











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
Las ontologías han estado presentes en las ciencias de la computación desde 1980, cuando fueron definidas como “una especificación de una conceptualización” (Gruber, 1995: 908) o “teorías de contenido acerca de los tipos de objetos, propiedades de los objetos y relaciones entre los objetos que son posibles de especificar en un dominio de conocimiento” (Chandrasekaran, Josephson y Benjamins, 1999: 20). Durante el periodo de 1980 a 1992 el interés de las ciencias computacionales hacia las ontologías fue mediano (García Marco, 2008), debido a su aislamiento en bases de datos y proyectos locales. Luego, de 1992 a 2018, el número de trabajos aumentó, soportado por la inteligencia artificial, las bases de datos, la ingeniería del software y la masificación de internet (Jurisca, Lylopoulos y Yu, 2004).
Al principio, las ontologías fueron herramientas exclusivas del ámbito computacional que las empleaba para modelar mundos en agentes artificiales; sin embargo, recientemente se han formalizado como un sistema para la organización del conocimiento (SOC)1 y convertido en un tema de interés de las ciencias documentales, cuyas actividades están asociadas a la organización de dominios2 y recursos de información en contextos digitales.
En lo que respecta a la bibliotecología, el término ontología ha estado presente desde la década de 1970, asociado “con aspectos epistemológicos de la Information Science […] o bien con implicación de la Ontología -como rama filosófica- en el diseño de sistemas para la organización del conocimiento” (García-Marco, 2008: 123). En 1997 el vocablo fue introducido en la literatura de la especialidad por Vickery, en su artículo “Ontologies”, publicado en Journal of Information Science y, a principios del siglo, Hodge (2000) las instaura como un SOC para ambientes digitales.
Las ontologías son un sistema para la organización del conocimiento con amplio espectro tipológico. Van Heijst, Schreiber y Wielinga (1997) las categorizan en ontologías terminológicas, ontologías de modelado de información, ontologías de aplicación, ontologías de dominio y ontologías genéricas.
Entre los diversos tipos, para la bibliotecología son esenciales:
Las ontologías terminológicas. Funcionan como otros sistemas para la organización del conocimiento (encabezamientos de materia, tesauros) pero tienen mayor potencial porque presentan rasgos atributivos y relacionales complejos. En la parte atributiva permiten la vinculación terminológica-conceptual mediante la adhesión de definiciones o anotaciones que posibilitan identificar con precisión una etiqueta lingüística. En la parte relacional, superan incluso a los tesauros, ya que mientras éstos poseen relaciones BT (Broad Term), NT (Narrow Term) y RT (Related Term), las ontologías, usando RDF (Sujeto-Predicado-Objeto), pueden crear cualquier tipo de asociación entre elementos conceptuales.
Las ontologías modeladoras de información. Estructuran datos de manera conceptual, categorial y relacional. Se adhieren al precepto de las bases de datos conceptuales y a los fundamentos de los datos enlazados al generar información compresible para los humanos y los agentes artificiales. Pueden simbolizar y ordenar de modo semántico conjuntos de datos/información de naturaleza muy diversa.
Desde el 2000, el estudio teórico sobre las ontologías en la bibliotecología ha sido tratado por autores como Bergman (2007), King y Reinold (2008), Lacasta, Nogueras-Iso y Zarazaga Soria (2010) y Moreira y Santos Neto (2014); no obstante, sus implementaciones son un asunto incipiente. Al realizar una búsqueda exploratoria sobre el tema, empleando el término de búsqueda “Ontologies and Applications/Implementations and Library Science” se recuperan 180 documentos;3 no obstante, tras la revisión de éstos, el número se reduce, pues sólo entre 10 y 20 documentos son verdaderas implementaciones mientras que el resto contiene los elementos de búsqueda en alguna parte del texto.
A partir de la búsqueda exploratoria, se confirma el estado primario de aplicación de las ontologías. Considerando lo anterior, el presente artículo tiene como objetivo determinar y mostrar las implementaciones que las ontologías pueden tener en la bibliotecología. La hipótesis de la que se parte es que al ser un SOC cumplirán con funciones de representación de dominios e indización de recursos de información.
