhuuliich’ (they did not show it to me) is the longest structure for a Tunisian verb that represents an entire sentence. This word is composed of the conjunction
‘wmaawarrawhuuliich’ (they did not show it to me) is the longest structure for a Tunisian verb that represents an entire sentence. This word is composed of the conjunction  ‘wa’ (and), the adverb
‘wa’ (and), the adverb  ‘maa’, the verb
‘maa’, the verb  ‘warraw’ (show), the DOC
‘warraw’ (show), the DOC  ‘huu’ (it), the IOC
‘huu’ (it), the IOC  ‘lii’ (to me) and finally the negation adverb
‘lii’ (to me) and finally the negation adverb  ‘ch’ (not).
‘ch’ (not).
3.2 Agglutinated Nouns
Nouns have many agglutination patterns. Regarding the proclitics, definite nouns are preceded by the definite article (PREF)  ‘il’ (the). The prepositions (PREP) that appear before the nouns are as follows:
‘il’ (the). The prepositions (PREP) that appear before the nouns are as follows:
 ‘b’ (by),
‘b’ (by),  ‘l’ (to),
‘l’ (to),  ‘k’ (as),
‘k’ (as),  ‘m’ (from) is the abbreviation for
‘m’ (from) is the abbreviation for  ‘min’,
‘min’,  ‘’a’ (on) is the abbreviation for
‘’a’ (on) is the abbreviation for 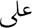 ‘’alaa’ and
‘’alaa’ and  ‘fi’ (in) is the abbreviation for
‘fi’ (in) is the abbreviation for  ‘fii’.
‘fii’.
The combination between the preposition  ‘l’ and the definite article
‘l’ and the definite article  ‘il’ produces the proclitic
‘il’ produces the proclitic  ‘lil’ (to the). The demonstrative pronoun
‘lil’ (to the). The demonstrative pronoun  ‘ha’ (this) stands as a proclitic only before definite nouns.
‘ha’ (this) stands as a proclitic only before definite nouns.
Enclitics are found only for indefinite nouns in the form of an annexation compound. These enclitics are noun suffixes (NSUFF) as shown in Table 2. Formally, The TD definite noun structure is defined by the regular expression 2:
Table 2 Noun suffix in Tunisian dialect
| Persons | Noun suffix |
| 1st singular person |
 ‘ii’ (my) ‘ii’ (my) |
| 1st plural person |
 ‘naa’ (our) ‘naa’ (our) |
| 2nd singular person |
 ‘k’ (your) ‘k’ (your) |
| 2nd plural person |
 ‘kum’ (your) ‘kum’ (your) |
| 3rd masculine singular person |
 ‘huu’ (his/its) ‘huu’ (his/its) |
| 3rd feminine singular person |
 ‘haa’ (her) ‘haa’ (her) |
| 3rd plural person |
 ‘hum’ (their) ‘hum’ (their) |
In addition, the TD indefinite noun structure is defined by the regular expression 3:
For example, the words  ’wibhalmachruu’a’ (and by this project) and
’wibhalmachruu’a’ (and by this project) and  ’wbimachruu’ahum’ (and by their project) are respectively the longest definite noun and indefinite noun structures in TD.
’wbimachruu’ahum’ (and by their project) are respectively the longest definite noun and indefinite noun structures in TD.
The first word is composed of the conjunction  ‘wa’ (and), the preposition
‘wa’ (and), the preposition 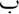 ‘b’ (by), the demonstrative pronoun
‘b’ (by), the demonstrative pronoun  ‘ha’ (this), the definite article
‘ha’ (this), the definite article  ‘il’ (the) and the noun
‘il’ (the) and the noun  ‘machruu’a’ (project).
‘machruu’a’ (project).
The second word is composed of the conjunction  ‘wa’ (and), the preposition
‘wa’ (and), the preposition  ‘b’ (by), the noun
‘b’ (by), the noun  ‘machruu’a’ (project), the noun suffix
‘machruu’a’ (project), the noun suffix  ‘hum’ (their).