Metodología
La metodología empleada para determinar y mostrar las aplicaciones de las ontologías se formó de dos técnicas: revisión bibliográfica y análisis de casos.
Revisión bibliográfica. Se consideraron documentos posteriores al 2000 que constituye el cúmulo de la literatura relevante. Los autores consultados fueron Hodge (2000), García Marco (2007), Zeng (2008), King y Reinold (2008), Abbas (2010), Ramalho y Lopes Fujita (2011), Bath (2013) y Moreira y Santos Neto (2014).
Análisis de casos. Se hizo una selección bajo los siguientes criterios: Obtención de casos. Se consultó el descubridor de información de la Dirección General de Bibliotecas de la Universidad Nacional Autónoma de México (http://dgb.unam.mx/) que contiene las bases bibliotecológicas INFOBILA, Library and Information Science Source y Library and Information Science Abstracts (LISA). Además, se buscó en todas las bases que centraliza el descubridor porque, frecuentemente, los trabajos sobre implementaciones de ontologías aparecen en las revistas del dominio tratado en el instrumento. Los términos de búsqueda empleados fueron:
Ontologies and Aplications and Libraries
Ontologies and Implementations and Libraries
Ontologies and Information Representation and Libraries
Ontologies and Information Organization and Libraries
Ontologies and Information Sources and Libraries
Selección de casos. Se establecieron los criterios siguientes:
Trabajos con aplicaciones desde el ámbito de la bibliotecología.
Estudios con validación autoral personal o corporativa.
Investigaciones formales y explícitas, con objetivos, marco teórico, metodología, resultados, conclusiones, etcétera.
Tras aplicar los criterios establecidos, se obtuvieron 15 casos en un rango de planeación y construcción que comprende de 2008 a 2016.
Una vez determinados los documentos para la revisión bibliográfica y los casos que se estudiarían, se realizó un análisis detallado, poniendo atención a las menciones de aplicación. En la revisión bibliográfica, los autores establecen verbalmente las implementaciones; tales menciones se tomaron como primer elemento para crear una categorización. Luego, en los estudios de caso hubo mayor especificidad asociada a sus aplicaciones.
Finalmente, considerando los resultados de ambos procesos, se crearon cinco categorías de aplicación:44 1) representación estructurada de dominios, 2) indización de recursos de información digitales, 3) generación de aprendizaje entre estudiantes y usuarios, 4) construcción de la web semántica, y 5) estructuración de redes de datos enlazados.
En los apartados siguientes se describen y ejemplifican las aplicaciones encontradas.
Presentación y análisis de los resultados
Ontologías para la representación estructurada de dominios
En el marco del saber humano persisten numerosos dominios (Física, Genética, Magia, Mitología, etc.) tangibles o abstractos. En un estado existencial el saber de un dominio se encuentra en la mente de las personas y en los recursos generados (libros, artículos, presentaciones, videos, etc.), mientras que, de forma activa, es información que se transmite entre individuos, entre generaciones y, actualmente, entre agentes artificiales. Así, el dominio “Medicina” existe, pero acercarse a un espacio de saber tan amplio en aras de recuperar información es una aventura. Por tanto, para que sea accesible deberá representarse y segmentarse en subáreas como “Neurología” y “Cardiología”, o bien temas específicos como “Alzheimer” o “Cardiopatía congénita”.
La representación estructurada de dominios es una tarea antiquísima que, al principio, se fundamentó en propuestas individuales; sin embargo, con la instauración de la bibliotecología, se crearon sistemas formales para esquematizar el saber humano. Hasta 1960, tales estructuras estuvieron asociadas a los recursos impresos y la biblioteca física y consistieron en listados de temas, encabezamientos de materias, tesauros y clasificaciones; no obstante, el auge tecnológico posterior a 1980 generó nuevos sistemas entre los que se encuentran las taxonomías digitales, las folksonomías, los mapas tópicos y las ontologías.
Un trabajo en el que se observa el potencial de las ontologías en la representación estructurada de un dominio es “Unifying Heterogeneous and Distributed Information about Marine Species Through the Top Level Ontology Marine TLO” (Tzitzikas et al., 2014), cuya base es un modelo de representación acorde a los estándares de la web semántica que denomina científicamente las especies marinas y les asigna atributos (Figura 1).
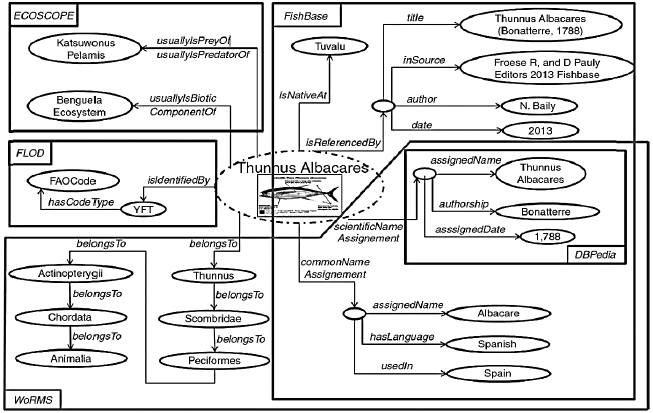
Fuente: Tzitzikas et al. (2014: 17)
Figura 1 Representación semántica-atributiva en ontología de especies marinas
Otro caso relevante es “Faceted Ontological Model for Brain Tumour Study” (Subhashis y Sayon, 2016), cuyo objetivo es brindar a los usuarios una representación estructurada del dominio que posibilita la identificación de los distintos tipos de tumores cerebrales bajo una estructura categorizadora (Figura 2) que sirve como base para una ontología del dominio que vincula los tumores cerebrales con los médicos especialistas y los tratamientos existentes.
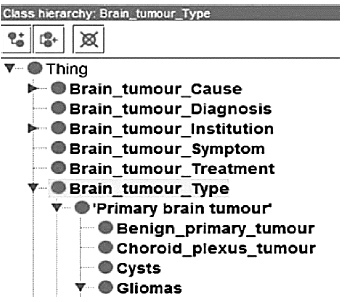
Fuente: Subhashis y Sayon (2016: 9)
Figura 2 Estructura categorial de ontología de tumores cerebrales
A partir de los casos se observa que las ontologías ofrecen mayores ventajas para la estructuración de dominios que otros sistemas (tesauros, taxonomías) porque incluyen todos los beneficios de éstos y agregan atributos, definiciones y relaciones asociadas con conceptos. Otra ventaja reside en su presentación, ya que pueden observarse como estructuras alfabéticas, jerárquicas o gráficas-desplegables que permiten la exploración temática de dominios, establecida en FRSAD-Requisitos Funcionales para Datos de Autoridad de Materia (IFLA, 2013) como un aspecto esencial.
Ontologías para la indización de recursos de información digitales
Las ontologías asociadas a la indización de recursos de información digitales actúan como vocabularios controlados, y desde la perspectiva de Lacasta, Nogueras-Iso y Zarazaga Soria (2010) son una continuidad de los SOC en el contexto digital. Sobre el tema señalan que
Teniendo en mente el incremento de la precisión terminológica, el uso de vocabularios controlados simples ha sido progresivamente desplazado por el uso de modelos de conocimiento más sofisticados […]. Los modelos de conocimiento almacenados en papel (taxonomías, tesauros) por las bibliotecas y otras instituciones han sido llevados al ambiente computacional y trasformados en modelos ontológicos formales que proveen un alto nivel de semántica (Lacasta, Nogueras-Iso y Zarazaga Soria, 2010: viii).
Las ontologías en funciones de indización dan prioridad al control terminológico-conceptual:
[…] se comparan con los vocabularios controlados desarrollados para ser utilizados por un dominio específico […]. Contienen las especificaciones formales explícitas de los términos en un dominio y las relaciones entre ellos. Sin embargo, donde difieren de los vocabularios controlados es en las diversas formas en que se construyen o representan. Por ejemplo, en lugar de usar una estructura jerárquica estricta para mostrar relaciones, la ontología se puede estructurar utilizando un gráfico no lineal que delimita los términos y las relaciones mediante facetas (Abbas, 2010: 165).