‘hum’ (their).
3.3 Agglutinated Particles
Particles are composed of several grammatical categories. Most of them have the phenomenon of agglutination. First of all, prepositions also have proclitics and enclitics. The TD preposition structure is defined by the regular expression 4:
For example, the word  ‘wmaam’ahaach’ (And not with her) is the longest structure for a Tunisian preposition. This word is composed of the conjunction
‘wmaam’ahaach’ (And not with her) is the longest structure for a Tunisian preposition. This word is composed of the conjunction  ‘wa’ (and), the adverb
‘wa’ (and), the adverb  ‘maa’, the preposition
‘maa’, the preposition  ‘m’a’ (with), the noun suffix
‘m’a’ (with), the noun suffix  ‘haa’ (her), and finally the negation adverb
‘haa’ (her), and finally the negation adverb  ‘ch’ (not). Furthermore, the TD personnel pronoun structure is defined by the regular expression 5:
‘ch’ (not). Furthermore, the TD personnel pronoun structure is defined by the regular expression 5:
For example, the word  ‘wmahich’ (She is not) is the longest structure for a Tunisian personal pronoun.
‘wmahich’ (She is not) is the longest structure for a Tunisian personal pronoun.
This word is composed of the conjunction  ‘wa’ (and), the adverb the adverb
‘wa’ (and), the adverb the adverb  ‘maa’, the personal pronoun
‘maa’, the personal pronoun  ‘hiya’ (she) and finally the negation adverb
‘hiya’ (she) and finally the negation adverb  ‘ch’ (not). In addition, the TD demonstrative pronoun structure is defined by the regular expression 6:
‘ch’ (not). In addition, the TD demonstrative pronoun structure is defined by the regular expression 6:
For example, the word  ‘wbihathaa’ (and by this) is the longest structure for a Tunisian demonstrative pronoun. This word is composed of the conjunction
‘wbihathaa’ (and by this) is the longest structure for a Tunisian demonstrative pronoun. This word is composed of the conjunction  ‘wa’ (and), the preposition
‘wa’ (and), the preposition  ‘b’ (by) and the demonstrative pronoun
‘b’ (by) and the demonstrative pronoun  ‘hathaa’ (this).
‘hathaa’ (this).
The conjunction  ‘wa’ (and) marks a great presence in all grammatical categories in TD. In addition, the TD adverb
‘wa’ (and) marks a great presence in all grammatical categories in TD. In addition, the TD adverb  ‘maa’ is frequently found in words without or with the form of interrogation or negation.
‘maa’ is frequently found in words without or with the form of interrogation or negation.
3.4 Effect of Agglutination on Certain Letters
The agglutination phenomenon has an effect on some letters at the end of the word. The correlated letter tā  becomes
becomes  . For example, the noun
. For example, the noun  ‘karhbah’ (a car) after the agglutination becomes
‘karhbah’ (a car) after the agglutination becomes  ‘karhbatha’ (her car). Moreover, the letter shortened alif
‘karhbatha’ (her car). Moreover, the letter shortened alif  ‘aa’ also undergoes a transformation and becomes the letter
‘aa’ also undergoes a transformation and becomes the letter  ‘yi’.
‘yi’.
For example, the preposition  ‘’alaa’ (on) becomes
‘’alaa’ (on) becomes  ‘’aliih’ (on it). Also, the letter hamzah
‘’aliih’ (on it). Also, the letter hamzah  becomes the letter yā hamzah
becomes the letter yā hamzah  . For example, the noun
. For example, the noun  ‘asdikaa’ (friends) becomes
‘asdikaa’ (friends) becomes  ‘asdikaiha’ (her friends).
‘asdikaiha’ (her friends).
4 Proposed Method
The method we propose to deal with the agglutination phenomenon starts with the automatic extraction of all non-repetitive words from the study corpus. Afterwards, the filtering phase allows to eliminate the same words which are written under different inflected forms.
Then, the choice of a canonical form allows to present the collected words. Finally, this canonical form is enriched by adding morphological, lexical and syntactic features. All these phases are established thanks to the dictionary, inflectional and morphological grammars of the linguistic platform NooJ [14].
4.1 Dictionary and Inflectional Grammars
The dictionary is a set of entries that consist of a canonical form, a lexical category and an inflectional grammar if necessary. Fig. 1 shows an example of dictionary entries. The dictionary entries presented in Fig. 1 contain different lexical categories such as definite article (PREF), demonstrative pronoun (DEM), preposition (PREP), noun suffix (NSUFF), verb (V) and noun (N).

Entries with the NW (non-word) code should not be analyzed as real words because they are either proclitic or enclitic. For example, the demonstrative pronoun  ‘hathaa’ (this) is a real word while its abbreviation
‘hathaa’ (this) is a real word while its abbreviation  ‘ha’ is not a real word but it is a proclitic.
‘ha’ is not a real word but it is a proclitic.
Similarly, the preposition  ‘’a’ (on) is not a real word while
‘’a’ (on) is not a real word while  ‘’alaa’ is real word. In fact, inflectional grammars (FLX) generate all the inflected forms of the dictionary entry. As mentioned in Fig. 1, a set of nouns uses an inflectional grammar called ”MFP5”.
‘’alaa’ is real word. In fact, inflectional grammars (FLX) generate all the inflected forms of the dictionary entry. As mentioned in Fig. 1, a set of nouns uses an inflectional grammar called ”MFP5”.
This grammar is presented by a transducer in Fig. 2. This transducer is dedicated to feminine nouns having the scheme  ‘fa’alalah’ in the singular and transforming into the other scheme
‘fa’alalah’ in the singular and transforming into the other scheme  ‘fa’alil’ in the plural. For example, the canonical form
‘fa’alil’ in the plural. For example, the canonical form  ‘bisklah’ (bike) remains the same in the first path and becomes
‘bisklah’ (bike) remains the same in the first path and becomes  ‘bsaakil’ (bikes) in the second path.
‘bsaakil’ (bikes) in the second path.

In addition, the TD verb (V) in Fig. 1 is a hollow verb. Thus, it uses an inflectional grammar called ”VERBE2” presented by a transducer in Fig. 3. Indeed, this transducer allows to generate hollow verbs whose root origin having the second letter is  ’w’ and transforming into the letter
’w’ and transforming into the letter  ‘a’.
‘a’.

For example, after conjugation in the present tense (P) with the third person masculine singular (3+m+s) of the Tunisian canonical form  ‘maat’ (to die), it becomes the conjugated verb
‘maat’ (to die), it becomes the conjugated verb  ‘ymuut’ (he dies).
‘ymuut’ (he dies).
4.2 Morphological Grammars
To deal with the phenomenon of agglutination, we establish two morphological grammars based on a set of nested finite transducers.
For TD noun agglutination, we construct several transducers, among which the nested transducer shown in Fig. 4 solves the definite noun problem. Indeed, the nested transducer in Fig. 4 contains a subgraph called ”PrefNom” and two nodes. The first one recognizes the first lemma ($1L) as a definite article (PREF) and the second node recognizes the category ($2C), the inflectional feature ($2F) and the semantic and syntactic feature of the second lemma ($2L). Fig. 5 shows the PrefNom transducer and its PREF subgraph. In the first transducer, the name is stored in the variable ($N) indicating that the loop <L> means a sequence of letters.


Thus, the contents of the variable ($N) are verified by a dictionary lookup. With the same variable principle, the second transducer recognizes the definite article  ‘il’ (the). For verbs, we also establish several transducers, for example, the set of transducers in Fig. 8 solves the negation form of verbs.