La presencia de ontologías para la indización se ha vuelto un tema de interés de bibliotecas digitales y repositorios de información en donde se ha planteado cómo debe ser el acceso temático en ambientes web. Ante tal cuestionamiento, se tienen dos posibilidades: asignar temas con herramientas como encabezamientos de materias y tesauros, asentados en un metadato temático, o bien, optar por construir herramientas indizadoras asociadas a la web semántica tales como mapas tópicos u ontologías con visualización gráfica.
Una ontología en tarea indizadora es “Ontology-Based Search and Document Retrieval in a Digital Library with Folk Songs” (Nisheva Pavlova y Pavlov, 2011), cuyo objetivo es construir una biblioteca digital de canciones folclóricas búlgaras. Se forma de distintas ontologías (Figura 3) a partir de las cuales se crea un vocabulario controlado ideal para el dominio.

Fuente: Nisheva Pavlova y Pavlov (2011: 159)
Figura 3 Propuesta terminológica para ontología de canciones folclóricas
Es un sistema que posee términos precisos como “Oath Songs” [Canciones de juramento] o “Wooing Songs” [Canciones de conquista/galanteo]. En su construcción, el asentamiento de descriptores siguió un proceso de análisis de contenido, definición del tema tratado en cada canción, simbolización lingüística y normalización terminológica.
Otro caso interesante es “A Water Conservation Digital Library using Ontologies” (Ziemba, Cornejo y Beck, 2010), diseñada para gestionar temáticamente la Biblioteca Digital de Conservación del Agua en Florida, que soporta una colección dinámica de varios tipos de recursos con descriptores especializados, por ejemplo, “orinales de alta eficiencia” o “inodoros de absorción” (Figura 4).

Fuente: Ziemba, Cornejo y Beck (2010: 207)
Figura 4 Descriptores de ontología de conservación del agua
Un tercer caso es “Ontología de fenómenos naturales: planeación y diseño” (Suárez Sánchez y Rodríguez García, 2017), que tiene por objetivo servir como herramienta indizadora de fotografías digitales. Se compone de dos estructuras: conceptual y categorial, y establece relaciones particulares para el dominio (Figura 5).
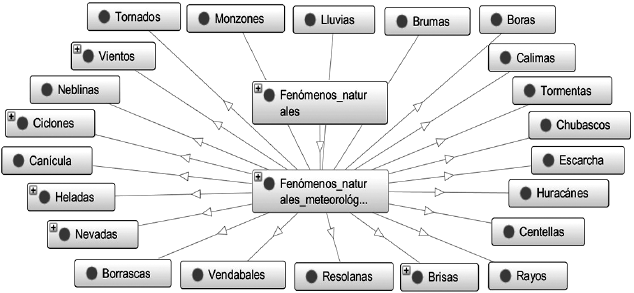
Fuente: Suárez Sánchez y Rodríguez García (2017: 909)
Figura 5 Visualización gráfica-desplegable de ontología de fenómenos naturales
Las ontologías en funciones de indización igualan las funciones de los tesauros en precisión terminológica y normalización. Pero van más alla, los superan en la parte relacional y en el uso de tripletas RDF-Marco de Descripción de Recursos (sujeto-predicado-objeto) y lenguaje OWL-Lenguaje Ontológico Web, mediante los cuales es posible crear estructuras conceptuales, categoriales y relacionales comprensibles para los humanos y las máquinas, integrando rasgos híbridos que retoman aspectos de los vocabularios controlados y los sistemas clasificatorios.
Ontologías para la generación de aprendizaje entre estudiantes y usuarios
Una función poco mencionada de las ontologías reside en su capacidad para generar aprendizaje entre los usuarios de la biblioteca, estudiantes de bibliotecología o estudiantes en general. Son aplicables tanto en educación presencial como a distancia y actúan como mapas disciplinares en los que se explora y conoce el dominio, los temas, los subtemas, los conceptos, las instancias específicas, etcétera.
Allert, Markkanen y Richter (2006) señalan su aplicación para:
Apoyar la ejecución de actividades de aprendizaje,
Anotar y organizar objetos compartidos,
Fomentar aprendizaje metacognitivo, y
Evaluar competencias de aprendizaje.