‘il’ (the). For verbs, we also establish several transducers, for example, the set of transducers in Fig. 8 solves the negation form of verbs.



The first transducer is the main graph contains a subgraph called ”AdvVNeg” and three nodes. The first one recognizes the first lemma ($1L) as an adverb (ADV). The second node is explained above. The third node recognizes the third lemma ($3L) as a negation particle (NEG). In addition, the second transducer recognizes the adverb and the negation particle by its two subgraphs called ”ADV” and ”NEG” respectively.
In addition, we dedicate a set of finite state transducers to deal with TD particles. For example, the two finite transducers illustrated in Fig. 6 treat a specific type of agglutination for prepositions explained below. The first transducer is the main graph that contains a subgraph called ”Prep_spcNsuff” and two nodes.
This subgraph which is the second transducer is used to recognize prepositions that undergo a transformation from the shortened letter alif  ‘aa’ to the letter
‘aa’ to the letter  ‘yi’. This problem is solved by using two variables. The first variable ($MVide) stores the unchanged part and the second stores the changed part. Thus, the code ($MVide#
‘yi’. This problem is solved by using two variables. The first variable ($MVide) stores the unchanged part and the second stores the changed part. Thus, the code ($MVide#  = :PREP) adds the letter
= :PREP) adds the letter  ‘aa’ to the first variable and then checks its existence in the dictionary.
‘aa’ to the first variable and then checks its existence in the dictionary.
In addition, the subgraph called ”NSUFF” recognizes the noun suffix in TD. In conclusion, we construct 95 finite state transducers to solve the different forms of the agglutination phenomenon for all grammatical categories in TD; among which 23 main transducers for agglutinated verbs, 13 main transducers for agglutinated nouns and 18 main transducers for agglutinated particles.
5 Experimentation and Evaluation
To experiment with our constructed linguistic resources on the collected test corpus, we have implemented our lexical resources in the NooJ linguistic platform. In fact, the dictionary is edited and saved in the file “barcha.dic” which is extended by the file “barcha.nod” after compilation.
Up to now, our NooJ morphological analyzer generates, from 4422 entries, 169815 forms as presented in Fig. 7. Moreover, the morphological grammars allowing the resolution of agglutination are stored in the file ”agglutination.nom” and are implemented by finite transducers.
As already indicated, to evaluate our resources, we have collected a corpus from Tunisian dialect novels and social networks such as Facebook and Twitter. The test corpus contains 3300 sentences and 18680 words. The evaluation of our NooJ prototype is based on the recognition of TD words. Thus, we used the known metrics: recall, precision and f-measure.
We obtain the following results presented in Table 3. More precisely, Table 4 shows the results obtained of the prototype application. It shows how well our grammars recognize nouns, verbs, particles and adjectives. Table 4 shows that our prototype recognizes 89% of the total words.
Table 3 Summarizing the obtained metrics for all words
| Corpus | Recall | Precision | F-measure |
| 18680 | 0.89 | 0.95 | 0.91 |
Table 4 Obtained results for all words
| Noun | Verb | Particle | Adjective | Total | |
| Corpus | 8450 | 3260 | 5740 | 1140 | 18680 |
| Correct recognized word | 7940 | 2820 | 4910 | 990 | 16660 |
93% of nouns in the corpus are recognized. Some unrecognized nouns are compound proper names, city names or company names. Moreover, our prototype detects 86% of verbs, particles and adjectives in the corpus. In addition, a set of unrecognized words belong entirely to MSA.
For example,  ‘sata’udina’ (you will come back) is not a Tunisian verb because the proclitic
‘sata’udina’ (you will come back) is not a Tunisian verb because the proclitic  ‘sa’ (will) does not belong to the Tunisian dialect as well as the flexion of the verb. Another example, the adjective
‘sa’ (will) does not belong to the Tunisian dialect as well as the flexion of the verb. Another example, the adjective  ‘ha’iriin’ (worried) it is not considered as a Tunisian adjective because the correct writing is
‘ha’iriin’ (worried) it is not considered as a Tunisian adjective because the correct writing is  ‘hayiriin’.