En la educación a distancia son empleadas de modo similar a los mapas cognitivos o bases de datos conceptuales, promoviendo el aprendizaje autodirigido.
Un ejemplo de ontología en tal implementación es “Cantabria’s Heritage Ontology” (Hernández Carrascal, 2008). Su objetivo es contribuir a la generación de conocimiento sobre el patrimonio cultural de Cantabria y la promoción turística de la región. Aglutina información sobre bienes culturales de Cantabria en múltiples aspectos: arqueológico, industrial, científico, cultural, etnográfico, entre otros.
Otro caso notable es “The Neurological Disease Ontology” (Jensen et al., 2013). Su estructura va más allá de ser una organización de información lineal o temática, se forma de categorías y relaciones visuales en las que el alumno puede hacer consultas directas y navegar. Frecuentemente, a partir de un grupo de síntomas los médicos establecen un diagnóstico, entonces una ontología en la que se asocian las diversas enfermedades con su sintomatología es efectiva para discernir sobre el padecimiento. Asimismo, permite observar, bajo un nodo categorizador, enfermedades cercanas que pueden presentar traslape sintomático, por ejemplo: “Enfermedad de Alzheimer” y sus clases “Enfermedad típica de Alzheimer” o “Enfermedad de Alzheimer atípica” (Figura 6).
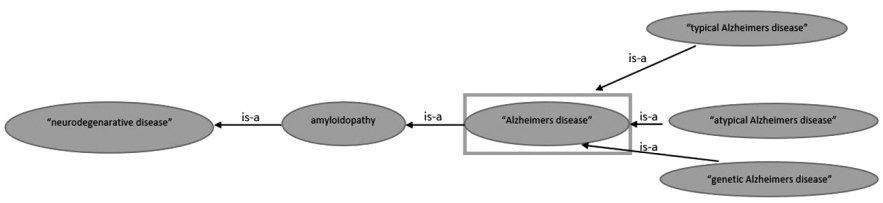
Fuente: Jensen et al. (2013: 20)
Figura 6 Nodos categorizadores en ontología de enfermedades neurológicas
El despliegue gráfico-categorial que poseen las ontologías es un aspecto crucial para el aprendizaje porque las caracteriza como herramientas dinámicas que posibilitan la representación y organización semántica de información (Figura 7).

Mediante la exploración, el usuario entra en contacto con nodos que develan la estructura del dominio. En el ejemplo anterior se observa que a partir de la categoría “Sistema solar” se despliegan las subcategorías “Asteroides” “Satélites”, “Planetas”, etc. Tal expansión de elementos compositivos puede derivarse de forma continua hasta niveles más profundos.
En la creación de ontologías para la generación de aprendizaje, los editores aunados a visualizadores han tenido un rol importante ya que proporcionan diversas ventajas para la creación de esquemas interactivos en los que el usuario extiende clases, visualiza definiciones y detecta relaciones a nivel conceptual.
Aunque las ontologías tienen gran potencial en la generación de aprendizaje, su estudio e implementación en espacios educativos, de entre todas sus funciones, es la menos tratada.
Ontologías aplicadas a la construcción de la web semántica
La web es un espacio con millones de usuarios que al paso del tiempo se ha tornado indispensable en distintos aspectos de la vida: académico, laboral, económico, gubernamental, etc. Pese a su relevancia, es un cúmulo de datos que presenta tres grandes problemas: almacenamiento desorganizado, formato HTML enfocado más a la maquetación que al contenido y estructuración poco útil para los recuperadores de información (Berners-Lee, Hendler y Lassila, 2001).