‘hayiriin’.
Among the undetected words, these contain a repetitive series of letters such as  ‘barchaaaaa’ (many). In fact, our prototype detects all demonstrative, relative and personal pronouns as well as interrogative adverbs. Moreover, agglutinated words are well recognized in different grammatical categories in TD.
‘barchaaaaa’ (many). In fact, our prototype detects all demonstrative, relative and personal pronouns as well as interrogative adverbs. Moreover, agglutinated words are well recognized in different grammatical categories in TD.
For example, the linguistic analysis of the Tunisian sentence shown in Fig. 9:  ‘maa kaaluulhaach ‘alhkikah’ (they do not tell her about the truth) is as follows. We get that the word
‘maa kaaluulhaach ‘alhkikah’ (they do not tell her about the truth) is as follows. We get that the word  ‘maa’ is recognized as an adverb (ADV).
‘maa’ is recognized as an adverb (ADV).

Moreover, the recognized word  ‘kaaluulhaach’ (tell) is a verb (V) conjugated in the past tense (I) with the third person (3) plural (p) having recognized enclitics:
‘kaaluulhaach’ (tell) is a verb (V) conjugated in the past tense (I) with the third person (3) plural (p) having recognized enclitics:  ’l’ (to) as a preposition and
’l’ (to) as a preposition and  ’haa’ (her) as a noun suffix which are an enclitic IOC and
’haa’ (her) as a noun suffix which are an enclitic IOC and  ’ch’ (not) as an adverb of negation (NEG).
’ch’ (not) as an adverb of negation (NEG).
Finally, the recognized word  ‘’alhkikah’ (about truth) is a singular (s) feminine (f) noun (N) that is preceded by the definite article (PREF)
‘’alhkikah’ (about truth) is a singular (s) feminine (f) noun (N) that is preceded by the definite article (PREF)  ‘il’ (the) and also by the preposition (PREP)
‘il’ (the) and also by the preposition (PREP)  ‘’a’ (about).
‘’a’ (about).
Thanks to the NooJ linguistic platform, we can locate patterns in the test corpus and detect all the different morphological, inflected, and agglutinated forms of different grammatical categories. For example, to locate a specific verb, we simply write < > in the regular expression box.
> in the regular expression box.
An excerpt of the result of this location is shown in Fig. 10. Among the results, there are just inflected forms like the words  ‘kult’ (I said),
‘kult’ (I said),  ‘nkuul’ (I say), and several agglutinated forms. Precisely, there are words with only proclitics like
‘nkuul’ (I say), and several agglutinated forms. Precisely, there are words with only proclitics like  ‘wkult’’ (and I said), others with only enclitics like
‘wkult’’ (and I said), others with only enclitics like  ‘nkuulhaa’ (I said it).
‘nkuulhaa’ (I said it).


The TD words in our dictionary have different origins like French and Turkish. The unrecognized words have a typographical error or are MSA words. We consider that the results obtained are ambitious. Moreover, they can be improved by increasing the coverage of the dictionary and by adding more morphological rules.
6 Conclusion and Perspectives
In the present paper, we have created a set of linguistic resources for TD in the NooJ language platform. These resources that deal with the agglutination phenomenon are realized through a set of nested finite transducers and are based on a deep linguistic study.
All these resources allow us to construct a NooJ prototype. Moreover, we have demonstrated the efficiency of our NooJ prototype. Thus, the evaluation is performed on a set of sentences belonging to the test corpus. The obtained results are ambitious and show that several agglutinated words can be detected and resolved.
As perspectives, we will increase the coverage of our dictionaries. Furthermore, we will improve our grammars by adding morphological rules that recognize other linguistic phenomena.