Desde su surgimiento, la web ha mejorado sus tecnologías, pero el problema de la organización no ha sido resuelto. Como resultado, a principios del presente milenio, Tim Berners-Lee −creador de la www− propuso una web con semanticidad, es decir, organizada a partir de su contenido y sus relaciones. La web semántica
[…] no es una web separada sino una extensión de la actual, en la cual la información es ofrecida con significado bien definido, permitiendo a las computadoras y las personas trabajar en cooperación. […] La web semántica dotará de estructura al contenido significativo de las páginas web, creando un ambiente donde los agentes de software recorriendo página tras página pueden fácilmente llevar a cabo tareas de los usuarios. (Berners-Lee, Hendler y Lassila, 2001: 34)
En el marco de la web semántica, las ontologías son un aspecto crucial, incluso han sido definidas por el W3C como un aspecto necesario para que ésta llegue a consolidarse. Sobre el tema, Sánchez Jiménez y Gil Urdiciain (2007: 552) mencionan lo siguiente:
Existen varios paradigmas y muchas formas concretas de representar del conocimiento [sic], pero las ontologías parecen ser la mejor forma en el ámbito de la web semántica […]. Su utilización es clave desde el punto de vista de la reutilización del conocimiento en contextos diferentes al original, ya que por su estructura y capacidad de formalización permiten la puesta en relación de diferentes schemata RDF.
La creación de ontologías que apoyen la recuperación en la web abrirá el camino a las búsquedas semánticas mediante sentencias RDF5 formadas por tripletas sujeto-predicado-objeto. Lo que implica que un sistema estará en posibilidades no sólo de responder a búsquedas expresadas en etiquetas o términos, por ejemplo, “Fenómenos naturales”, sino que podrá dar respuesta a búsquedas más complejas como “¿quién en el Centro de Ciencias de la Atmósfera estudia los fenómenos naturales?” (Figura 8).
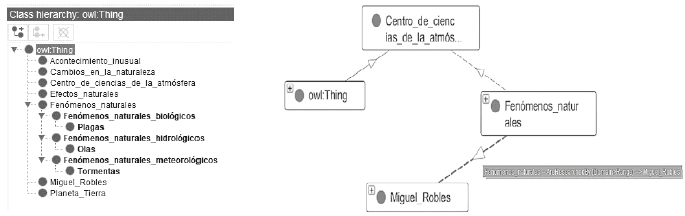
Fuente: elaboración propia, 2019
Figura 8 Estructura jerárquica-visual de ontología para la web semántica
Una vez mencionada la implementación, surge una pregunta esencial: ¿qué función tienen los bibliotecólogos en la construcción de ontologías para la web semántica y la misma web semántica? Aunque la web semántica parece ser un asunto exclusivo de expertos en cómputo e ingenieros ontológicos, la tarea del bibliotecólogo es más relevante de lo que parece. “La formación y experiencia de esta clase de profesionales hacen de ellos firmes candidatos a jugar un papel preferente en el desarrollo de la web semántica” (Pedraza Jiménez, Codina y Rovira, 2007: 577). Una primera tarea se encuentra asociada a la descripción de los recursos que albergará la web semántica: descripción de metadatos, granularidad de recursos y asociaciones de descripciones de recursos con URI, mientras que otra consiste en la construcción de ontologías de dominios, recursos y creadores de recursos.
Ontologías para la estructuración de redes de datos enlazados
Bajo el término datos enlazados (Linked Data (LD)) se hace referencia al uso de datos en la web para crear vínculos entre elementos de un mismo recurso o de recursos diversos, de modo que sean legibles por las máquinas (Bizer, Heath y Berners-Lee, 2008). Tales datos se enlazan desde tres perspectivas: sintáctica, semántica e informática. Desde la parte sintáctica, se establecen estructuras con RDF sujeto-predicado-objeto. A partir de la semántica, se instauran relaciones significativas de diversa naturaleza (equivalencia, jerarquía, asociación, creación, datos de edición, materia prima, producto generado, etc.). Desde la informática, se posibilita la comprensión de tales relaciones en un sistema.
La web tradicional bien puede ser vista como un grupo de silos sin asociación, mientras que los datos enlazados en la web posibilitarán un espacio interconectado en el que los recursos tendrán una descripción unitaria alta e integrarán aspectos de contenido con asociaciones significativas al mismo recurso o a otros (Figura 9).
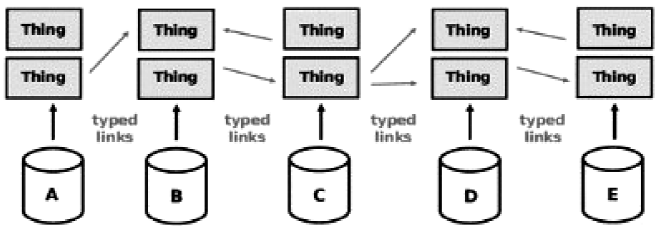
La adopción de las mejores prácticas en datos enlazados conducirá a la vinculación de la web, conectando datos de diversos dominios como gente, compañías, libros, publicaciones científicas, filmes, música, televisión y programas de radio, tratamientos (farmacéuticos, clínicos, genéticos, alimenticios), comunidades en línea, datos estadísticos, revistas, etc. El objetivo final es que los usuarios esbocen una búsqueda inicial y, a partir de ésta, tengan posibilidades de navegación hacia otros recursos asociados a su tema de interés.
Entre los datos enlazados y las ontologías coexiste una estrecha relación en tanto que éstas posibilitan la creación de redes, ya sea a nivel de un recurso o entre varios recursos. A nivel recurso, se pueden establecer asociaciones entre los atributos de una entidad bibliográfica (Figura 10):

mientras que entre recursos diversos crean vinculaciones a partir de elementos seleccionados (Figura 11):
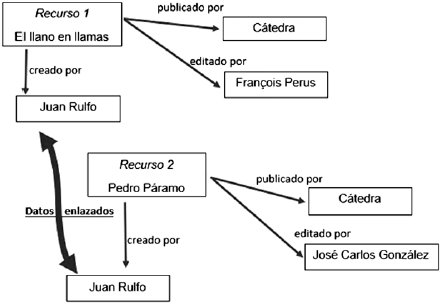
Crear datos enlazados es un tema actual de la bibliotecología que favorecerá la exploración a nivel de sistemas organizadores y recuperadores. El fortalecimiento de tal actividad redundará en asociaciones útiles para los usuarios en la recuperación de información.
Discusión y conclusiones
Las ontologías tuvieron su origen en las ciencias computacionales; sin embargo, derivado de sus características, se han extendido a otras disciplinas. Tal es el caso de la bibliotecología, donde tienen cinco aplicaciones: 1) representación estructurada de dominios, 2) indización de recursos de información digitales, 3) generación de aprendizaje entre estudiantes y usuarios, 4) construcción de la web semántica, y 5) estructuración de redes de datos enlazados.
A partir de los resultados obtenidos, es posible afirmar que, en la bibliotecología, como se planteó en la hipótesis, las ontologías pueden funcionar como un SOC empleado para la representación de dominios y organización de recursos de información. Pero, además, se detectaron tres implementaciones más: generación de aprendizaje, construcción de la web semántica y redes de datos enlazados, vinculados con la representación y organización de información en la web. Tales resultados son muestra de que la bibliotecología, por una parte, sigue una tendencia tradicionalista que organiza temáticamente dominios y recursos; por otra, se desplaza hacia una inserción en contextos web en los que impera la web semántica, los datos enlazados y las redes de información.
En comparación con otros sistemas para la representación y organización de la información (encabezamientos de materias, tesauros, bases conceptuales), las ontologías ofrecen ventajas de representación y organización de datos, información y recursos de información con base en estructuras complejas compuestas de conceptos, atributos, categorías y relaciones. Aunado a ello, ofrecen múltiples opciones de acceso (alfabético, jerárquico, gráfico-desplegable) que las convierten en herramientas flexibles para necesidades de organización-recuperación de información de naturaleza diversa en disciplinas igualmente diversas.
Por último, se concluye que sus implementaciones en ámbitos bibliotecológicos se encuentran en un estado inicial que abarca apenas de 2008 a la actualidad. Derivado de ello, los próximos años serán cruciales para su desarrollo, que dependerá de aspectos como el estudio teórico de las herramientas, la difusión de sus características y ventajas como SOC, la formación de profesionales capaces de implementarlas y las posibilidades de presentación final hacia los usuarios, ya sea como meras bases de datos, subyacentes a sitios web para la web semántica, como grafos desplegables bajo una interfaz del sistema, o como mapas temáticos que vinculen recursos de información a partir de su contenido temático.

